


![More Static Evolution Research
Association rule mining
For predicting changes [Ying et al., IEEE TSE, v30 n9, Sept. 2004]
For architectural justification [Zimmermann, Diehl, and Zeller,
Proc. IWPSE 2003]
Identifying code “chunks” for future
modularization [Mockus and Weiss, IEEE Software, v18 n2, 2001]
“Feature” identification [Fischer, Pinzger, and Gall, Proc. WCRE
2003]
…and the ongoing research related to these.](https://image.slidesharecdn.com/kenyon-ucsc-01262005-120614145632-phpapp02/75/Kenyon-A-Software-Stratigraphy-Platform-ESEC-FSE-2005-4-2048.jpg)







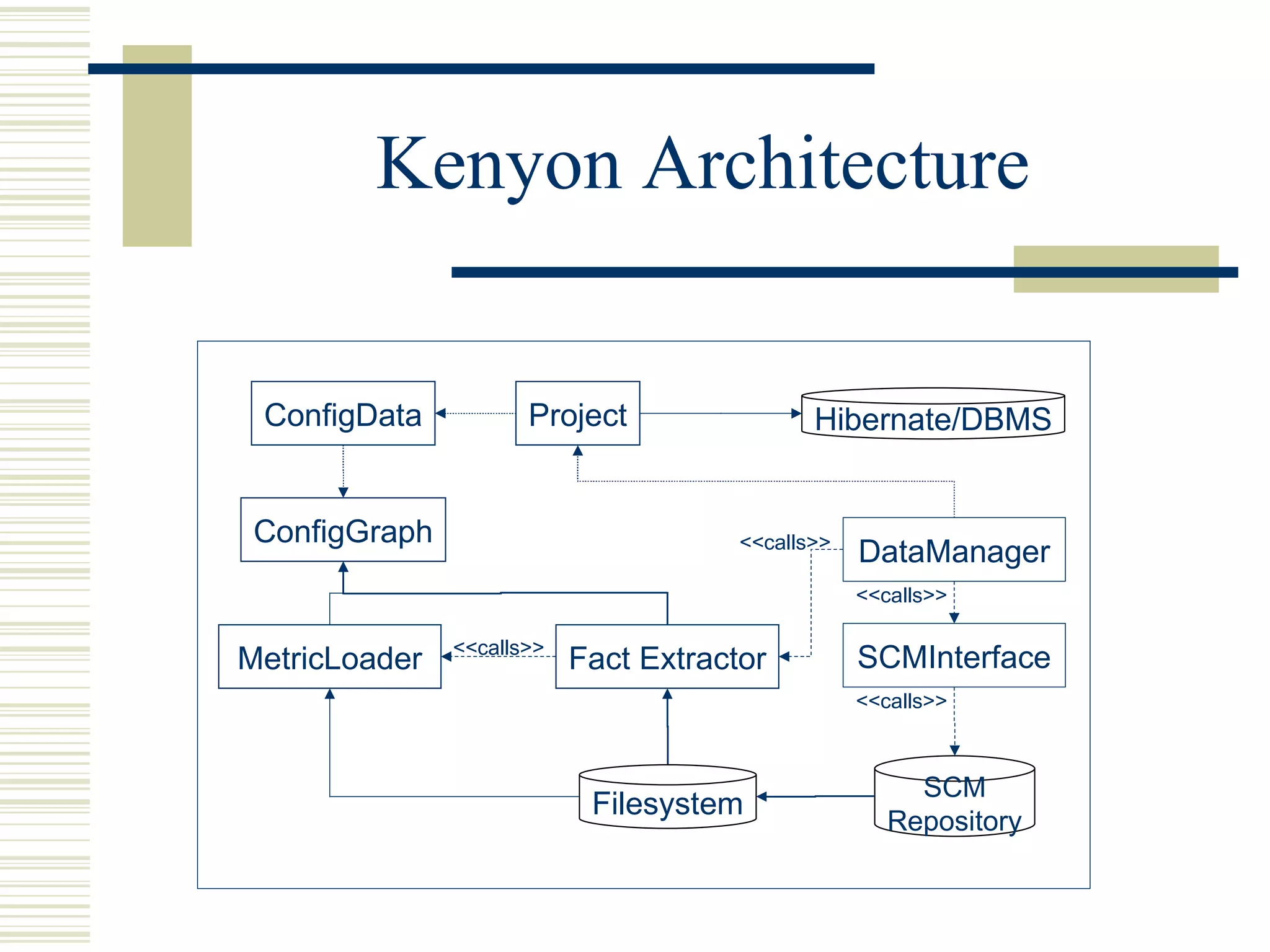
![Phase 2: Invoke Fact Extractors
Kenyon provides an abstract class that is used to
invoke third-party fact extractors on the
configuration extracted to the filesystem.
Kenyon users would subclass this class to invoke their
own fact extractor.
Support for Codesurfer (line-level analysis) and
SWAGKIT (procedure-level analysis) are provided with
Kenyon. [www.grammatech.com, swag.uwaterloo.ca]
FactExtractor subclasses have a tri-modal return status:
“failure”, “new data to store”, or “no new data to store”.](https://image.slidesharecdn.com/kenyon-ucsc-01262005-120614145632-phpapp02/75/Kenyon-A-Software-Stratigraphy-Platform-ESEC-FSE-2005-13-2048.jpg)

