













![Time 2012-02-04 01:33:51
Apache Tag apache.log
Record {
"host": "127.0.0.1",
tail "method": "GET",
"path": "/",
write ...
}
insert
127.0.0.1
127.0.0.1
127.0.0.1
-
-
-
-
-
-
[11/Dec/2012:07:26:27]
[11/Dec/2012:07:26:30]
[11/Dec/2012:07:26:32]
"GET
"GET
"GET
/
/
/
...
...
...
Fluentd
127.0.0.1 - - [11/Dec/2012:07:26:40] "GET / ...
127.0.0.1 - - [11/Dec/2012:07:27:01] "GET / ...
...
event
buffering
Mongo
22
Friday, April 5, 13](https://image.slidesharecdn.com/thearchitectureofdataanalyticspaasonaws-130316024932-phpapp02/75/The-architecture-of-data-analytics-PaaS-on-AWS-22-2048.jpg)



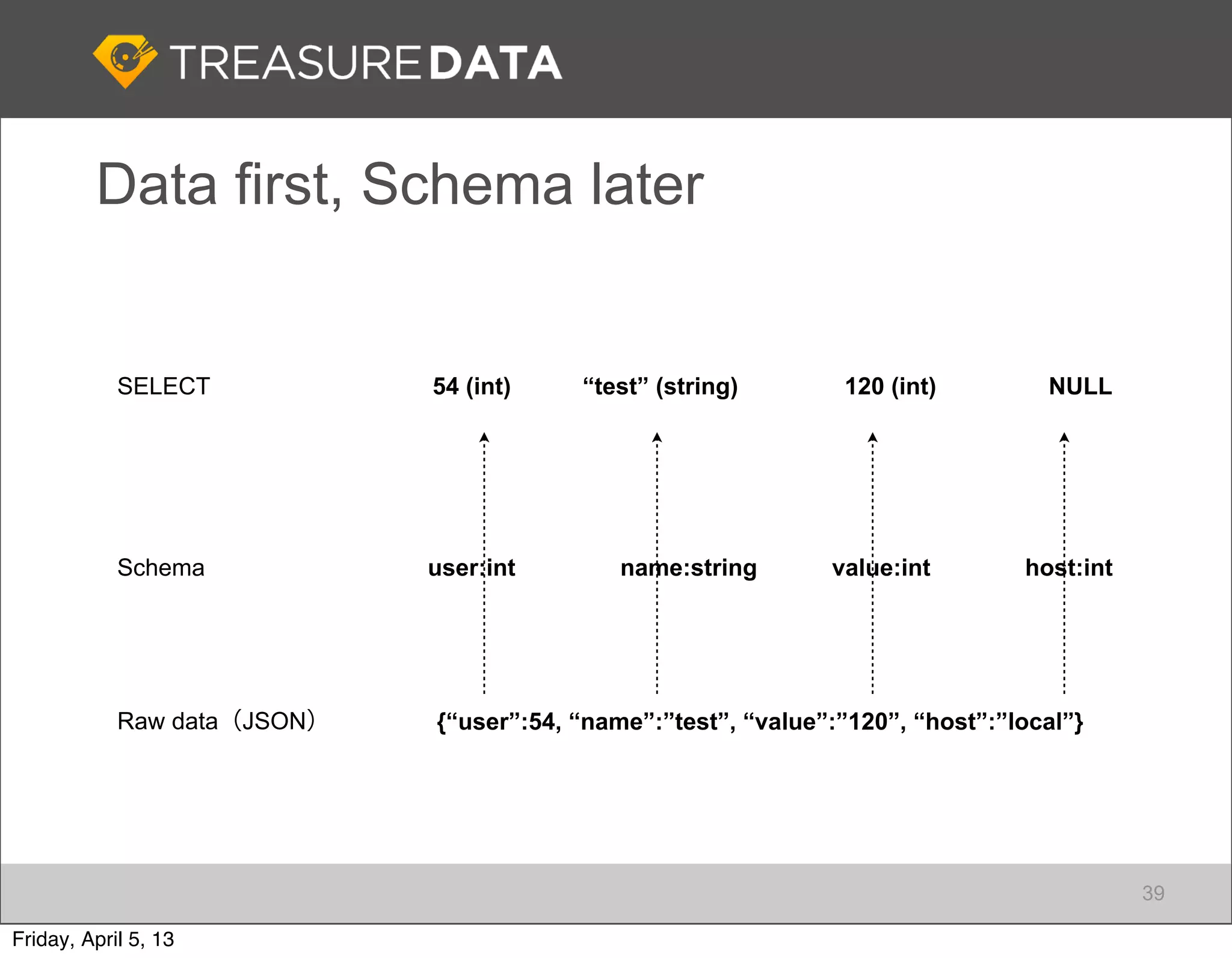
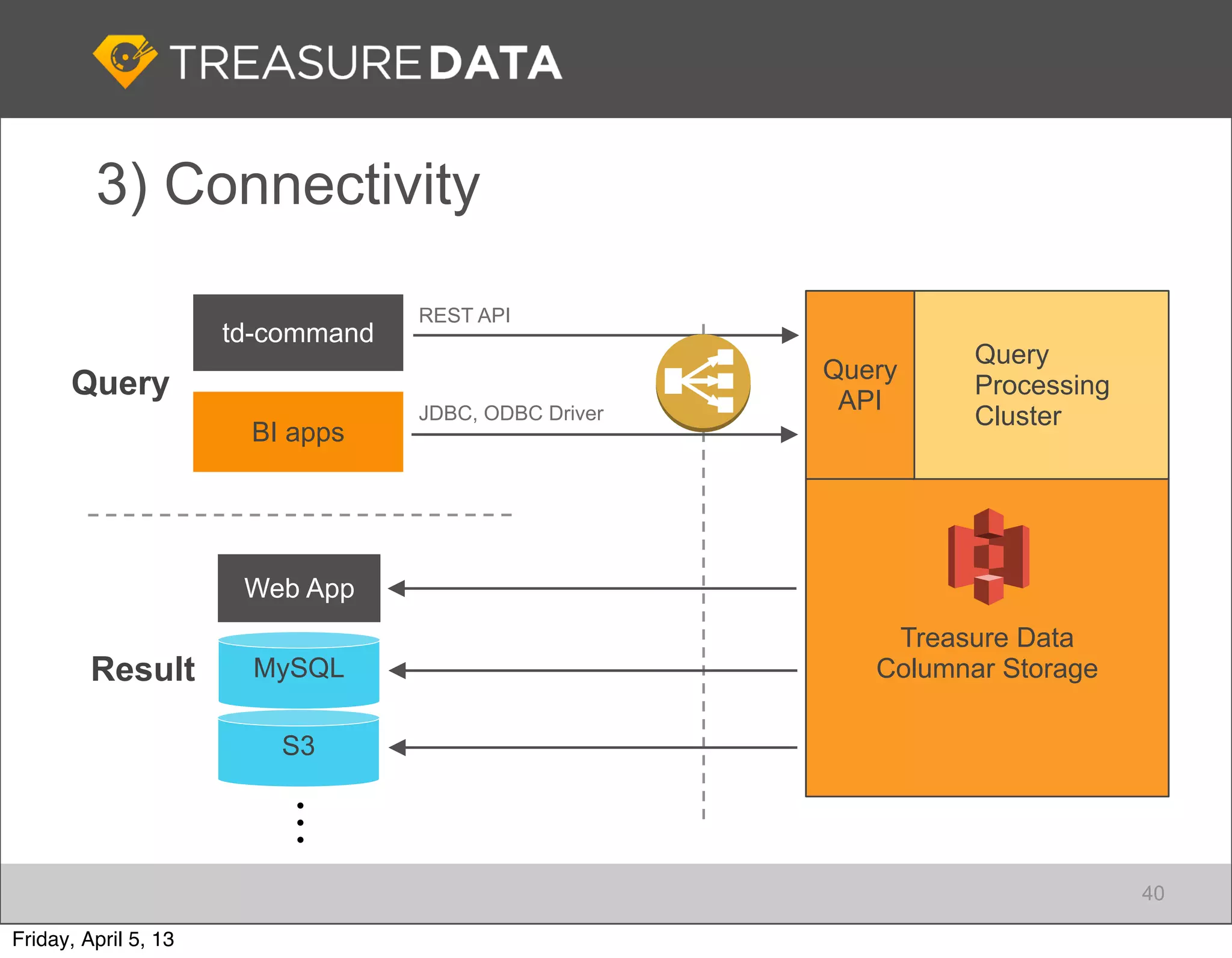
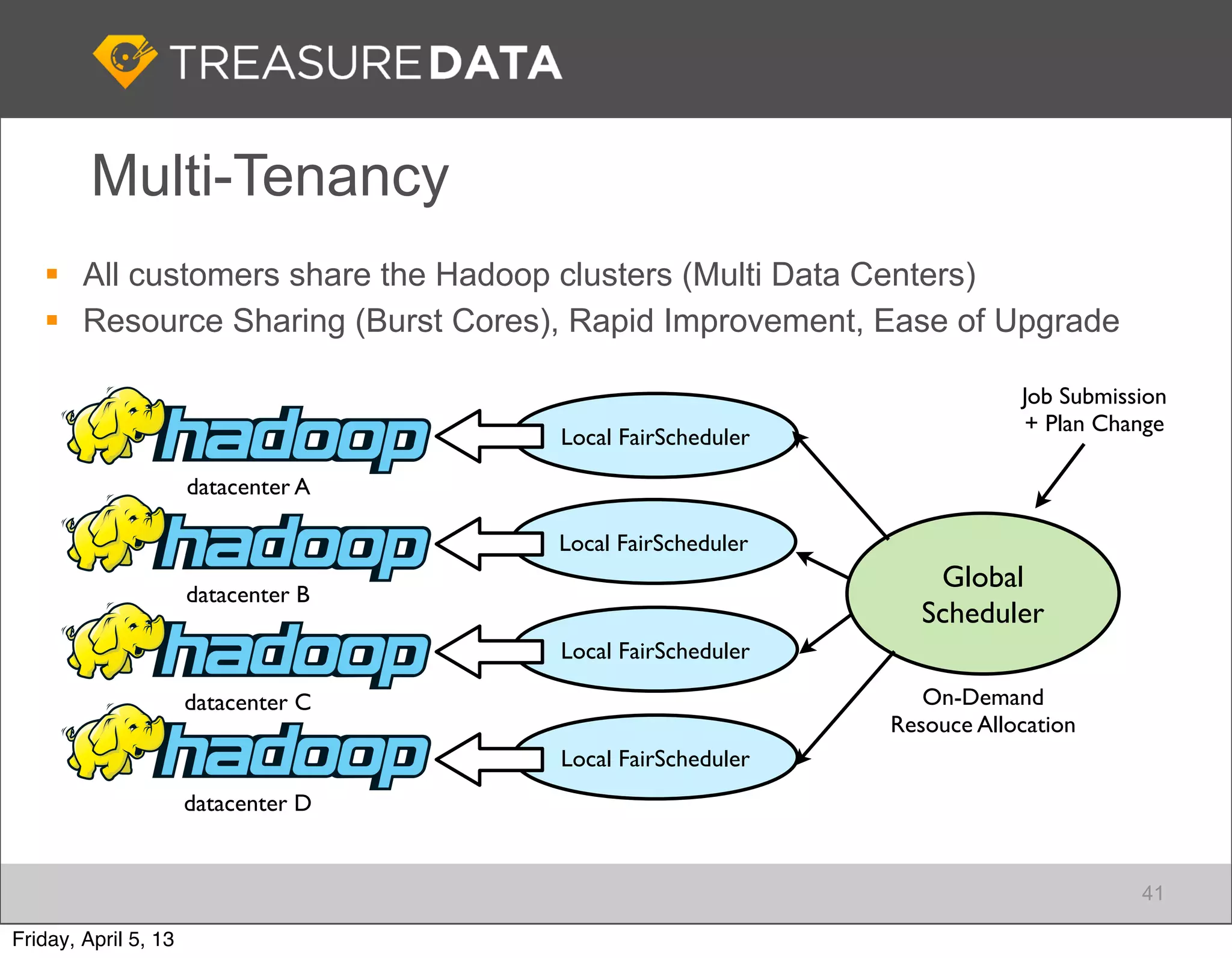



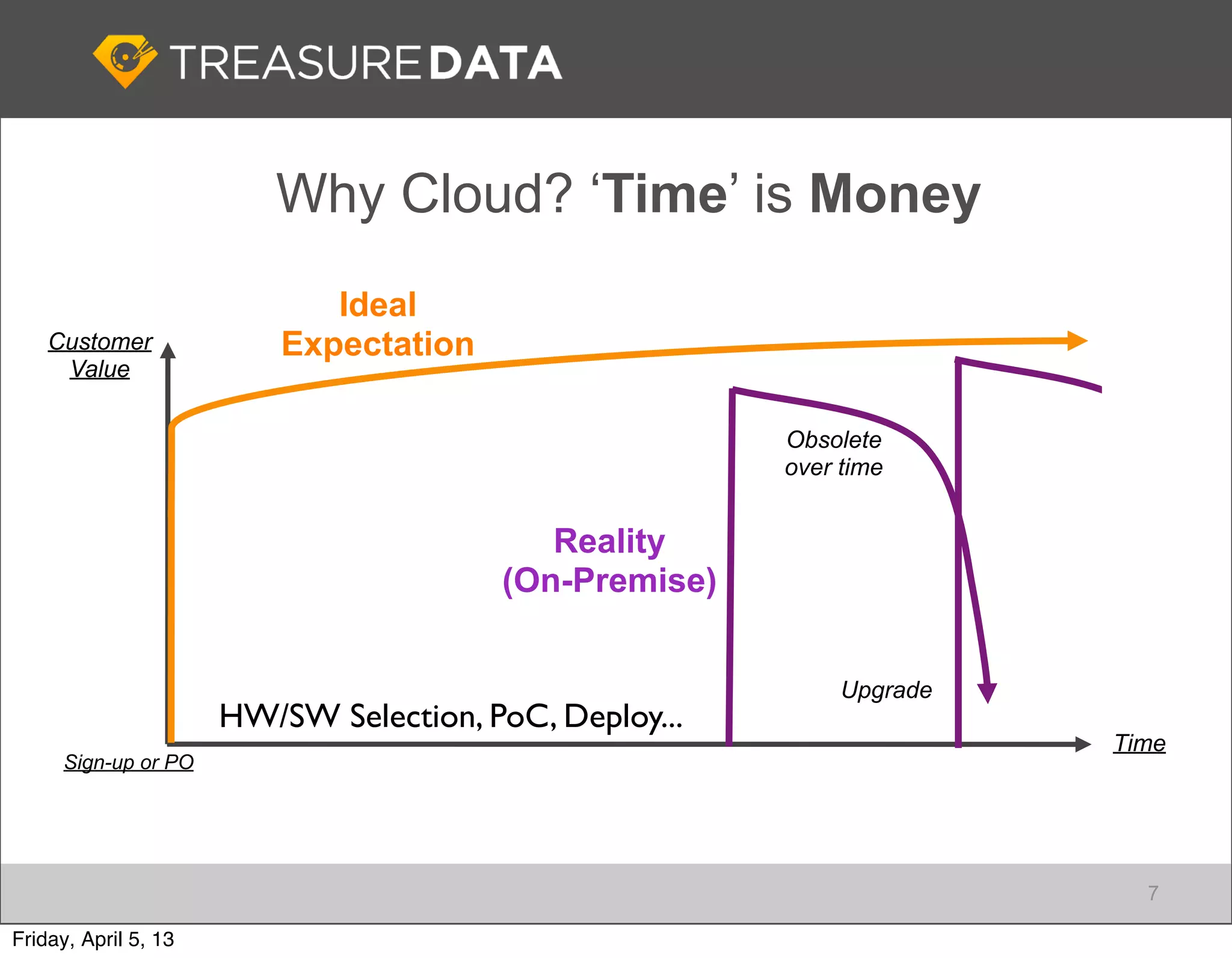
