Downloaded 148 times





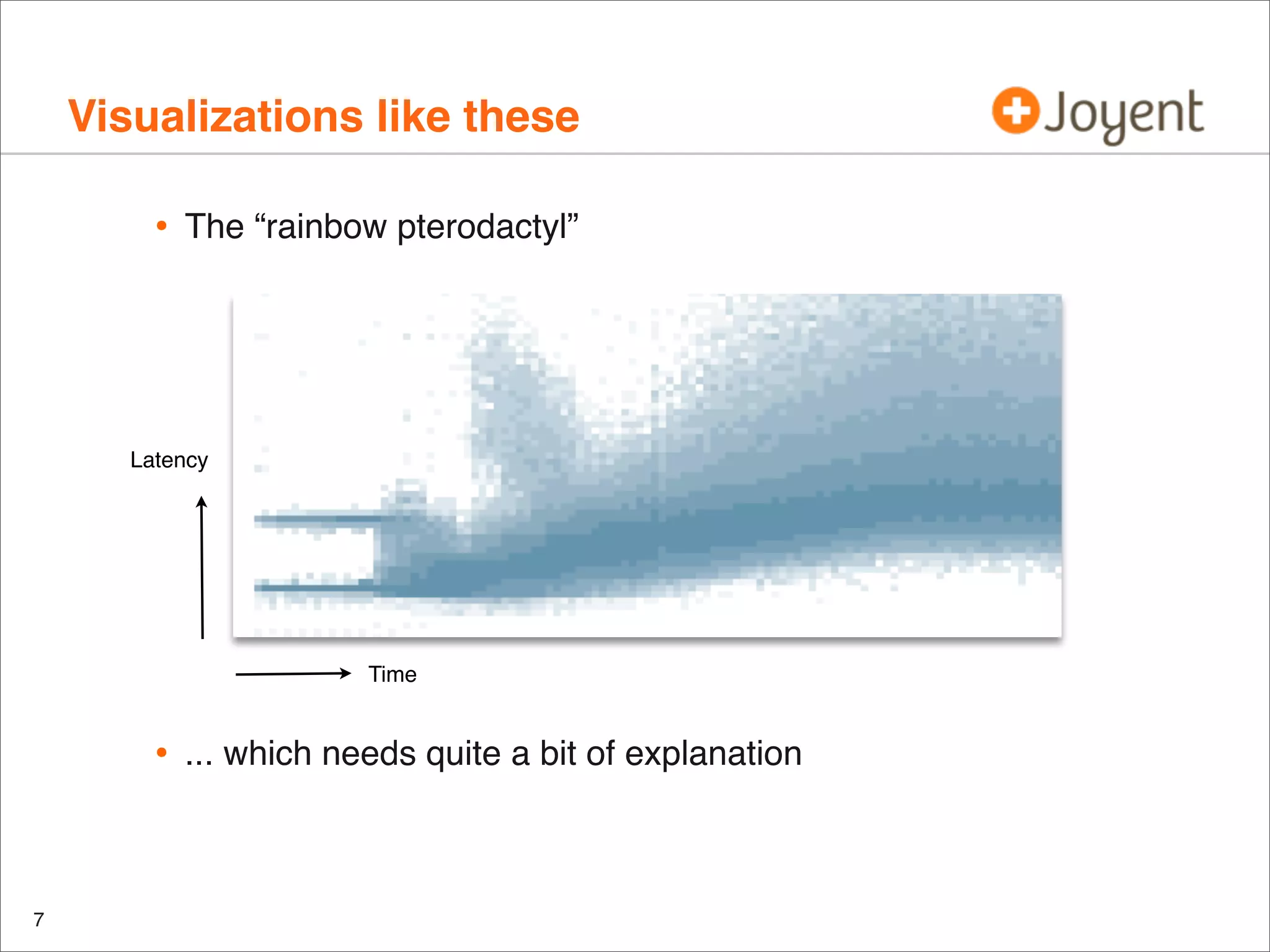



























