Download to read offline















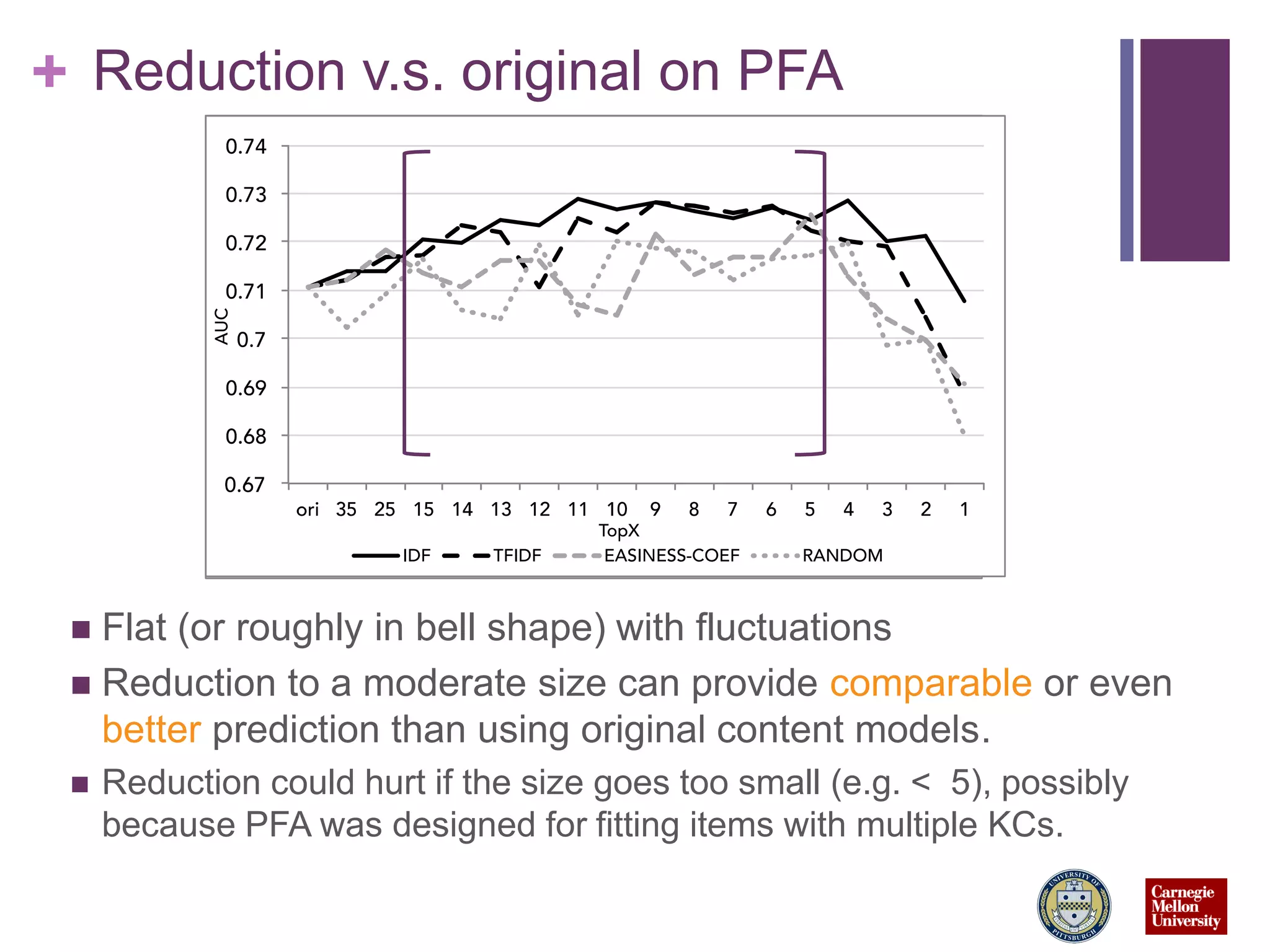
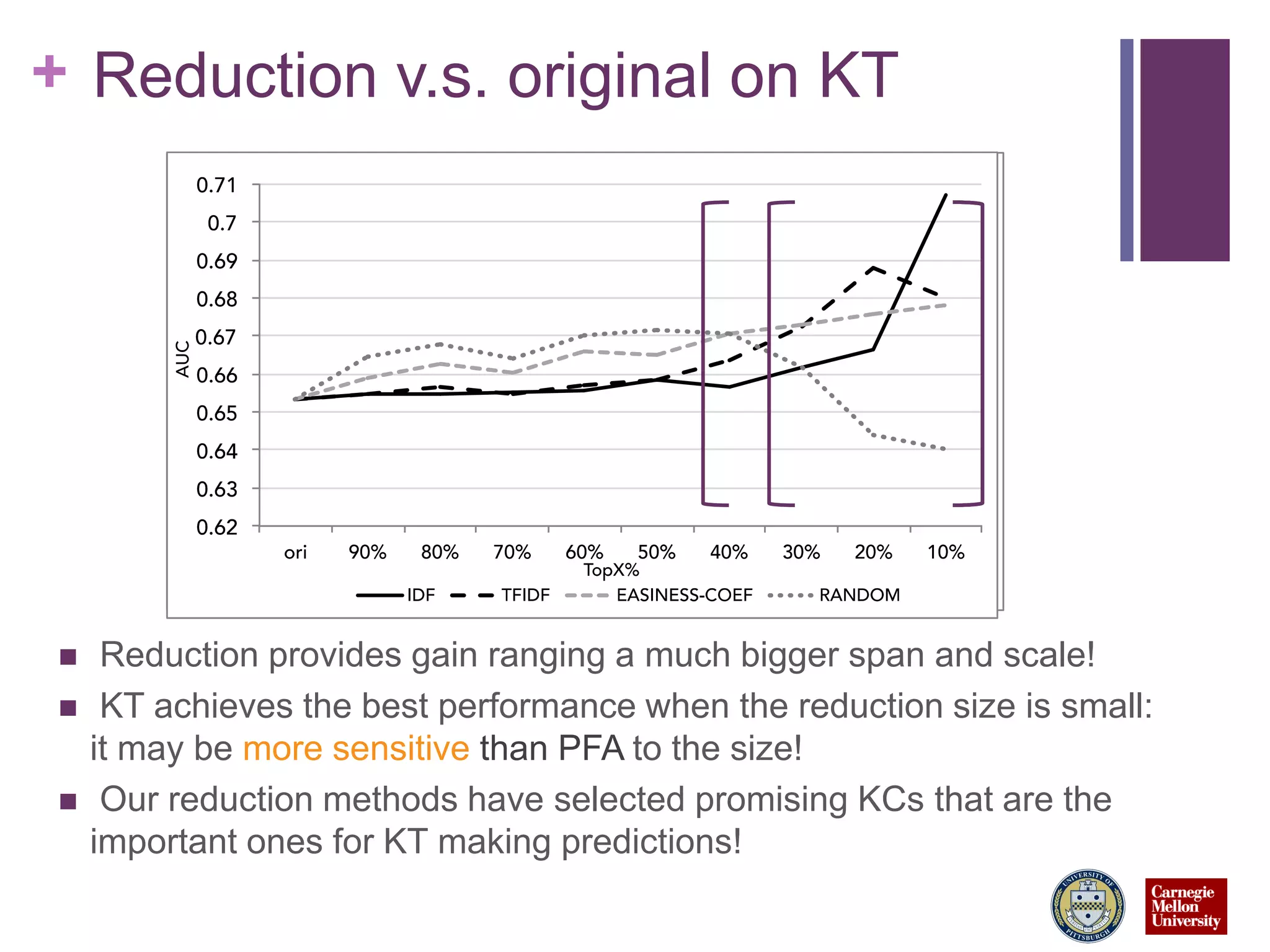






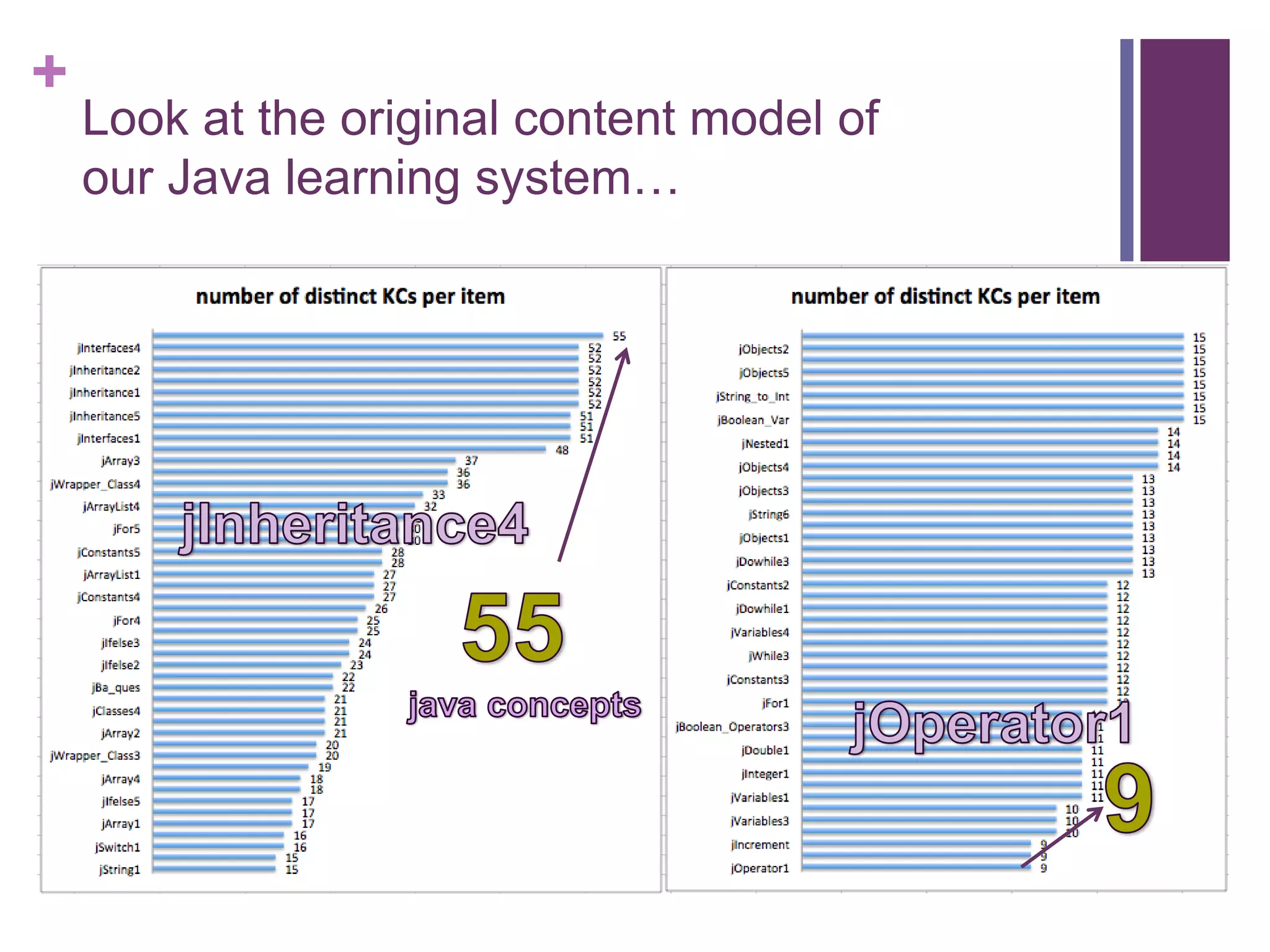


This talk discusses reducing the content models used for student modeling and performance prediction while maintaining or improving prediction accuracy. The researchers tested reducing the number of concepts (knowledge components or KCs) used to represent problems in a Java tutoring system. Their novel framework reduced the KCs for problems to 10-20% of the original numbers. When evaluated using two popular student modeling techniques, the reduced models either maintained or improved prediction performance compared to the original full models, with improvements up to 8% higher AUC. Different reduction methods and sizes worked best depending on the modeling technique used. The simple reduction approach enabled more effective student modeling with lower complexity models.




































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