This document outlines the architecture and service offerings of Treasure Data, a cloud-based big data analytics platform founded by Japanese entrepreneurs. It details the company's use of AWS products for data collection, storage, and analytics, emphasizing efficiency and scalability. The presentation highlights the importance of real-time data processing and the integration of open-source tools like Fluentd for log collecting.
Introduction to Treasure Data and its architecture, presented by Masahiro Nakagawa at JAWS Days.
Overview of Treasure Data's foundation, team background, and investment details from notable individuals.
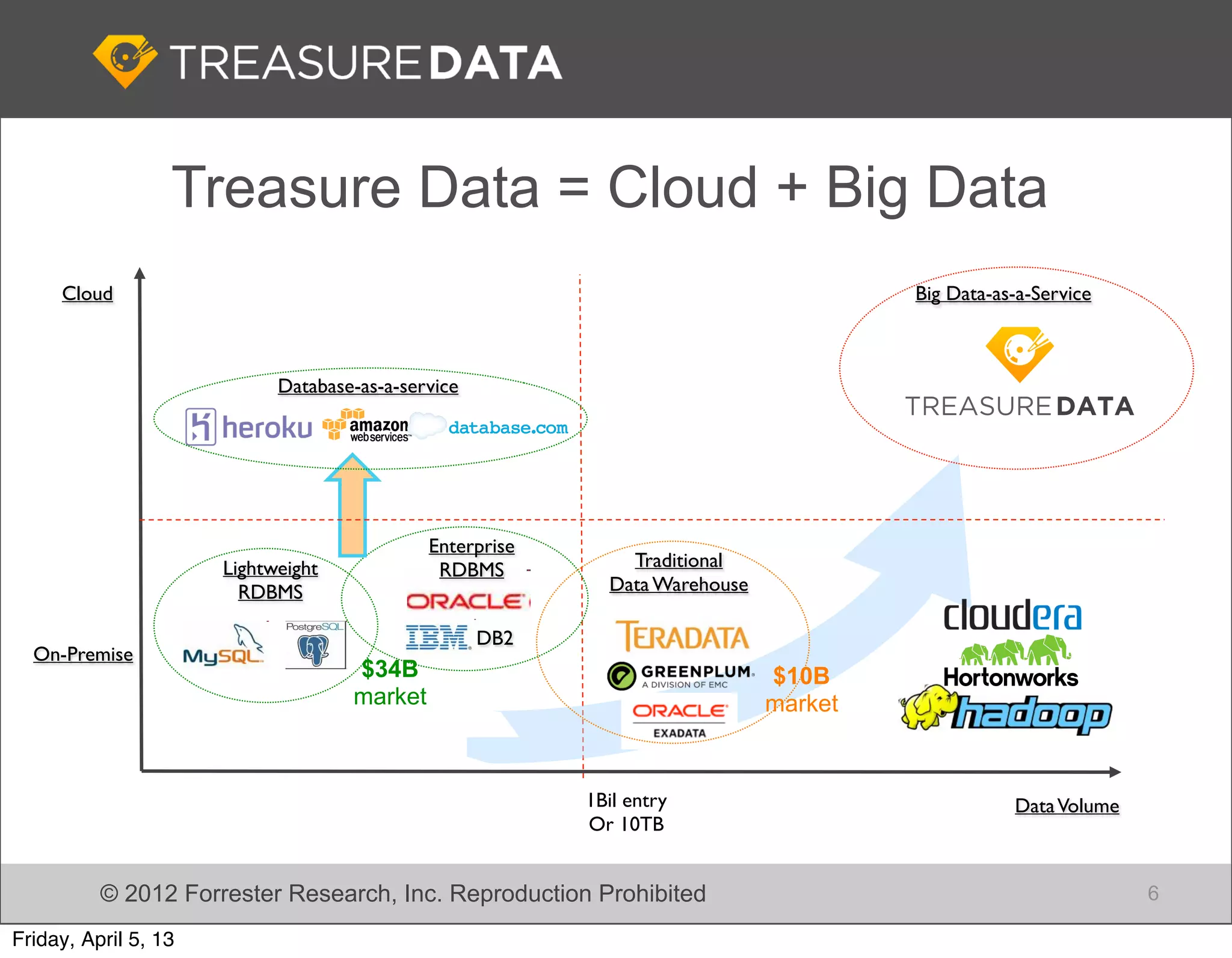
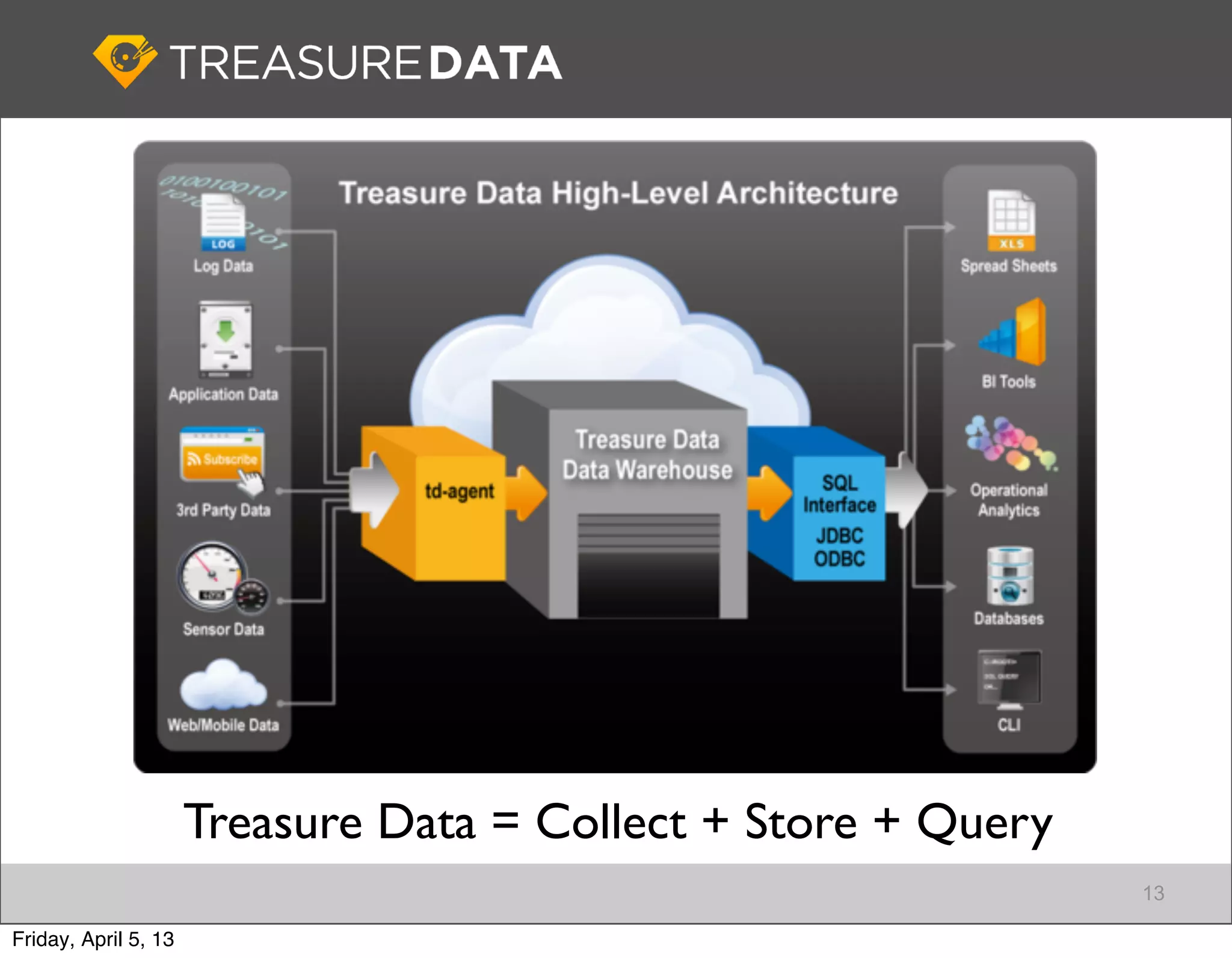
Treasure Data combines cloud technology with Big Data services, including database solutions and analytics.
