Download as KEY, PPTX



























![Hierarchical Aggregation
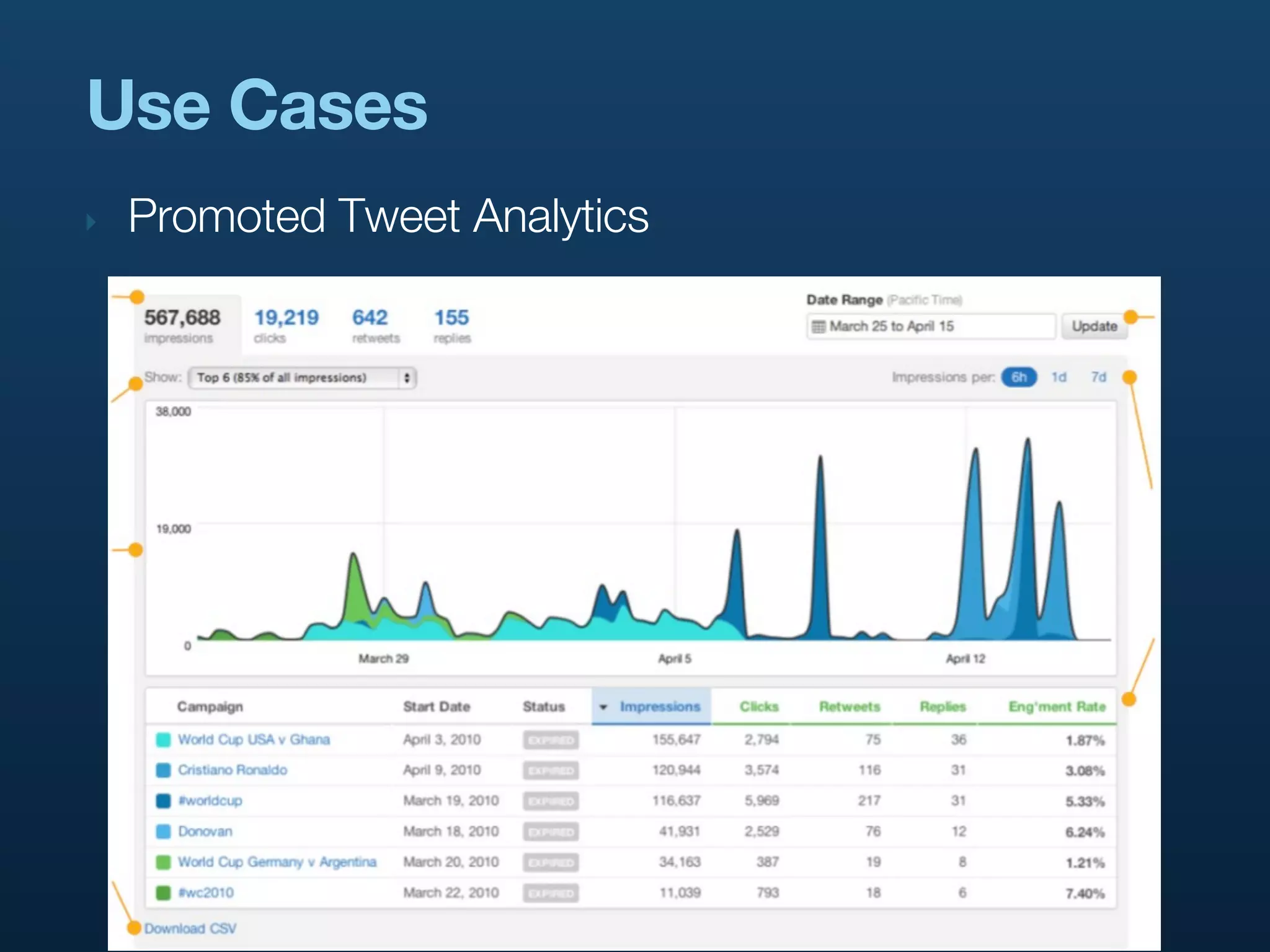
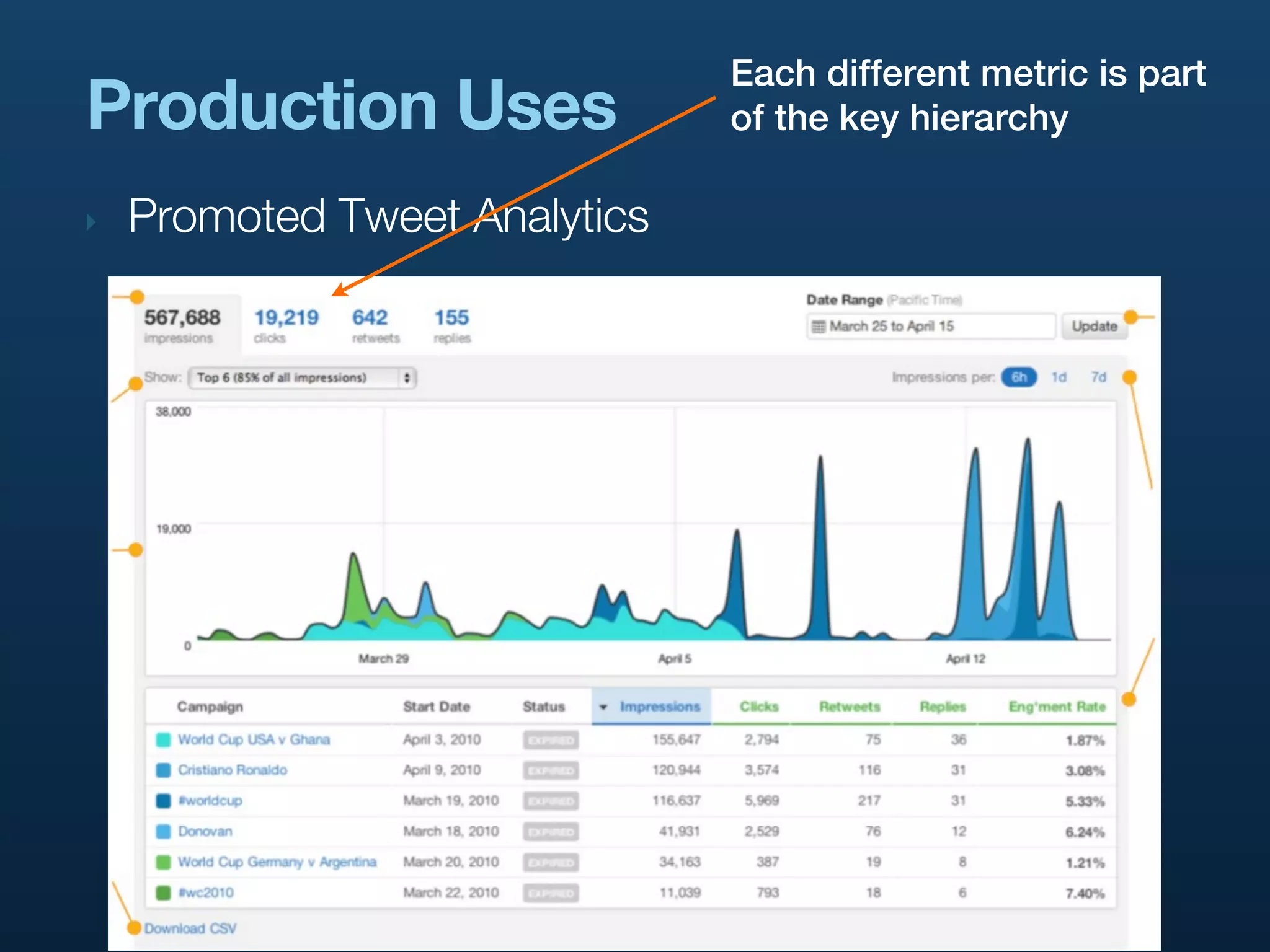
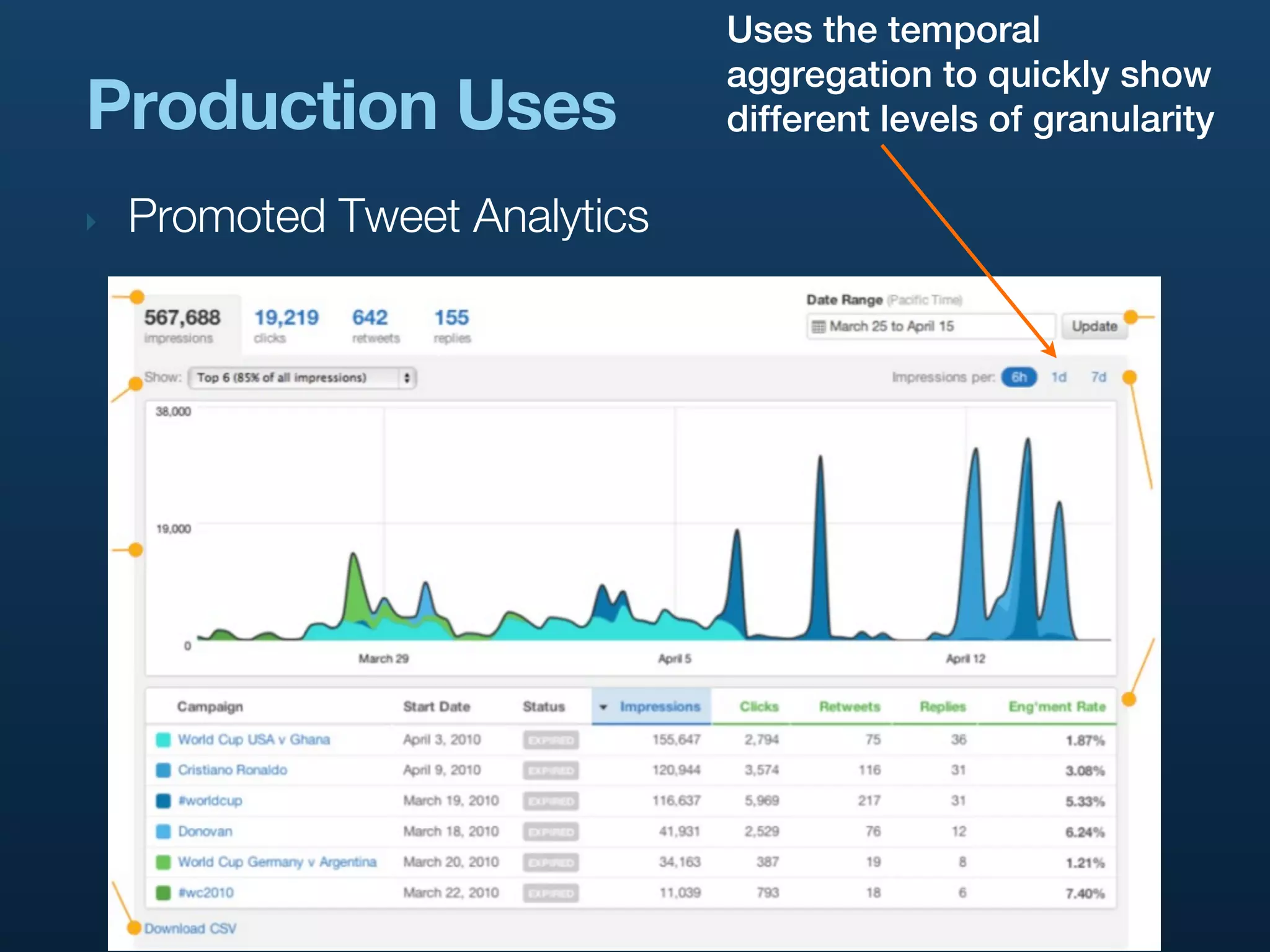
‣ Say we’re counting Promoted Tweet impressions
‣ category = pti
‣ keys = [advertiser_id, campaign_id, tweet_id]
‣ count = 1
‣ Rainbird automatically increments the count for
‣ [advertiser_id, campaign_id, tweet_id]
‣ [advertiser_id, campaign_id]
‣ [advertiser_id]
‣ Means fast queries over each level of hierarchy
‣ Configurable in rainbird.conf, or dynamically via ZK](https://image.slidesharecdn.com/realtimeanalyticsattwitter-strata2011-110204123031-phpapp02/75/Rainbird-Realtime-Analytics-at-Twitter-Strata-2011-33-2048.jpg)
![Hierarchical Aggregation
‣ Another example: tracking URL shortener tweets/clicks
‣ full URL = http://music.amazon.com/some_really_long_path
‣ keys = [com, amazon, music, full URL]
‣ count = 1
‣ Rainbird automatically increments the count for
‣ [com, amazon, music, full URL]
‣ [com, amazon, music]
‣ [com, amazon]
‣ [com]
‣ Means we can count clicks on full URLs
