





















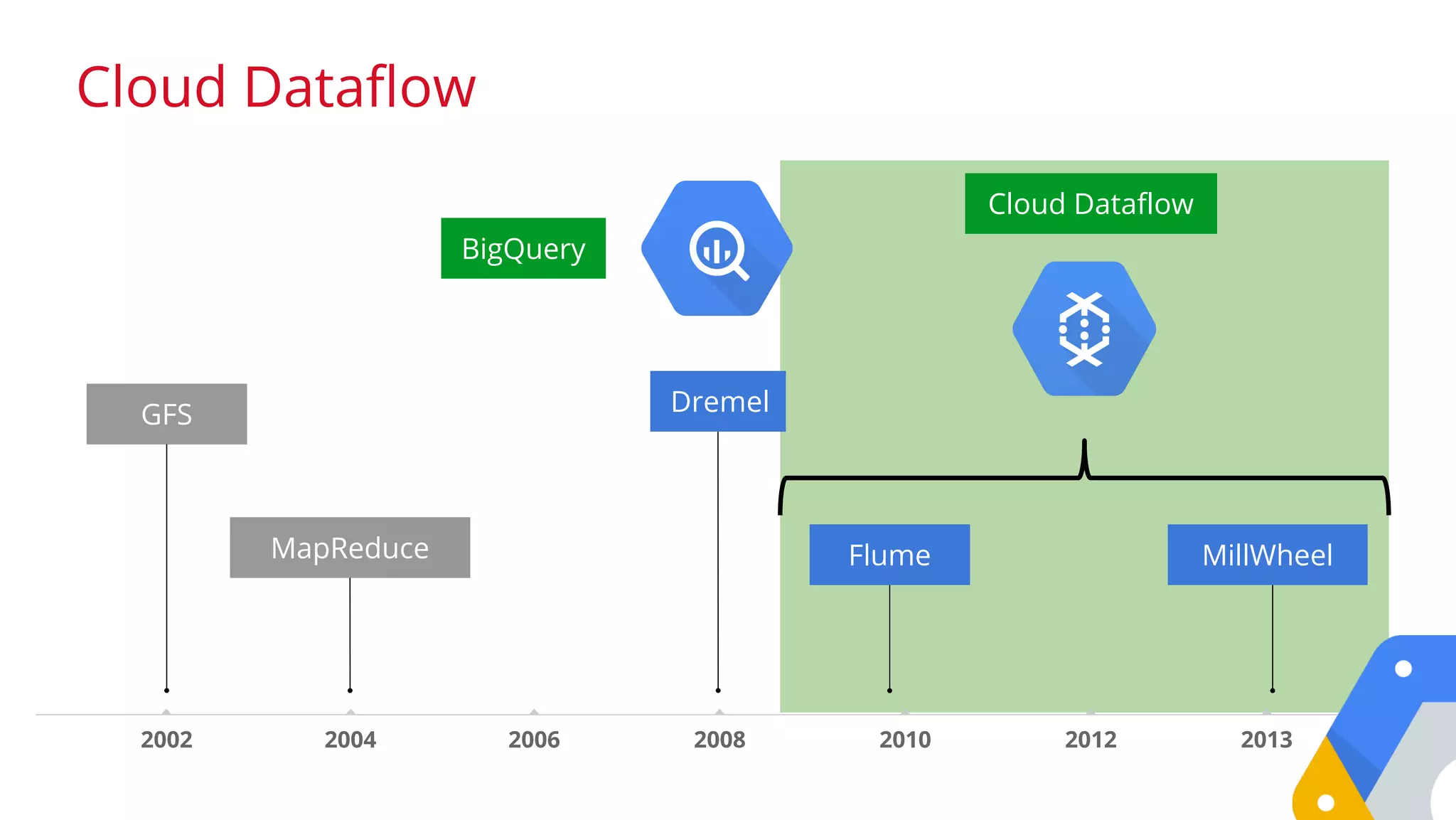
![Google confidential │ Do not distribute
How many pageviews does Wikipedia
have in a month?
SELECT SUM(requests)FROM
[fh-bigquery:wikipedia.pagecounts_201412]
bigquery.cloud.google.com/table/fh-bigquery:wikipedia.pagecounts_201412](https://image.slidesharecdn.com/opendatabigquery-distributioncopy-150918142401-lva1-app6891/75/An-indepth-look-at-Google-BigQuery-Architecture-by-Felipe-Hoffa-of-Google-33-2048.jpg)

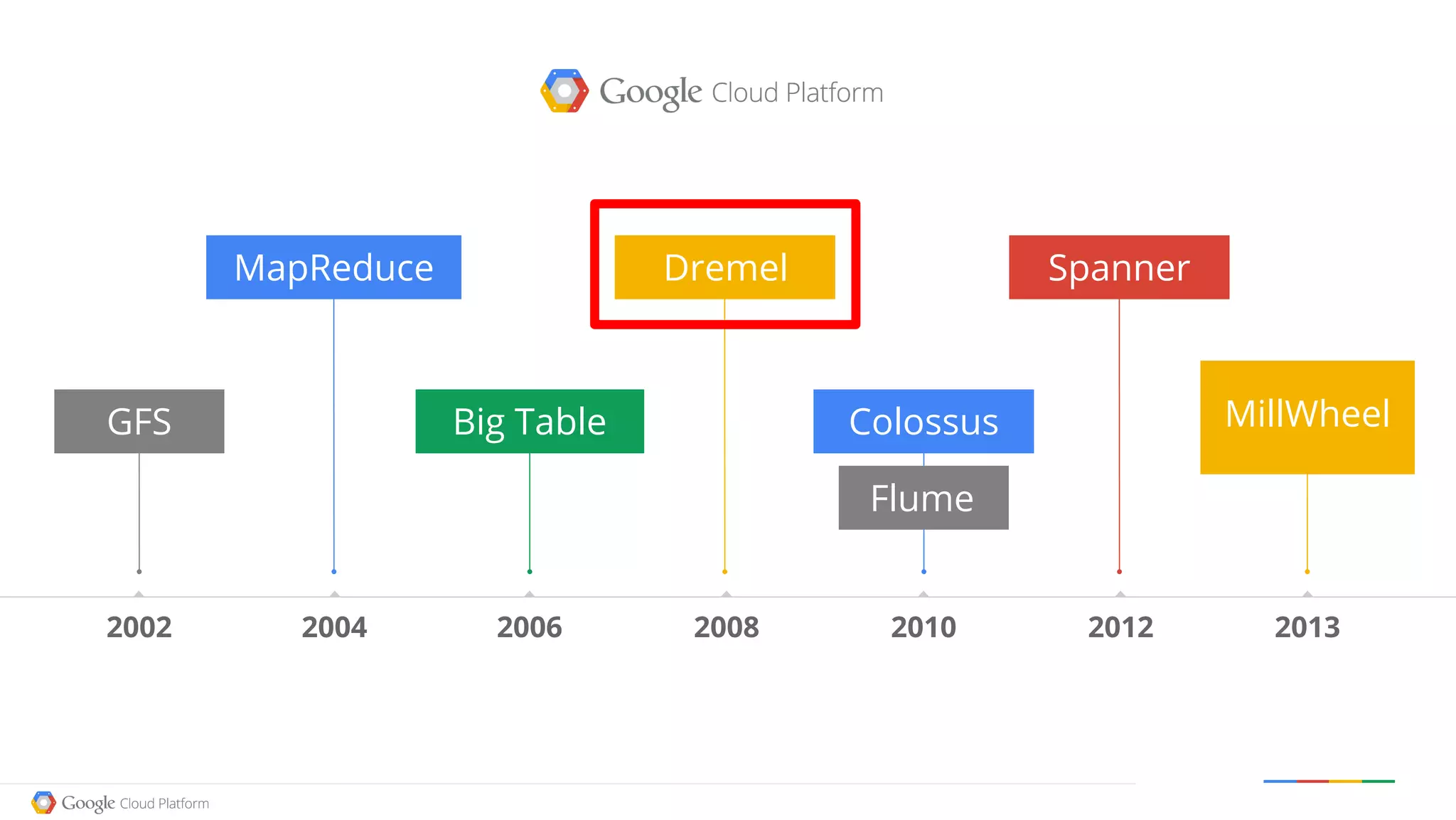
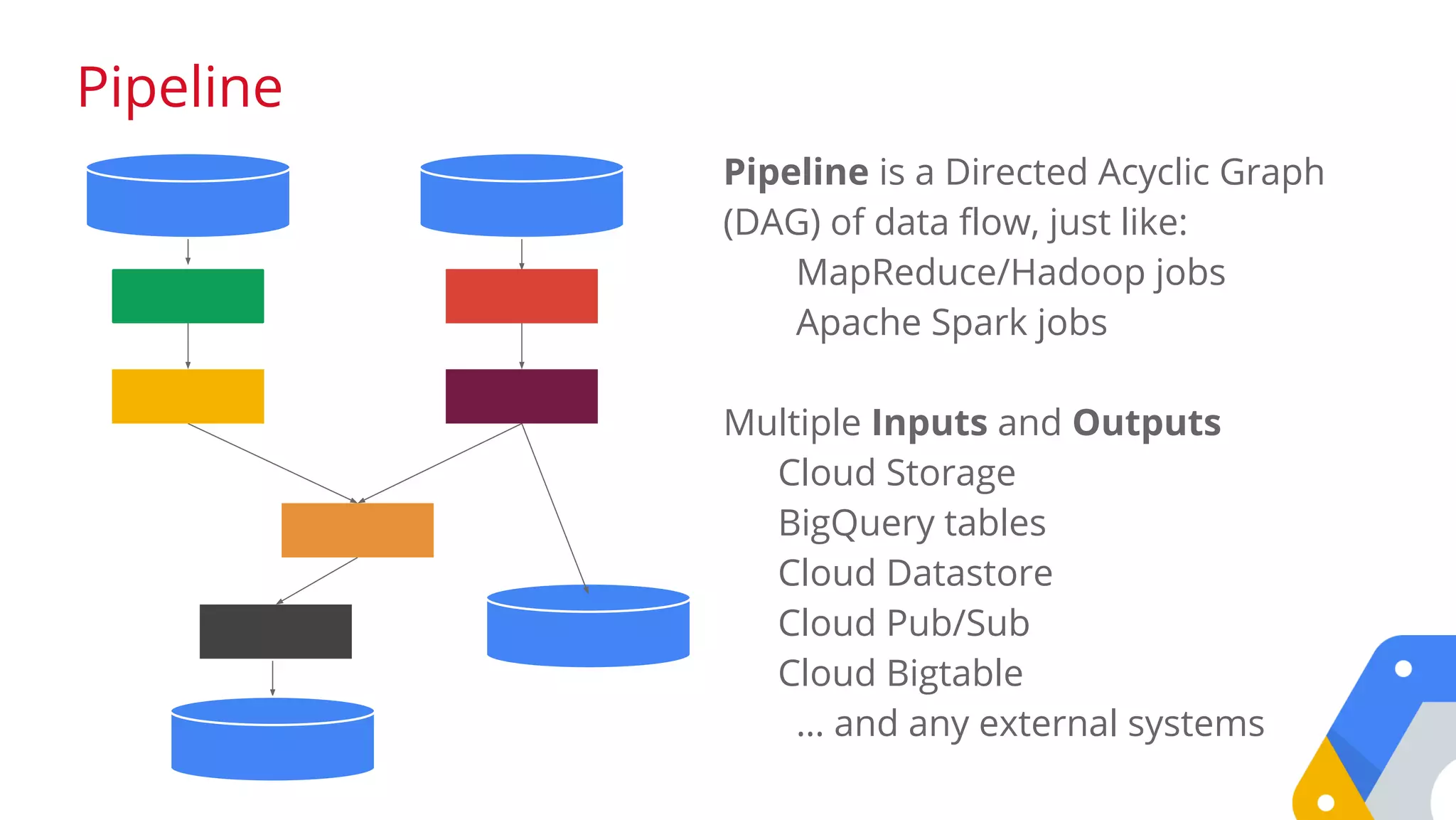
![How BigQuery works
Tree Structured Query Dispatch and Aggregation
Distributed Storage
SELECT state, year
Leaf Leaf Leaf Leaf
O(Rows ~140M)
COUNT(*)
GROUP BY state
WHERE year >= 1980 and year < 1990
Mixer 1 Mixer 1
O(50 states)
COUNT(*)
GROUP BY state
Mixer 0
O(50 states)
LIMIT 10
ORDER BY count_babies DESC
COUNT(*)
GROUP BY state SELECT
state, COUNT(*) count_babies
FROM [publicdata:samples.natality]
WHERE
year >= 1980 AND year < 1990
GROUP BY state
ORDER BY count_babies DESC
LIMIT 10](https://image.slidesharecdn.com/opendatabigquery-distributioncopy-150918142401-lva1-app6891/75/An-indepth-look-at-Google-BigQuery-Architecture-by-Felipe-Hoffa-of-Google-35-2048.jpg)