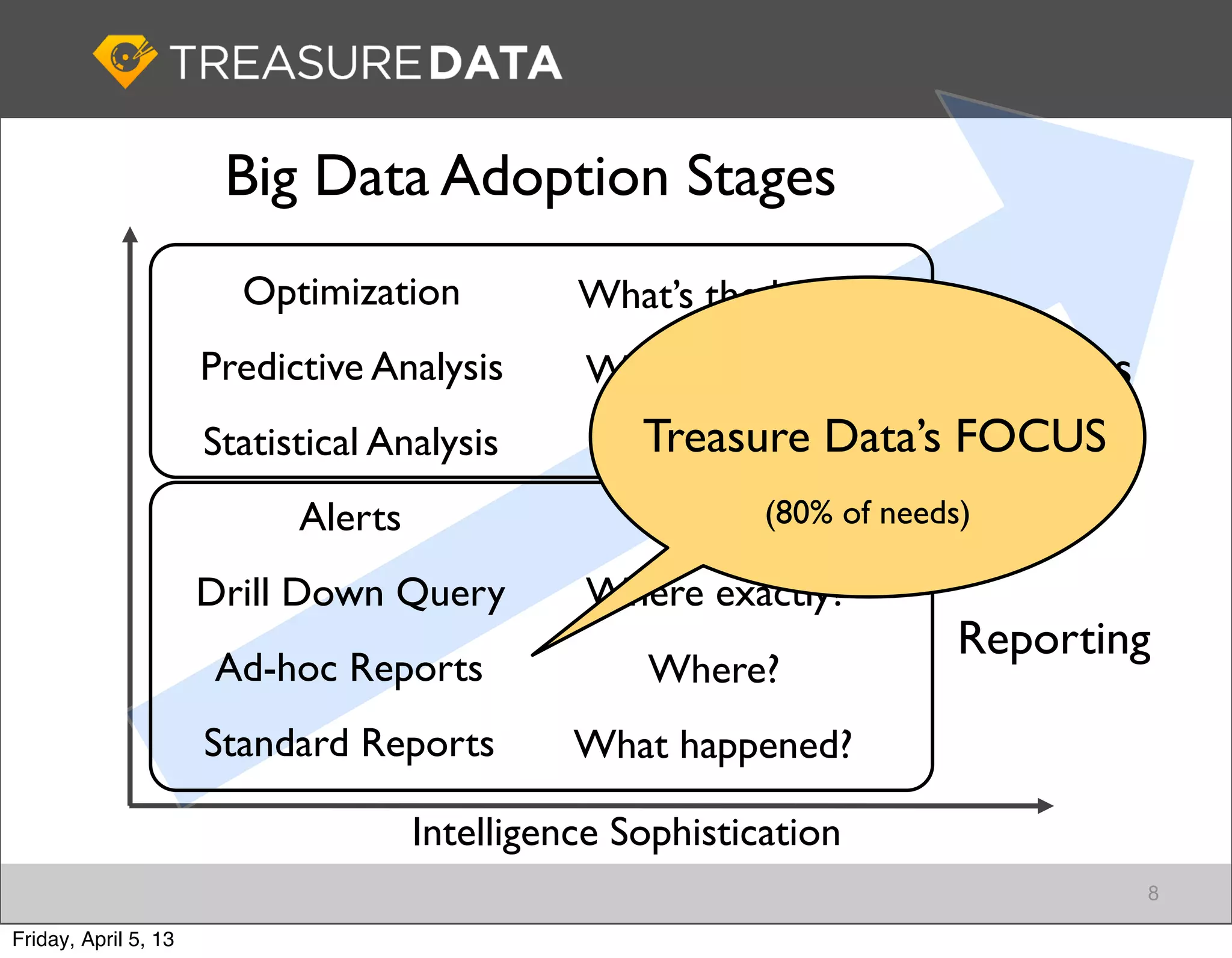
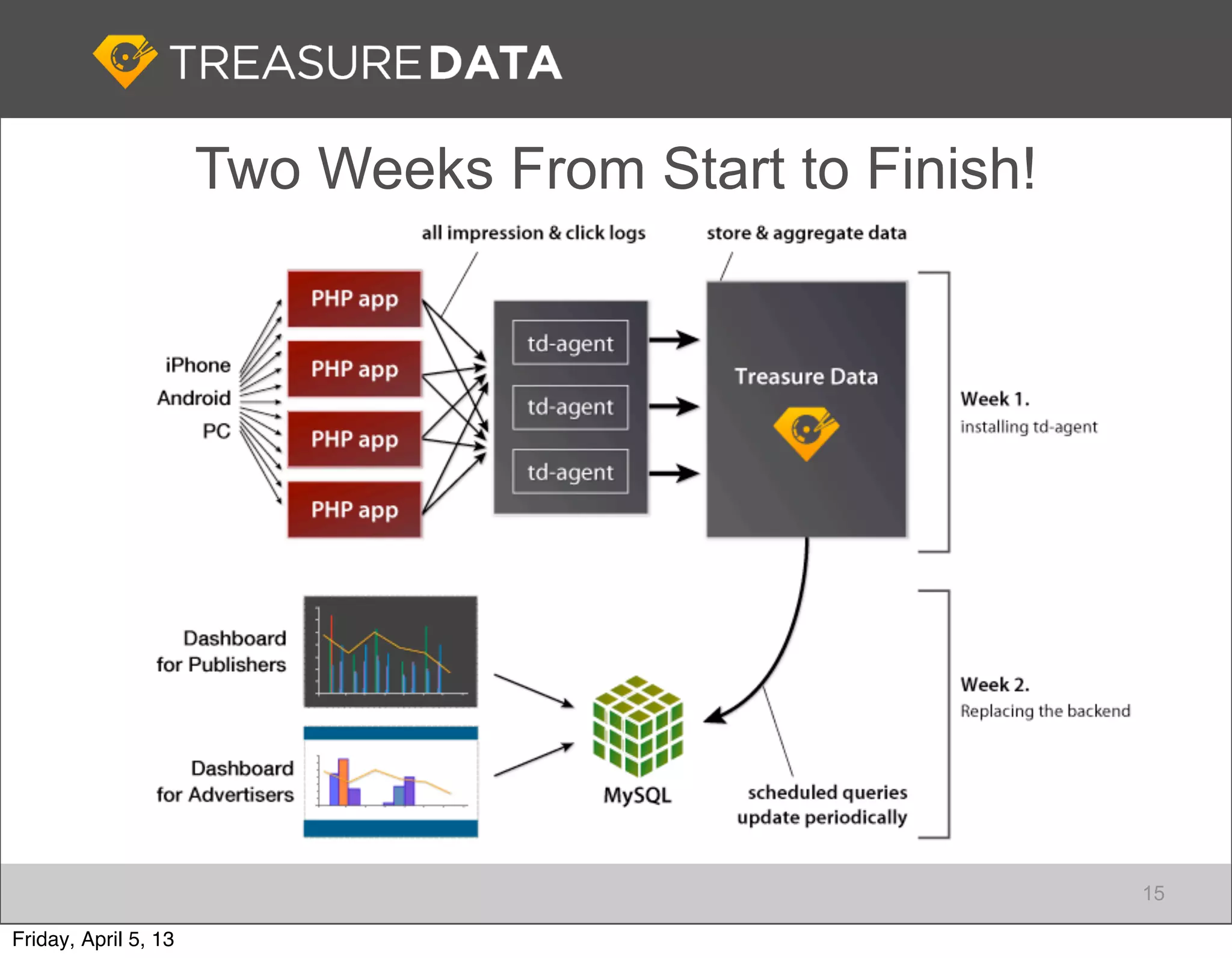
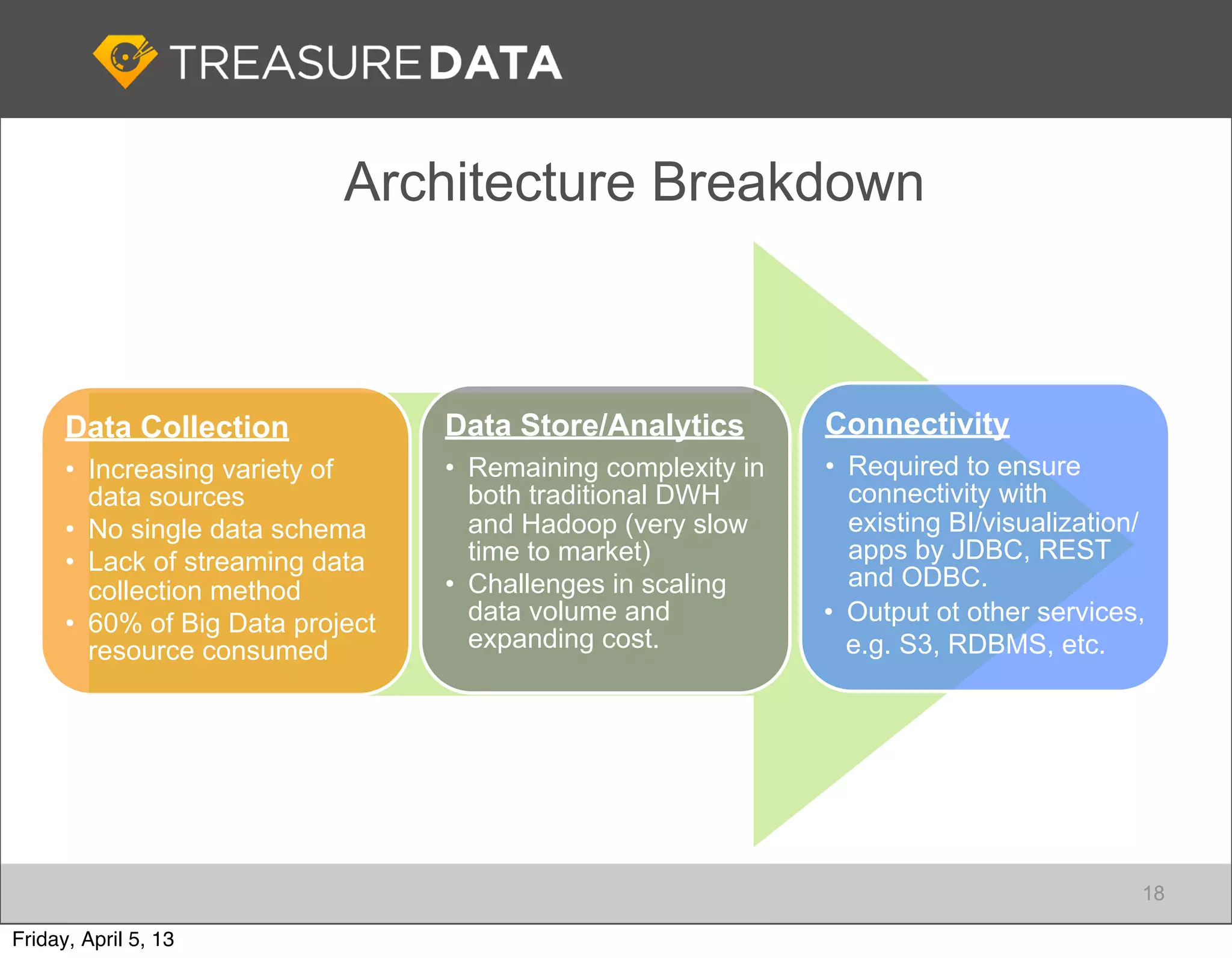
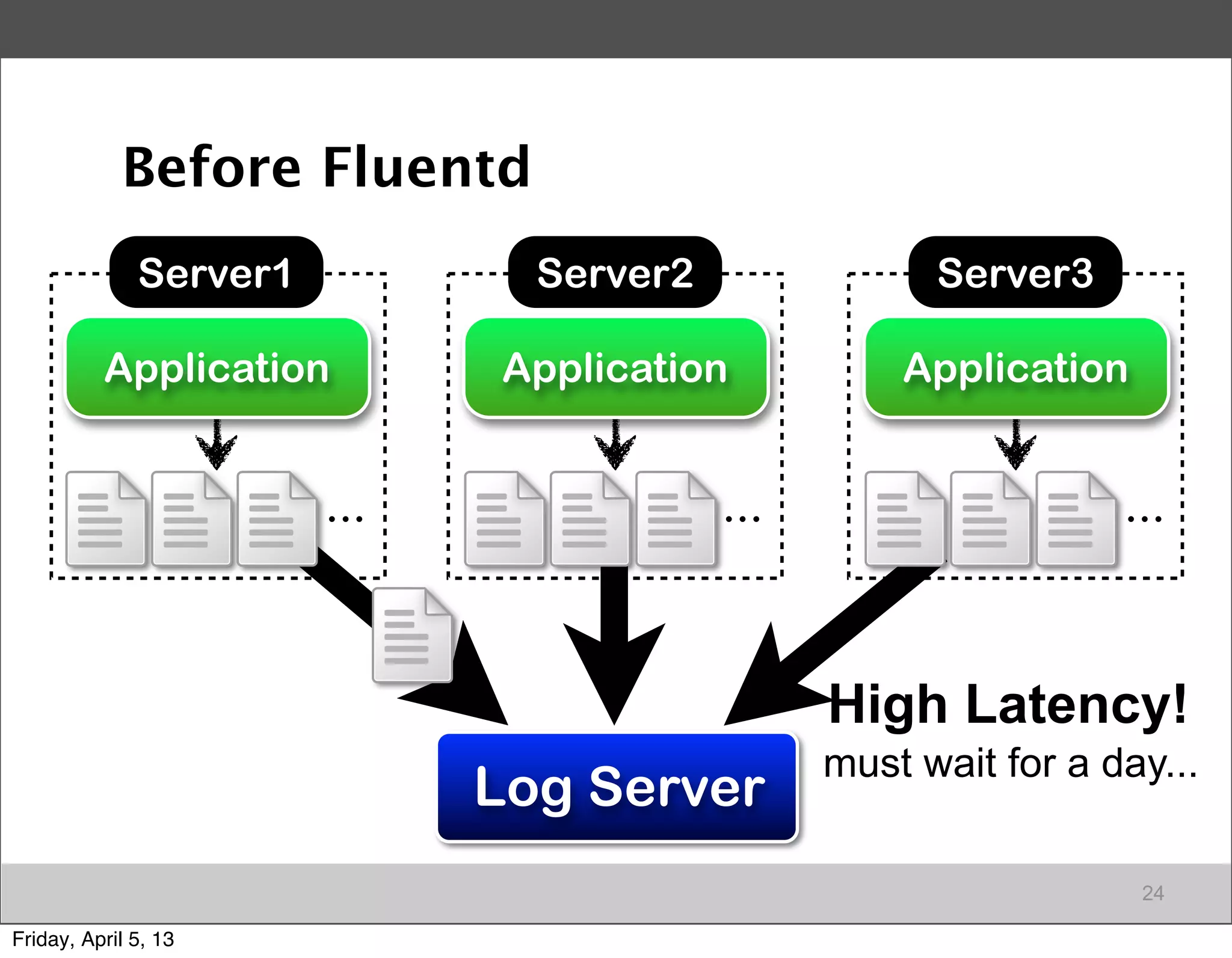
