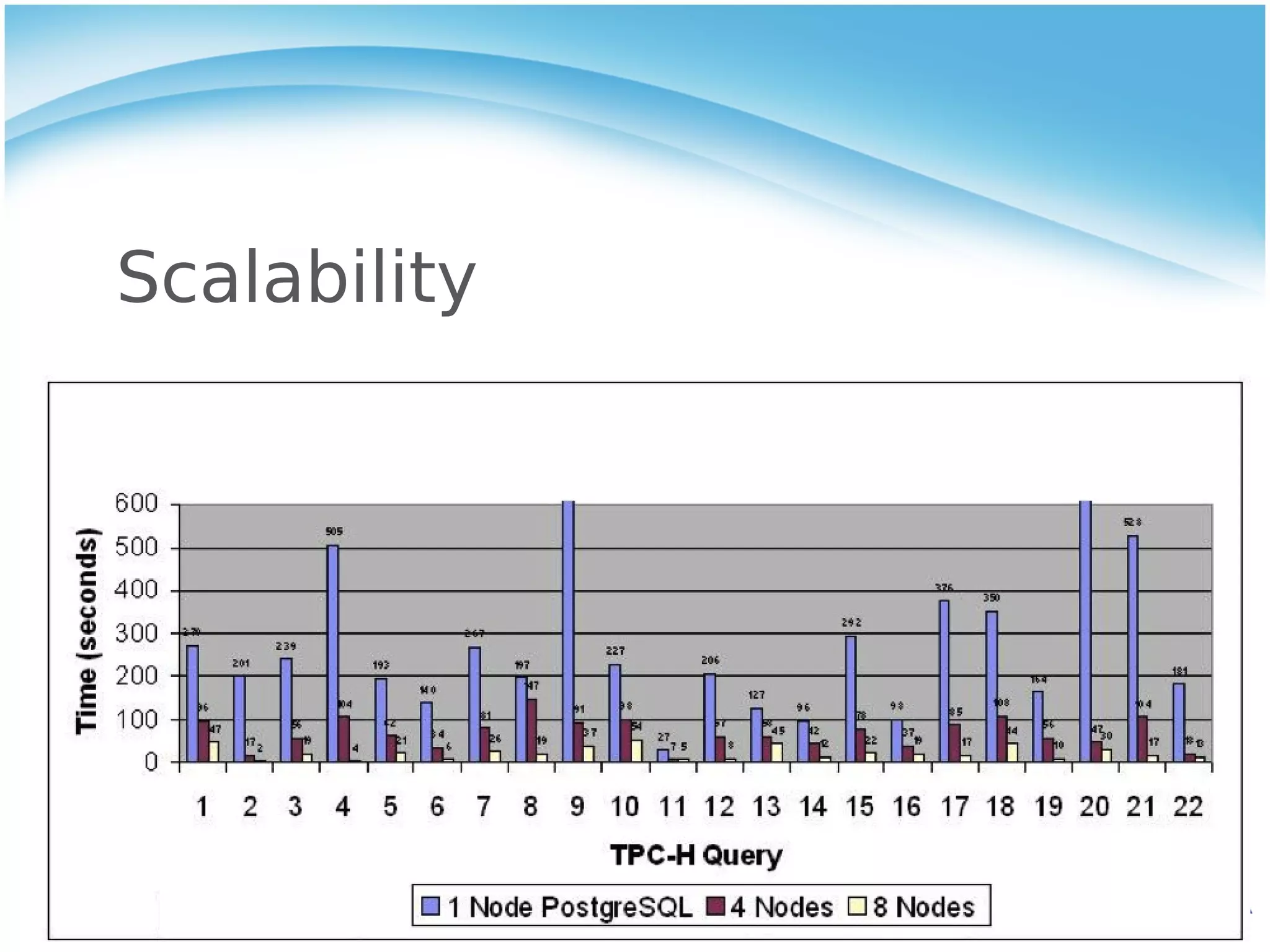
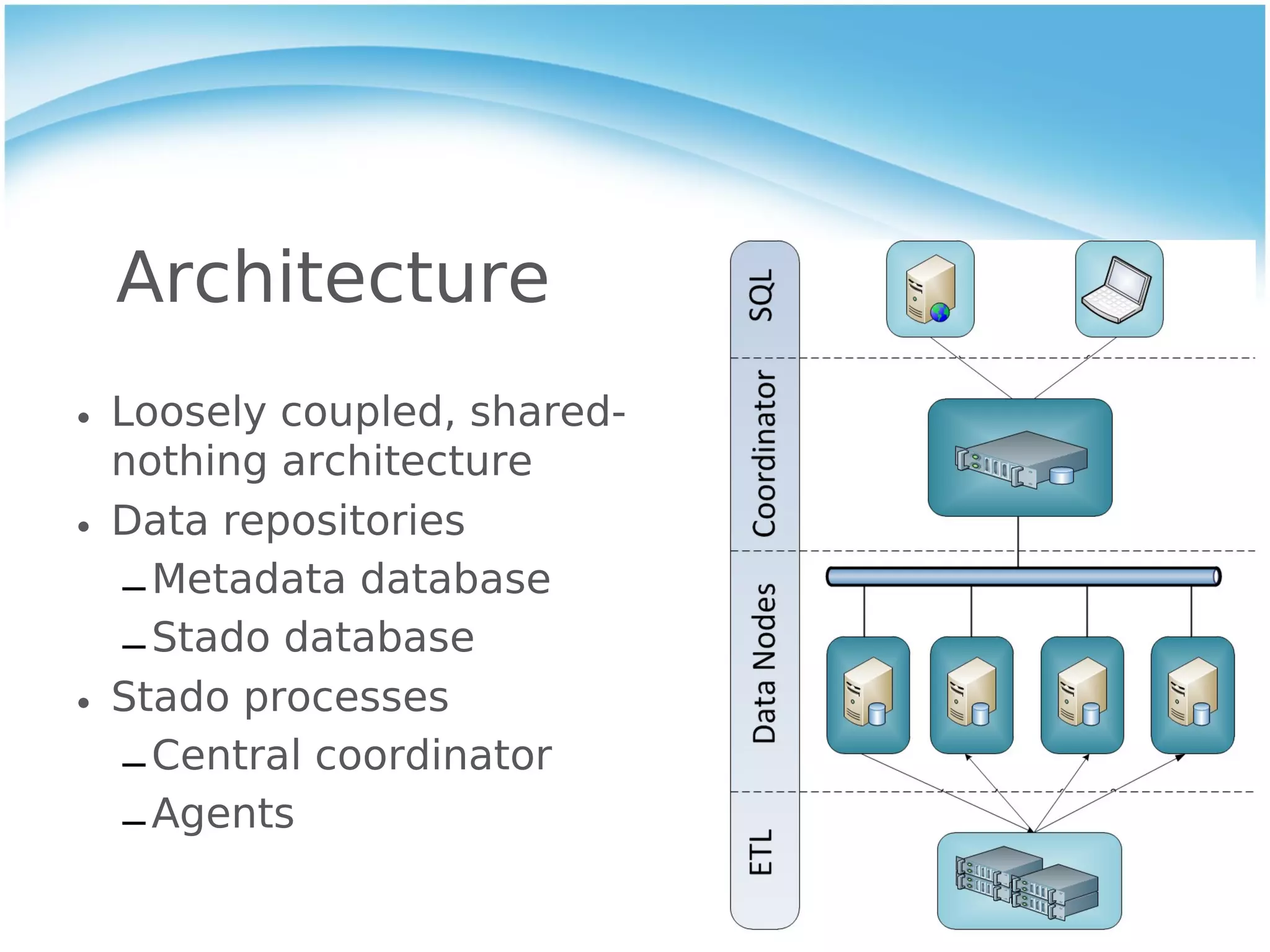
Stado is an open source, shared-nothing architecture for scaling PostgreSQL across multiple servers. It partitions and distributes PostgreSQL tables and queries them in parallel. Stado provides linear scalability for read queries as more nodes are added. However, writes are slower than a single PostgreSQL instance due to additional network hops. Stado also has limitations in transaction performance, high availability and backup/restore capabilities compared to a single PostgreSQL database.