![IOPS vs Utilization
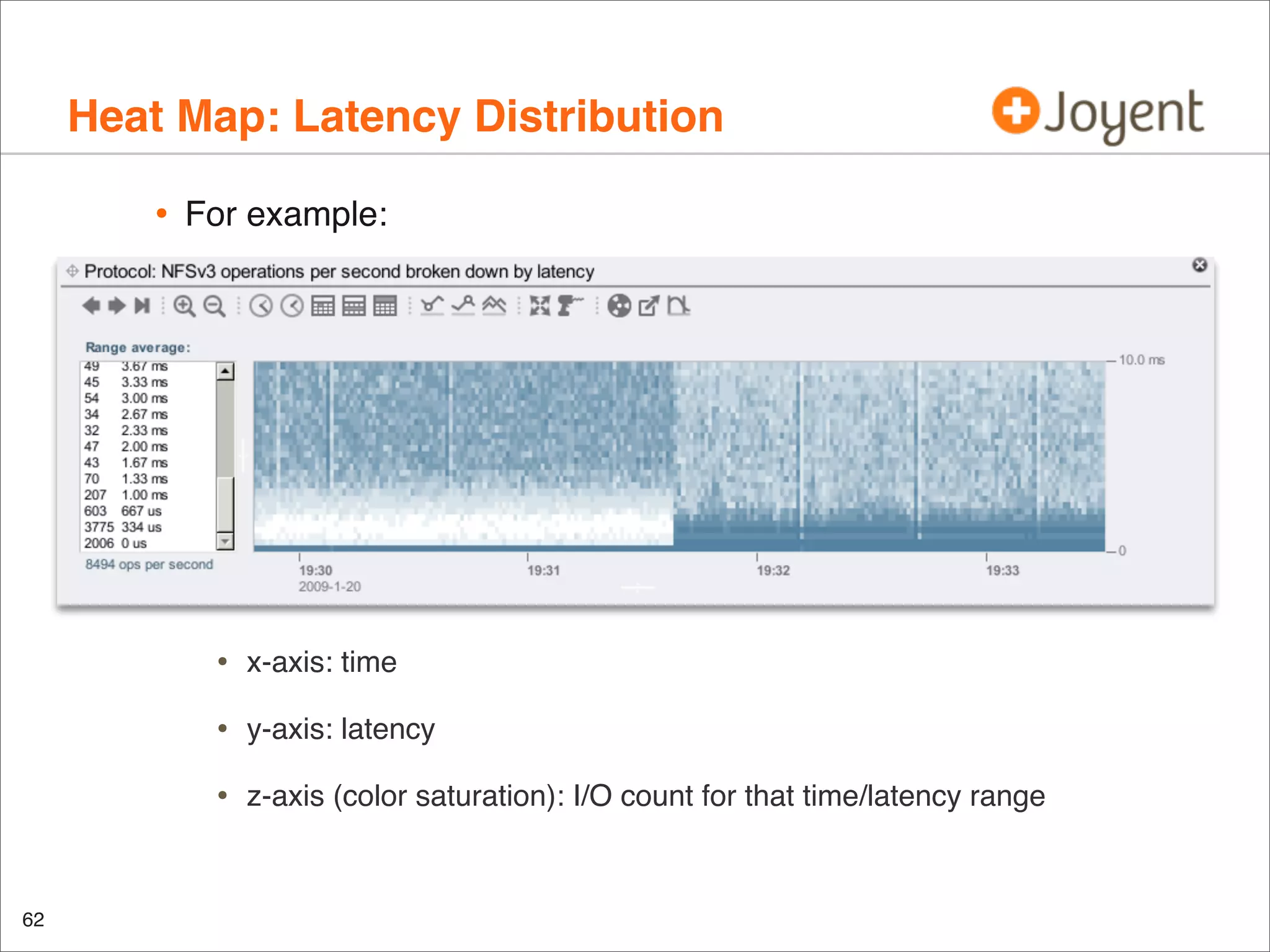
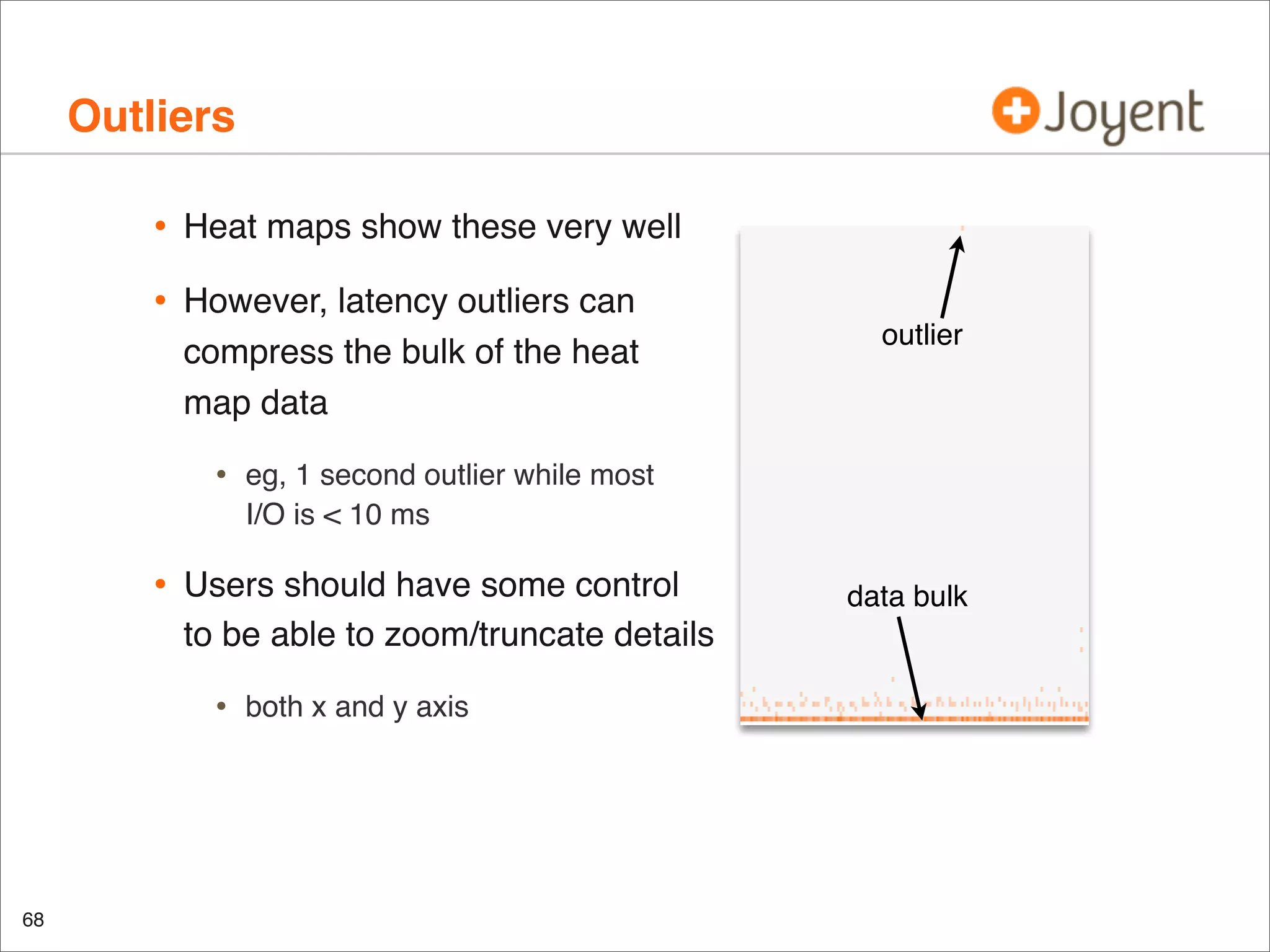
