Downloaded 23 times






![Update v1
• Use $inc to
update fields in-
place
increment = { daily: 1 }
increment['hourly.' + hour] = 1
increment['minute.' + minute] = 1
• Use upsert to
db.stats.update(
{ _id: id, metadata: metadata },
create document
{ $inc: update }, if it’s missing
true) // upsert
• Easy, correct,
seems like a good
idea....](https://image.slidesharecdn.com/schemadesignatscale-120725122529-phpapp02/75/Schema-Design-at-Scale-7-2048.jpg)













![Queries
db.stats.daily.find( { • Updates are by
"metadata.date": { $gte: dt1, $lte: dt2 },
"metadata.metric": "metric-1"},
_id, so no index
{ "metadata.date": 1, "hourly": 1 } }, needed there
sort=[("metadata.date", 1)])
• Chart queries are
by metadata
db.stats.daily.ensureIndex({
'metadata.metric': 1,
• Your range/sort
'metadata.date': 1 }) should be last in
the compound
index](https://image.slidesharecdn.com/schemadesignatscale-120725122529-phpapp02/75/Schema-Design-at-Scale-31-2048.jpg)



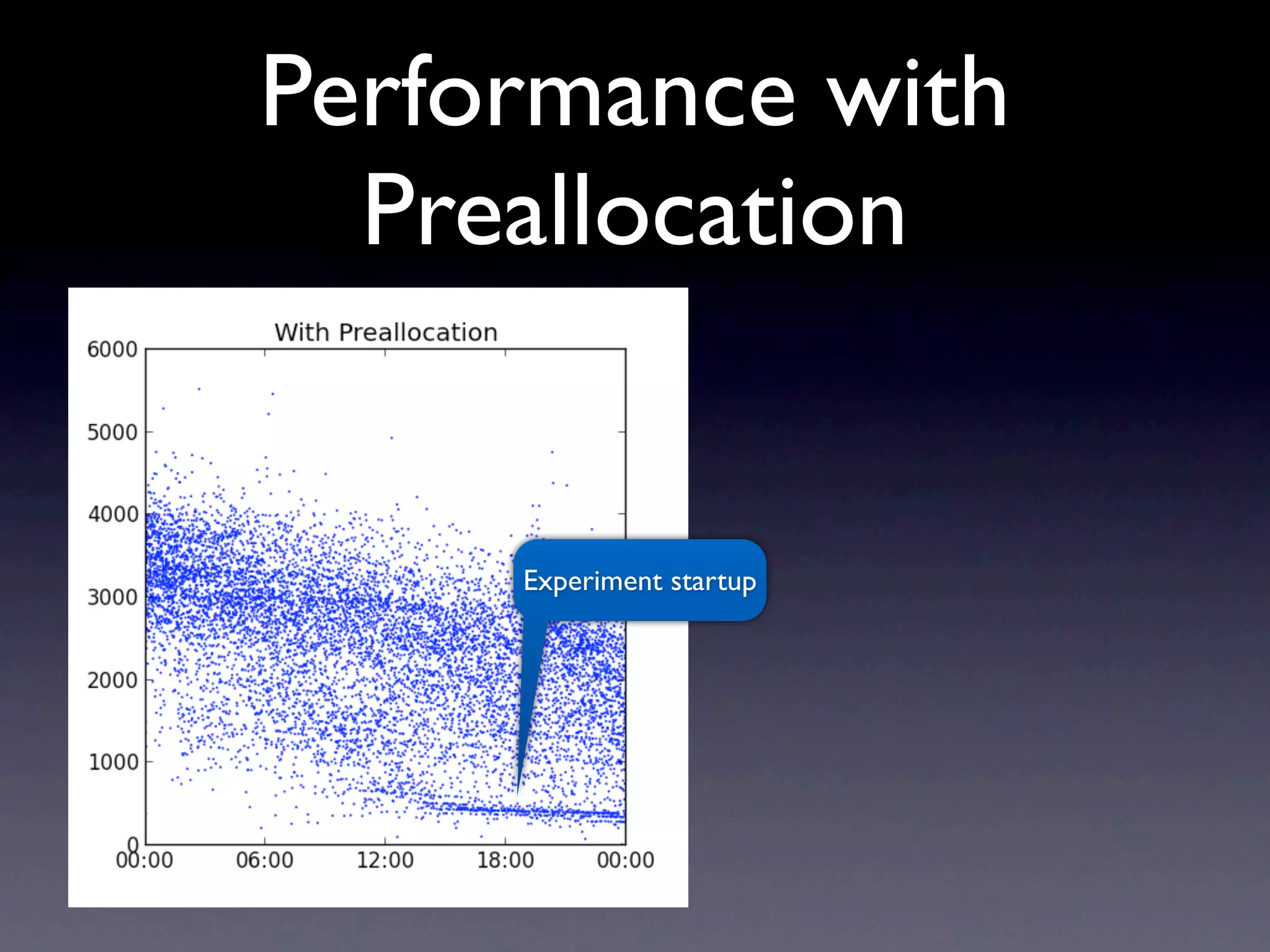
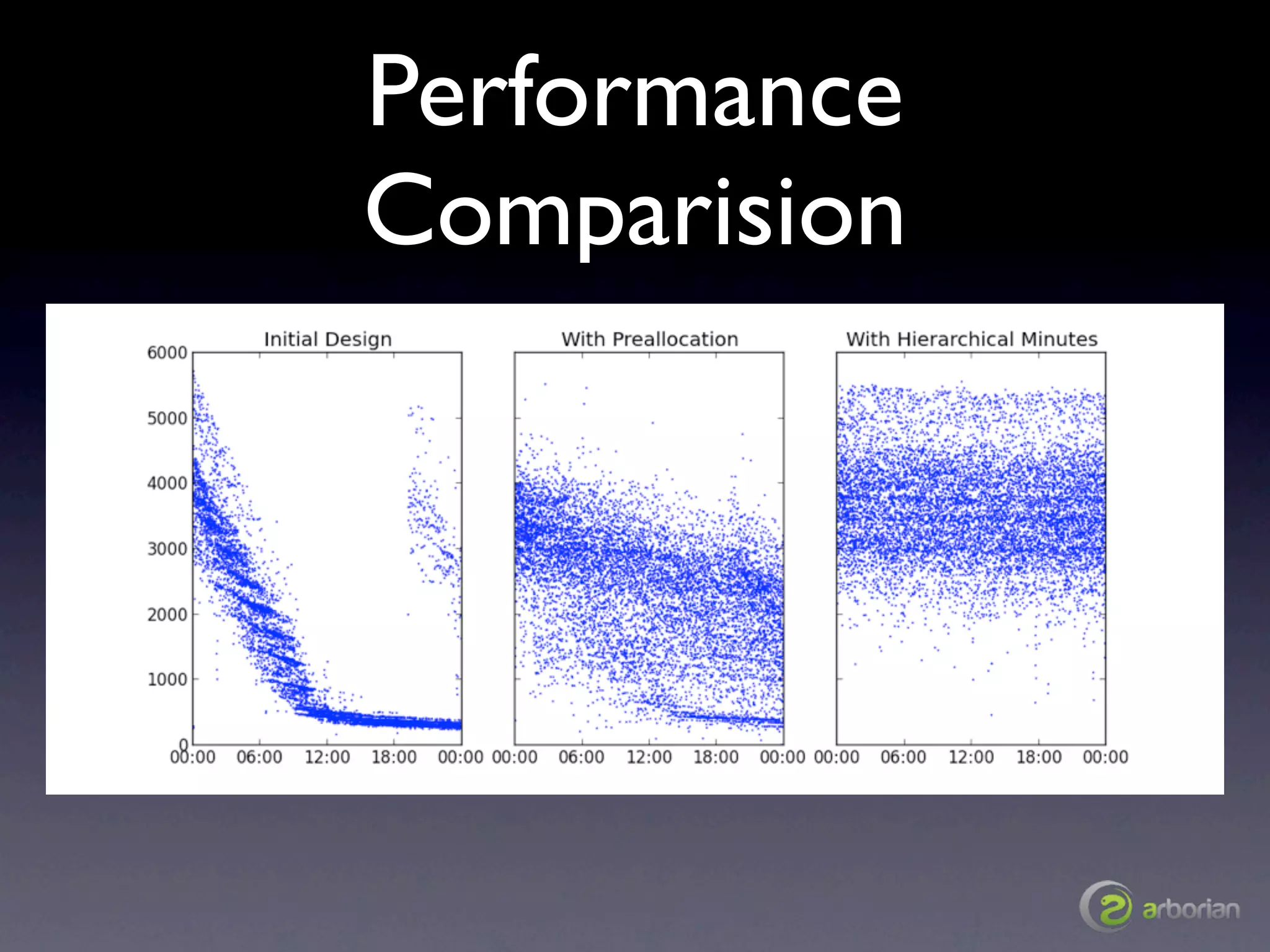
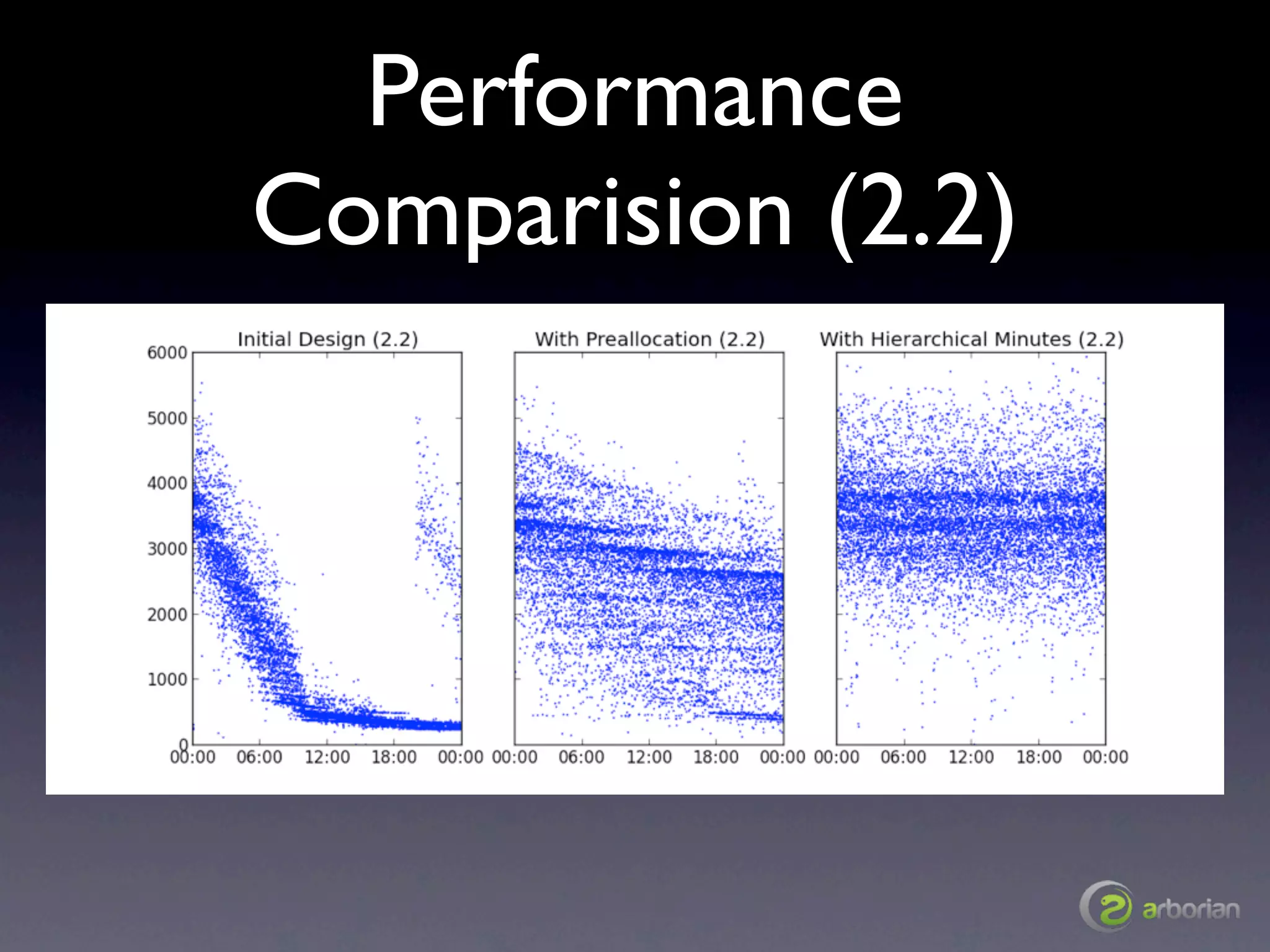
The document discusses the challenges and strategies associated with schema design in MongoDB at scale, focusing on performance issues related to document movement, midnight spikes, end-of-day load increases, and historical queries. It emphasizes the importance of preallocating documents and organizing data hierarchically to optimize performance. The author, Rick Copeland, provides insights based on experimental results and offers recommendations for efficient MongoDB usage.





















































