![Query 1
SELECT sum(st_length_spheroid(the_geom,
'SPHEROID["GRS_1980",6378137,298.257222101]'))/1609.344
as interstate_miles
FROM roads
WHERE rttyp = 'I';
interstate_miles
------------------
84588.5425986619
(1 row)](https://image.slidesharecdn.com/scalingpostresqlwithstado-110929165517-phpapp02/75/Scaling-PostreSQL-with-Stado-14-2048.jpg)
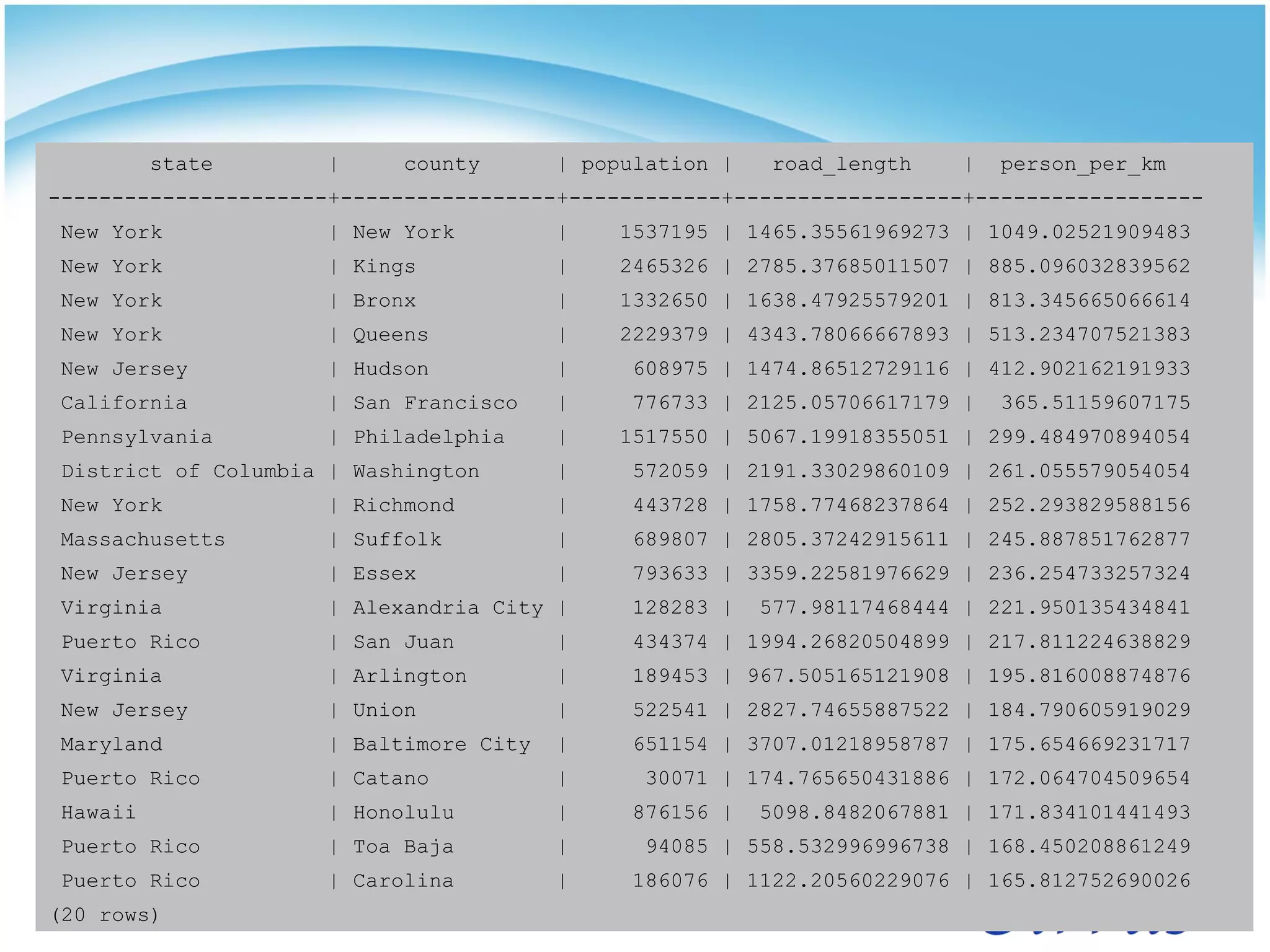
![Query 2
SELECT s.name as state, c.name as county, a.population, b.road_length,
a.population/b.road_length as person_per_km
FROM (SELECT state_cd, county_cd, sum(population) as population
FROM census_tract
GROUP BY 1, 2) a,
(SELECT statefp, countyfp,
sum(st_length_spheroid(the_geom,
'SPHEROID["GRS_1980",6378137,298.257222101]'))/1000 as road_length
FROM roads
GROUP BY 1, 2) b,
state_codes s, county_codes c
WHERE a.state_cd = b.statefp
AND a.county_cd = b.countyfp
AND a.state_cd = c.state_cd
AND a.county_cd = c.county_cd
AND c.state_cd = s.state_cd
ORDER BY 5 DESC
LIMIT 20;](https://image.slidesharecdn.com/scalingpostresqlwithstado-110929165517-phpapp02/75/Scaling-PostreSQL-with-Stado-16-2048.jpg)