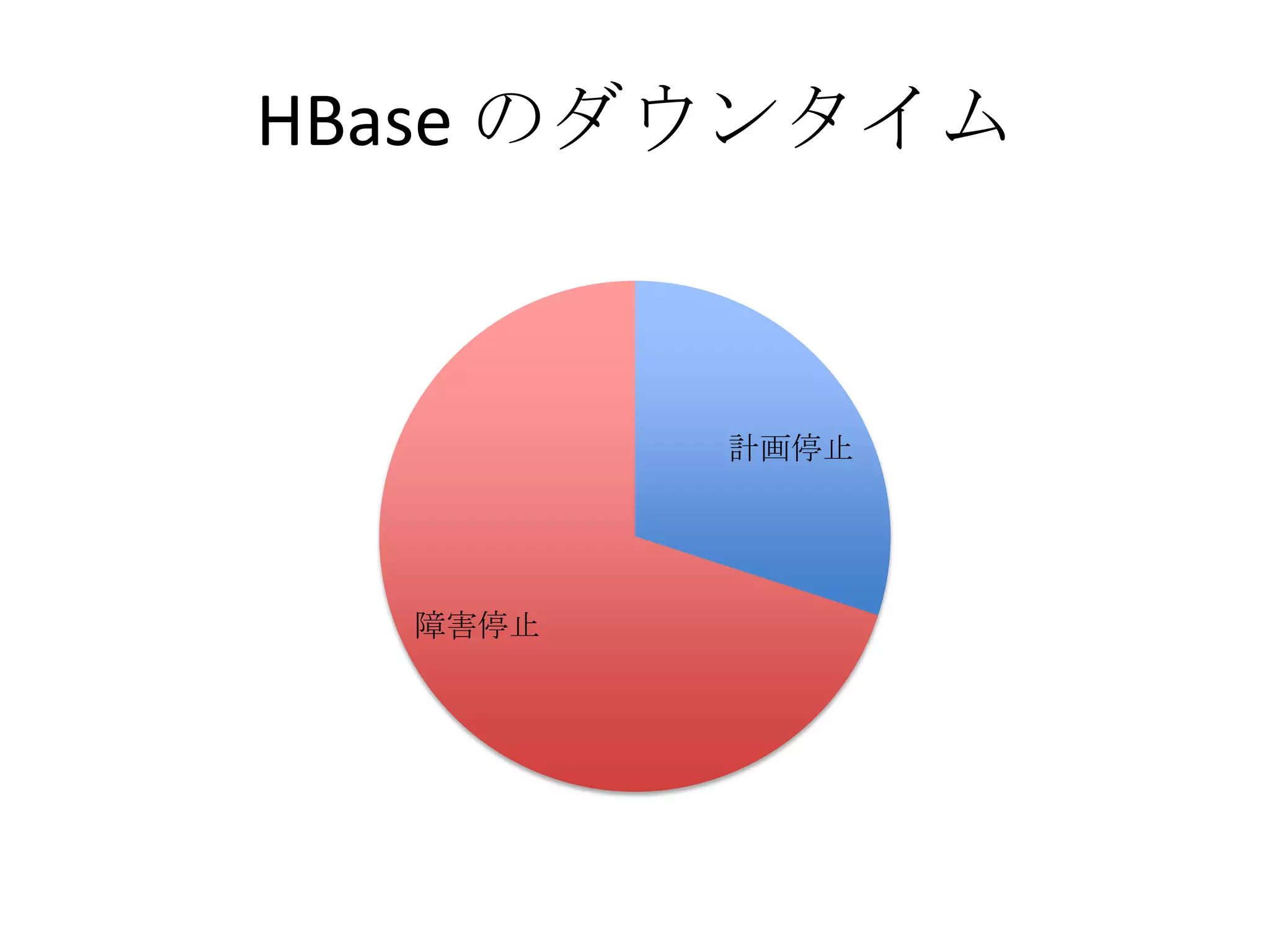
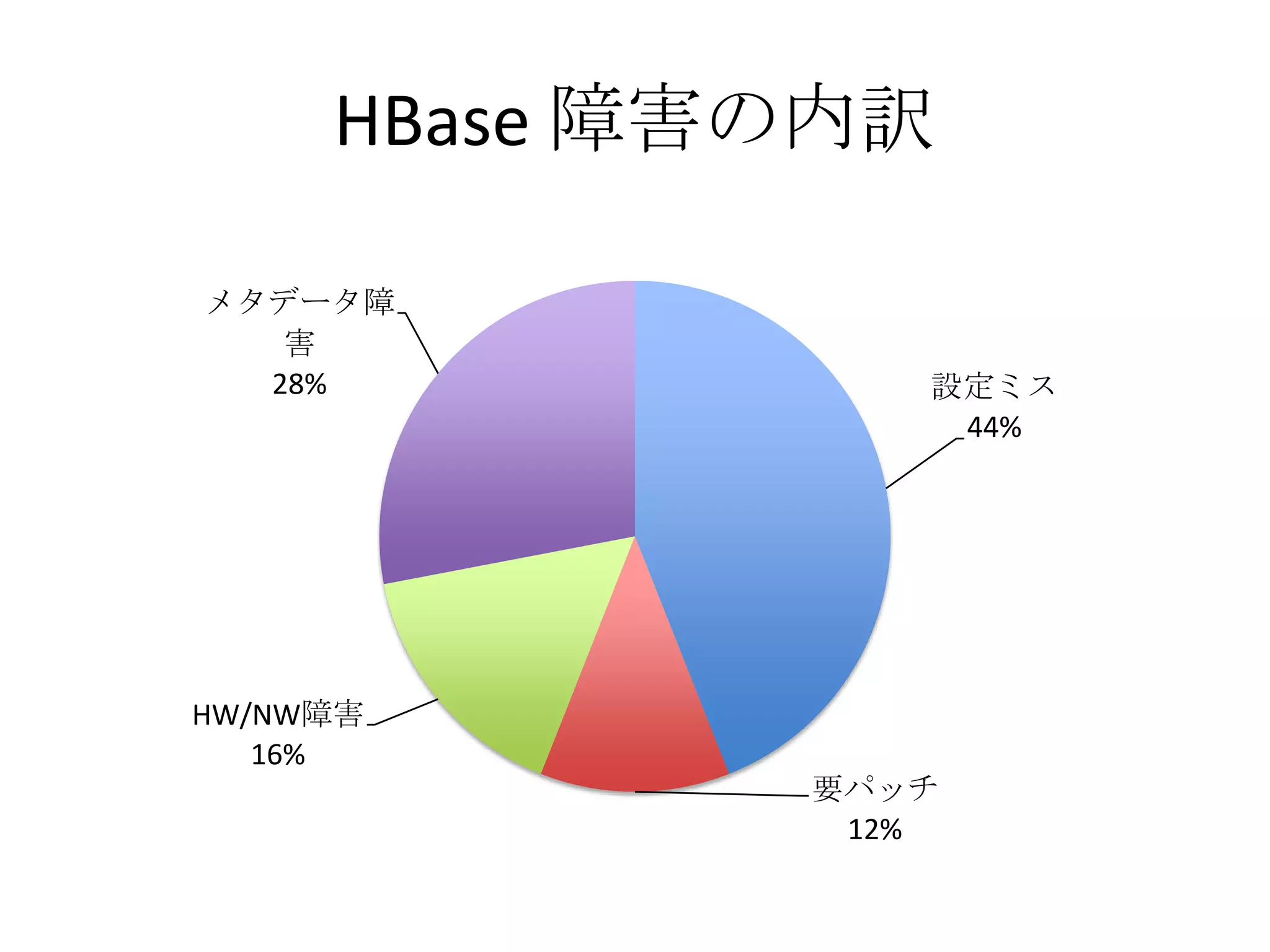
第10回Hadoopソースコードリーディングで発表した資料です。 2012年6月に開催されたHadoop Summit の参加レポートで、YARN、HBase、HDFS HA などのセッションを紹介しています。