サンプル:Word CountFreebase isan open database of the world’s information, covering millions of topics inhundreds of categories. Drawing from large open data sets like Wikipedia, MusicBrainz,and the SEC archives, it contains structured information on many popular topics,including movies, music, people and locations – all reconciled and freely available. Thisinformation is supplemented by the efforts of a passionate global community of usersコードを書く方法:
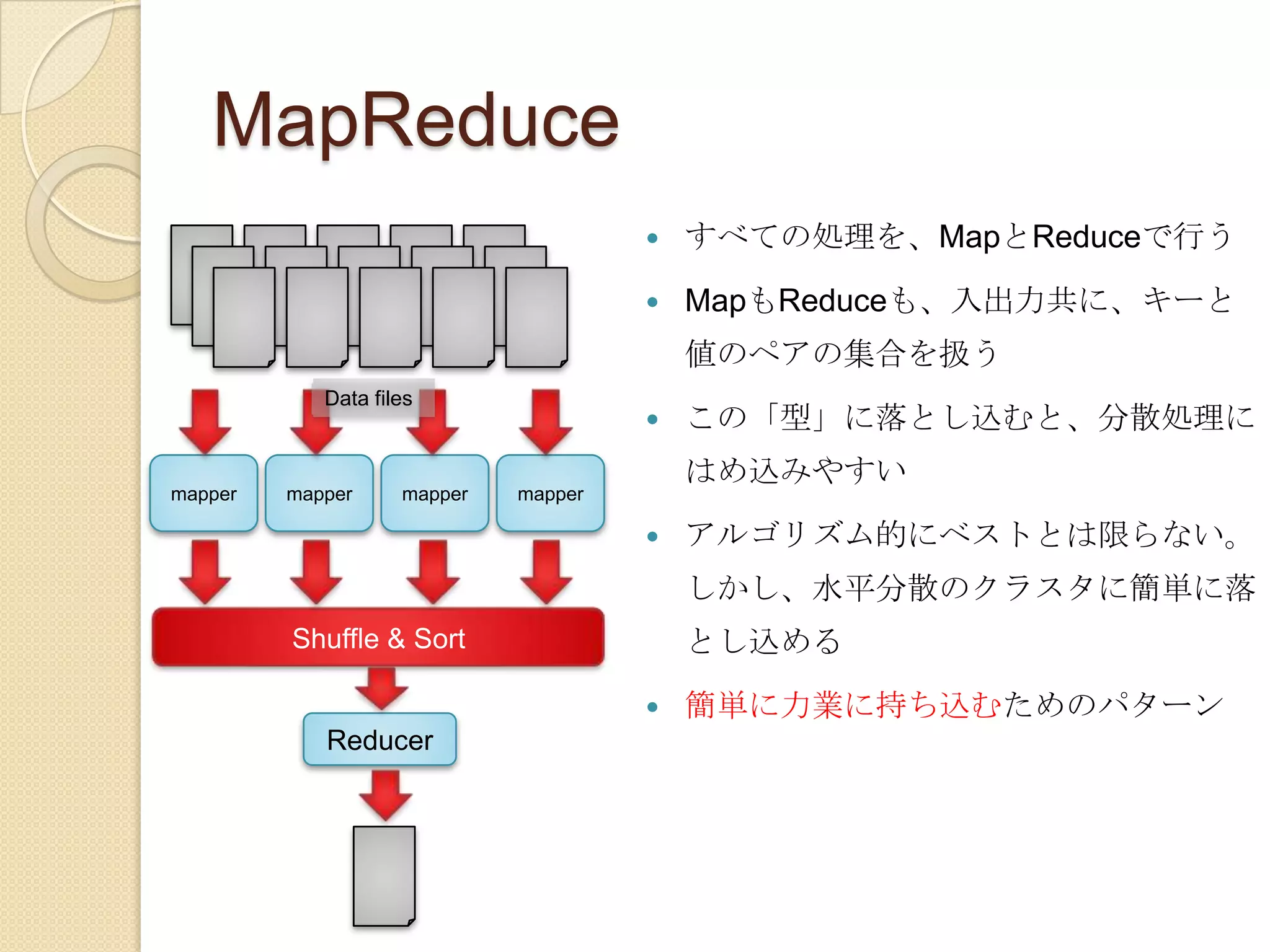
Java(これが標準)この他にも状況に応じていろいろなやり方があるので、HadoopConfefence Japan 2009の資料も参考にしてくださいHadoopによる入力(0,Freebase is an open database of the world’s information, covering millions of topics in...)(1, hundreds of categories. Drawing from large open data sets like Wikipedia, MusicBrainz,...)(2, and the SEC archives, it contains structured information on many popular topics,...)(3, including movies, music, people and locations – all reconciled and freely available. This...)(4, information is supplemented by the efforts of a passionate global community of users...)for line in sys.stdin:for word in line.split(): print word + “\t” + “1”mapタスクによる処理他のmapタスクによる処理(Freebase , 1)(is , 1)(an , 1)(open , 1)(database , 1)(MySQL, 1)(is, 1)(not, 1)(proprietary, −5)(database, 119)for aLine in sys.stdin:currentWord= aLine.split()[0] if currentWord == prevWord:count += 1else:print "%s\t%d" % (prevWord, count) count = 1prevWord= currentWordHadoopによるシャッフル(freebase, [1])(is, [1, 1])(an, [1])(open, [1])(database, [1, 1])reduceタスクによる処理(freebase, 1)(is, 2)(an, 1(open, 1)(database, 2)
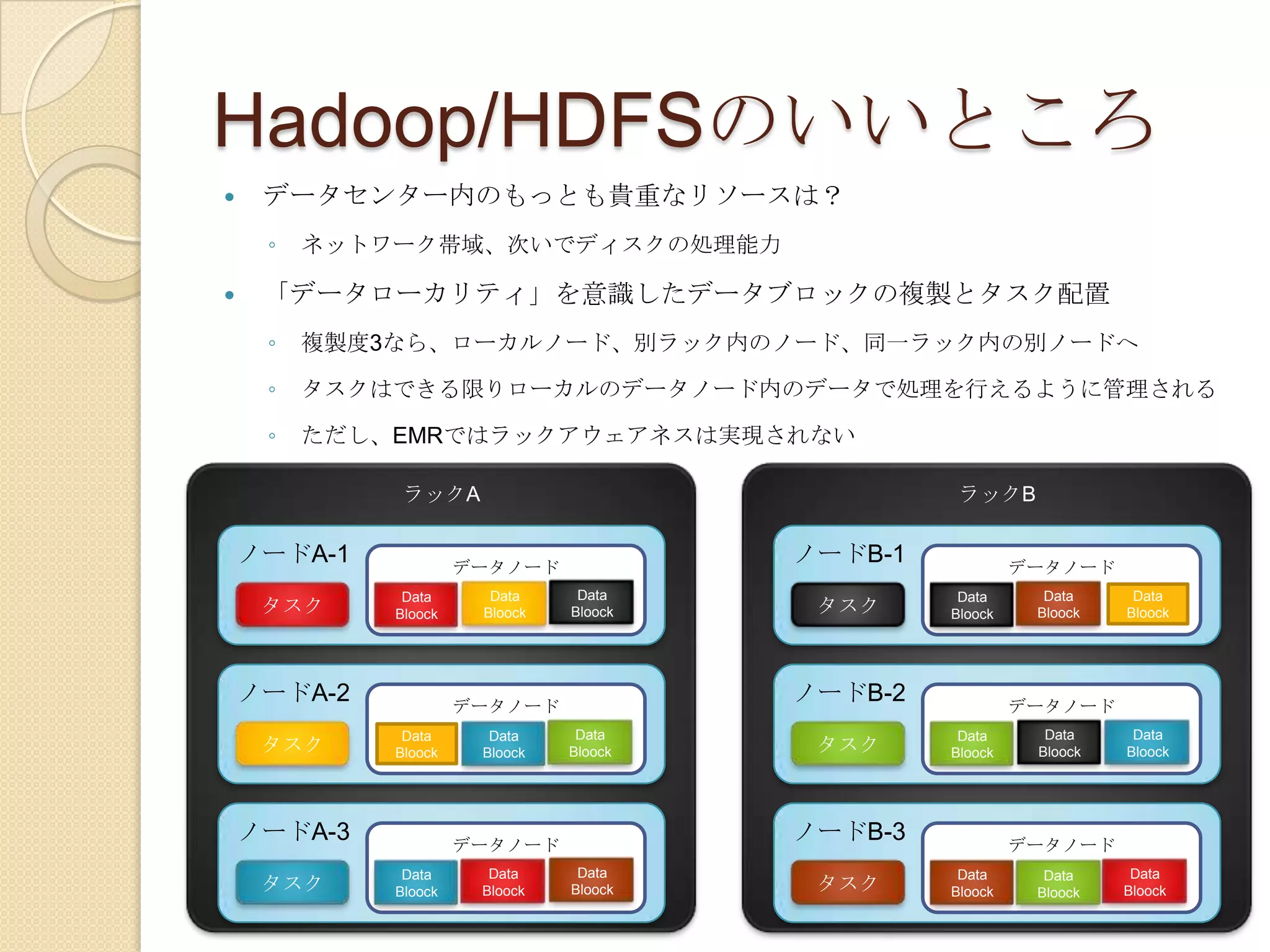