![SELECT TIMESTAMP(STRING(MonthYear)+'01') month,
SUM(ActionGeo_CountryCode='BR') Brasil
FROM [gdelt-bq:full.events]
WHERE MonthYear>0
GROUP BY 1 ORDER BY 1
GDELT: Rows per month (Brasil)](https://image.slidesharecdn.com/opendatabigquery-distributioncopy-150918142401-lva1-app6891/75/An-indepth-look-at-Google-BigQuery-Architecture-by-Felipe-Hoffa-of-Google-42-2048.jpg)
![SELECT TIMESTAMP(STRING(MonthYear)+'01') month,
SUM(ActionGeo_CountryCode='BR') Brasil
FROM [gdelt-bq:full.events]
WHERE MonthYear>0
GROUP BY 1 ORDER BY 1
GDELT: Rows per month (Brasil)](https://image.slidesharecdn.com/opendatabigquery-distributioncopy-150918142401-lva1-app6891/75/An-indepth-look-at-Google-BigQuery-Architecture-by-Felipe-Hoffa-of-Google-43-2048.jpg)
![SELECT TIMESTAMP(STRING(MonthYear)+'01') month,
SUM(ActionGeo_CountryCode='BR')/COUNT(*) Brasil
FROM [gdelt-bq:full.events]
WHERE MonthYear>0
GROUP BY 1 ORDER BY 1
GDELT: Rows per month (Brasil, normalized)
June 1992
July 2013](https://image.slidesharecdn.com/opendatabigquery-distributioncopy-150918142401-lva1-app6891/75/An-indepth-look-at-Google-BigQuery-Architecture-by-Felipe-Hoffa-of-Google-44-2048.jpg)
![SELECT TIMESTAMP(STRING(MonthYear)+'01') month,
