More Related Content

PPTX

PDF

PDF
競技プログラミングにおけるコードの書き方とその利便性 
PPTX

PDF

PDF

PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning 
PDF
What's hot

PDF

PDF

PDF

PDF

PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~ 
PDF

PDF

PDF
Prophet入門【Python編】Facebookの時系列予測ツール 
PDF

PDF

PDF

PPTX
AtCoder Beginner Contest 002 解説 
PDF

PDF

PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展 
PDF
AtCoder Beginner Contest 015 解説 
PDF

PDF
計算論的学習理論入門 -PAC学習とかVC次元とか- 
PPTX

PDF
Viewers also liked

PDF

PDF

PDF

PDF

PDF
Amortize analysis of Deque with 2 Stack 
PPTX
AtCoder Beginner Contest 004 解説 
PDF
Similar to 計算量

PPTX

PPTX

PDF

PDF

PPTX

PDF
実践・最強最速のアルゴリズム勉強会 第三回講義資料(ワークスアプリケーションズ & AtCoder) 
PDF

PDF

PDF

PDF
AtCoder Beginner Contest 020 解説 
PDF
計算量のはなし(Redisを使うなら必読!O(logN)など) 
PDF

KEY
Algebraic DP: 動的計画法を書きやすく 
PDF
翔泳社 「C++ ゼロからはじめるプログラミング」対応 C++学習教材(三谷純) 
PDF
AtCoder Regular Contest 017 
PPTX

PDF
Seminar on Quantum Computation & Quantum Information part19 More from Ken Ogura

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

ODP

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF
計算量
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
制限からの計算量予想
●
N 10^6 →O(N)≦ もしくは O(N log N)
●
N 10^5 → O(N log N)≦ もしくは O(N log^2 N)
● N 3000 → O(N ^ 2)≦
●
N 500 → O(N ^ 3)≦ の中でも早いもの
● N 100 → O(N ^ 3)≦
●
N 50 → O(N ^ 5)≦ くらいまでいける
●
N 20 → O(2 ^ N)≦ もしくは O(N * 2 ^ N)
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
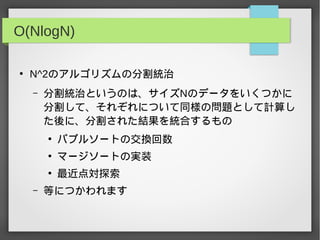
O(log N)
●
std:set, std:map,std:priority_queueのクエリ
– C++のライブラリから得られる便利なデータ構造
– 順序付き集合、辞書、順序付きキュー
●
平衡二分探索木のクエリ
– 探索、質問、更新、追加、削除、併合、分割
– 右に行くほど実装が重い
- 28.
- 29.
- 30.
- 31.
- 32.


















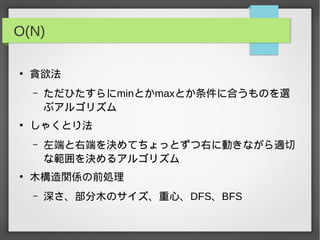

![O(N)
●
1~Nまでの数字の逆元の取得
– inv[x] = -inv[MOD % x] * (MOD / x);
– という漸化式を使う方法
– 組み合わせ関係の式の前処理において多用
●
aho corasick法による文字列探索
– 探索対象文字列から文字列群の各要素を検出するアル
ゴリズム](https://image.slidesharecdn.com/random-130916115309-phpapp02/85/slide-20-320.jpg)