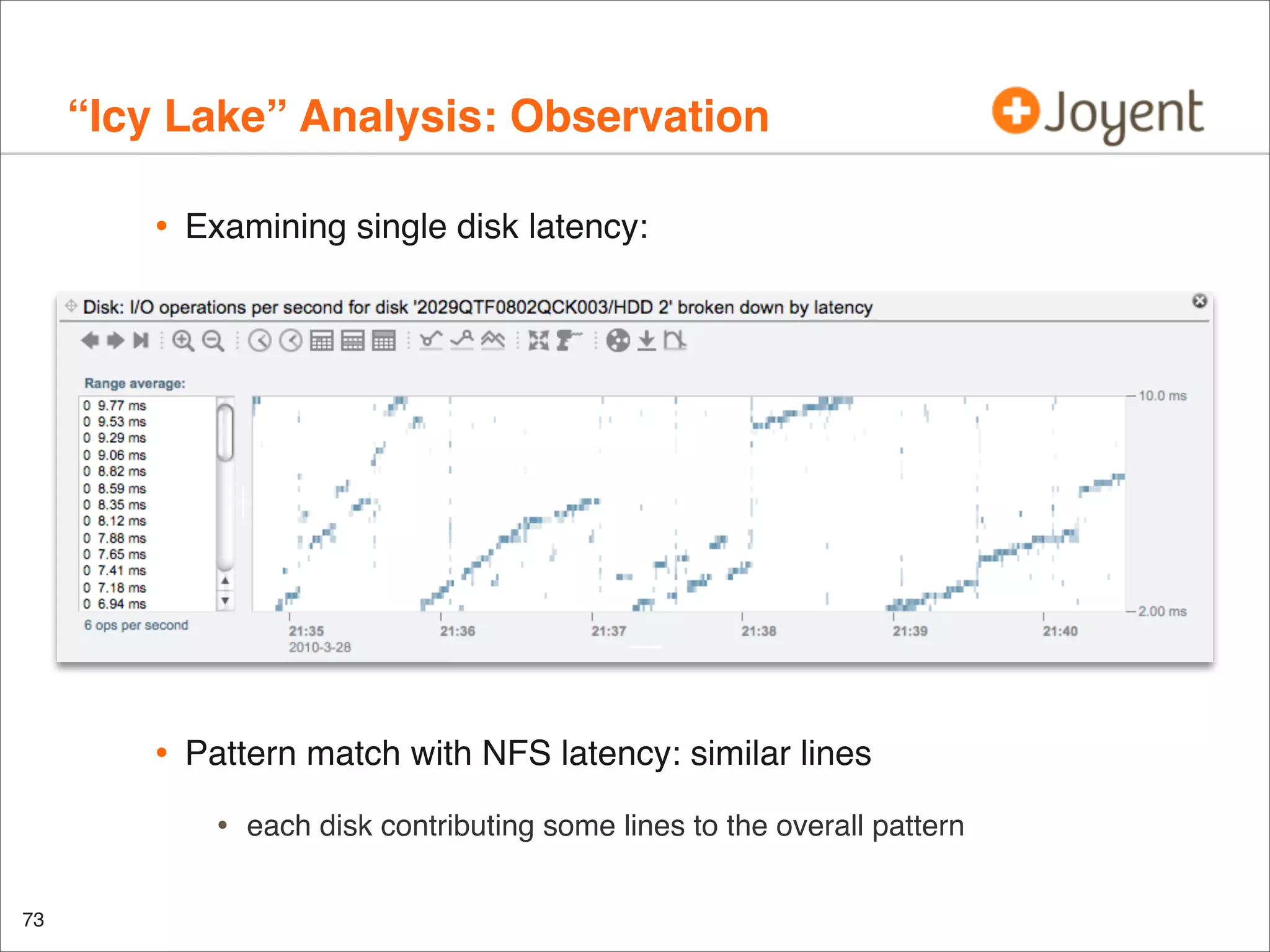
•
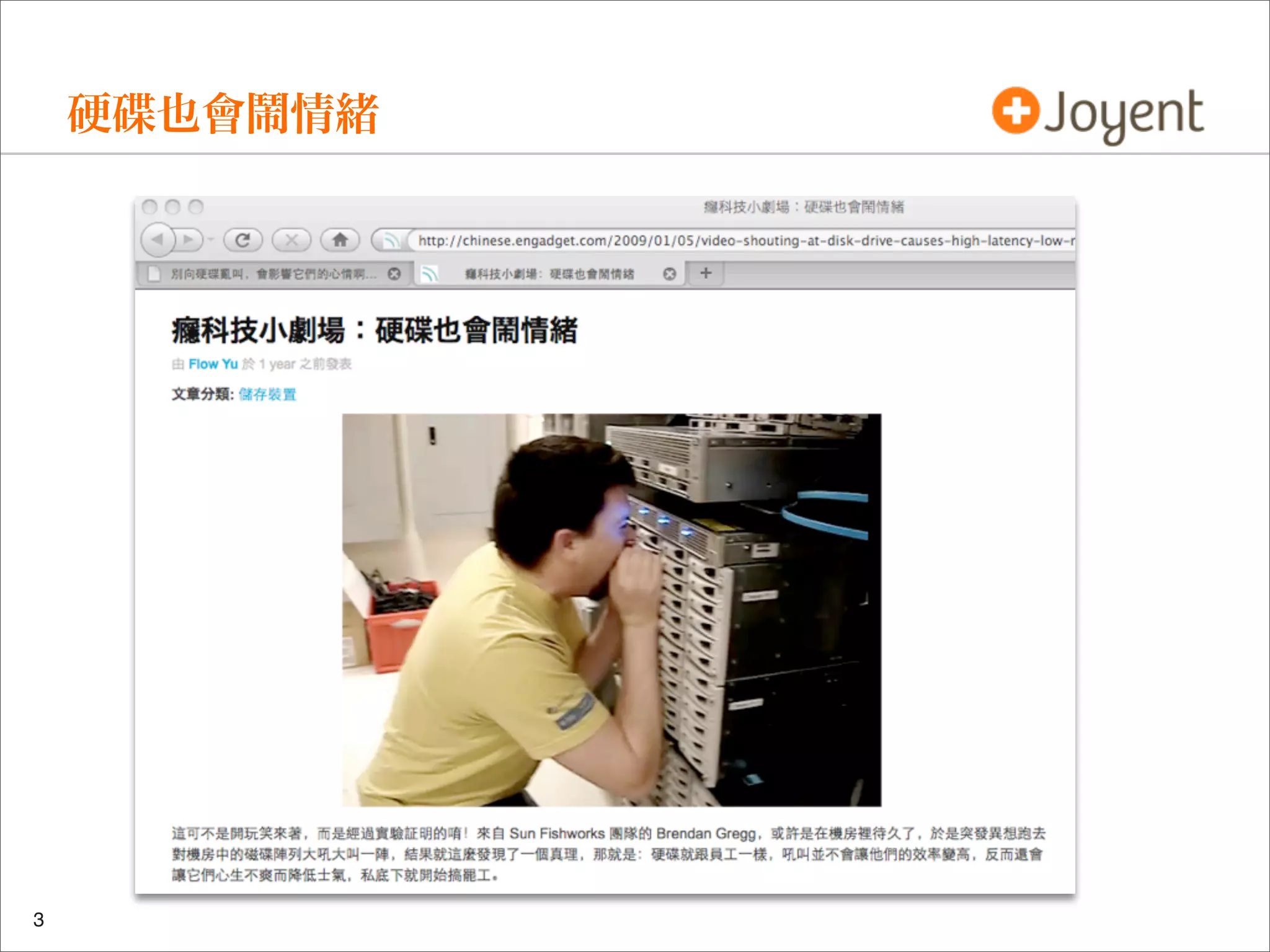