‣ And automatically aggregate over domains and subdomains!](https://image.slidesharecdn.com/realtimeanalyticsattwitter-strata2011-110204123031-phpapp02/75/Rainbird-Realtime-Analytics-at-Twitter-Strata-2011-34-2048.jpg)
![Hierarchical Aggregation
‣ Another example: tracking URL shortener tweets/clicks
‣ full URL = http://music.amazon.com/some_really_long_path
‣ keys = [com, amazon, music, full URL]
‣ count = 1
‣ Rainbird automatically increments the count for
‣ [com, amazon, music, full URL]
‣ [com, amazon, music] How many people tweeted
‣ [com, amazon] full URL?
‣ [com]
‣ Means we can count clicks on full URLs
‣ And automatically aggregate over domains and subdomains!](https://image.slidesharecdn.com/realtimeanalyticsattwitter-strata2011-110204123031-phpapp02/75/Rainbird-Realtime-Analytics-at-Twitter-Strata-2011-35-2048.jpg)
![Hierarchical Aggregation
‣ Another example: tracking URL shortener tweets/clicks
‣ full URL = http://music.amazon.com/some_really_long_path
‣ keys = [com, amazon, music, full URL]
‣ count = 1
‣ Rainbird automatically increments the count for
‣ [com, amazon, music, full URL]
‣ [com, amazon, music] How many people tweeted
‣ [com, amazon] any music.amazon.com URL?
‣ [com]
‣ Means we can count clicks on full URLs
