More Related Content

PPTX

PDF
ヤフー社内でやってるMySQLチューニングセミナー大公開 
PDF

PDF

PDF

PDF

PDF

PDF
競技プログラミングにおけるコードの書き方とその利便性 What's hot

PDF

PDF
組み込み関数(intrinsic)によるSIMD入門 
PDF
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか) 
PDF
SQLアンチパターン 幻の第26章「とりあえず削除フラグ」 
PDF

PPTX

PDF

PDF
使ってみて気づいた AGPL ライセンスの メリット・デメリット 
PDF
Linuxにて複数のコマンドを並列実行(同時実行数の制限付き) 
PPTX

PDF
RSA暗号運用でやってはいけない n のこと #ssmjp 
PDF

PDF
マイクロサービスバックエンドAPIのためのRESTとgRPC 
PDF
Boost.Logとfluentdで始めるログ活用術 
PDF
コンパイルターゲット言語としてのWebAssembly、そしてLINEでの実践 
PDF
NextGen Server/Client Architecture - gRPC + Unity + C# 
PDF

PDF

PPTX

PDF
Viewers also liked

PDF

PDF

PDF

PPTX
Intel AES-NI Application Performance 
PDF

PDF

PDF
改ざん検知暗号Minalpherの設計とIvy Bridge/Haswellでの最適化 
PDF
Cybozu Tech Conference 2016 バグの調べ方 
PPTX
Similar to AES-NI@Sandy Bridge

PDF

PDF
第11回ACRiウェビナー_インテル/竹村様ご講演資料 
PDF
![[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理](https://cdn.slidesharecdn.com/ss_thumbnails/basic-07-180228134341-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理 
PDF

PDF

PPTX
あなたのAppleにもEFIモンスターはいませんか? by Pedro Vilaça - CODE BLUE 2015 
PDF

PDF
エバンジェリストが語るパワーシステム特論 ~ 第3回:IBMオフコンはいかにして生き残れたのか?~第二章~ 
PDF
CMSI計算科学技術特論B(15) インテル Xeon Phi コプロセッサー向け最適化、並列化概要 1 
PDF
Bitvisorをベースとした既存Windowsのドライバメモリ保護 
PDF
GPUを用いたSSLリバースプロキシの実装についての論文を読んだ 
PDF
セキュアVMの構築 (IntelとAMDの比較、あともうひとつ...) - AVTokyo 2009 
PDF

PDF
CLRの基礎 - プログラミング .NET Framework 第3版 読書会 
PDF
エバンジェリストが語るパワーシステム特論 ~ 第1回:IBMオフコンはいかにして生き残れたのか? 
PDF

PDF
Secure Scheme Script Suite 
PDF
Secure scheme script suite 
PPTX
More from MITSUNARI Shigeo

PDF

PDF
Intel AVX-512/富岳SVE用SIMDコード生成ライブラリsimdgen 
PDF

PDF
深層学習フレームワークにおけるIntel CPU/富岳向け最適化法 
PDF
Intro to SVE 富岳のA64FXを触ってみた 
PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF
Lifted-ElGamal暗号を用いた任意関数演算の二者間秘密計算プロトコルのmaliciousモデルにおける効率化 
PDF

