Downloaded 95 times







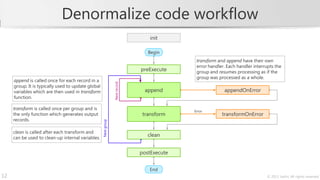
![Data denormalization
Account
Original data accountId customerId balance created closed
Multiple records grouped
based on the key. 9804568699 27345 2300.56 2011-11-14
1108193472 27345 -1739.05 2005-07-22
6054951154 27345 4500.60 2009-09-01 2010-04-30
9459175447 27345 3200.80 2011-03-08
Denormalize
CustomerAccount
Denormalized data s
Single record containing values customerId totalBalance accounts
determined by processing the
27345 8262.91 [9804568699, 1108193472, 6054951154, 9459175447]
whole input group.
10 © 2013 Javlin; All rights reserved](https://image.slidesharecdn.com/cloveretl-training-sample-130311110423-phpapp01/85/CloverETL-Training-Sample-10-320.jpg)


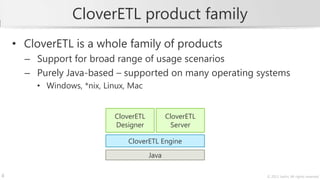
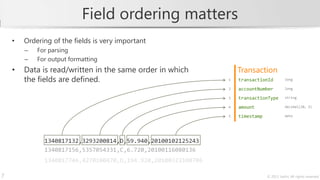
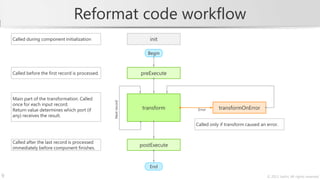
The document describes a training course on CloverETL, an open-source data integration tool. The course goals are to learn how to compose transformations to connect to various data sources and sinks, handle errors, and design complex job flows. The course modules cover basics of the tool, common components, databases, structured data, advanced graph design, and the CloverETL Server. It also provides information on the CloverETL product family and describes how to work with metadata and use the Reformat transformation component to write code directly in CTL.



