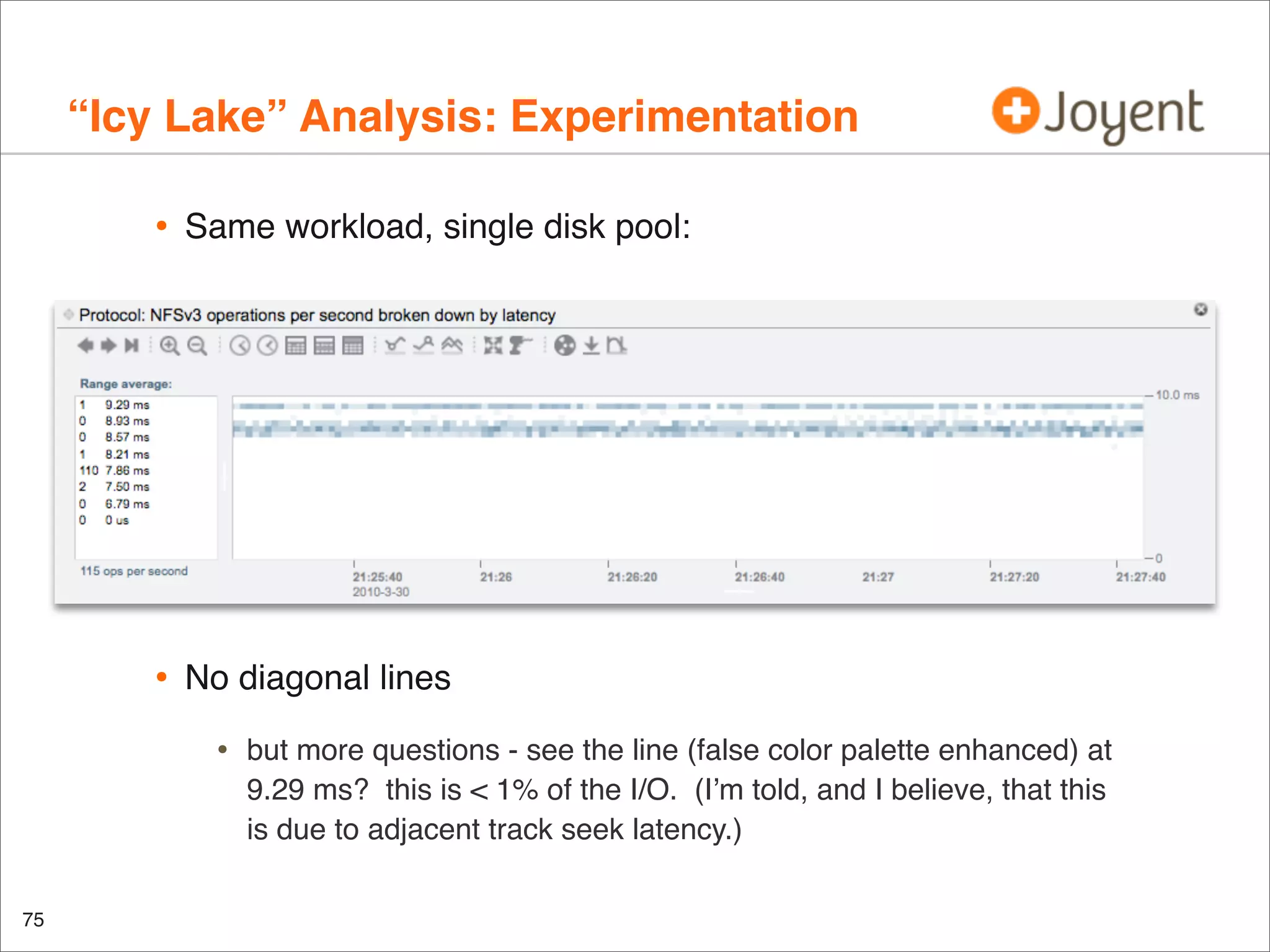
Another look at this disk:
r/s
86.6
[...]