![Phase 3: Data Storage
Kenyon uses Hibernate to persist data
classes.
Hibernate is an “object/relational persistence and
query service for Java” [www.hibernate.org].
Allows reuse of Kenyon classes by research
tools implemented in Java.
Each configuration processed by Kenyon is
assigned to a Project, the top-level data class
persisted by Kenyon.](https://image.slidesharecdn.com/kenyon-ucsc-01262005-120614145632-phpapp02/75/Kenyon-A-Software-Stratigraphy-Platform-ESEC-FSE-2005-15-2048.jpg)
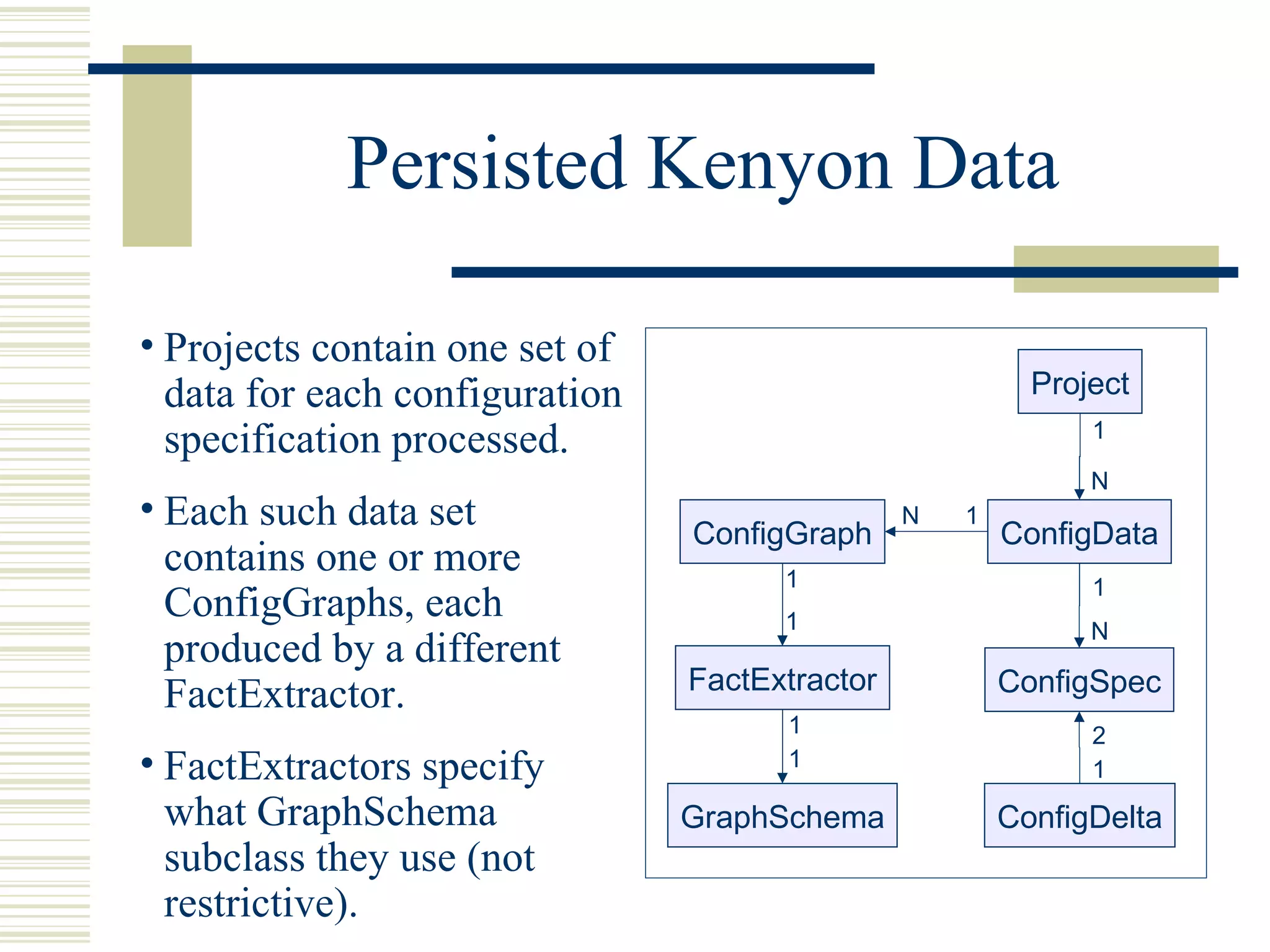