SUM(ActionGeo_CountryCode='CI')/COUNT(*) Chile
FROM [gdelt-bq:full.events]
WHERE MonthYear>0
GROUP BY 1 ORDER BY 1
GDELT: Rows per month (Chile, normalized)](https://image.slidesharecdn.com/opendatabigquery-distributioncopy-150918142401-lva1-app6891/75/An-indepth-look-at-Google-BigQuery-Architecture-by-Felipe-Hoffa-of-Google-45-2048.jpg)
![SELECT TIMESTAMP(STRING(MonthYear)+'01') month,
SUM(ActionGeo_CountryCode='CI')/COUNT(*) Chile
FROM [gdelt-bq:full.events]
WHERE MonthYear>0
GROUP BY 1 ORDER BY 1
GDELT: Rows per month (Chile, normalized)
October 1988
March 2010
October 2010](https://image.slidesharecdn.com/opendatabigquery-distributioncopy-150918142401-lva1-app6891/75/An-indepth-look-at-Google-BigQuery-Architecture-by-Felipe-Hoffa-of-Google-46-2048.jpg)

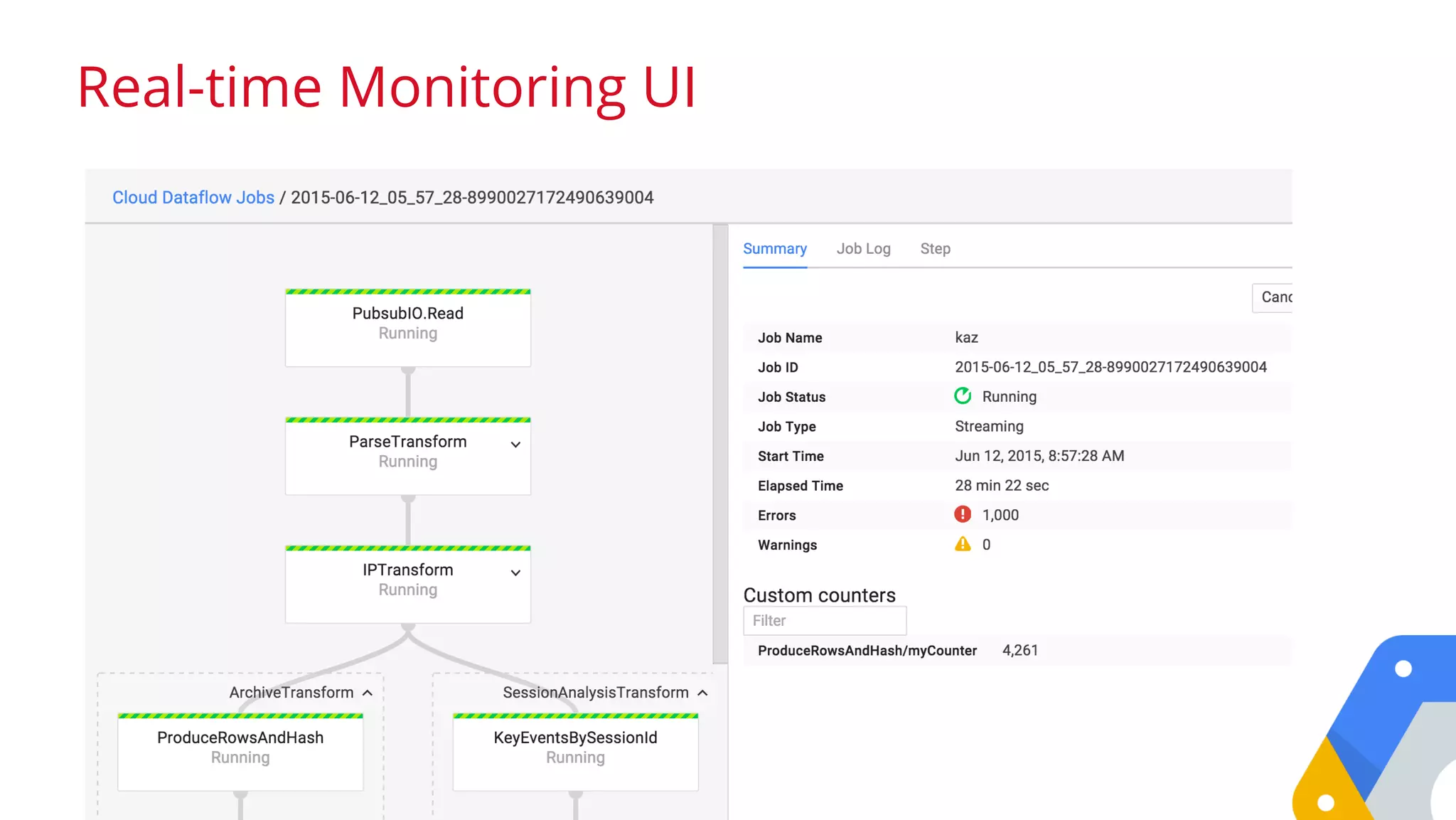
![The Auto Complete Example
Tweets
Predictions
read #argentina scores, my #art project,
watching #armenia vs #argentina
ExtractTags #argentina #art #armenia #argentina
Count (argentina, 5M) (art, 9M) (armenia, 2M)
ExpandPrefixes
a->(argentina,5M) ar->(argentina,5M)
arg->(argentina,5M) ar->(art, 9M) ...
Top(3)
write
a->[apple, art, argentina]
ar->[art, argentina, armenia]
.apply(TextIO.Read.from(...))