‣ And automatically aggregate over domains and subdomains!](https://image.slidesharecdn.com/realtimeanalyticsattwitter-strata2011-110204123031-phpapp02/75/Rainbird-Realtime-Analytics-at-Twitter-Strata-2011-36-2048.jpg)
![Hierarchical Aggregation
‣ Another example: tracking URL shortener tweets/clicks
‣ full URL = http://music.amazon.com/some_really_long_path
‣ keys = [com, amazon, music, full URL]
‣ count = 1
‣ Rainbird automatically increments the count for
‣ [com, amazon, music, full URL]
‣ [com, amazon, music] How many people tweeted
‣ [com, amazon] any amazon.com URL?
‣ [com]
‣ Means we can count clicks on full URLs
‣ And automatically aggregate over domains and subdomains!](https://image.slidesharecdn.com/realtimeanalyticsattwitter-strata2011-110204123031-phpapp02/75/Rainbird-Realtime-Analytics-at-Twitter-Strata-2011-37-2048.jpg)
![Hierarchical Aggregation
‣ Another example: tracking URL shortener tweets/clicks
‣ full URL = http://music.amazon.com/some_really_long_path
‣ keys = [com, amazon, music, full URL]
‣ count = 1
‣ Rainbird automatically increments the count for
‣ [com, amazon, music, full URL]
‣ [com, amazon, music] How many people tweeted
‣ [com, amazon] any .com URL?
