Downloaded 64 times




























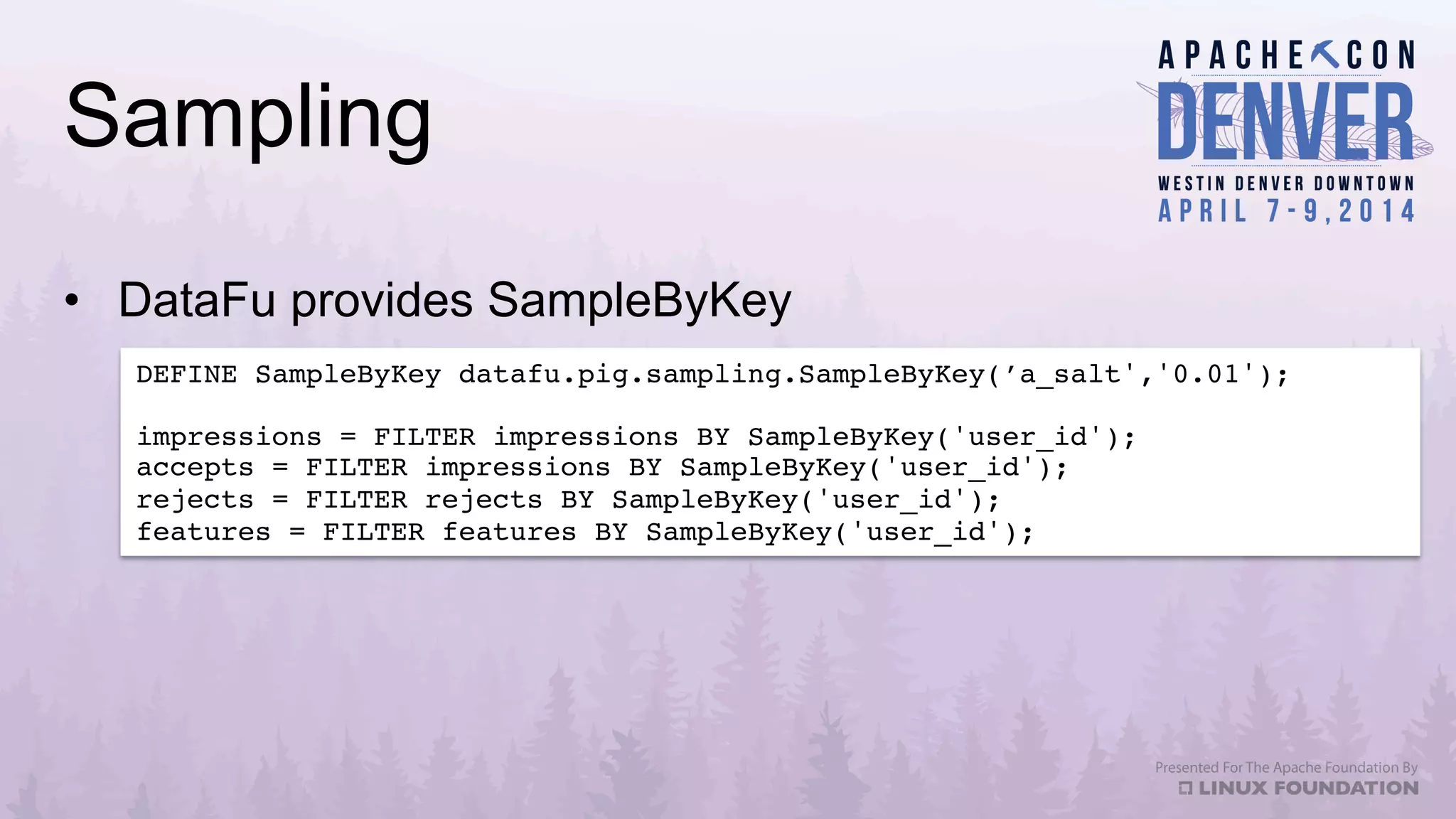

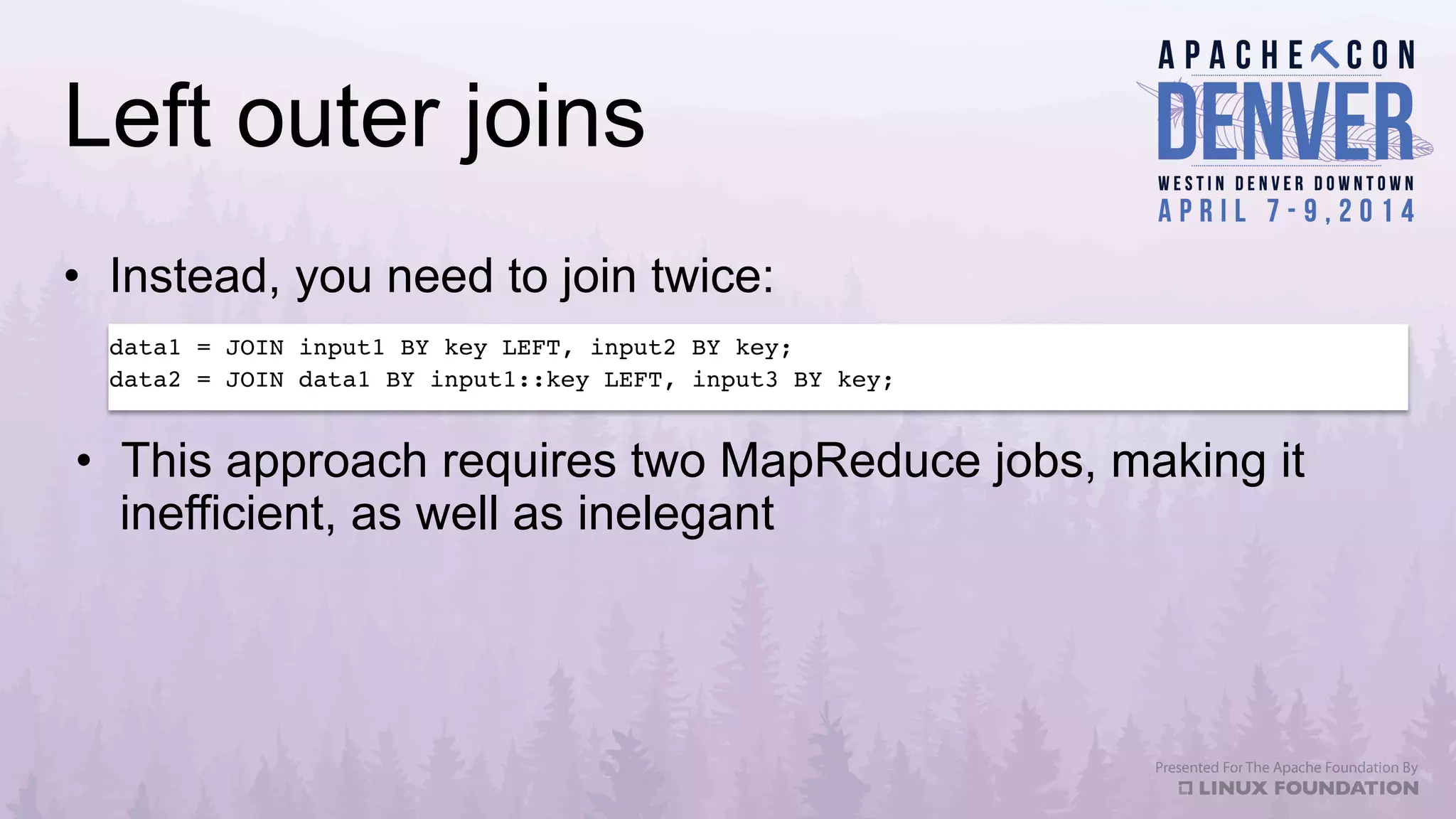