r/s
21284.7
•
42
w/s
0.0
extended device statistics
kr/s
kw/s wait actv wsvc_t asvc_t
655.5
0.0 0.0 1.0
0.0
11.5
%w
0
%b device
99 c1d0
extended device statistics
w/s
kr/s
kw/s wait actv wsvc_t asvc_t %w %b device
0.0 10642.4
0.0 0.0 1.8
0.0
0.1
2 99 c1d0
Q. does this system need more spindles for IOPS capacity?](https://image.slidesharecdn.com/lisa2010visualizations-121206200321-phpapp02/75/LISA2010-visualizations-42-2048.jpg)
![IOPS vs Utilization
•
Another look at this disk:
r/s
86.6
[...]
r/s
21284.7
•
w/s
0.0
extended device statistics
kr/s
kw/s wait actv wsvc_t asvc_t
655.5
0.0 0.0 1.0
0.0
11.5
%b device
99 c1d0
extended device statistics
w/s
kr/s
kw/s wait actv wsvc_t asvc_t %w %b device
0.0 10642.4
0.0 0.0 1.8
0.0
0.1
2 99 c1d0
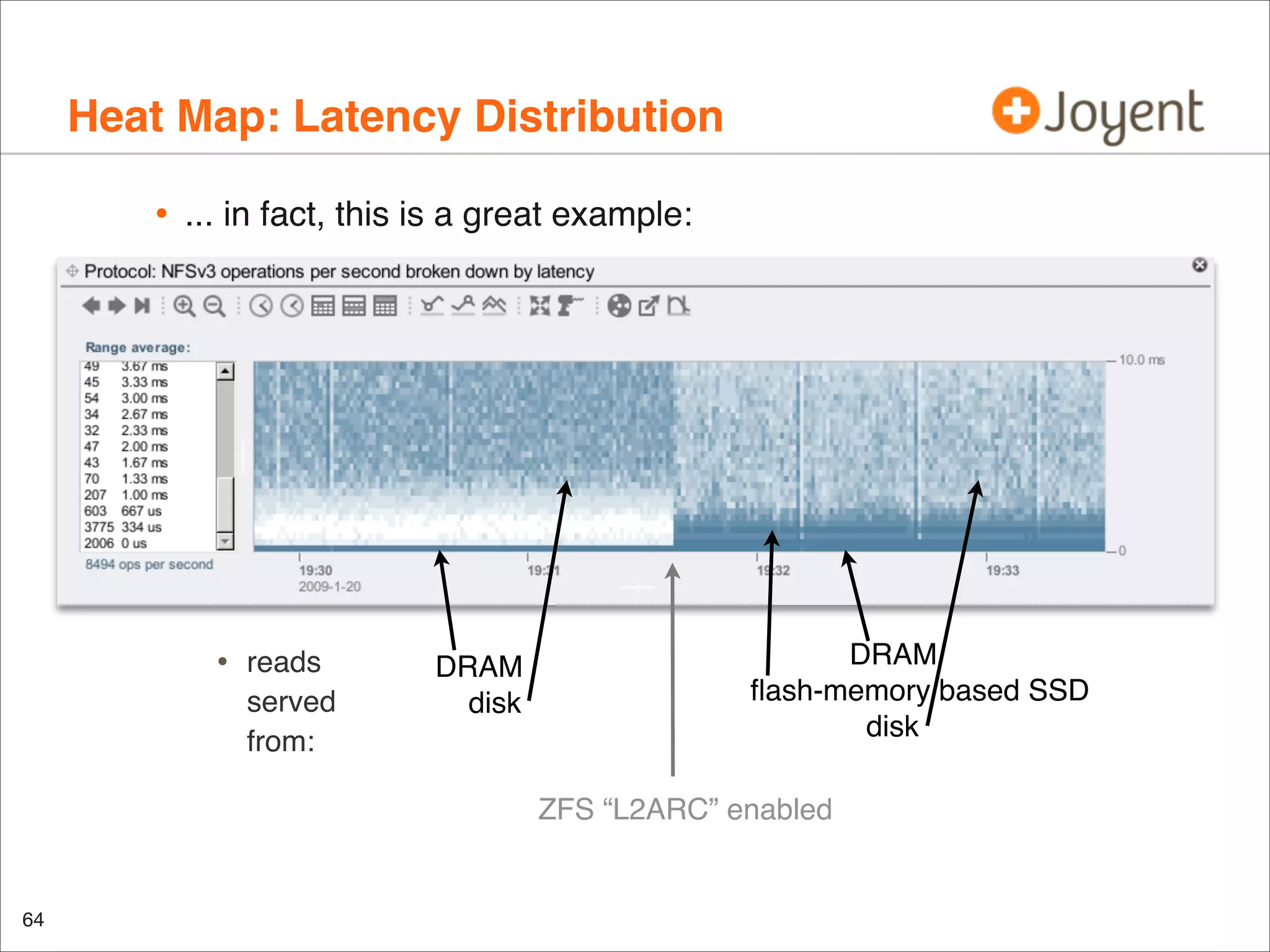
Q. does this system need more spindles for IOPS capacity?
•
IOPS (r/s + w/s): ???