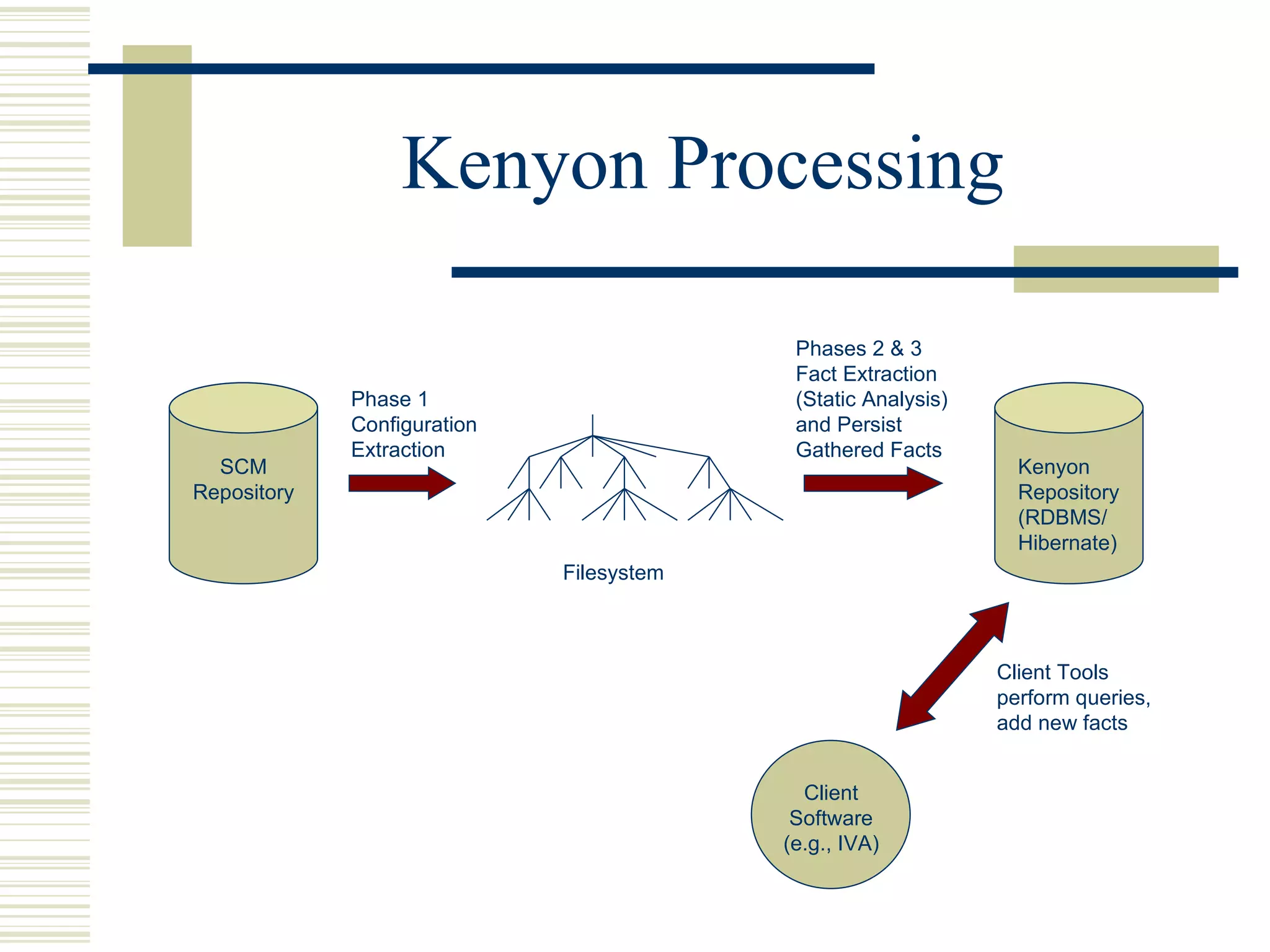
Kenyon is a software platform that facilitates static software evolution research by automatically extracting configurations from source code management systems, running static analysis tools on the configurations to extract facts, and storing the results in a database. This allows research projects to share data and technologies while avoiding redundant computation. Kenyon extracts logical configurations that represent the state of the software at specific points in time, calculates configuration deltas, and invokes customizable fact extraction tools. It uses Hibernate to persist the extracted facts to a database for efficient querying and retrieval to support various evolution analyses.
















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)



![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)