‣ [com]
‣ Means we can count clicks on full URLs
‣ And automatically aggregate over domains and subdomains!](https://image.slidesharecdn.com/realtimeanalyticsattwitter-strata2011-110204123031-phpapp02/75/Rainbird-Realtime-Analytics-at-Twitter-Strata-2011-38-2048.jpg)





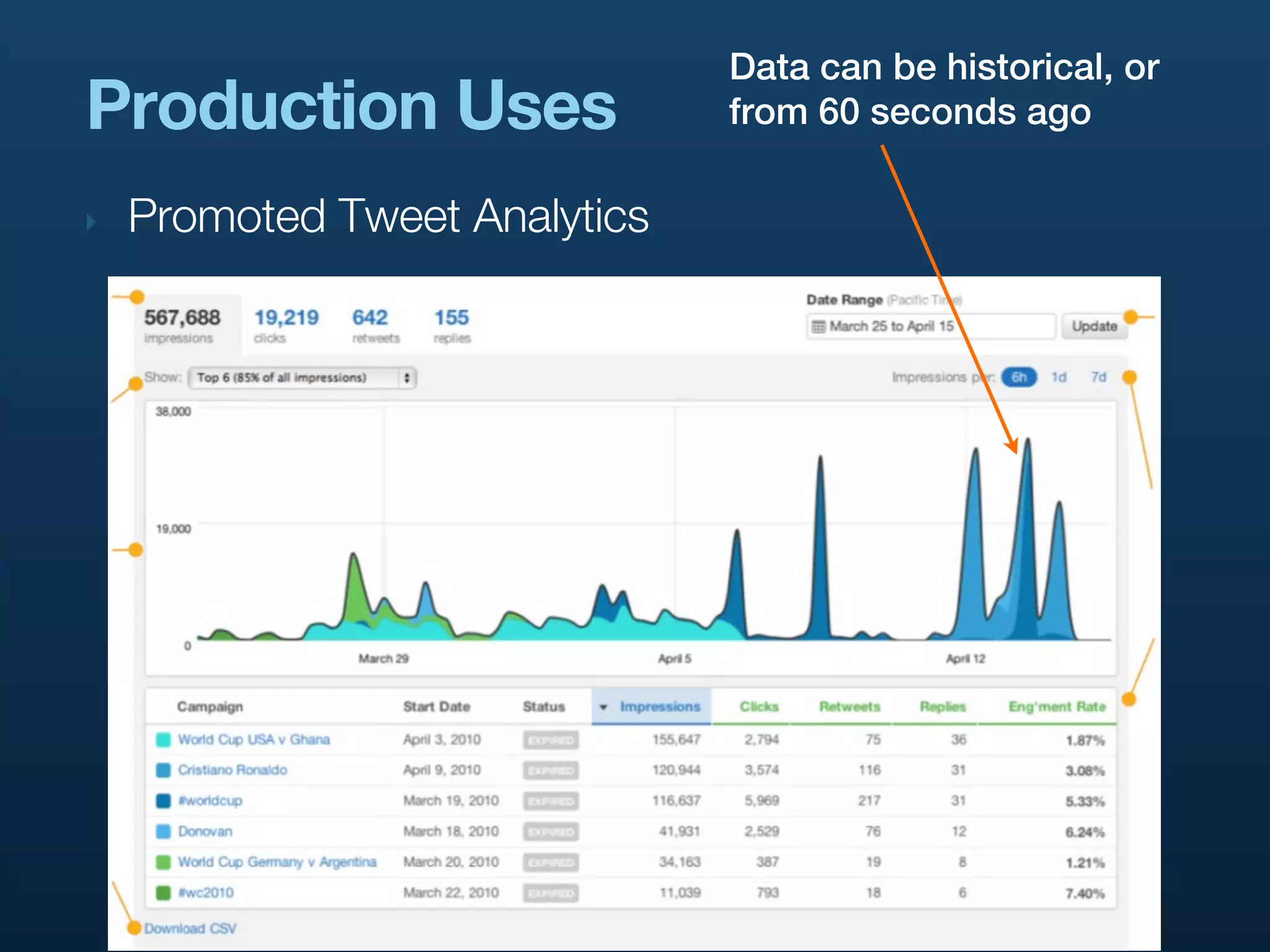
![Production Uses
‣ Internal Monitoring and Alerting
‣ We require operational reporting on all internal services
‣ Needs to be real-time, but also want longer-term
aggregates
‣ Hierarchical, too: [stat, datacenter, service, machine]](https://image.slidesharecdn.com/realtimeanalyticsattwitter-strata2011-110204123031-phpapp02/75/Rainbird-Realtime-Analytics-at-Twitter-Strata-2011-48-2048.jpg)













The document details a presentation by Kevin Weil from Twitter on Rainbird, a real-time analytics system built on Cassandra that handles extremely high write and read volumes for counting events. Rainbird enables efficient queries with hierarchical and temporal aggregations, supporting various use cases like promoted tweet analytics and operational monitoring. It is currently in-house but will be open-sourced for community use, leveraging high scalability and fast response times.
Kevin Weil introduces Real-time Analytics at Twitter, highlighting its significance.
The presentation agenda covers Real-time Analytics, Rainbird and Cassandra, production uses at Twitter, and open-source plans.