•
43
%w
0
Utilization (%b): yes (even considering NCQ)](https://image.slidesharecdn.com/lisa2010visualizations-121206200321-phpapp02/75/LISA2010-visualizations-43-2048.jpg)
![IOPS vs Utilization
•
Another look at this disk:
r/s
86.6
[...]
r/s
21284.7
•
w/s
0.0
extended device statistics
kr/s
kw/s wait actv wsvc_t asvc_t
655.5
0.0 0.0 1.0
0.0
11.5
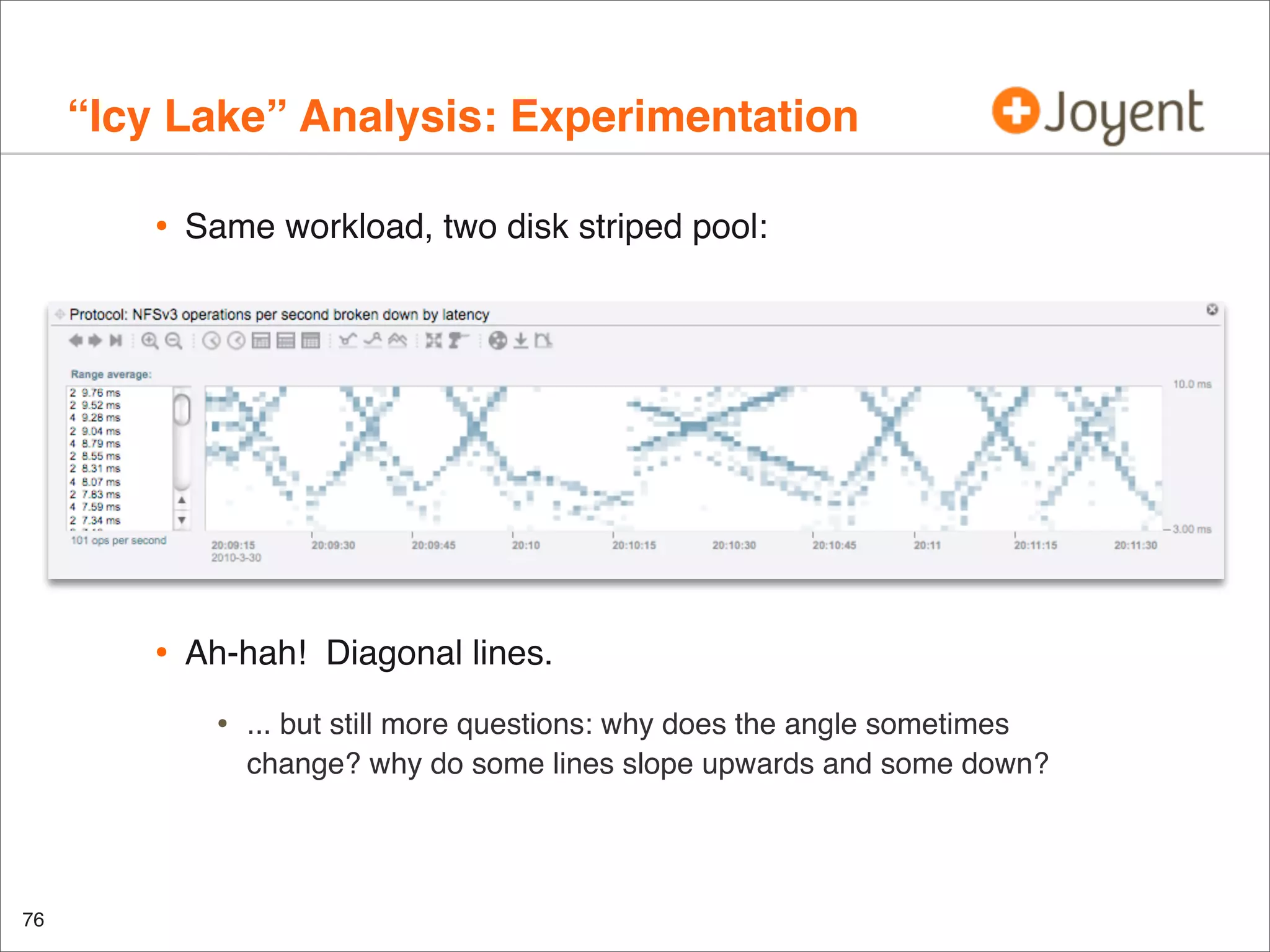
Q. does this system need more spindles for IOPS capacity?
IOPS (r/s + w/s): ???