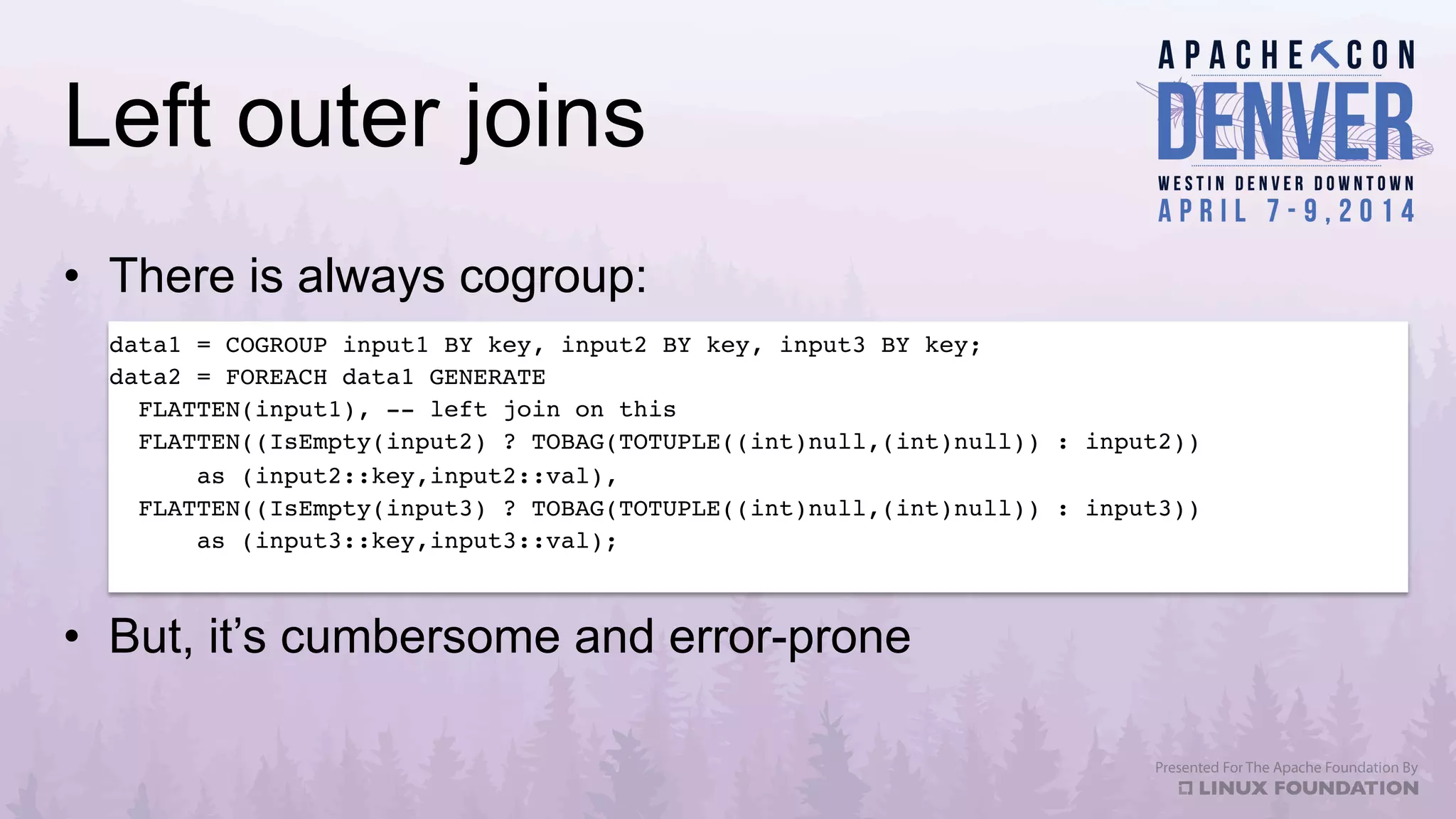
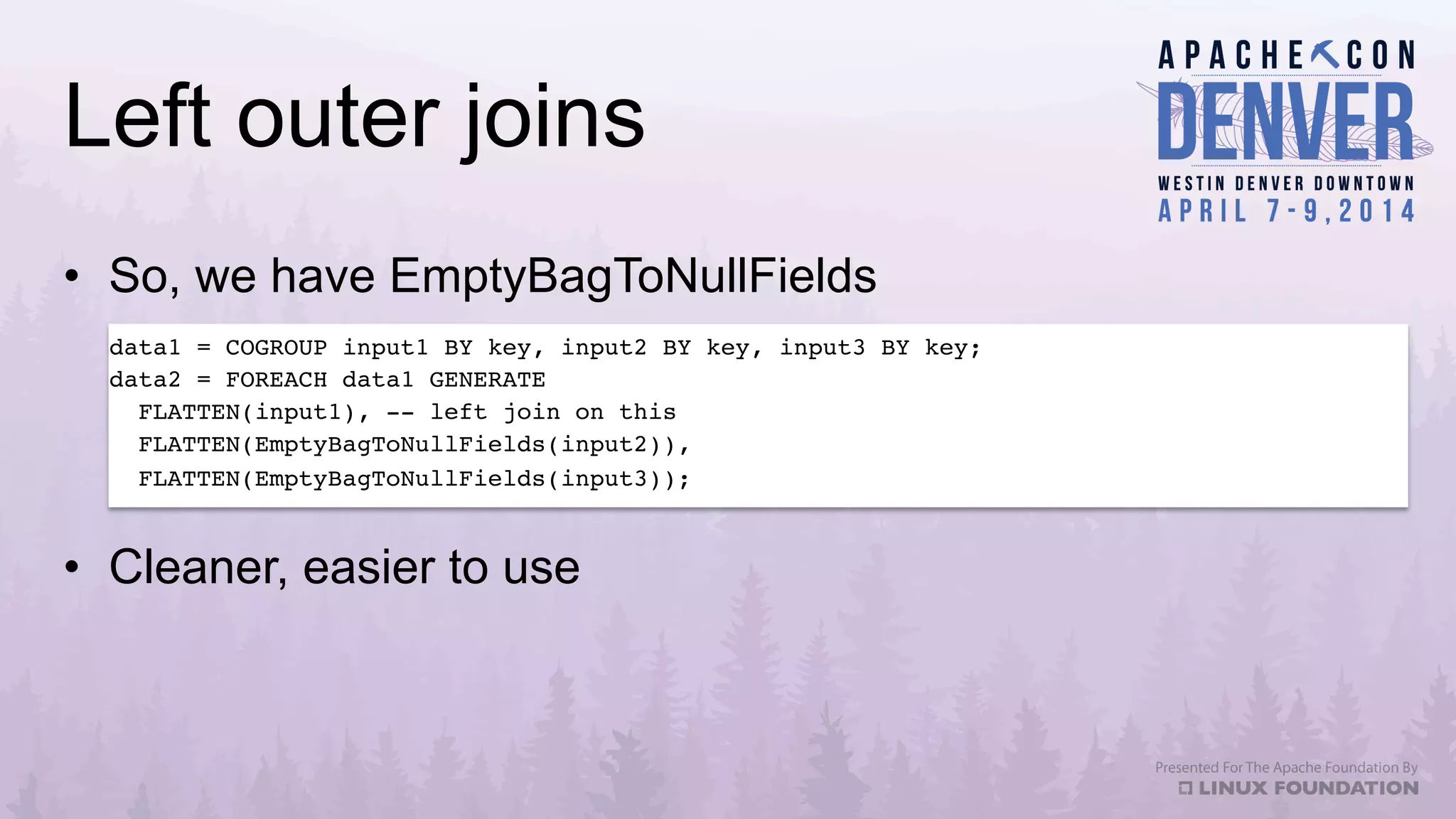












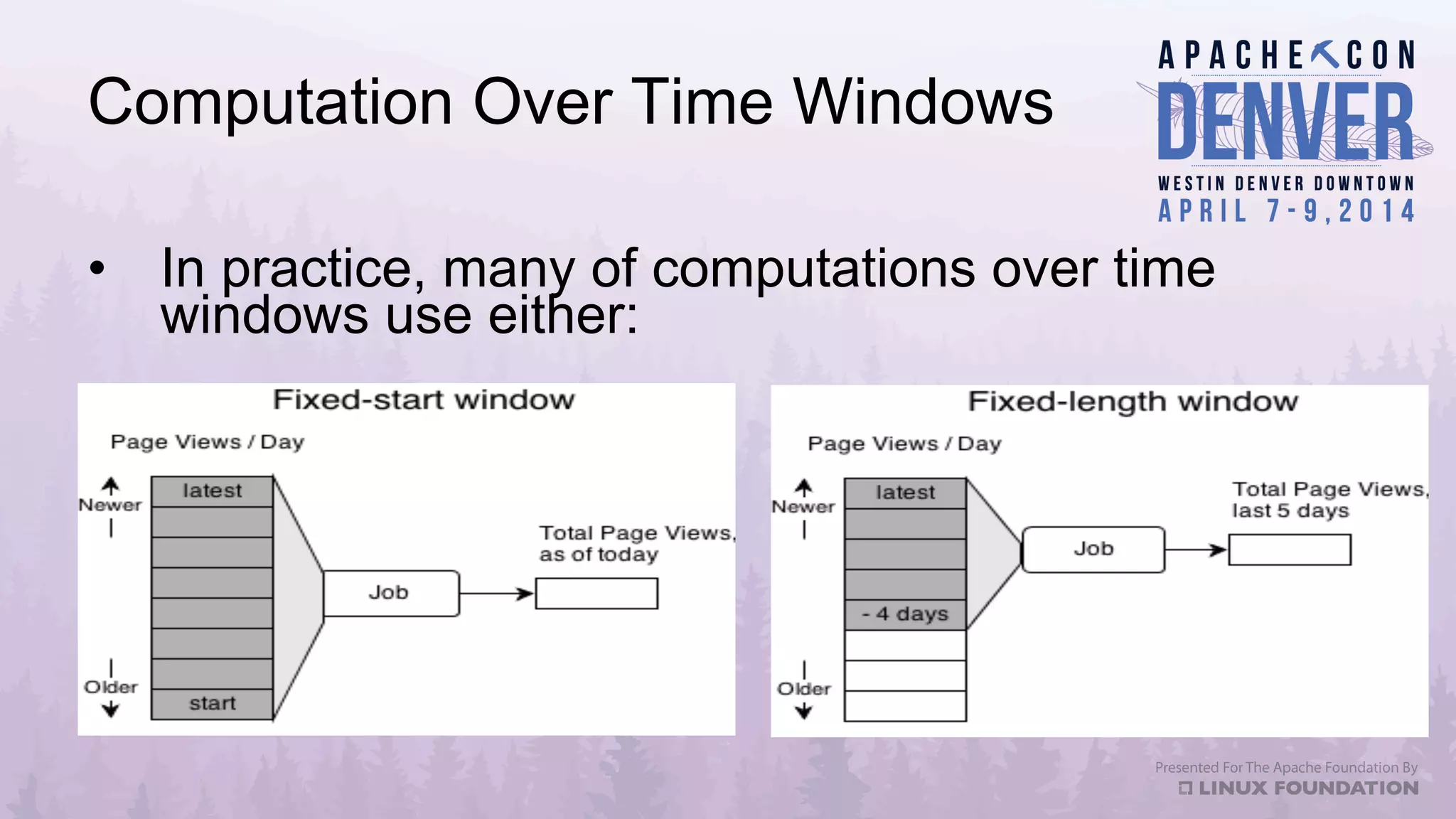

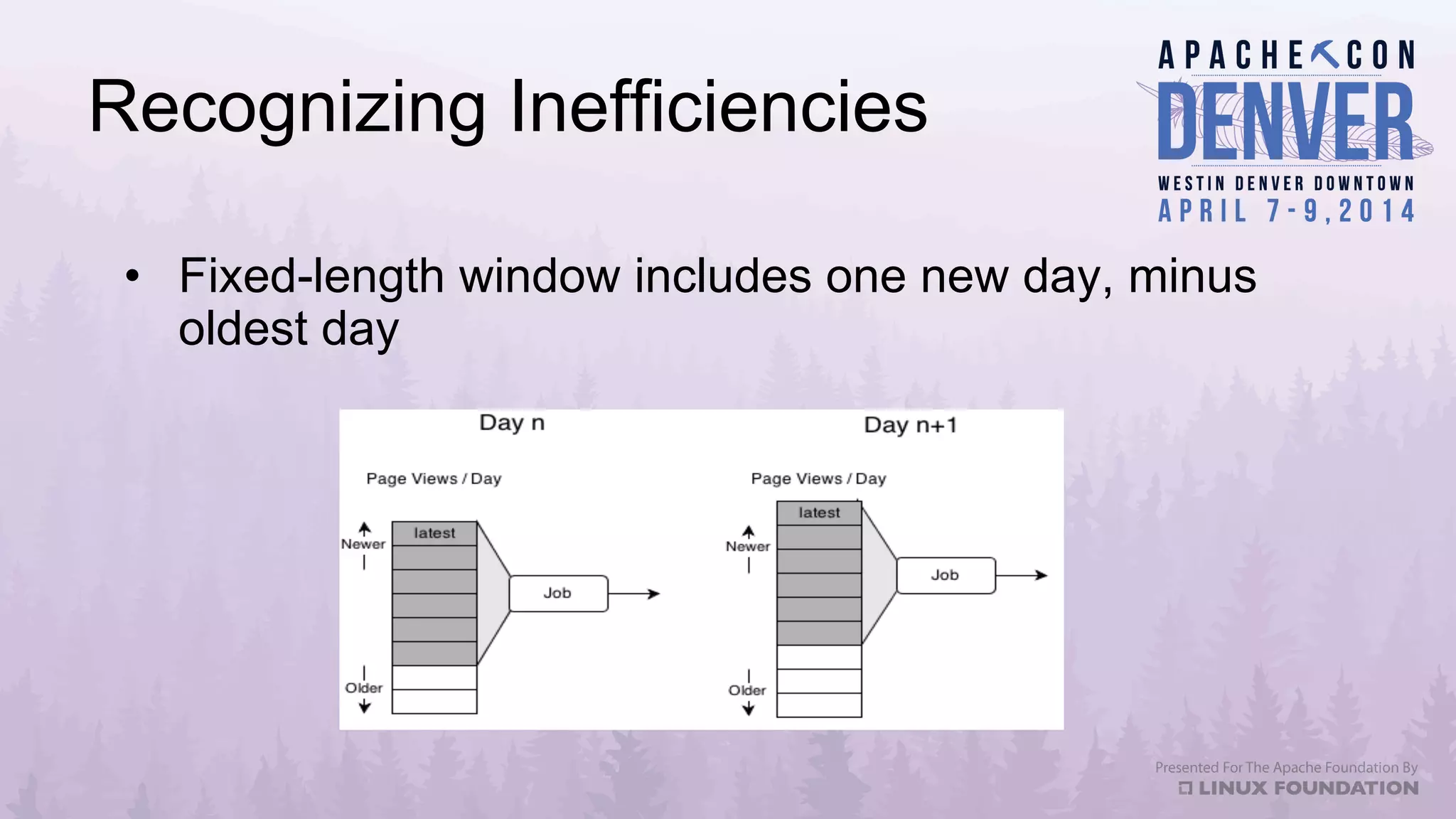