.apply(ParDo.of(new ExtractTags()))
.apply(Count.create())
.apply(ParDo.of(new ExpandPrefixes())
.apply(Top.largestPerKey(3)
Pipeline p = Pipeline.create();
p.begin();
.apply(TextIO.Write.to(...));
p.run()](https://image.slidesharecdn.com/opendatabigquery-distributioncopy-150918142401-lva1-app6891/75/An-indepth-look-at-Google-BigQuery-Architecture-by-Felipe-Hoffa-of-Google-52-2048.jpg)

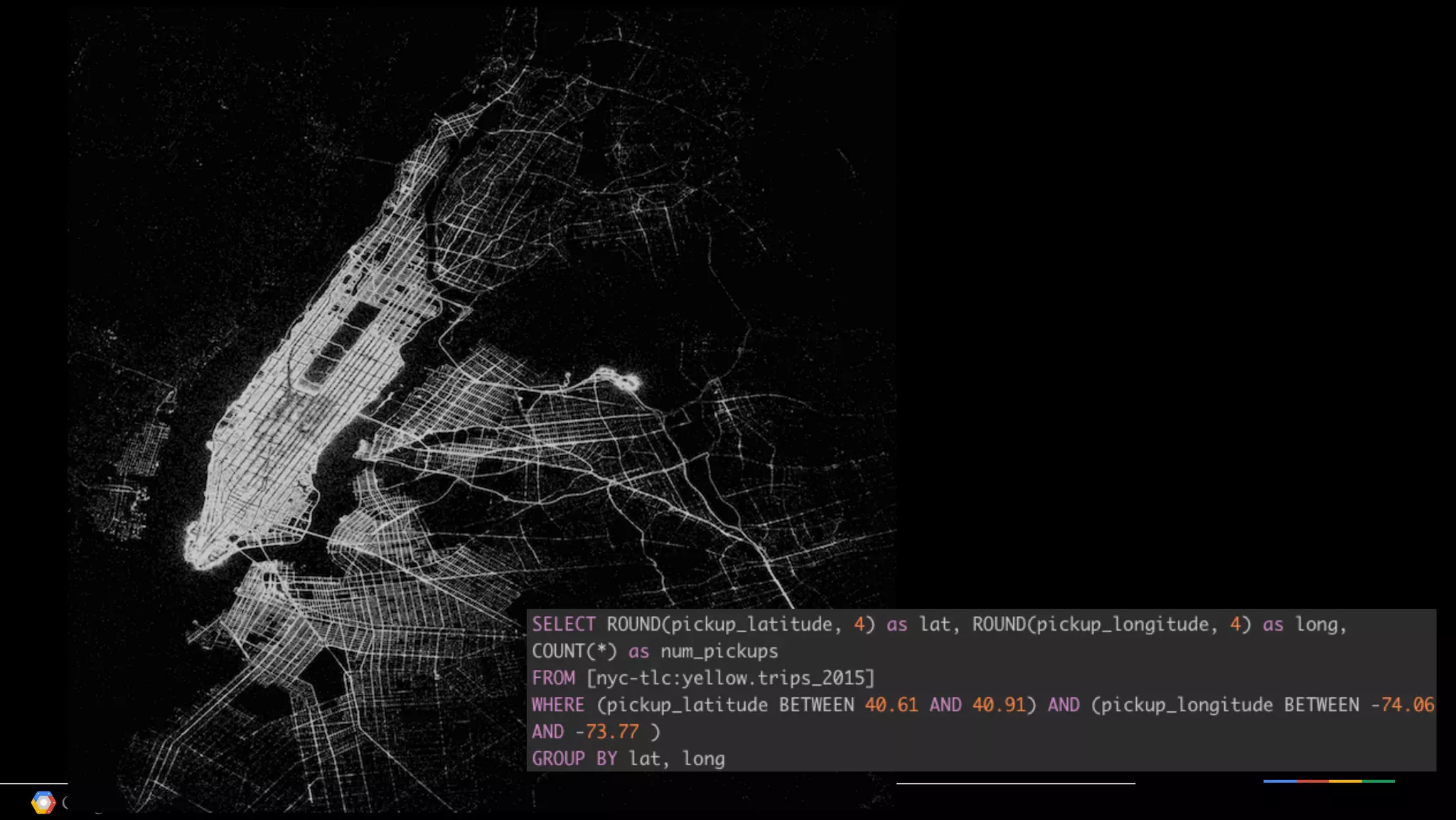
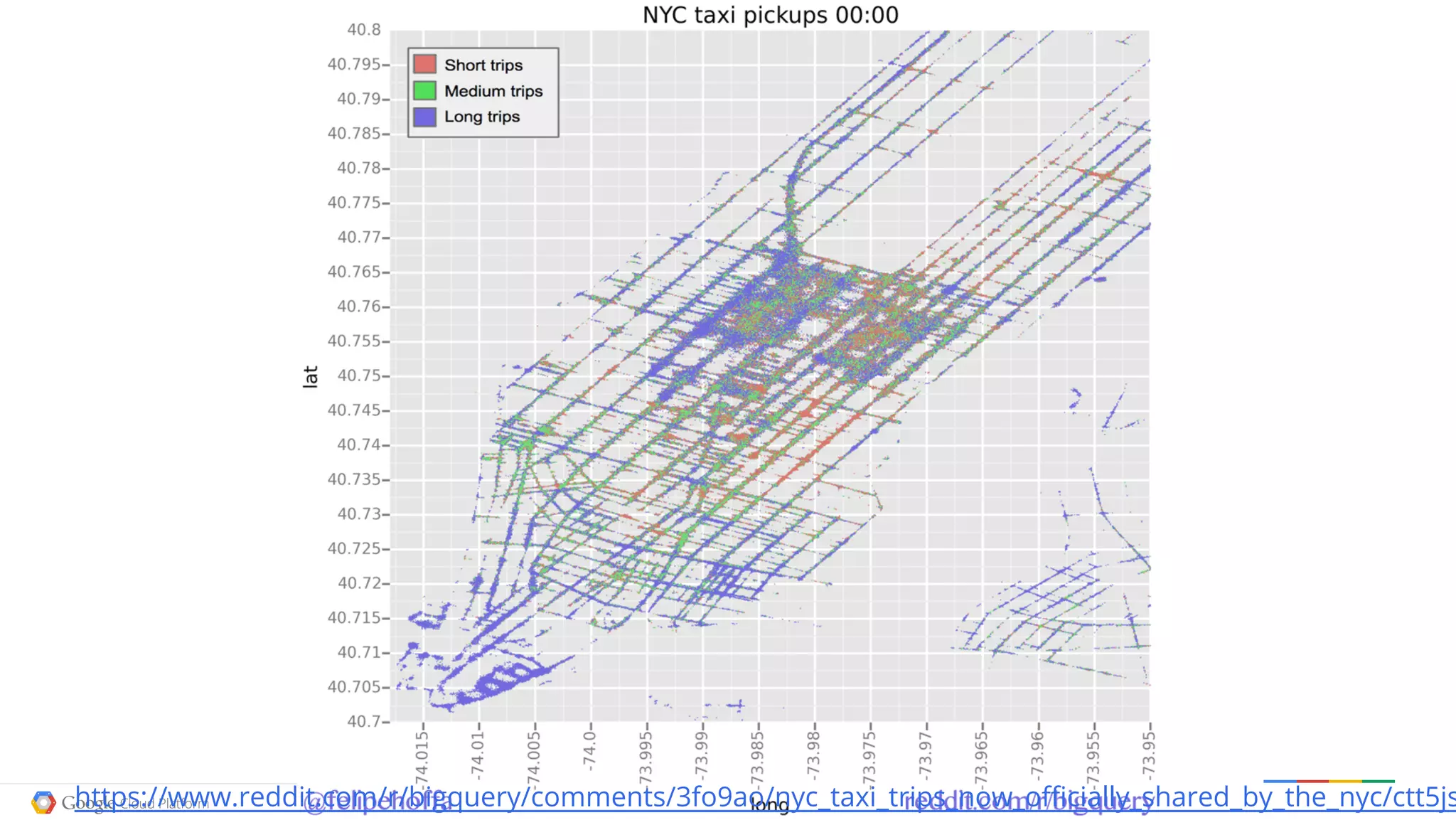

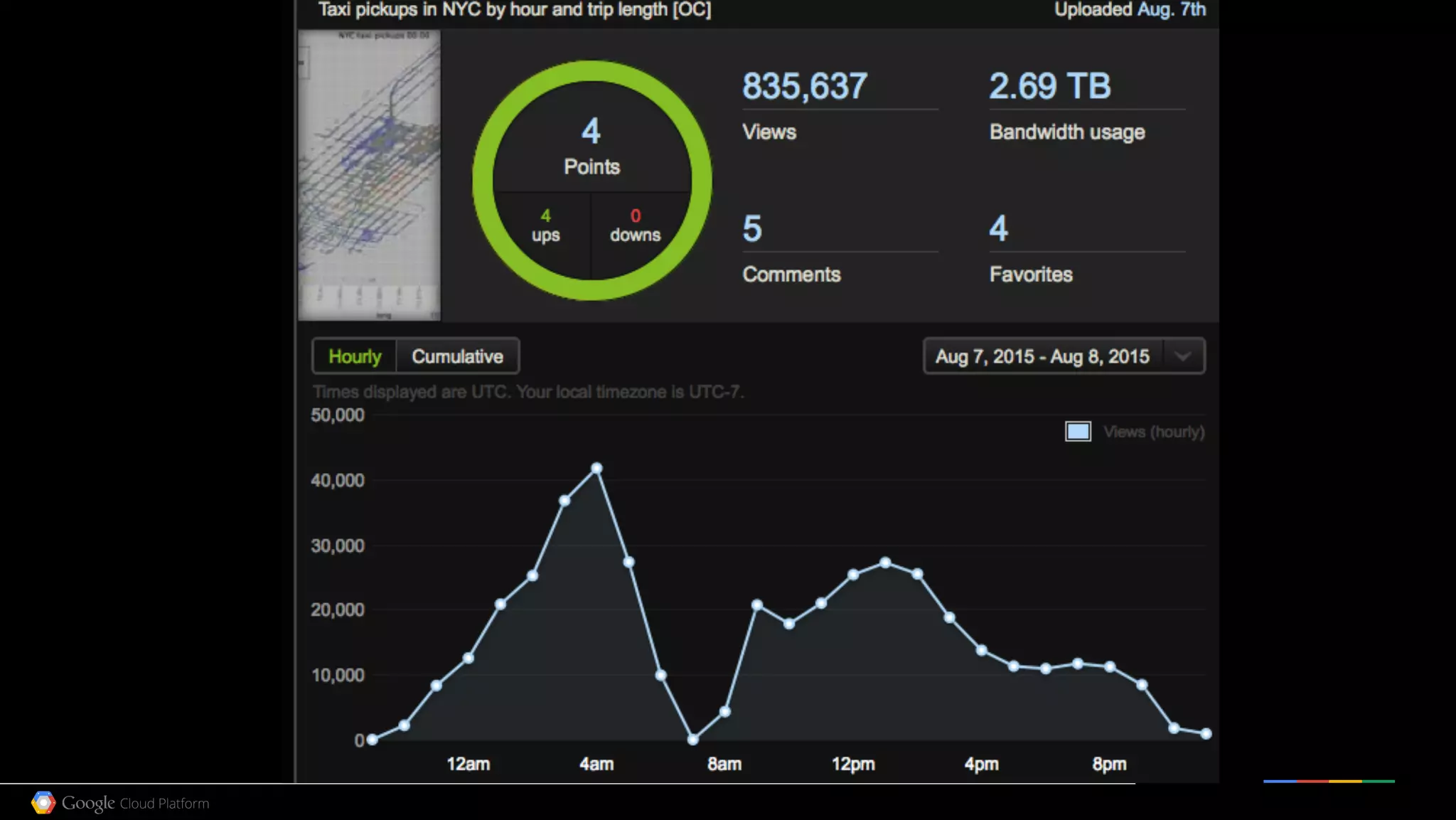

![SELECT TIMESTAMP(year+mo+da) day, min, max, IF(prcp=99.99,0,prcp) prcp
FROM [fh-bigquery:weather_gsod.gsod2014] a
