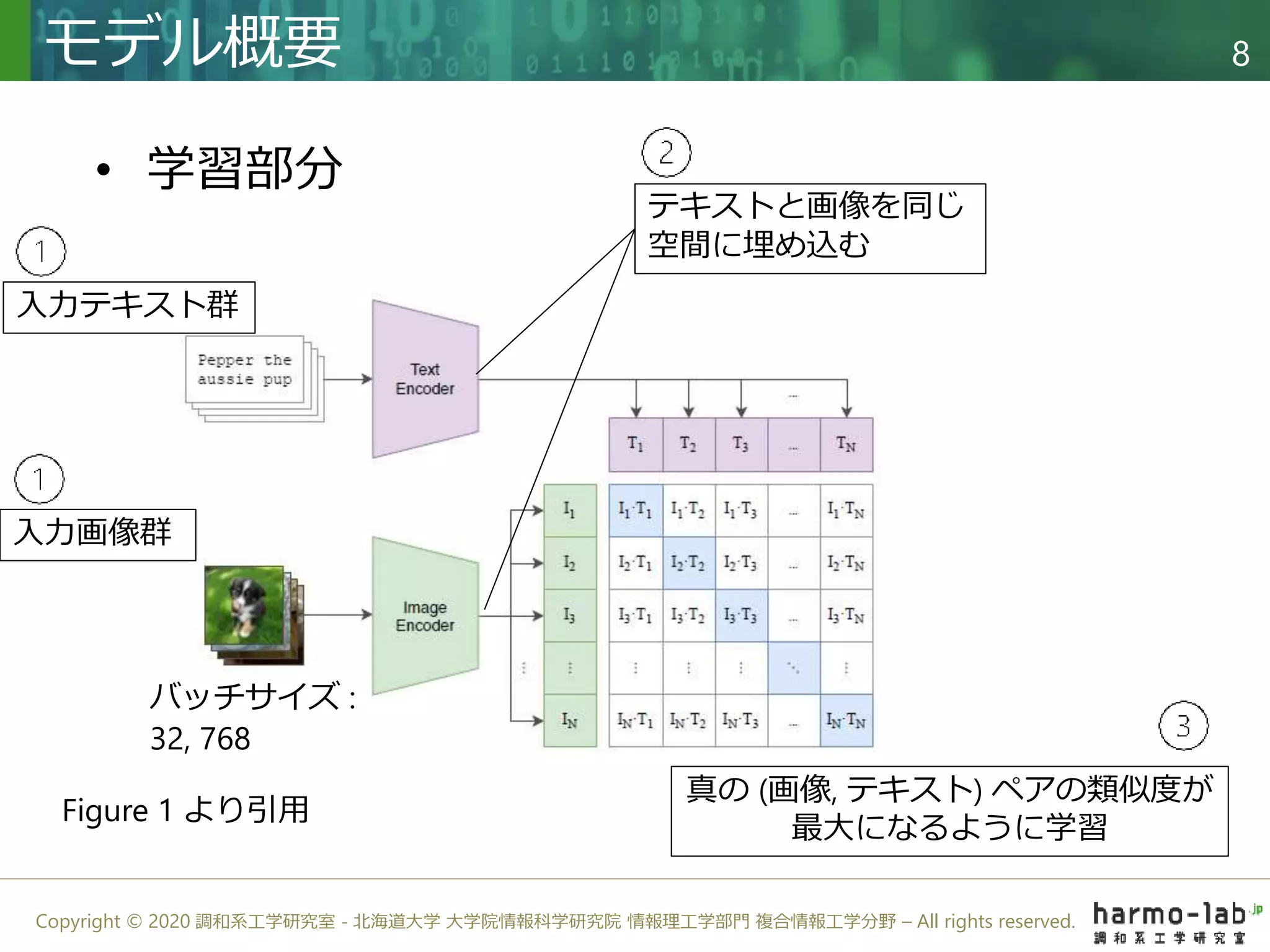
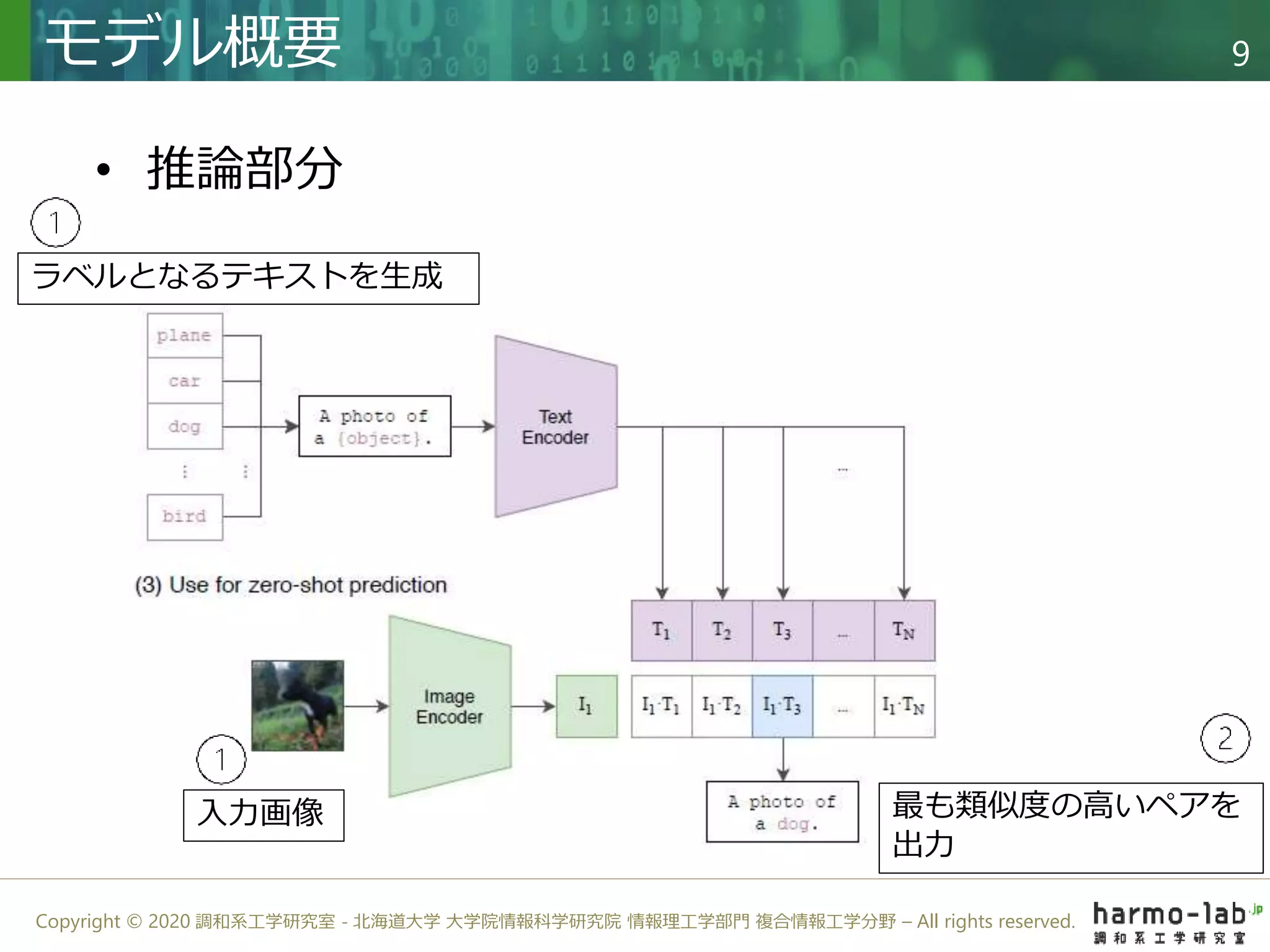
近年、NLP分野で成功している大規模事前学習、転移学習のシステムを CV分野に応用し、zero-shot 条件下でも性能を発揮する分類モデル CLIP を提案しました。 自然言語と画像を結びつけるタスクを設定することで、従来の分類モデルよりもラベルに対する拡張性の高いモデルを学習することに成功しました。 学習に用いたWeb 上から収集した(画像, テキスト)ペアの4億組のデータセットはGitHub上で公開されています。