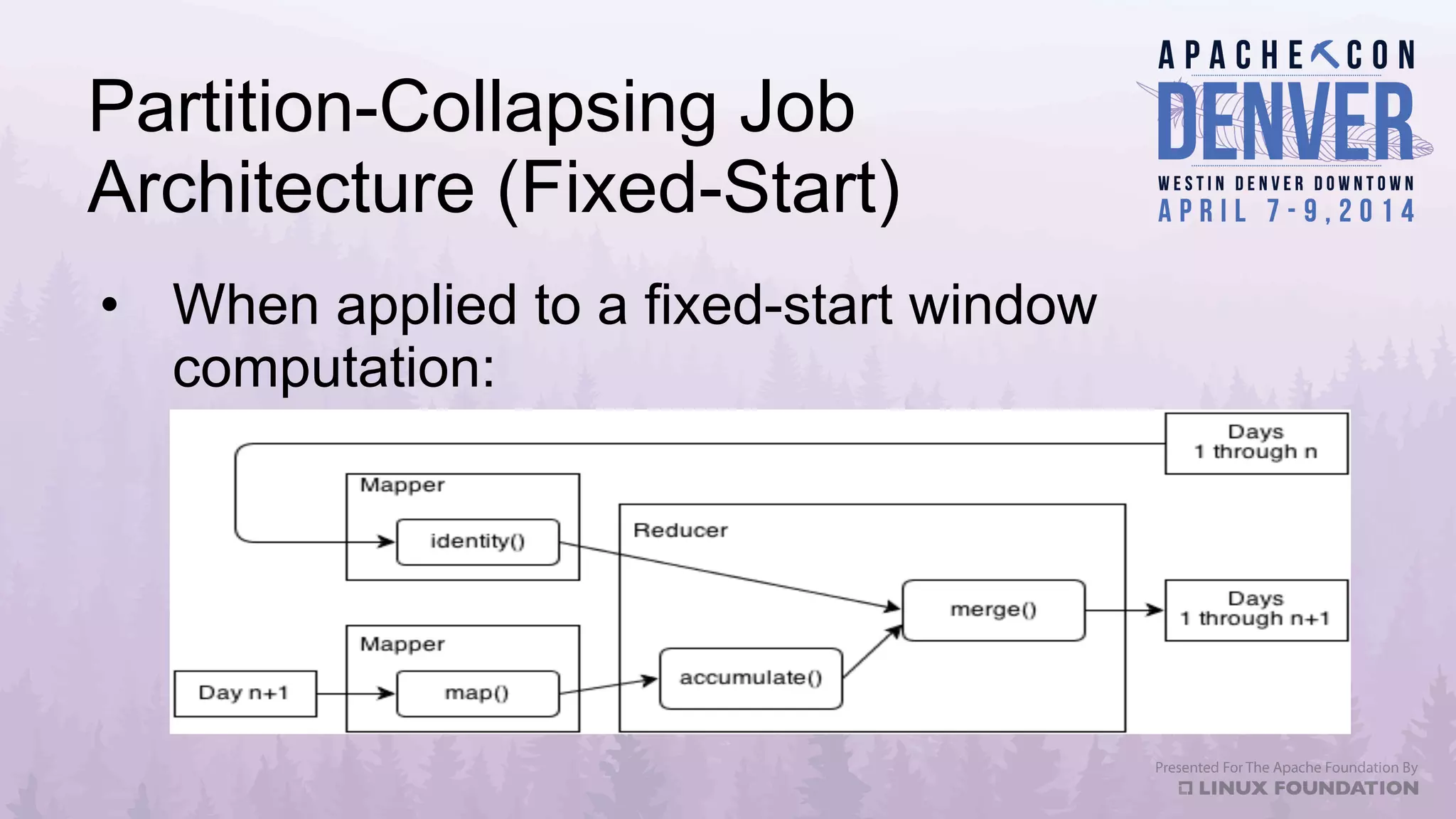

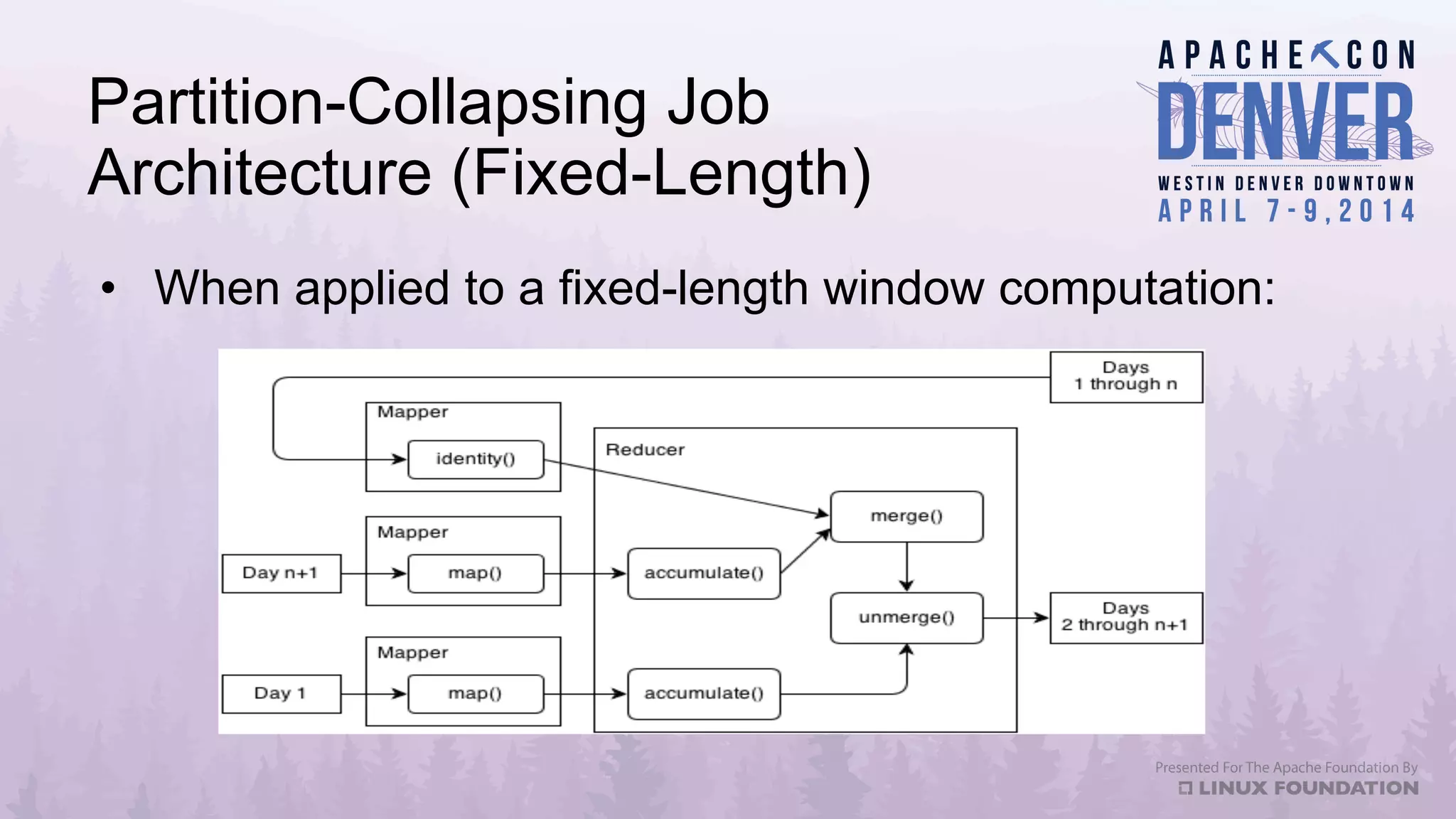

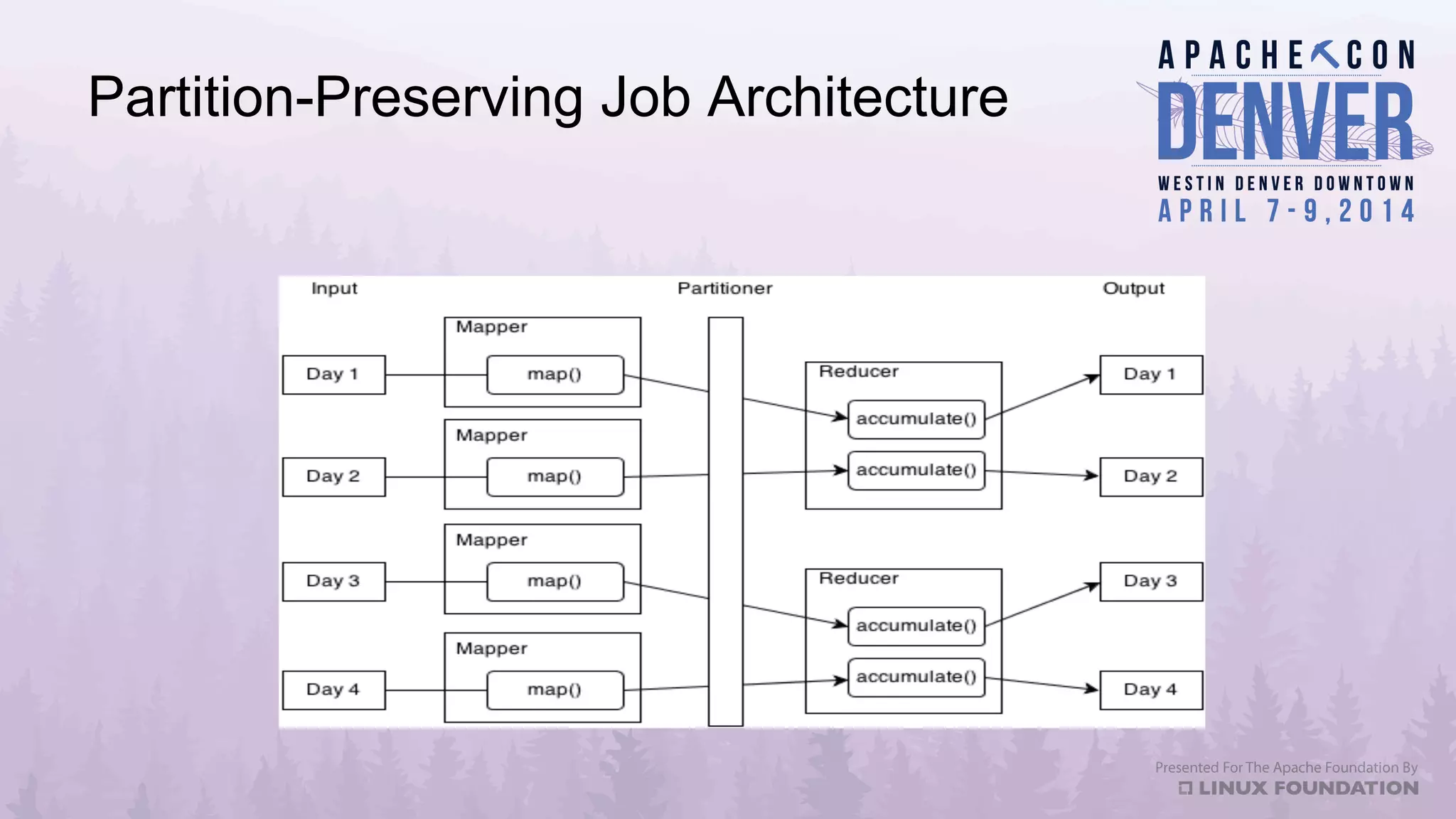





Apache Datafu is a collection of libraries designed to facilitate large-scale data processing in Hadoop, featuring components like Datafu Pig for user-defined functions (UDFs) and Datafu Hourglass for incremental processing. The libraries emphasize documentation, ease of contribution, and automated testing, making it user-friendly for data analysts and engineers. Datafu includes tools for session analysis, bag manipulation, and event counting, along with features that enhance efficiency in handling large datasets.





![Reproducible datascience [with Terraform]](https://cdn.slidesharecdn.com/ss_thumbnails/reproduceabledatascience1-180630074643-thumbnail.jpg?width=640&height=640&fit=bounds)








































