ローカル開発環境を用意してみたLinux(CentOS5)とCDH(Cloudera Distribution includingApache Hadoop) ver 3https://ccp.cloudera.com/display/SUPPORT/Downloads疑似分散モード(Psuedo Distribution mode)でインストールYumやaptを使って簡単にできますhttps://ccp.cloudera.com/display/CDHDOC/CDH3+Quick+Start+Guidehttps://ccp.cloudera.com/display/CDHDOC/CDH3+Installation+GuideデモンストレーションWikipediaでwordcountしょぼいサンプルですみません。ストリーミングでの実行方法は象本に載ってます














![Java(これが標準)この他にも状況に応じていろいろなやり方があるので、HadoopConfefence Japan 2009の資料も参考にしてくださいHadoopによる入力(0, Freebase is an open database of the world’s information, covering millions of topics in...)(1, hundreds of categories. Drawing from large open data sets like Wikipedia, MusicBrainz,...)(2, and the SEC archives, it contains structured information on many popular topics,...)(3, including movies, music, people and locations – all reconciled and freely available. This...)(4, information is supplemented by the efforts of a passionate global community of users...)for line in sys.stdin:for word in line.split(): print word + “\t” + “1”mapタスクによる処理他のmapタスクによる処理(Freebase , 1)(is , 1)(an , 1)(open , 1)(database , 1)(MySQL, 1)(is, 1)(not, 1)(proprietary, −5)(database, 119)for aLine in sys.stdin:currentWord= aLine.split()[0] if currentWord == prevWord:count += 1else:print "%s\t%d" % (prevWord, count) count = 1prevWord= currentWordHadoopによるシャッフル(freebase, [1])(is, [1, 1])(an, [1])(open, [1])(database, [1, 1])reduceタスクによる処理(freebase, 1)(is, 2)(an, 1(open, 1)(database, 2)](https://image.slidesharecdn.com/hadoop-emr-110619094822-phpapp01/75/Hadoop-Elastic-MapReduce-16-2048.jpg)












































