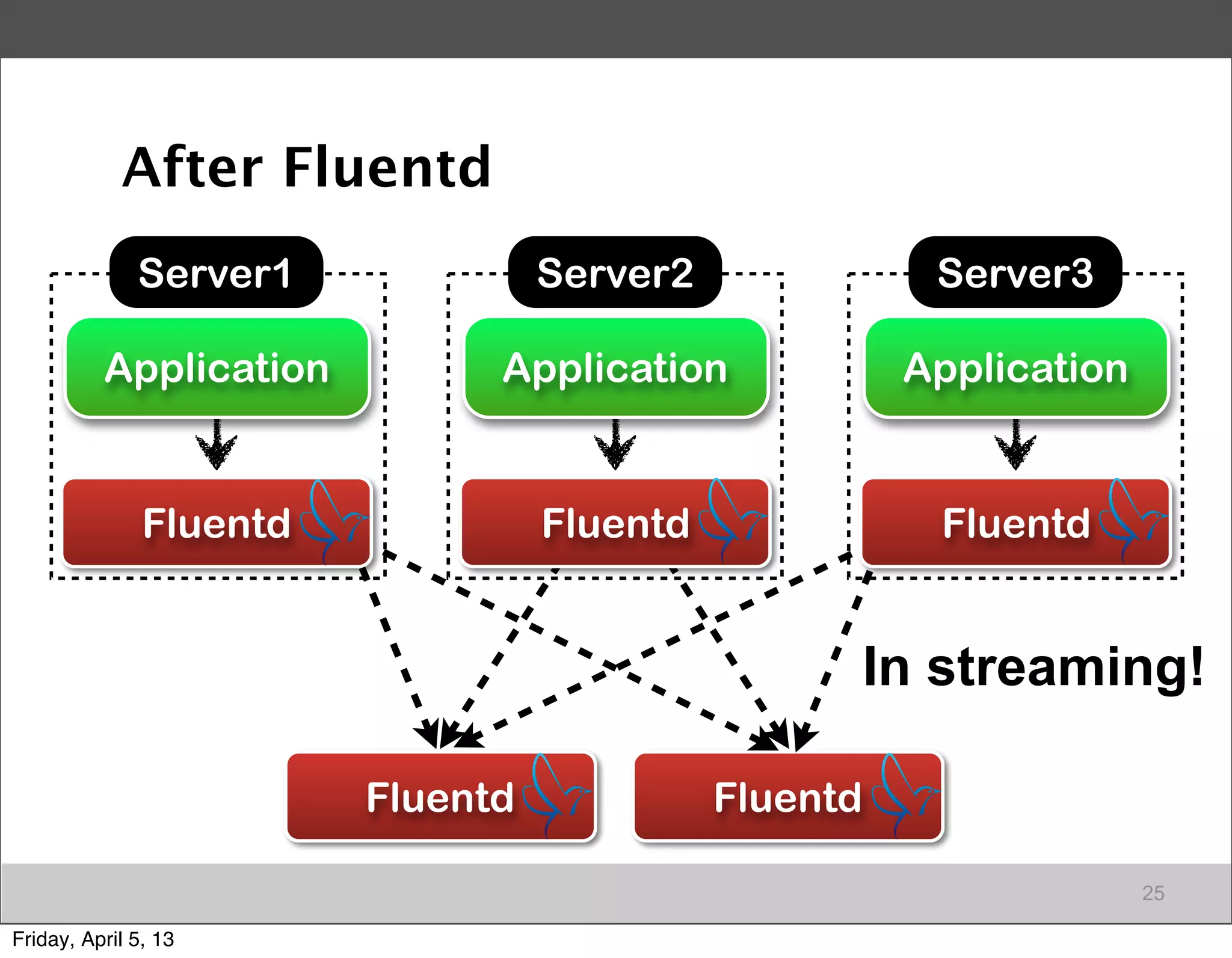
Stages of Big Data adoption and the importance of data collection, focusing on Fluentd for data management.