•
Utilization (%b): yes (even considering NCQ)
•
44
%b device
99 c1d0
extended device statistics
w/s
kr/s
kw/s wait actv wsvc_t asvc_t %w %b device
0.0 10642.4
0.0 0.0 1.8
0.0
0.1
2 99 c1d0
•
•
%w
0
Latency (wsvc_t): no
Latency will identify the issue once it is an issue; utilization
will forecast the issue - capacity planning](https://image.slidesharecdn.com/lisa2010visualizations-121206200321-phpapp02/75/LISA2010-visualizations-44-2048.jpg)



![Latency
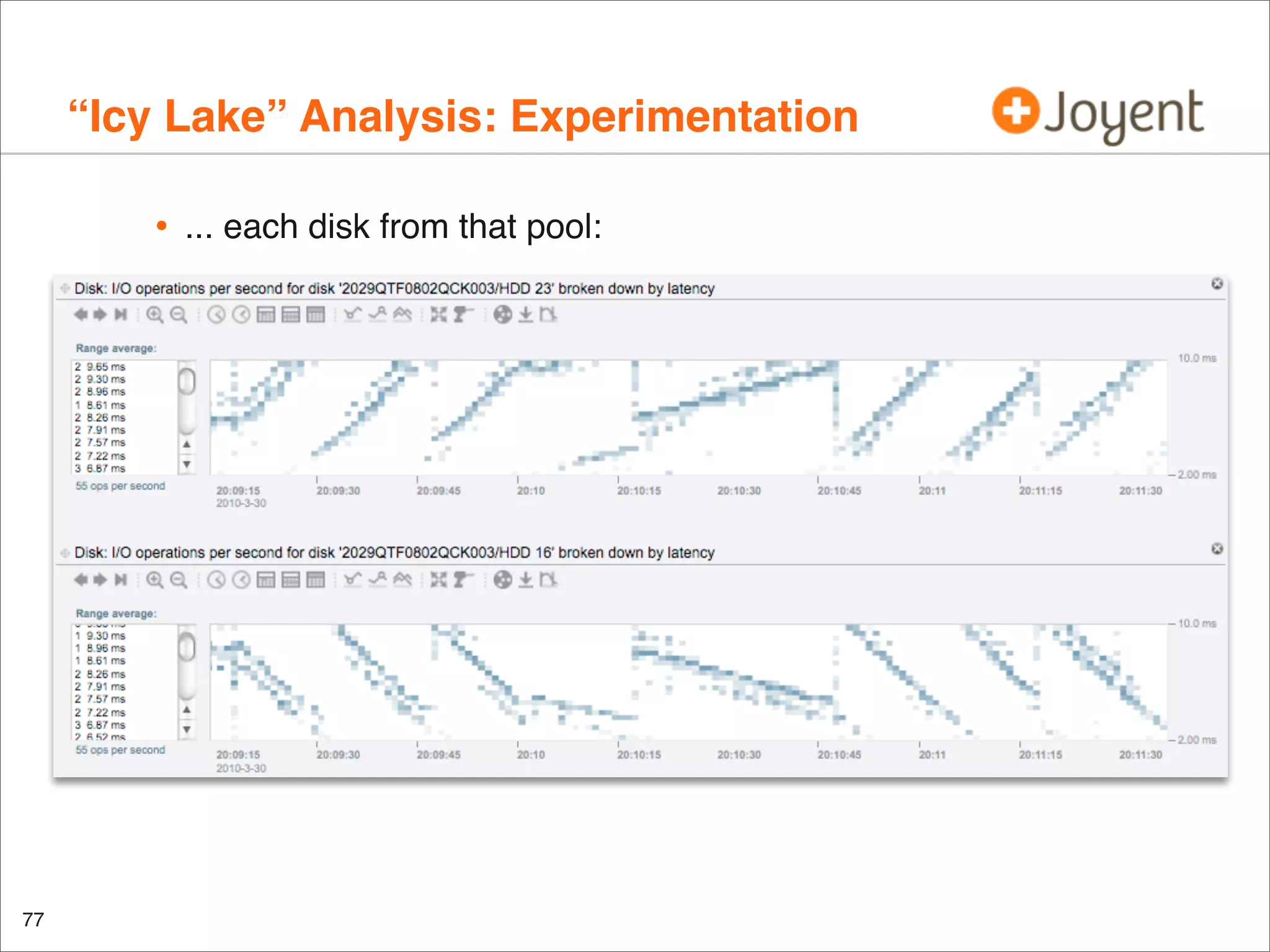
•
For example, disk I/O
•
Raw data looks like this:
# iosnoop -o
DTIME
UID
PID
125
100
337
138
100
337
127
100
337
135
100
337
118
100
337
108
100
337
87
100
337
9148
100
337
8806
100
337
2262
100
337
76
100
337
[...many pages of output...]
•
BLOCK
72608
72624
72640
72656
72672
72688
72696
113408
104738
13600
13616
SIZE
8192
8192
8192
8192
8192
4096
3072
8192
7168
1024
1024
COMM
bash
bash
bash
bash
bash
bash
bash
tar
tar
tar
tar
iosnoop is DTrace based
•
49
D
R
R
R
R
R
R
R
R
R
R
R
examines latency for every disk (back end) I/O
PATHNAME
/usr/sbin/tar
/usr/sbin/tar
/usr/sbin/tar
/usr/sbin/tar
/usr/sbin/tar
/usr/sbin/tar
/usr/sbin/tar
/etc/default/lu
/etc/default/lu
/etc/default/cron
/etc/default/devfsadm](https://image.slidesharecdn.com/lisa2010visualizations-121206200321-phpapp02/75/LISA2010-visualizations-49-2048.jpg)

![Summarizing Latency
•
iostat(1M) can show per second average:
$ iostat -xnz 1
[...]
r/s
471.0
r/s
631.0
w/s
0.0
r/s
472.0
[...]
51
w/s
7.0
w/s
0.0
extended
kr/s
kw/s
786.1
12.0
extended
kr/s
kw/s
1063.1
0.0
extended
kr/s
kw/s
529.0
0.0
device statistics
wait actv wsvc_t asvc_t
0.1 1.2
0.2
2.5
device statistics
wait actv wsvc_t asvc_t
0.2 1.0
0.3
1.6
device statistics
wait actv wsvc_t asvc_t
0.0 1.0
0.0
2.1
%w
4
%b device
90 c1d0
%w
9
%b device
92 c1d0
%w
0
%b device
94 c1d0](https://image.slidesharecdn.com/lisa2010visualizations-121206200321-phpapp02/75/LISA2010-visualizations-51-2048.jpg)

![Average/second
•
Average loses latency outliers
•
Average loses latency distribution
•
... but not disk distribution:
$ iostat -xnz 1
[...]
r/s
43.9
47.6
42.7
41.4
45.6
45.0
42.9
44.9
[...]
