Download as PDF, PPTX



![MongoDB
The leading NoSQL database
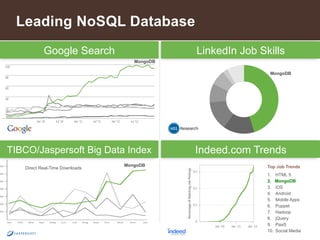
3
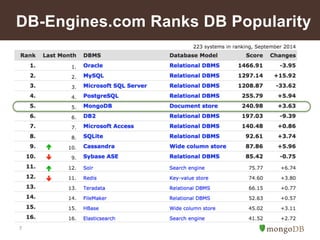
Document
Data Model
Open-
Source
Full-
Featured
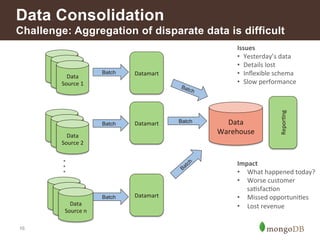
{ !
name: “John Smith”,!
pfxs: [“Dr.”,”Mr.”],!
address: “10 3rd St.”,!
phone: {!
!home: 1234567890,!
!mobile: 1234568138 }!
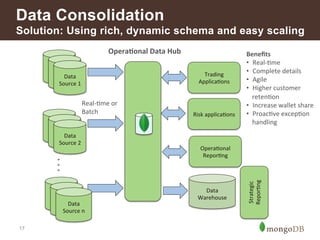
}!](https://image.slidesharecdn.com/howfinsvcsusemongov22-140924131556-phpapp02/85/How-Financial-Services-Organizations-Use-MongoDB-3-320.jpg)




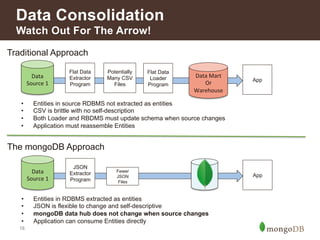
![mongoDB: Model Your Data The Way
it is Naturally Used
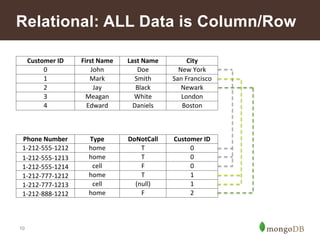
Relational MongoDB
11
{ !customer_id : 1,!
!first_name : "Mark",!
!last_name : "Smith",!
!city : "San Francisco",!
!phones: [ !{!
! ! number : “1-212-777-1212”,
! ! dnc : true,!
! ! type : “home”!
!},!
!{!
! ! number : “1-212-777-1213”, !!
! ! type : “cell”!
!}] !
}!
Customer
ID
First
Name
Last
Name
City
0
John
Doe
New
York
1
Mark
Smith
San
Francisco
2
Jay
Black
Newark
3
Meagan
White
London
4
Edward
Daniels
Boston
Phone
Number
Type
DNC
Customer
ID
1-‐212-‐555-‐1212
home
T
0
1-‐212-‐555-‐1213
home
T
0
1-‐212-‐555-‐1214
cell
F
0
1-‐212-‐777-‐1212
home
T
1
1-‐212-‐777-‐1213
cell
(null)
1
1-‐212-‐888-‐1212
home
F
2](https://image.slidesharecdn.com/howfinsvcsusemongov22-140924131556-phpapp02/85/How-Financial-Services-Organizations-Use-MongoDB-11-320.jpg)


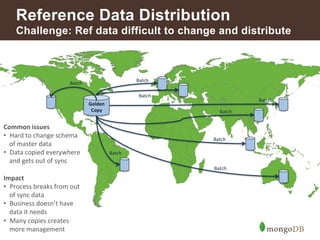
![Retail Banking - Common Uses
Functional Areas Use Cases to Consider
Customer Engagement Single View of a Customer
14
Customer Experience Management
Responsive Digital Banking
Gamification of Consumer Applications
Agile Next-generation Digital Platform
Marketing Multi-channel Customer Activity Capture
Real-time Cross-channel Next Best Offer
Location-based Offers
Risk Analysis & Reporting Firm-wide Liquidity Risk Analysis
Transaction Reporting and Analysis
Regulatory Compliance Flexible Cross-silo Reporting: Basel III, Dodd-Frank, etc.
Online Long-term Audit Trail
Aggregate Know Your Customer (KYC) Repository
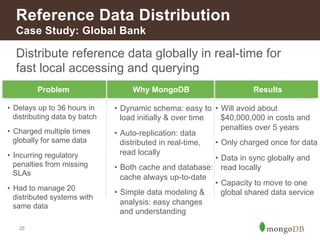
Reference Data Management [Global] Reference Data Distribution Hub
Payments Corporate Transaction Reporting
Fraud Detection Aggregate Activity Repository
Cybersecurity Threat Analysis](https://image.slidesharecdn.com/howfinsvcsusemongov22-140924131556-phpapp02/85/How-Financial-Services-Organizations-Use-MongoDB-14-320.jpg)
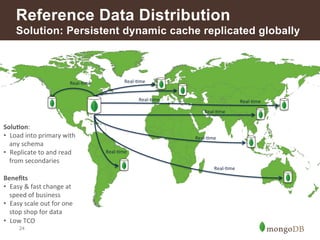
![Insurance – Common Uses
Functional Areas Use Cases to Consider
Customer Engagement Single View of a Customer
15
Customer Experience Management
Gamification of Applications
Agile Next-generation Digital Platform
Marketing Multi-channel Customer Activity Capture
Real-time Cross-channel Next Best Offer
Agent Desktop Responsive Customer Reporting
Risk Analysis & Reporting Catastrophe Risk Modeling
Liquidity Risk Analysis
Regulatory Compliance Online Long-term Audit Trail
Reference Data Management [Global] Reference Data Distribution Hub
Policy Catalog
Fraud Detection Aggregate Activity Repository](https://image.slidesharecdn.com/howfinsvcsusemongov22-140924131556-phpapp02/85/How-Financial-Services-Organizations-Use-MongoDB-15-320.jpg)








The document discusses the use of MongoDB in financial services, highlighting its advantages such as dynamic schema, real-time data processing, and rich querying capabilities. It provides examples of case studies across various sectors including insurance, capital markets, and retail banking, demonstrating how MongoDB improves data consolidation, customer engagement, and operational efficiency. Additionally, it emphasizes MongoDB's role in ensuring regulatory compliance and enhancing customer experience through agile data management.






















![[2018] NHN 모니터링의 현재와 미래 for 인프라 엔지니어](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra02-190131073314-thumbnail.jpg?width=640&height=640&fit=bounds)












![Competitive edgewithmongod bandpentaho_2014sep_v3[1]](https://cdn.slidesharecdn.com/ss_thumbnails/competitiveedgewithmongodbandpentaho2014sepv31-141022155232-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)



















![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)






