PDF

PDF

PDF
AES-NI@Sandy Bridge
- 1.
- 2.
- 3.
内容
SCIS 2013 で発表した「SandyBridge 環境で
のモード実装の最適化」を本勉強会向けに
再構成したものです
AES-NI の概要
Sandy Bridge
AES-NI の詳細
解析結果
Copyright 2013 c NTT – p.3/13
- 4.
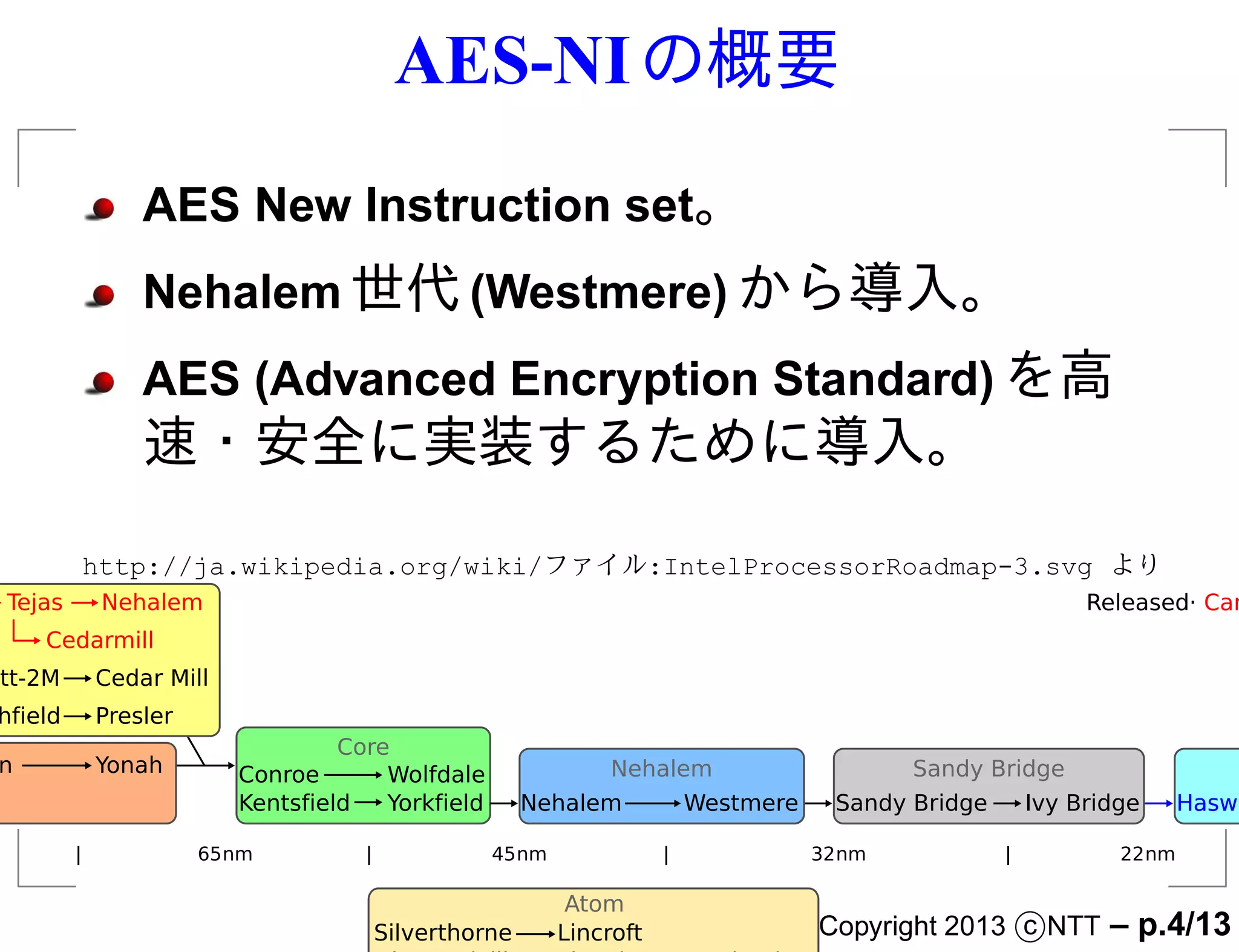
AES-NI の概要
AES New Instruction set。
Nehalem 世代 (Westmere) から導入。
AES (Advanced Encryption Standard) を高
速・安全に実装するために導入。
http://ja.wikipedia.org/wiki/ファイル:IntelProcessorRoadmap-3.svg より
cott Tejas Nehalem Released· Canceled
Cedarmill
Prescott-2M Cedar Mill
Smithfield Presler
Core
Dothan Yonah Conroe Wolfdale Nehalem Sandy Bridge Haswe
Kentsfield Yorkfield Nehalem Westmere Sandy Bridge Ivy Bridge Haswell B
90nm | 65nm | 45nm | 32nm | 22nm |
Atom
Silverthorne Lincroft Copyright 2013 c NTT – p.4/13
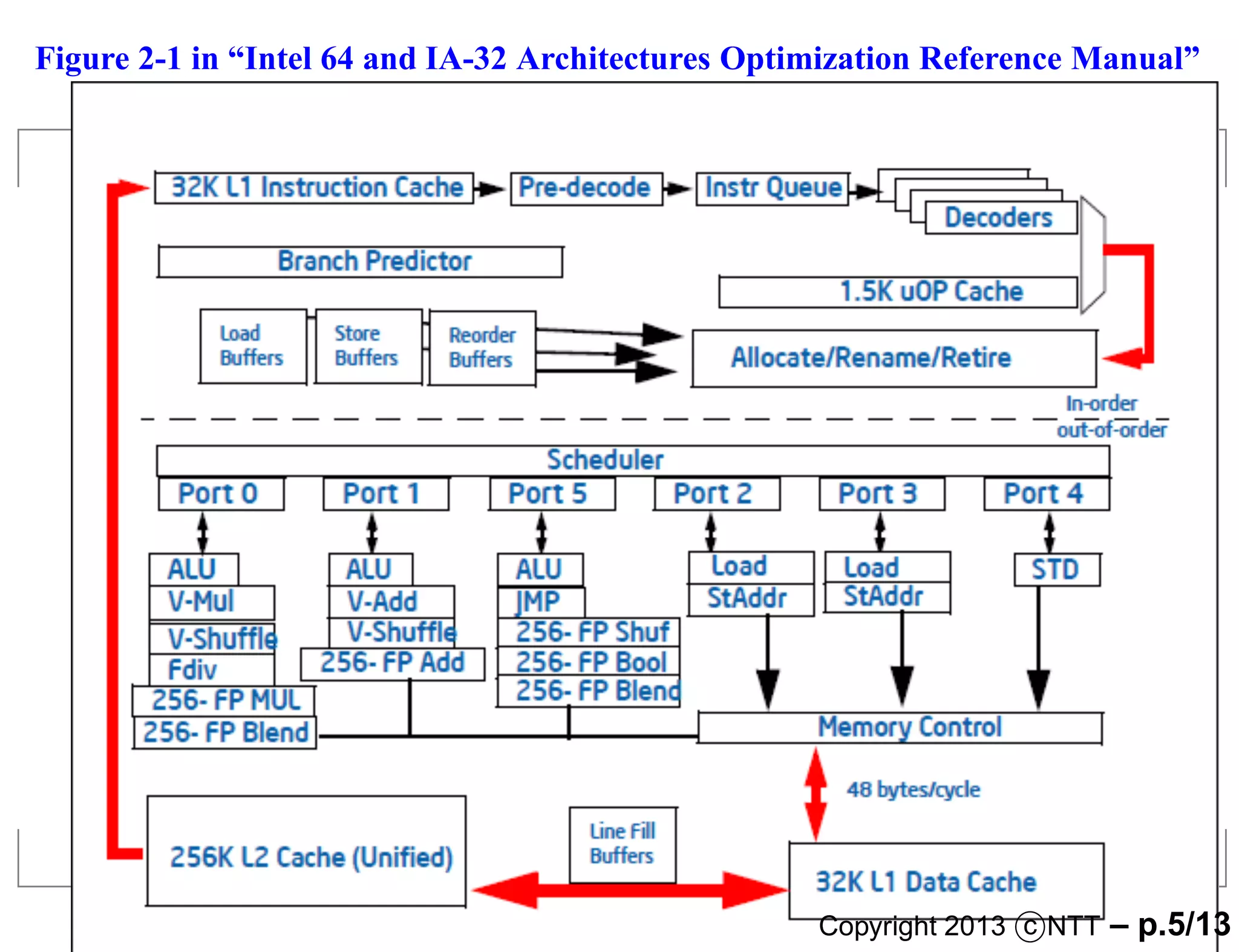
- 5.
Figure 2-1 in“Intel 64 and IA-32 Architectures Optimization Reference Manual”
Copyright 2013 c NTT – p.5/13
- 6.
AES-NI
aesenc: 暗号化 1段
aesenclast: 暗号化最終段