JOIN [fh-bigquery:weather_gsod.stations] b
ON a.wban=b.wban and b.usaf=a.stn
WHERE country='BZ' AND name='RIO DE JANEIRO /AER'
ORDER BY 1
Weather in Rio de Janeiro, 2014](https://image.slidesharecdn.com/opendatabigquery-distributioncopy-150918142401-lva1-app6891/75/An-indepth-look-at-Google-BigQuery-Architecture-by-Felipe-Hoffa-of-Google-67-2048.jpg)




![Age distribution
SELECT age, COUNT(*) c
FROM [compute_ages ]
WHERE age
BETWEEN 1 AND 80
GROUP BY 1
ORDER BY 1](https://image.slidesharecdn.com/opendatabigquery-distributioncopy-150918142401-lva1-app6891/75/An-indepth-look-at-Google-BigQuery-Architecture-by-Felipe-Hoffa-of-Google-72-2048.jpg)
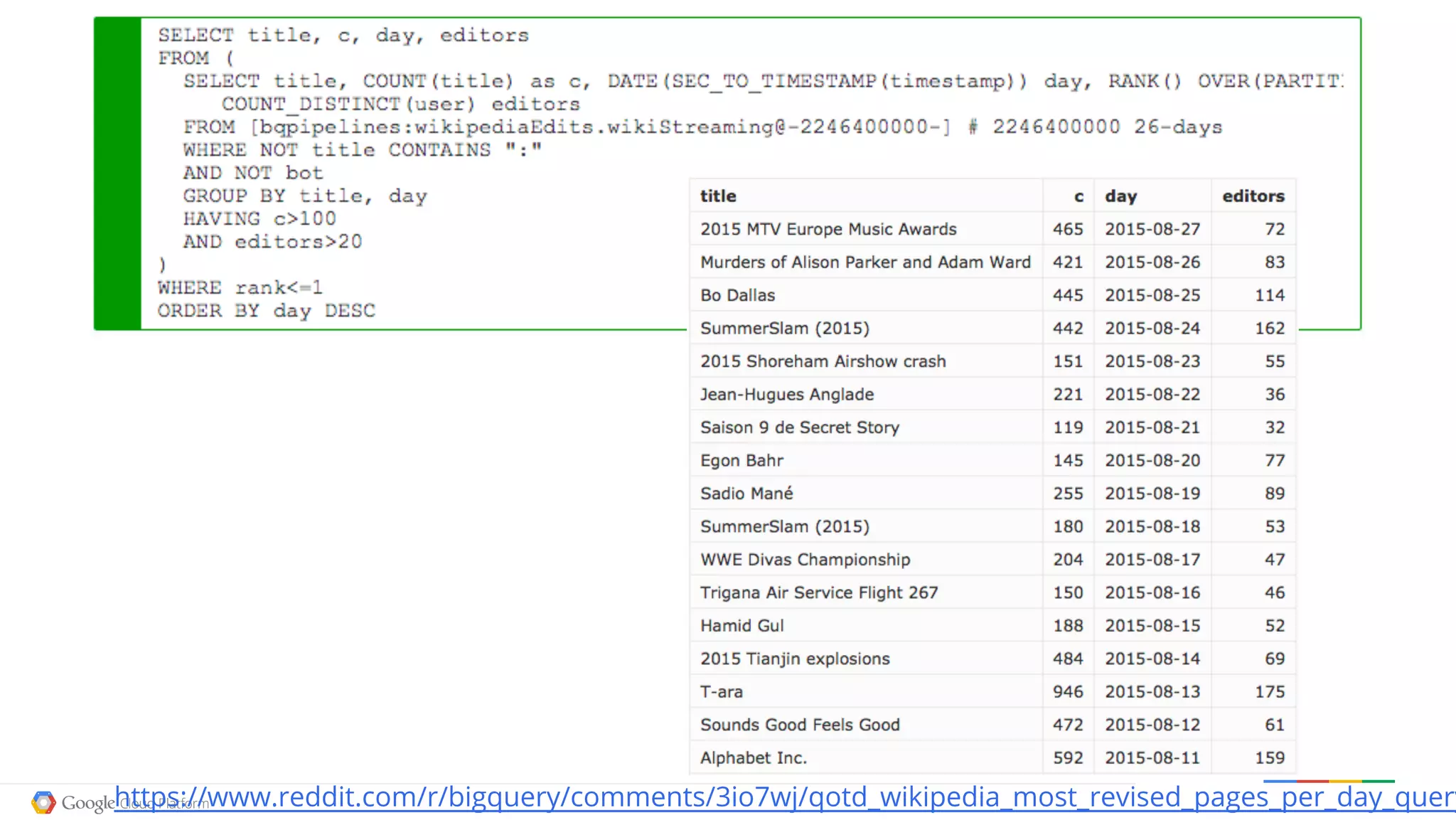
![SELECT title, count, iso FROM (
SELECT title, count, c.iso iso, RANK() OVER (PARTITION BY iso ORDER BY count DESC) rank
FROM (
SELECT a.title title, SUM(requests) count, b.person person
FROM [fh-bigquery:wikipedia.pagecounts_20140410_150000] a
JOIN (
SELECT REGEXP_REPLACE(obj, '/wikipedia/id/', '') title, a.sub person
FROM [fh-bigquery:freebase20140119.triples_nolang] a
JOIN (
SELECT sub FROM [fh-bigquery:freebase20140119.people_gender]
WHERE gender='/m/02zsn') b
ON a.sub=b.sub
WHERE obj CONTAINS '/wikipedia/id/' AND pred = '/type/object/key'