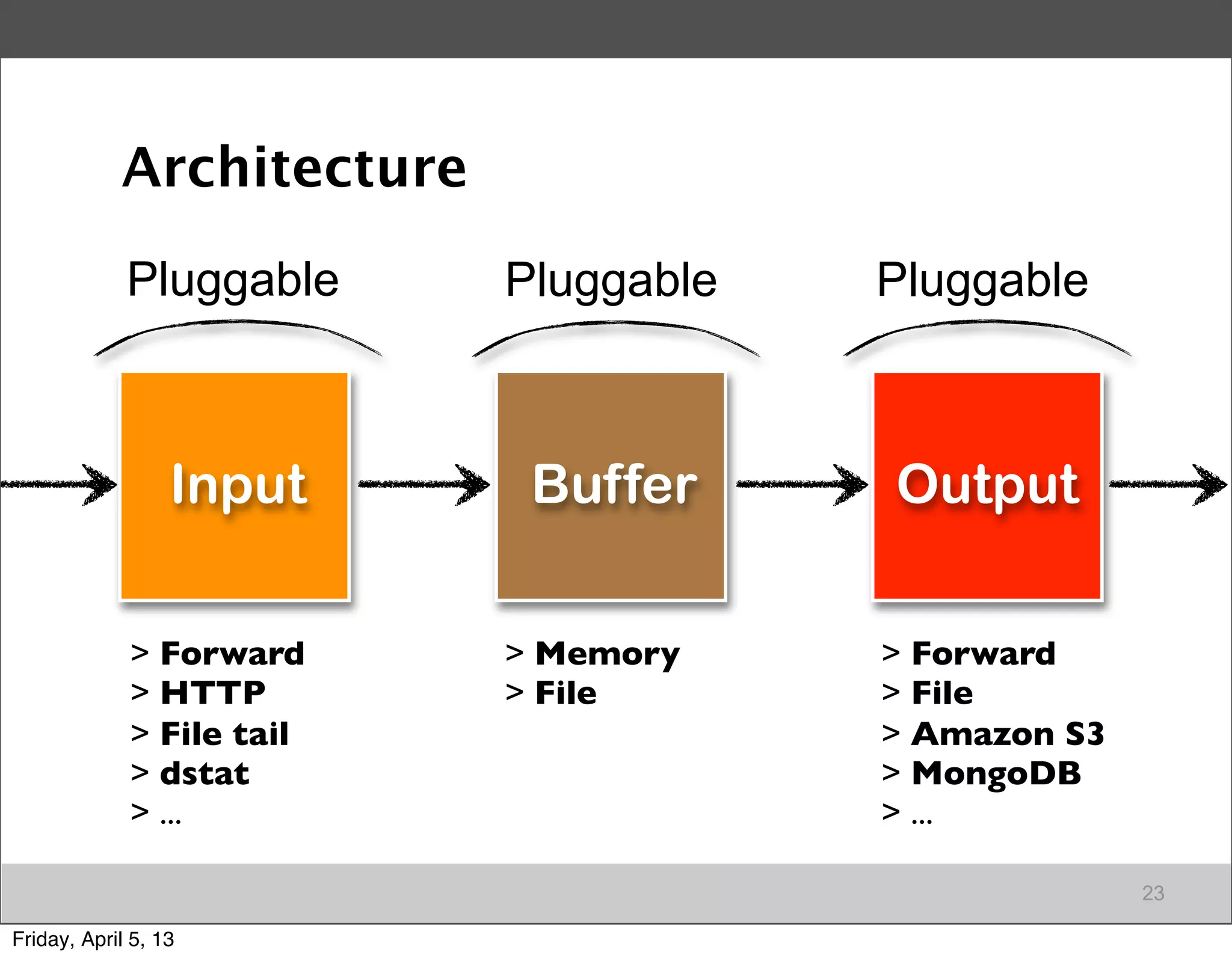
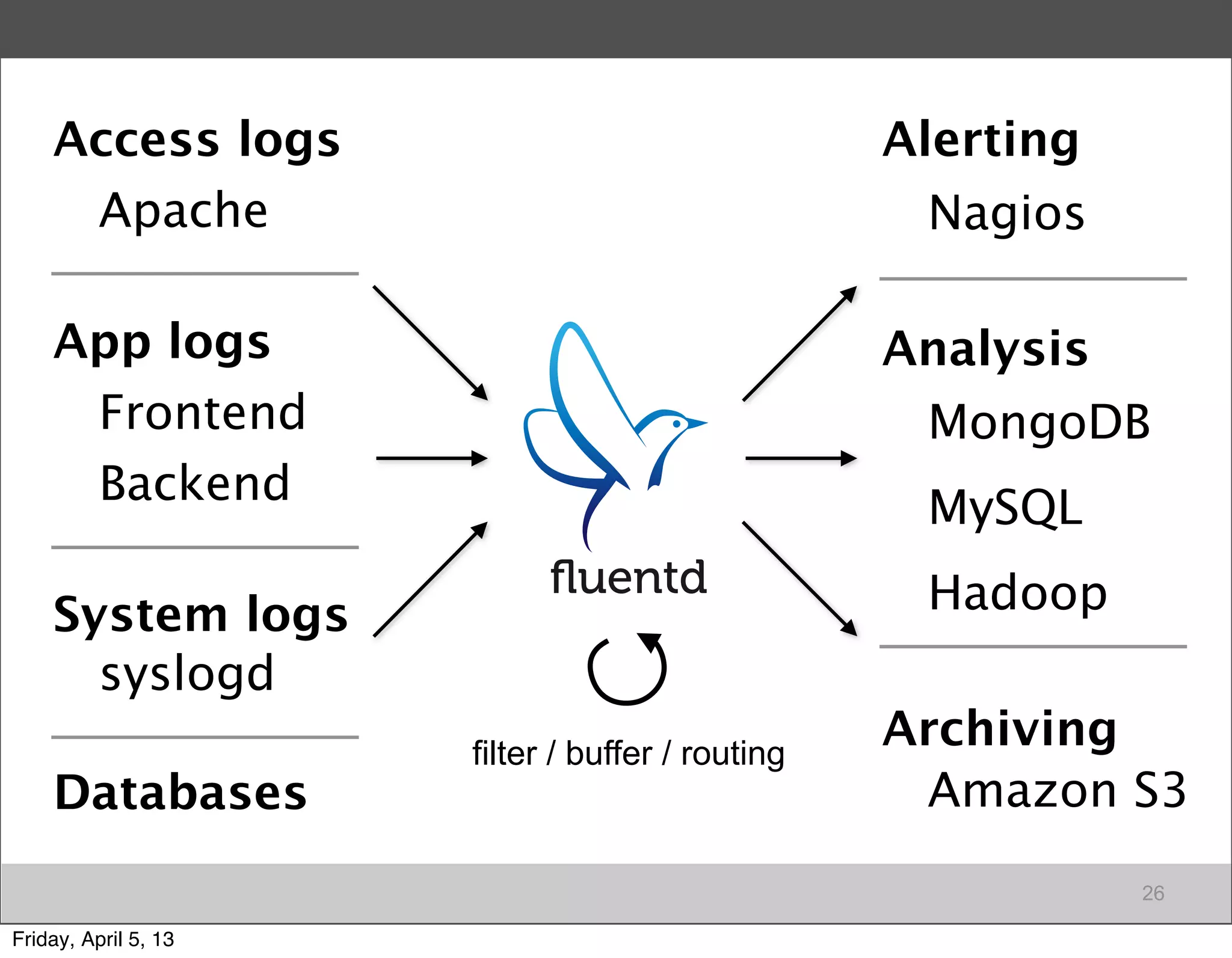
Introduction to Fluentd as an essential log collector for data, highlighting its architecture and functionalities.