aesdec: 復号 1 段
aesdeclast: 復号最終段
aeskeygenassist: 鍵スケジュールの
一部
aesimc: 復号用鍵スケジュールのの一部
AVX 環境: 「v」つき命令利用可、w/o ymm
Copyright 2013 c NTT – p.6/13
- 7.
AES-128 実装例
pxor xmm15, xmm0
aesenc xmm15, xmm1
aesenc xmm15, xmm2
aesenc xmm15, xmm3
aesenc xmm15, xmm4
aesenc xmm15, xmm5
aesenc xmm15, xmm6
aesenc xmm15, xmm7
aesenc xmm15, xmm8
aesenc xmm15, xmm9
aesenclast xmm15, xmm10
xmm15: I/O, xmm0∼xmm10: 副鍵
Copyright 2013 c NTT – p.7/13
- 8.
aes{enc,dec}{,last}の特性 (文献)
Intel Fog
SB WM SB WM
latency 8 6 8 ∼5
throughput 1 2 4 ∼2
p015 2
SB: Sandy Bridge, WM: Westmere
Intel: Intel 64 and IA-32 Architectures Optimization
Reference Manual
Fog: http://www.agner.org/optimize/
Copyright 2013 c NTT – p.8/13
- 9.
aes{enc,dec}{,last}の特性 (IACA)
Ryad Benadjila:“Use of AES Instruction Set” @
AES Day 2012
https://www.cosic.esat.kuleuven.be/ecrypt/AESday/
IACA: Intel Architecture Code Analyzer より
Sandy Bridge:
p01: 2×0.5µop×(latency 7, throughput 1)