Kevin Weil shares his educational background in Mathematics and Physics and experience at various companies, leading to his role at Twitter.
The presentation agenda covers Real-time Analytics, Rainbird and Cassandra, production uses at Twitter, and open-source plans.
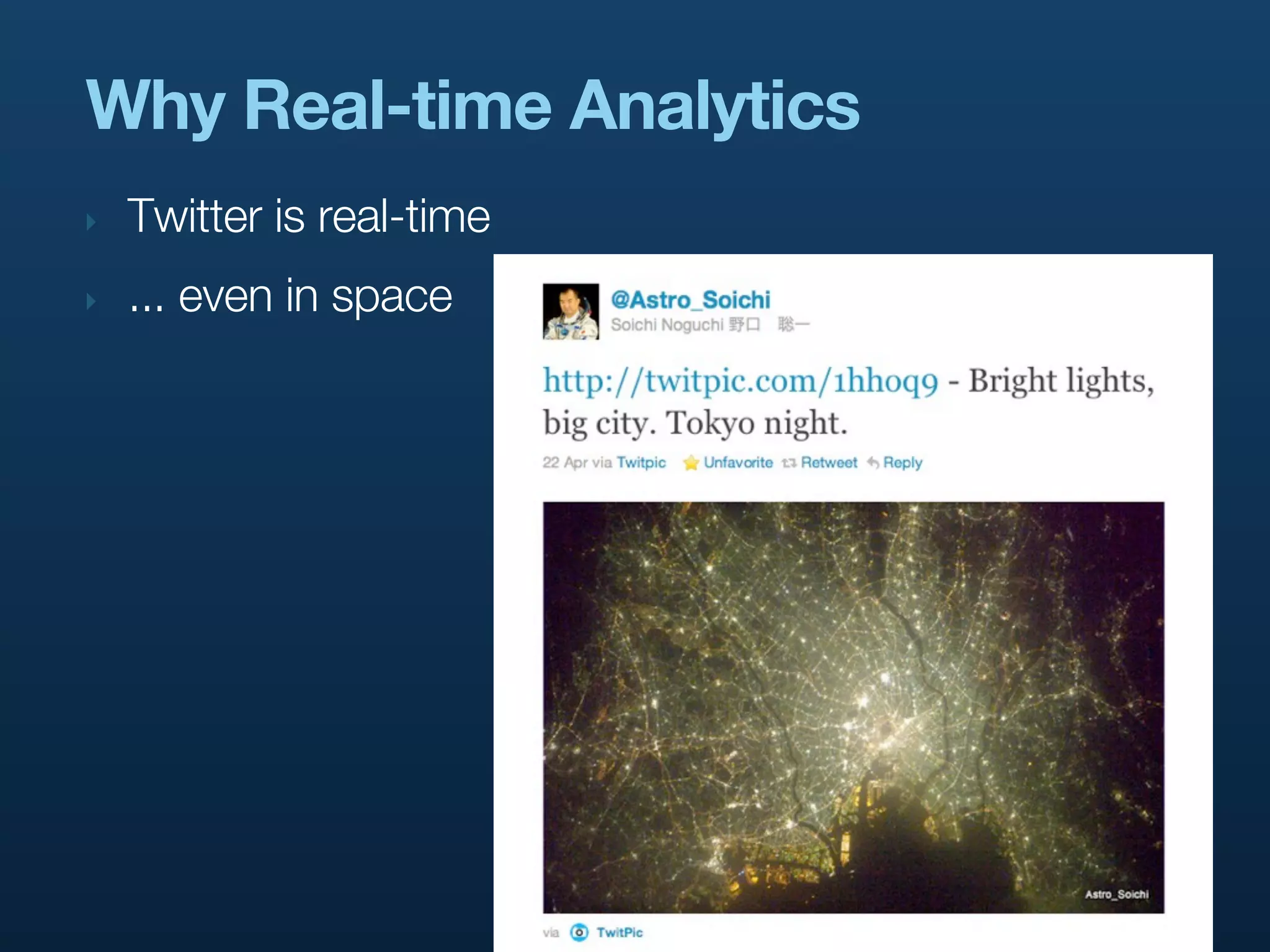
The presentation emphasizes why real-time analytics are crucial, especially for Twitter's nature of immediate interactions.