![Copyright © 2020 調和系工学研究室 - 北海道大学 大学院情報科学研究院 情報理工学部門 複合情報工学分野 – All rights reserved.
Copyright © 2020 調和系工学研究室 - 北海道大学 大学院情報科学研究院 情報理工学部門 複合情報工学分野 – All rights reserved.
6
背景 – モチベーション
• 従来手法
– NLP 分野では Web 上などから大規模データを
収集、事前学習を行ったモデルが成功
• CV 分野にも応用できないだろうか?
– CV 分野では自然言語から学習する分類器の研究
は盛んではない
• 他の教師あり手法に及ぶ結果が出ていなかった
Ex) [1] では ImageNet に対して 11.5% の精度
• 筆者らの考え
– 従来手法ではデータの規模が小さく、モデルの
性能を十分に引き出せていない
[1] Li, A., Jabri, A., Joulin, A., and van der Maaten, L. Learning visual n-grams from web data. In
Proceedings of the IEEE International Conference on Computer Vision, pp. 4183–4192, 2017
大規模な (画像, テキスト) データの作成](https://image.slidesharecdn.com/20210929dlhirata-211006042622/75/2021-09-29_dl_hirata-6-2048.jpg)


![Copyright © 2020 調和系工学研究室 - 北海道大学 大学院情報科学研究院 情報理工学部門 複合情報工学分野 – All rights reserved.
• 筆者らの調べではCLIP と同様のアプローチを
とっている既存研究は [1] のみ
• 3つのデータセットでの性能を比較
Vision N-Gram[1] との比較 11
性能が向上](https://image.slidesharecdn.com/20210929dlhirata-211006042622/75/2021-09-29_dl_hirata-11-2048.jpg)





![Copyright © 2020 調和系工学研究室 - 北海道大学 大学院情報科学研究院 情報理工学部門 複合情報工学分野 – All rights reserved.
Copyright © 2020 調和系工学研究室 - 北海道大学 大学院情報科学研究院 情報理工学部門 複合情報工学分野 – All rights reserved.
17
Scaling-law の検証
• 個々のデータセットではかなりばらつきがみられる
– 分散の違いなどがノイズになっていると推測される
• 平均をとると Scaling-law に
則ていることが確かめられる
[2] で提案された Scaling-law が CLIP にも当ては
まることを確かめる
※ 薄い線が個々のデータセット、
濃い線が平均を表す
Transformer モデルの性能がパラメータ数、
データ数、計算量にべき乗則でスケーリ
ングされる
[2] Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D.
Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020](https://image.slidesharecdn.com/20210929dlhirata-211006042622/75/2021-09-29_dl_hirata-17-2048.jpg)


![Copyright © 2020 調和系工学研究室 - 北海道大学 大学院情報科学研究院 情報理工学部門 複合情報工学分野 – All rights reserved.
Copyright © 2020 調和系工学研究室 - 北海道大学 大学院情報科学研究院 情報理工学部門 複合情報工学分野 – All rights reserved.
20
ImageNet SOTAモデルとの比較
• 27のデータセット中21で [3]
を上回る結果
• 両者の差は事前学習が
WIT or ImageNet であること
– CLIP が勝るデータセット
(SST2, Country211 etc) は
WIT が包含する概念の広さが
要因と考えられる
– [3]が勝るデータセット
(CIFAR系など) は WIT に画質に
関するデータの水増しが
行われていないことに起因する
Noisy Student EfficientNet-L2 [3] との比較
[3] Xie, Q., Luong, M.-T., Hovy, E., and Le, Q. V. Self-training with noisy student improves imagenet classification. In
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10687–10698, 2020](https://image.slidesharecdn.com/20210929dlhirata-211006042622/75/2021-09-29_dl_hirata-20-2048.jpg)







































![[DL輪読会]It's not just size that maters small language models are also few sho...](https://cdn.slidesharecdn.com/ss_thumbnails/itsnotjustsizethatmaterssmalllanguagemodelsarealsofew-shotlearners-210910034516-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)




