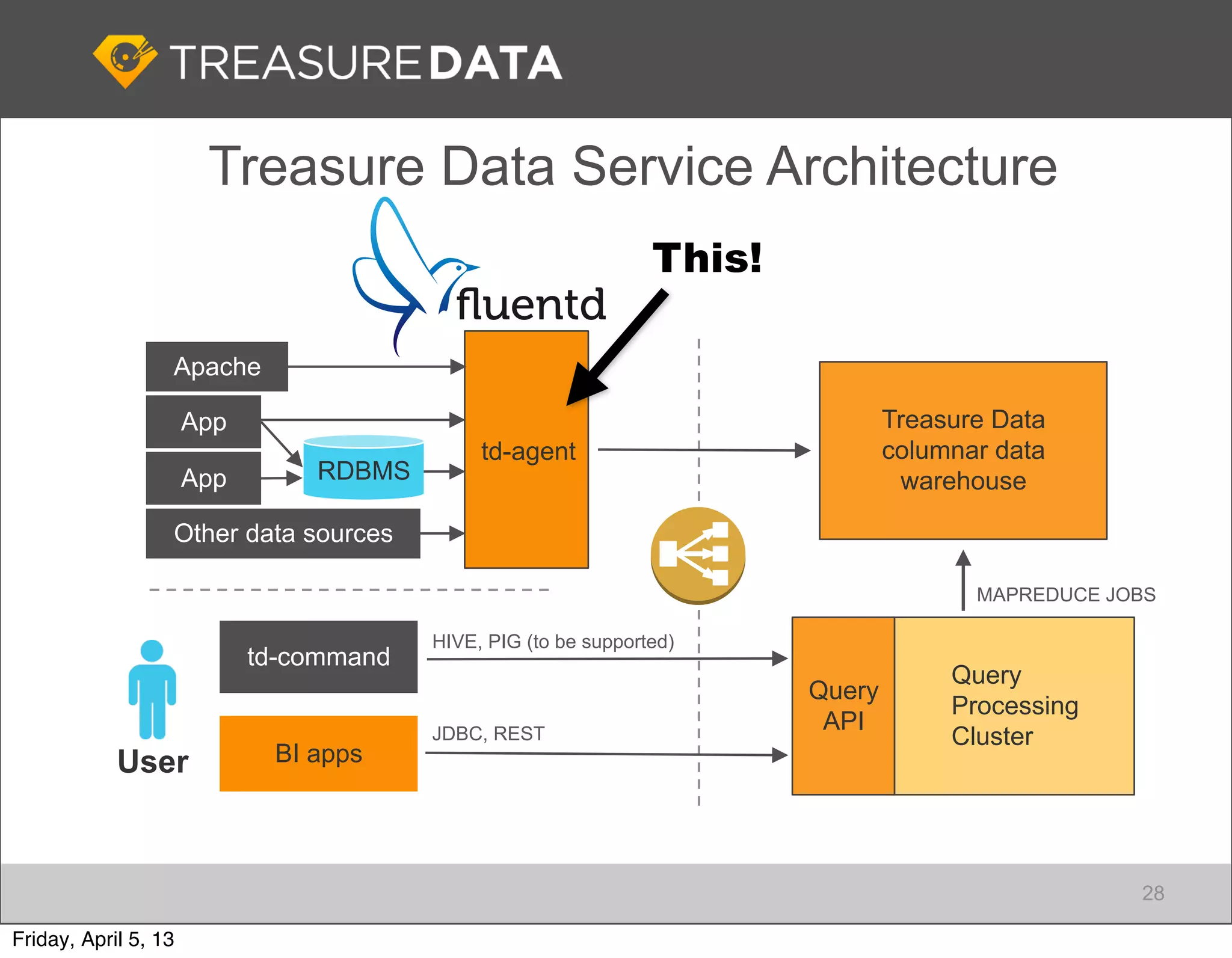
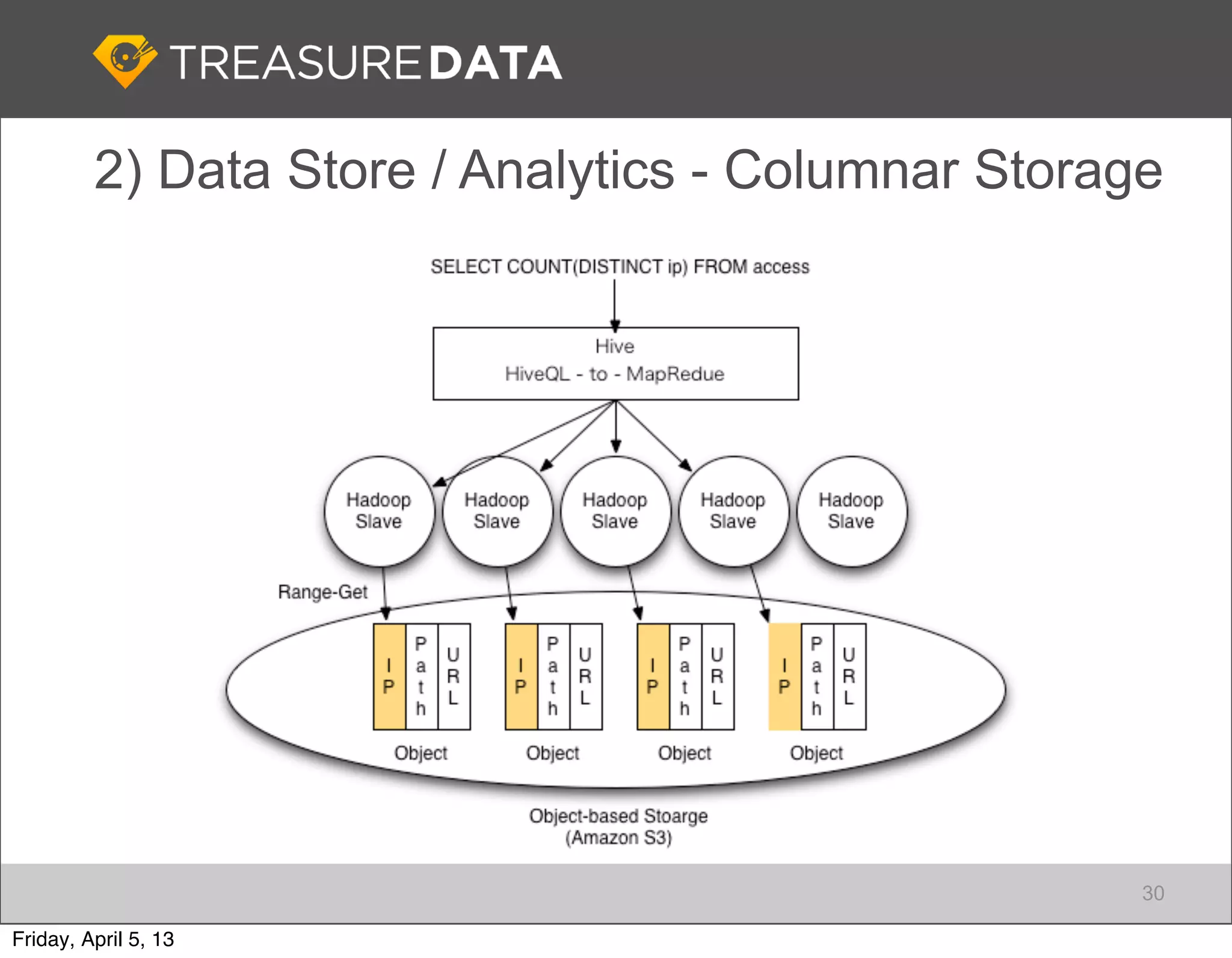
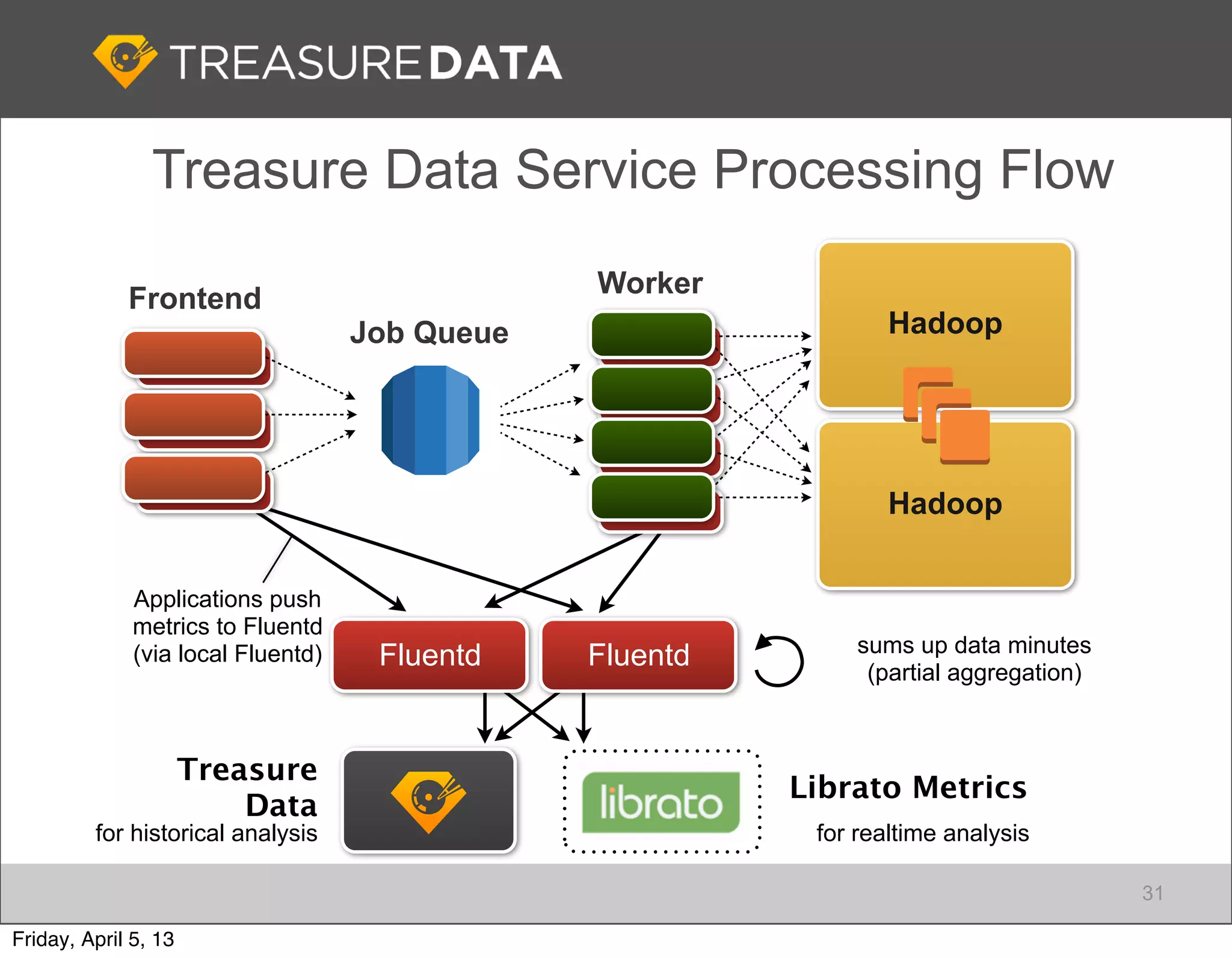
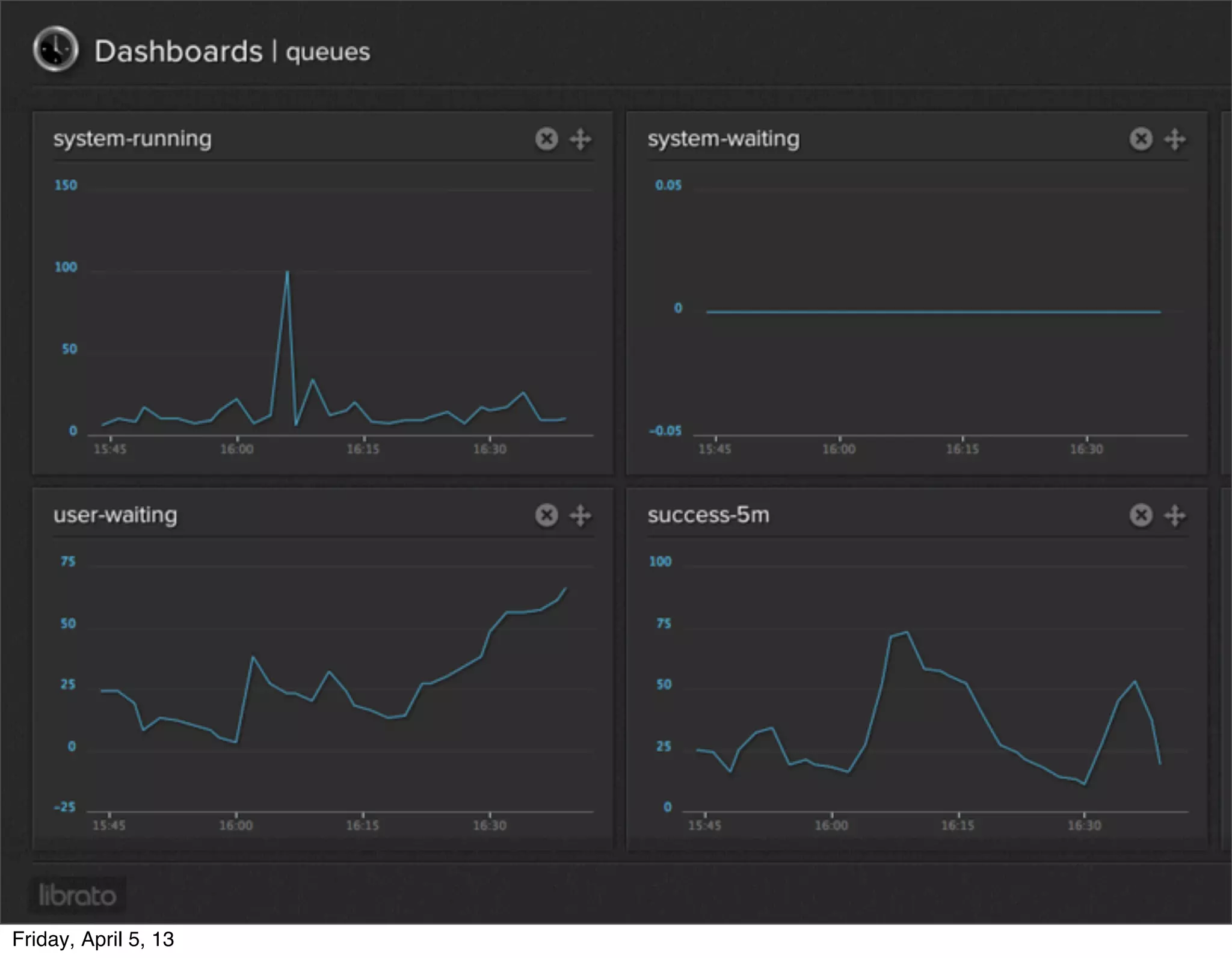
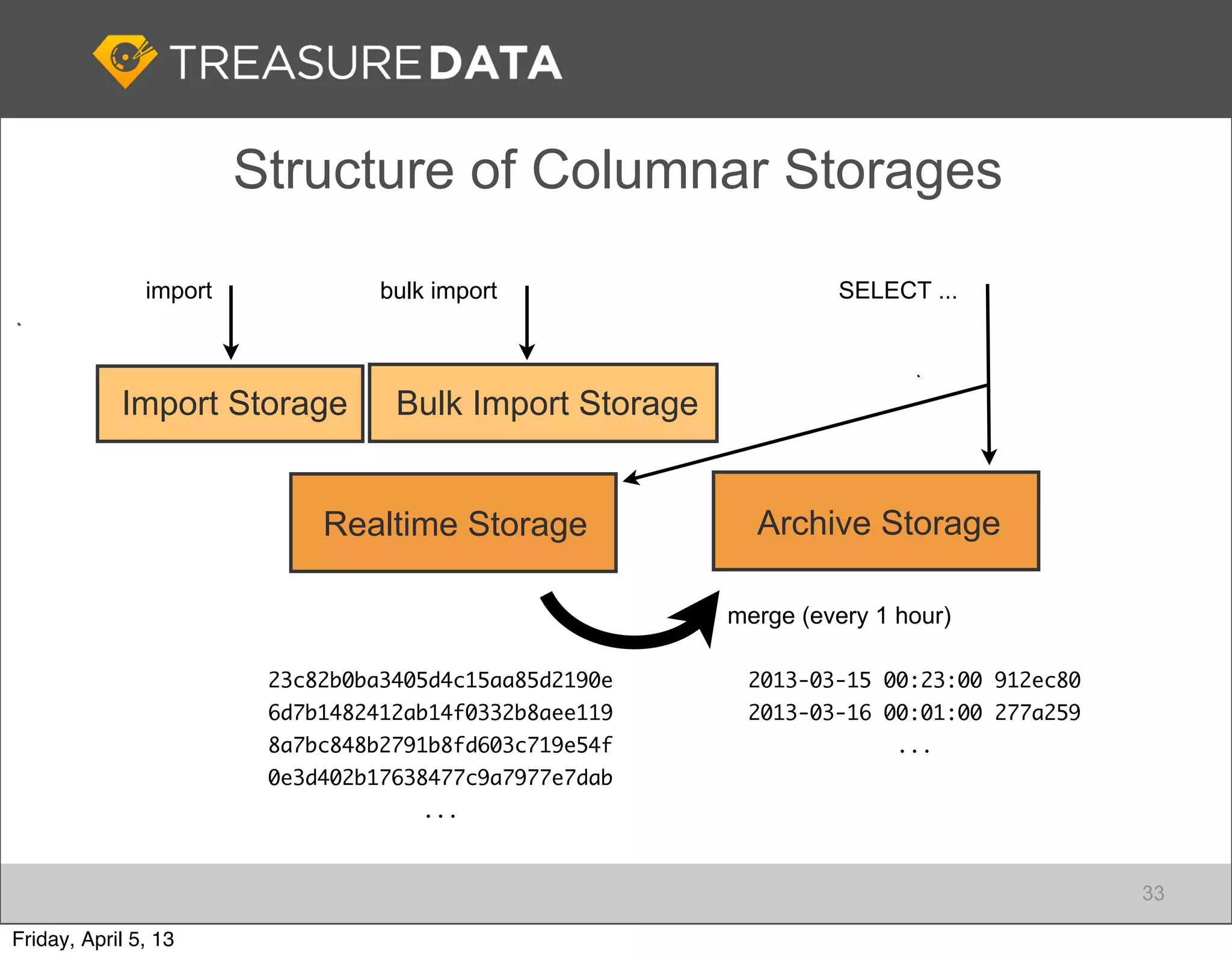
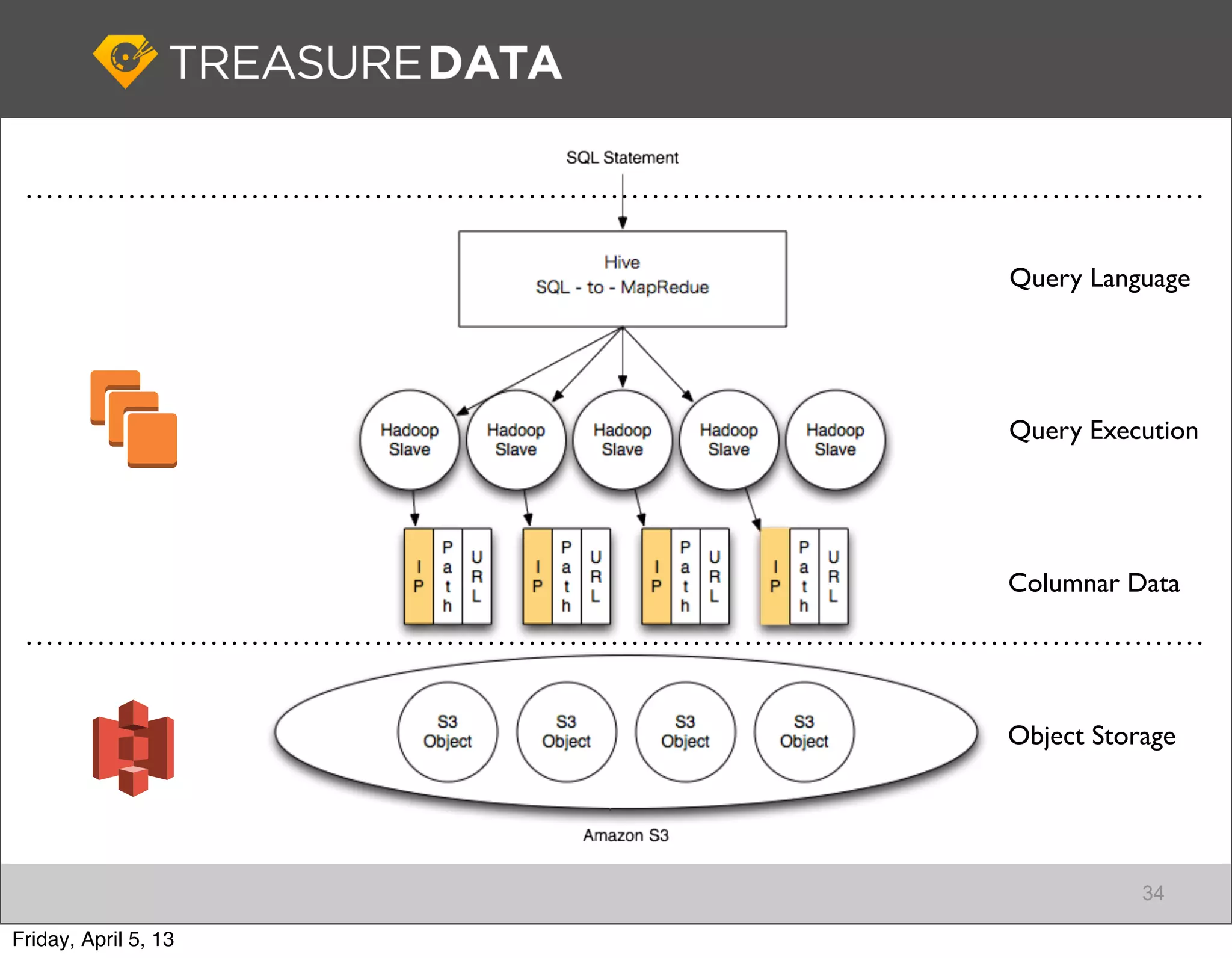
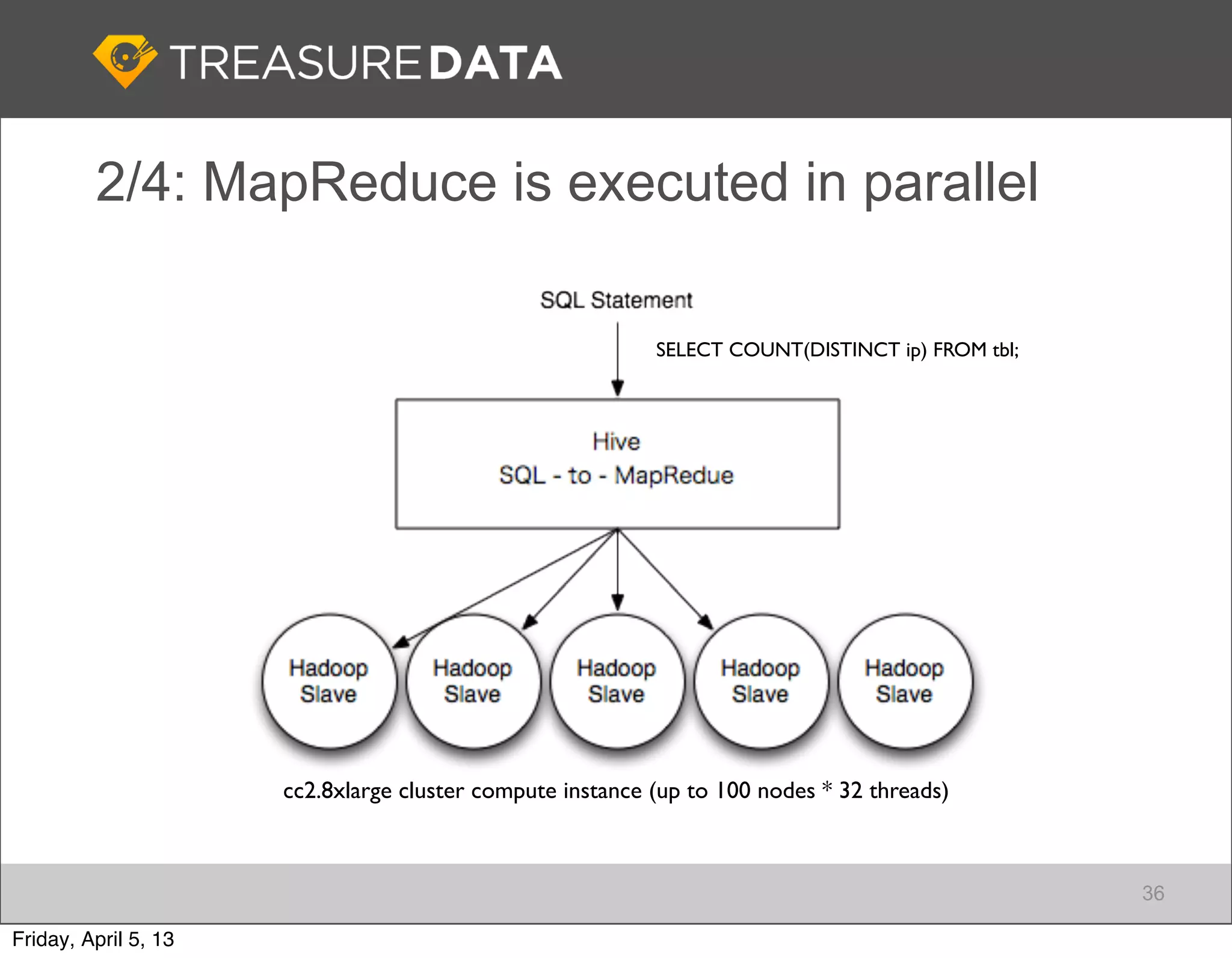