GROUP BY 1,2) b
ON a.title = b.title
GROUP BY 1,3) a
JOIN EACH [fh-bigquery:freebase20140119.people_place_of_birth] b
ON a.person=b.sub
JOIN [fh-bigquery:freebase20140119.place_of_birth_to_country] c
ON b.place_of_birth=c.place)
WHERE rank=1 ORDER BY count DESC
http://devnook.github.io/GenderMaps/maplabels/](https://image.slidesharecdn.com/opendatabigquery-distributioncopy-150918142401-lva1-app6891/75/An-indepth-look-at-Google-BigQuery-Architecture-by-Felipe-Hoffa-of-Google-74-2048.jpg)

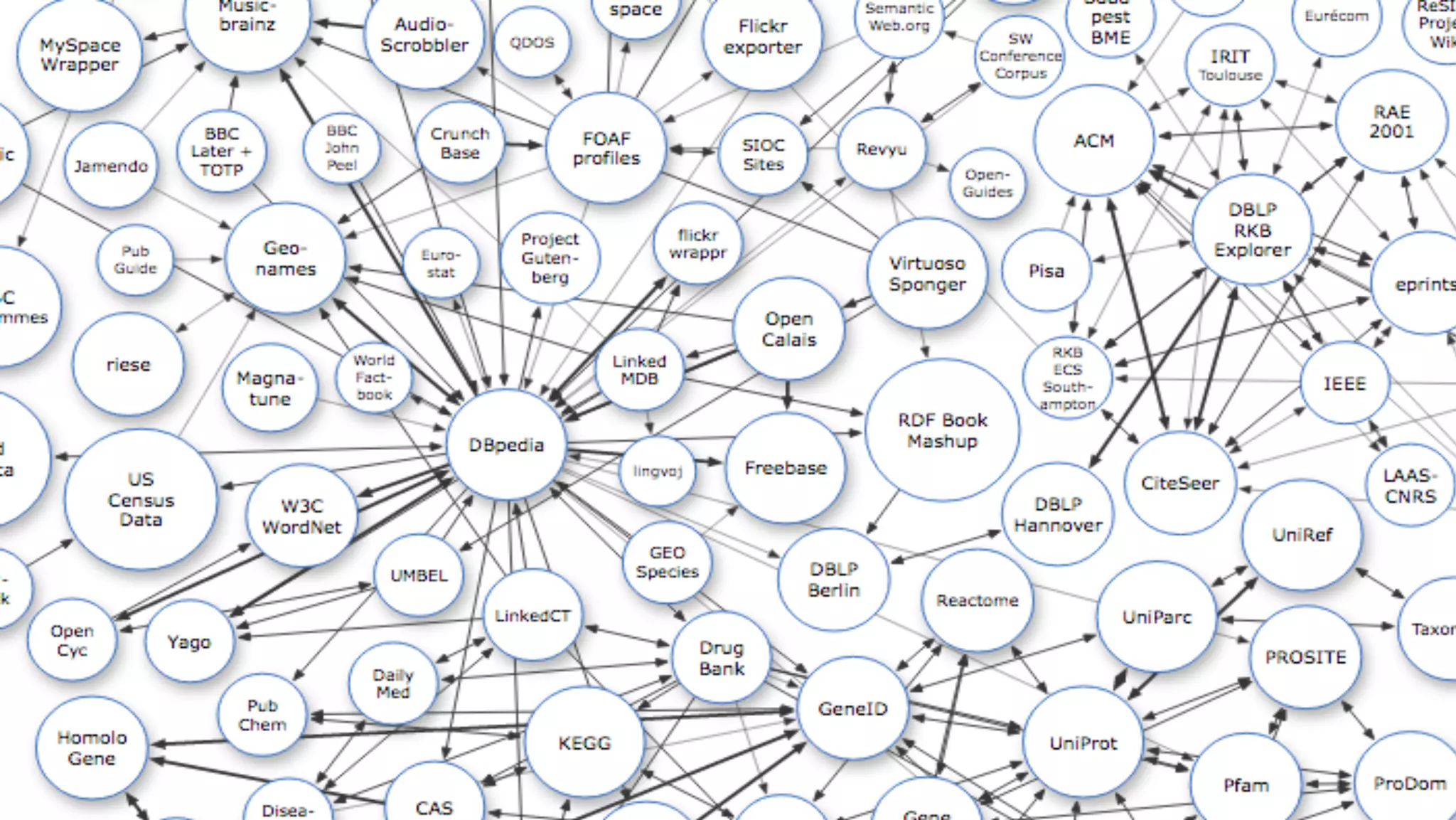
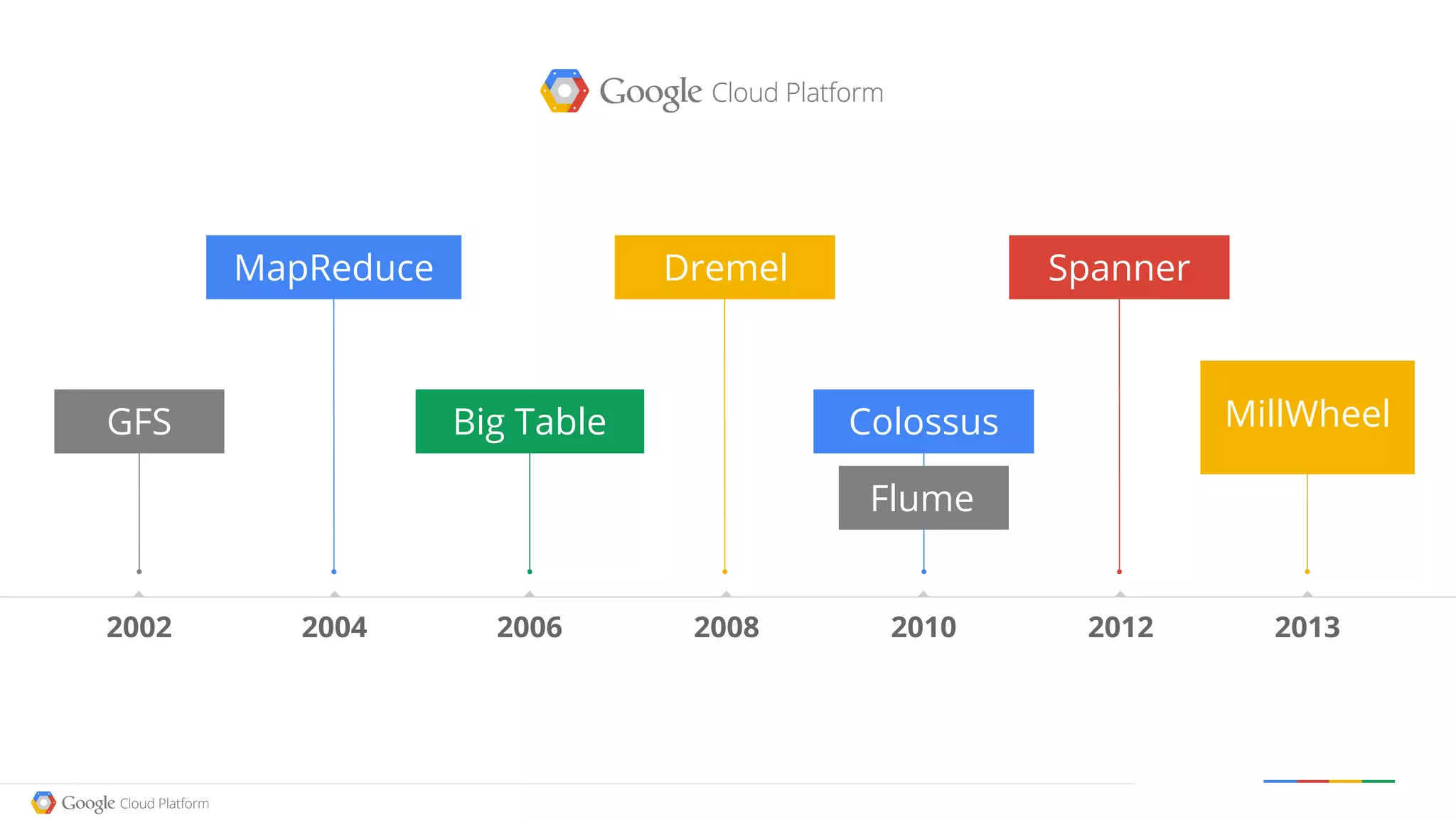