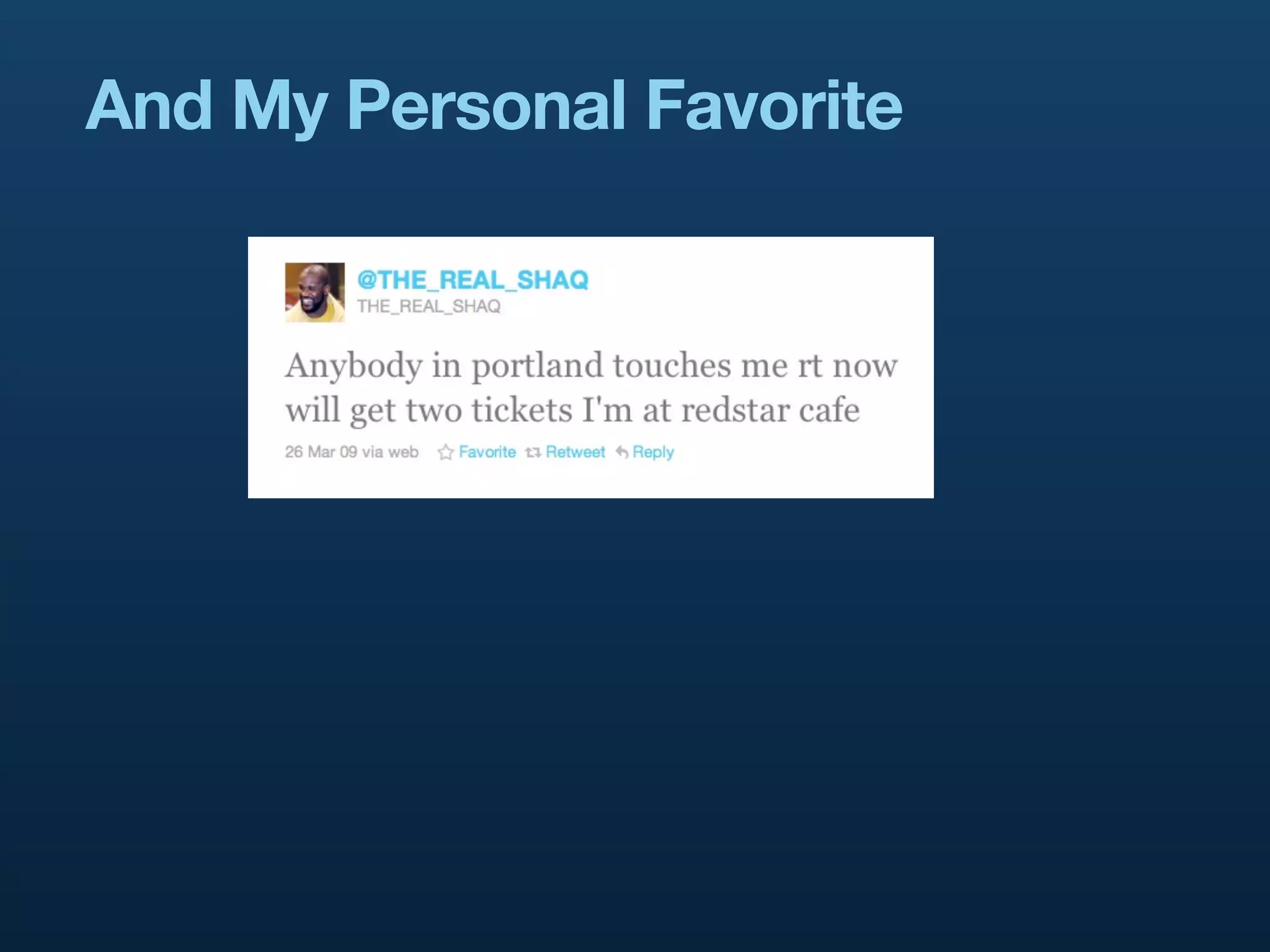
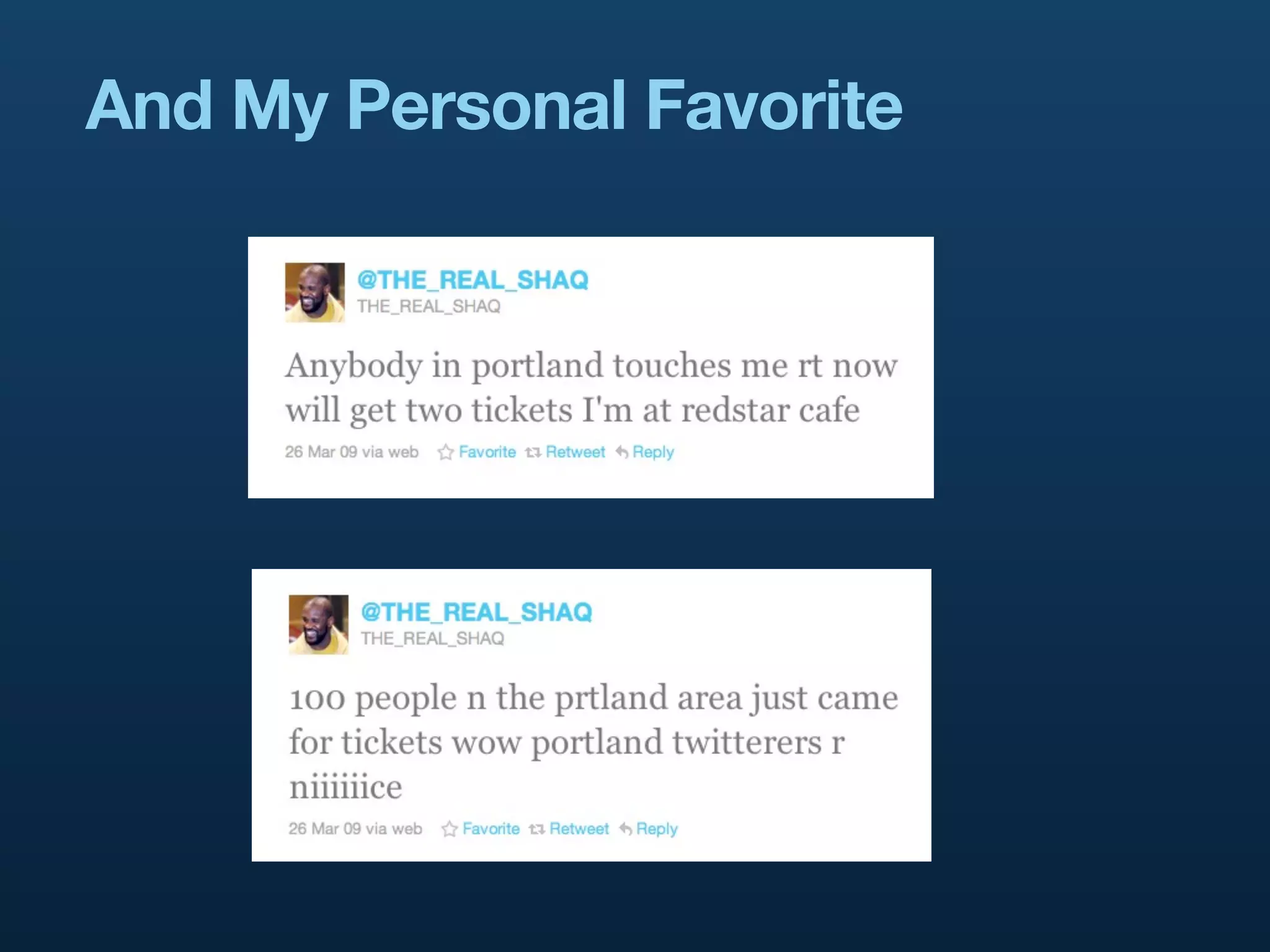
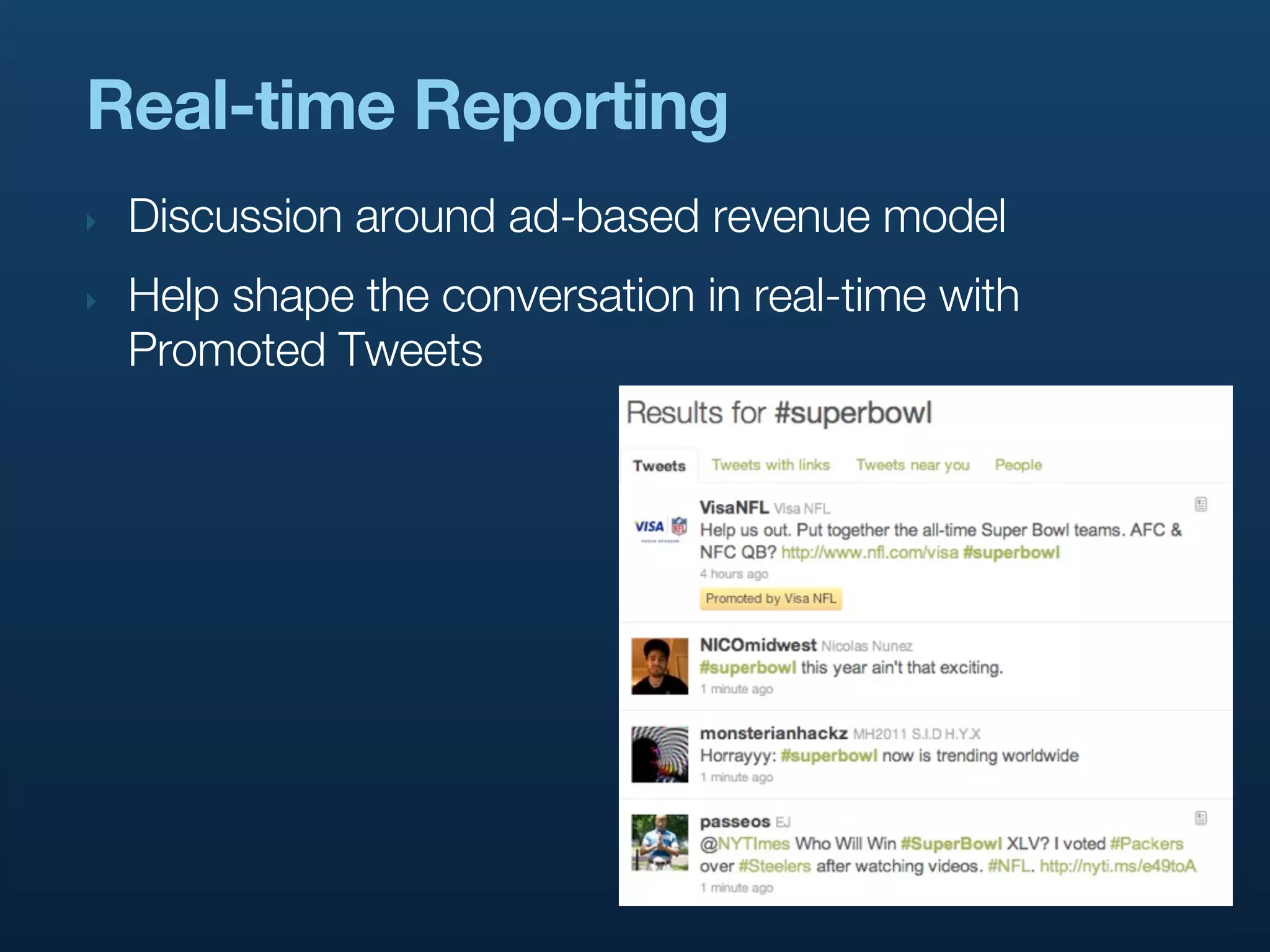
Discusses how real-time reporting assists in shaping conversations via Twitter's ad model with Promoted Tweets.