p5: 1µop×(latency 1, throughput 1)
Westmere:
p0: 2µop×(latency 4, throughput 1)
p5: 1µop×(latency 1, throughput 1)
Copyright 2013 c NTT – p.9/13
- 10.
妄想
理論性能の限界 (ECB):
(1/3 +1 × 10)/16 = 0.646 cpb
暗号処理にはメモリロードとかループ処
理とかいるだろう
port 1 ALU とか load/store は十分空いてい
そうだ
ほぼ理論性能が出るんじゃないだろうか
Copyright 2013 c NTT – p.10/13
- 11.
現実
0.702 cpb まではいけた@ C intrinsic
0.853 cpb @ OpenSSL 1.0.1c よりは速いが
1 cycle/block ぐらい取られている
何故???
Copyright 2013 c NTT – p.11/13
- 12.
実験
独立データのaesenc をいっぱい並べる
途中に単純な命令を 1 つ入れてみる
何をどういれても 1 cycle 遅くなる
Sandy Bridge ではレジスタ zero クリアは
register renaming で終了
これをいれると…やっぱり 1 cycle 遅い
結論: MSROM 命令 (?)
MSROM 命令: 1 cycle に 1 命令しか decode 出
来ない
Copyright 2013 c NTT – p.12/13
- 13.
Best Current Practice
出来る限り aes{enc,dec}{,last}は
連続して並べる
他の命令を混ぜる場合は 4 命令ずつ
(4-1-1-1 template にあわせて) いれる
おまけ: aes{enc,dec}{,last} のデータ
は little endian friendly。数値計算をする場合
は endian 変換が必要。
Copyright 2013 c NTT – p.13/13