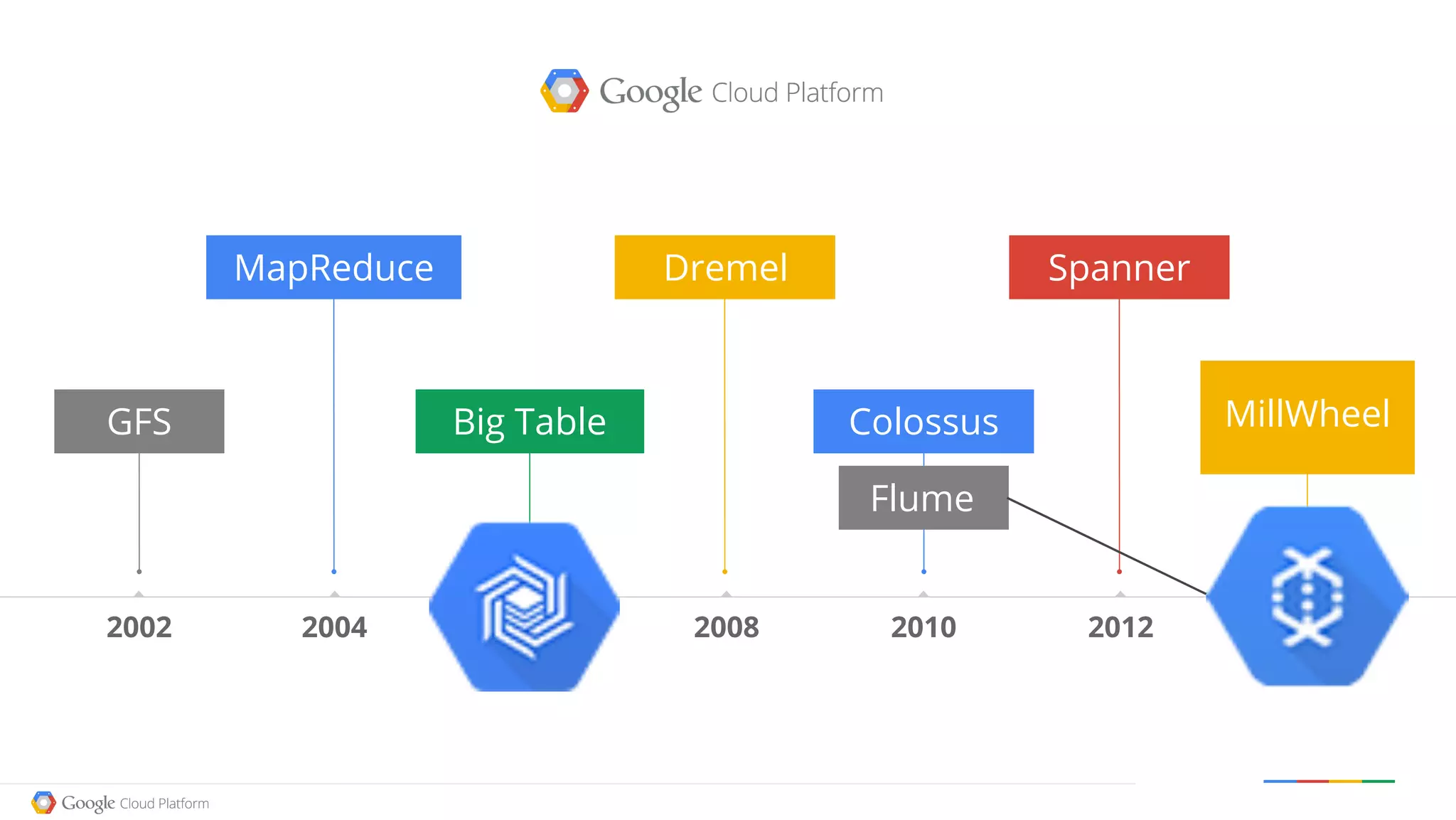
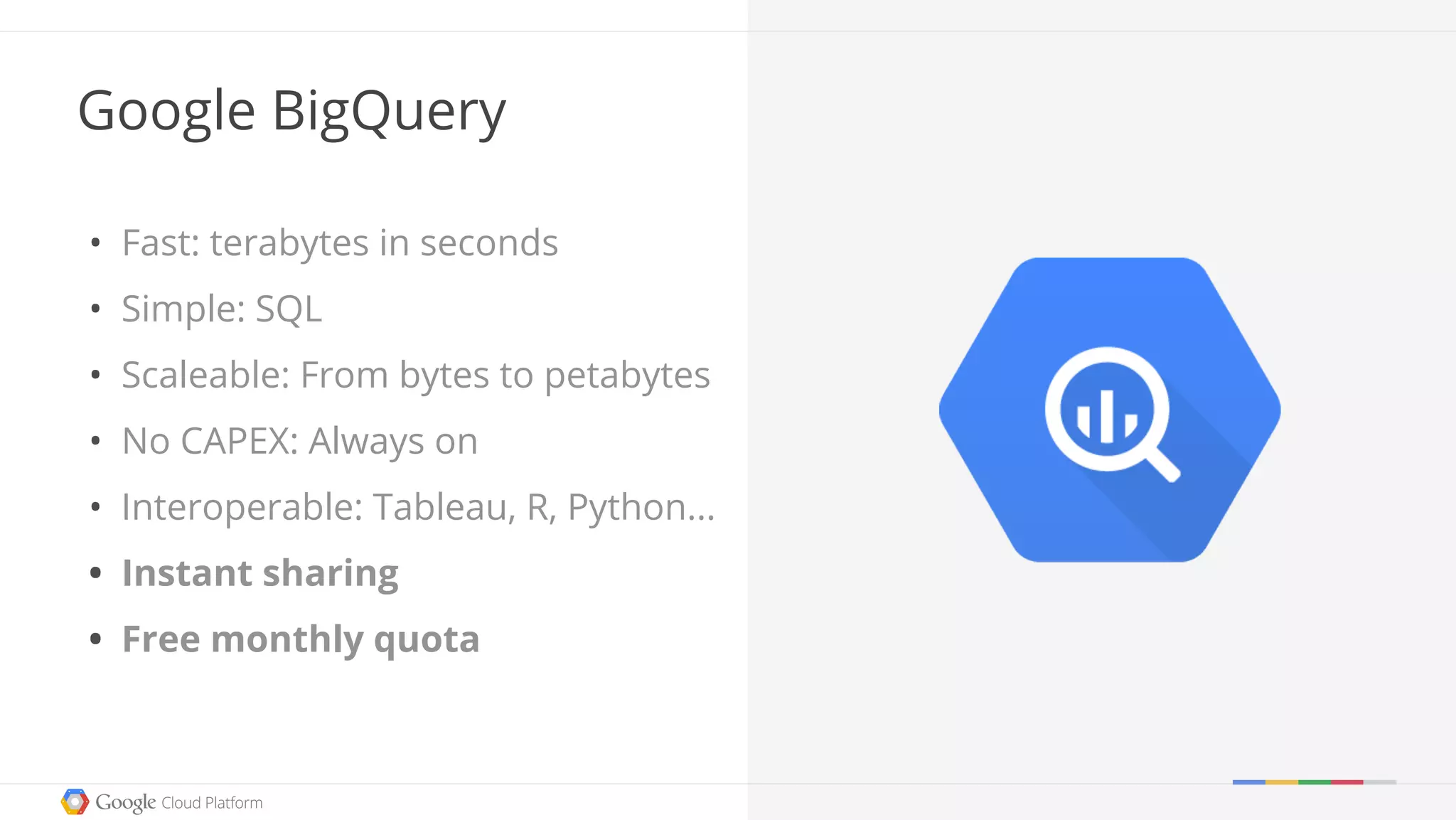
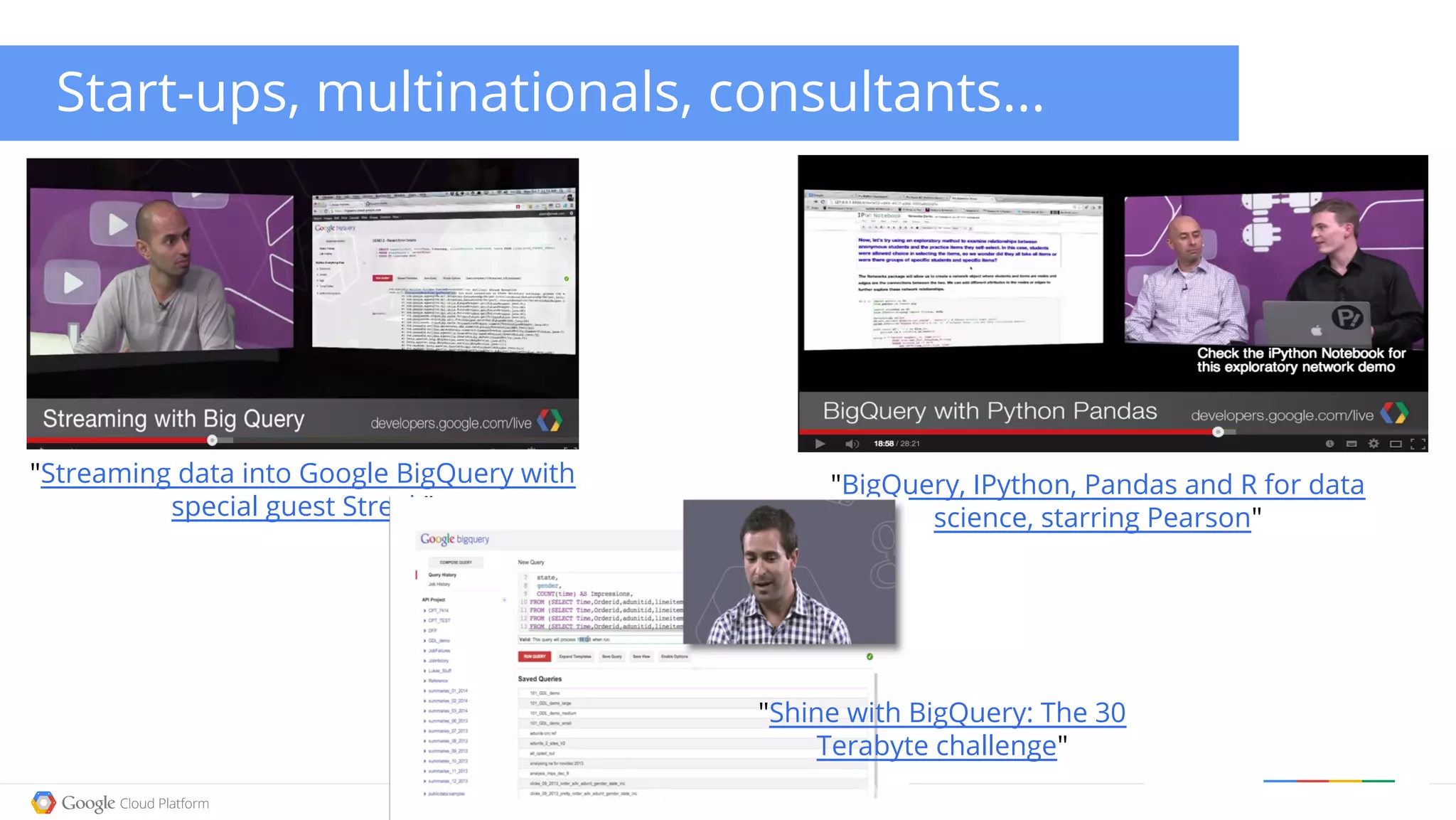
The document discusses the current state and advancements in big data on cloud platforms, particularly focusing on Google BigQuery. It highlights key features such as speed, scalability, and ease of use for various data applications, including analytics and real-time monitoring. Additionally, it emphasizes the historical development of search engines and the significance of open data in relation to big data technologies.























































