The presentation agenda covers Real-time Analytics, Rainbird and Cassandra, production uses at Twitter, and open-source plans.
Outlines requirements for Twitter's analytics system, emphasizing the need for high write and read volumes, scalability, and low latency.
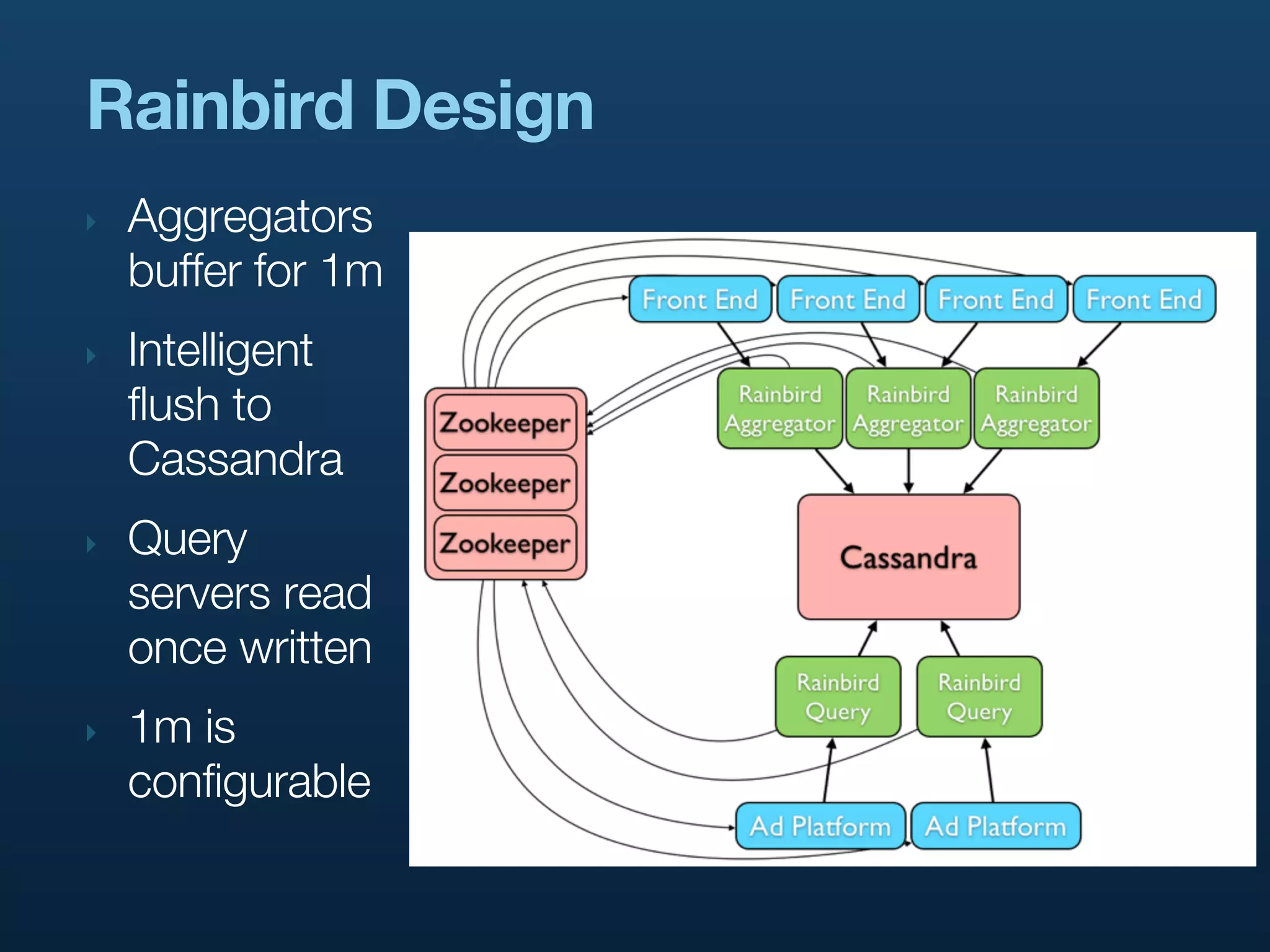
Discusses the advantages and disadvantages of using Cassandra for high-speed data processing at Twitter and Rainbird's reliance on it.Describes Rainbird's functionality in counting events quickly, utilizing hierarchical and temporal aggregations to support various metrics.
Explores various use cases of Rainbird at Twitter, including analytics for Promoted Tweets, URL tracking, and internal monitoring.
The presentation agenda covers Real-time Analytics, Rainbird and Cassandra, production uses at Twitter, and open-source plans.
Discusses plans for making Rainbird open source, highlighting dependencies on unreleased versions of Cassandra and internal frameworks.
Concludes with team acknowledgments, a summary of Rainbird's capabilities, and an invitation for questions.


































