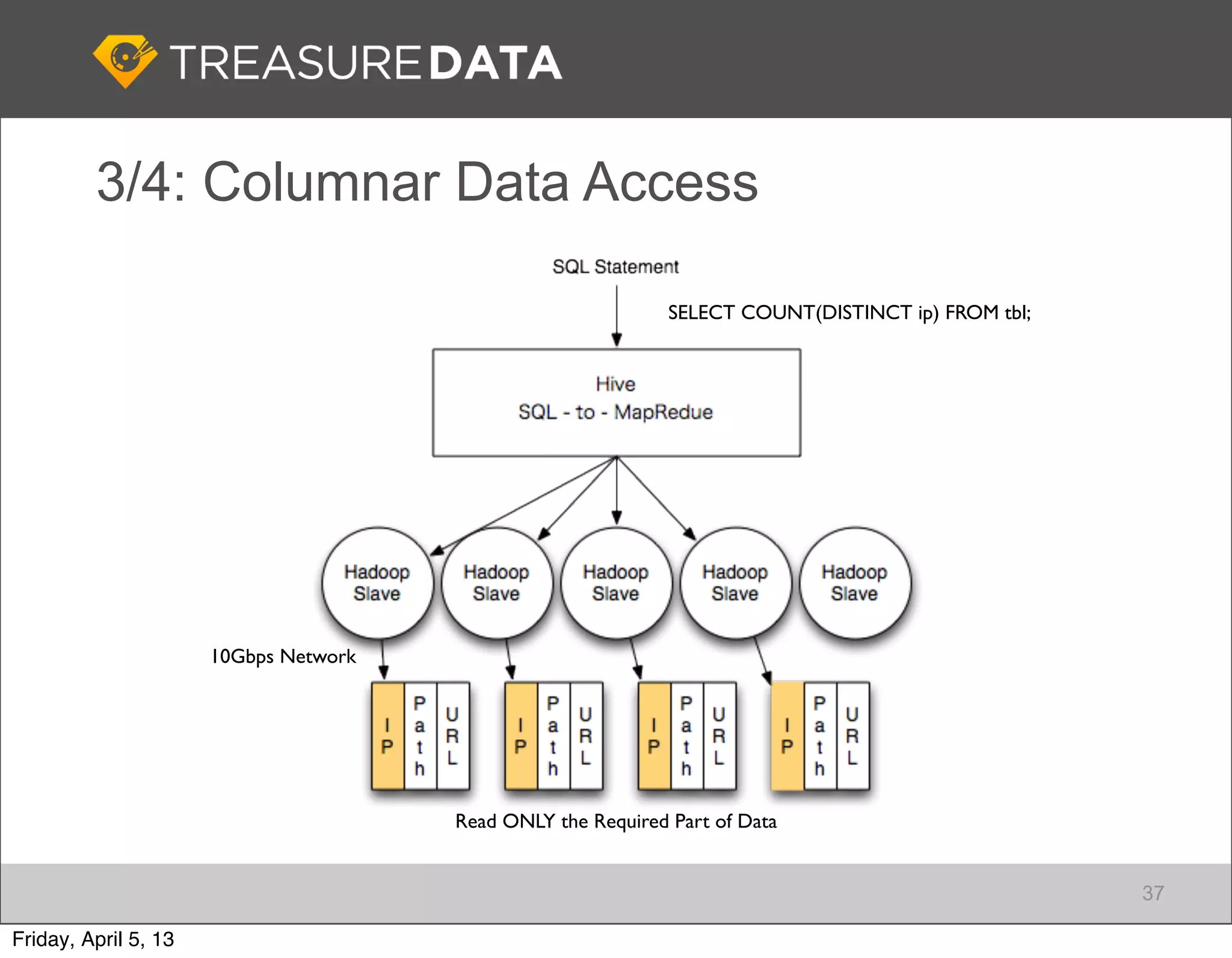
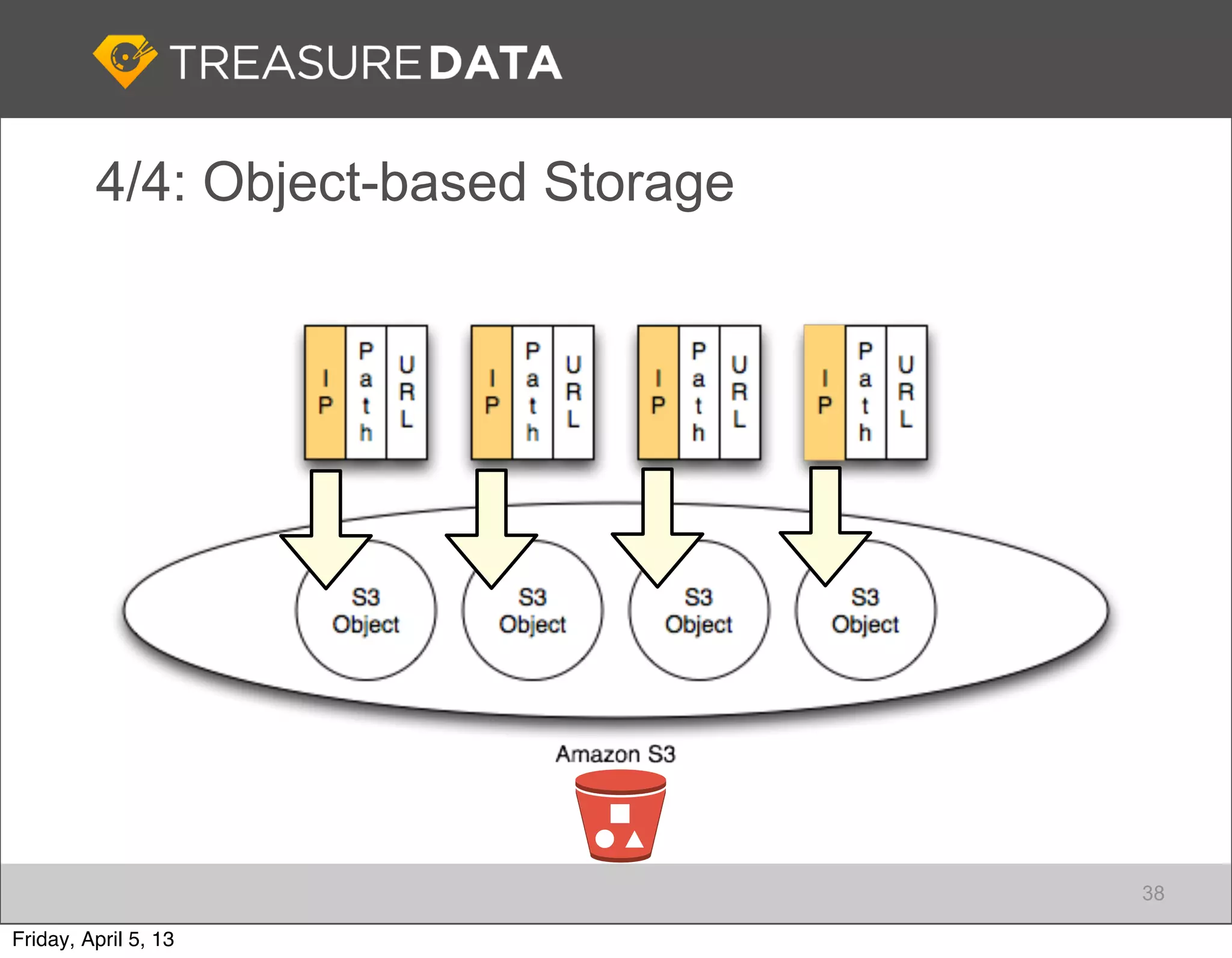
Architecture of Treasure Data service, including data storage and analytics processing using MapReduce.
Focus on data connectivity using APIs and multi-tenancy in Hadoop clusters for optimized resource sharing.
Summarization of Treasure Data’s cloud-based Big Data analytics platform and its capabilities.


























![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)
















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)