•
%w
0
0
0
0
0
0
0
0
%b
34
36
35
32
34
34
33
35
device
c0t5000CCA215C46459d0
c0t5000CCA215C4521Dd0
c0t5000CCA215C45F89d0
c0t5000CCA215C42A4Cd0
c0t5000CCA215C45541d0
c0t5000CCA215C458F1d0
c0t5000CCA215C450E3d0
c0t5000CCA215C45323d0
only because iostat(1M) prints this per-disk
•
53
w/s
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
extended device statistics
kr/s
kw/s wait actv wsvc_t asvc_t
351.5
0.0 0.0 0.4
0.0
10.0
381.1
0.0 0.0 0.5
0.0
9.8
349.9
0.0 0.0 0.4
0.0
10.1
331.5
0.0 0.0 0.4
0.0
9.6
365.1
0.0 0.0 0.4
0.0
9.2
360.3
0.0 0.0 0.4
0.0
9.4
343.5
0.0 0.0 0.4
0.0
9.9
359.5
0.0 0.0 0.4
0.0
9.3
but that gets hard to read for 100s of disks, per second!](https://image.slidesharecdn.com/lisa2010visualizations-121206200321-phpapp02/75/LISA2010-visualizations-53-2048.jpg)




![disklatency.d
•
not why we are here, but before someone asks...
#!/usr/sbin/dtrace -s
#pragma D option quiet
dtrace:::BEGIN
{
printf("Tracing... Hit Ctrl-C to end.n");
}
io:::start
{
start_time[arg0] = timestamp;
}
io:::done
/this->start = start_time[arg0]/
{
this->delta = (timestamp - this->start) / 1000;
@[args[1]->dev_statname, args[1]->dev_major, args[1]->dev_minor] =
quantize(this->delta);
start_time[arg0] = 0;
}
dtrace:::END
{
printa("
}
58
%s (%d,%d), us:n%@dn", @);](https://image.slidesharecdn.com/lisa2010visualizations-121206200321-phpapp02/75/LISA2010-visualizations-58-2048.jpg)

















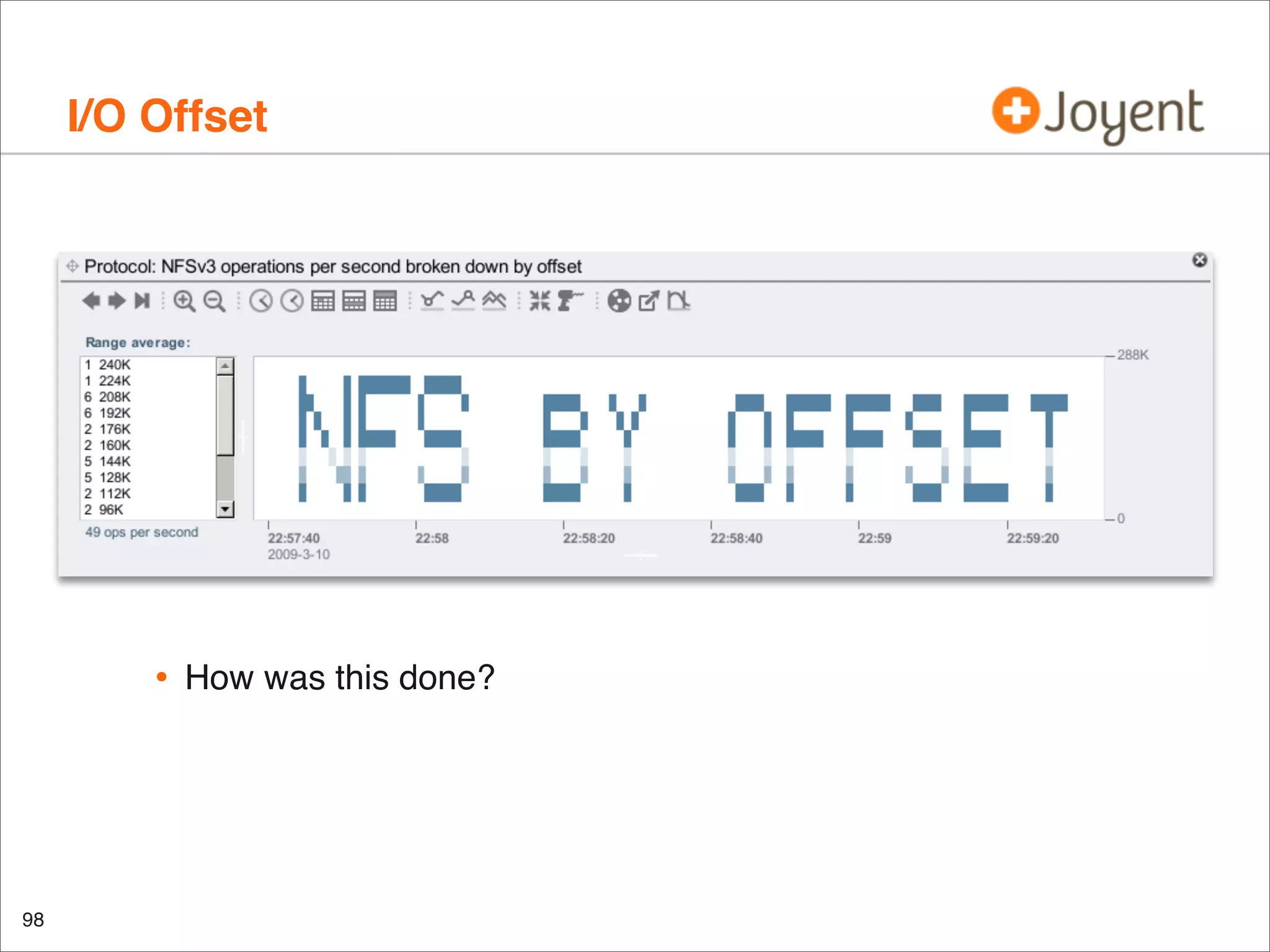



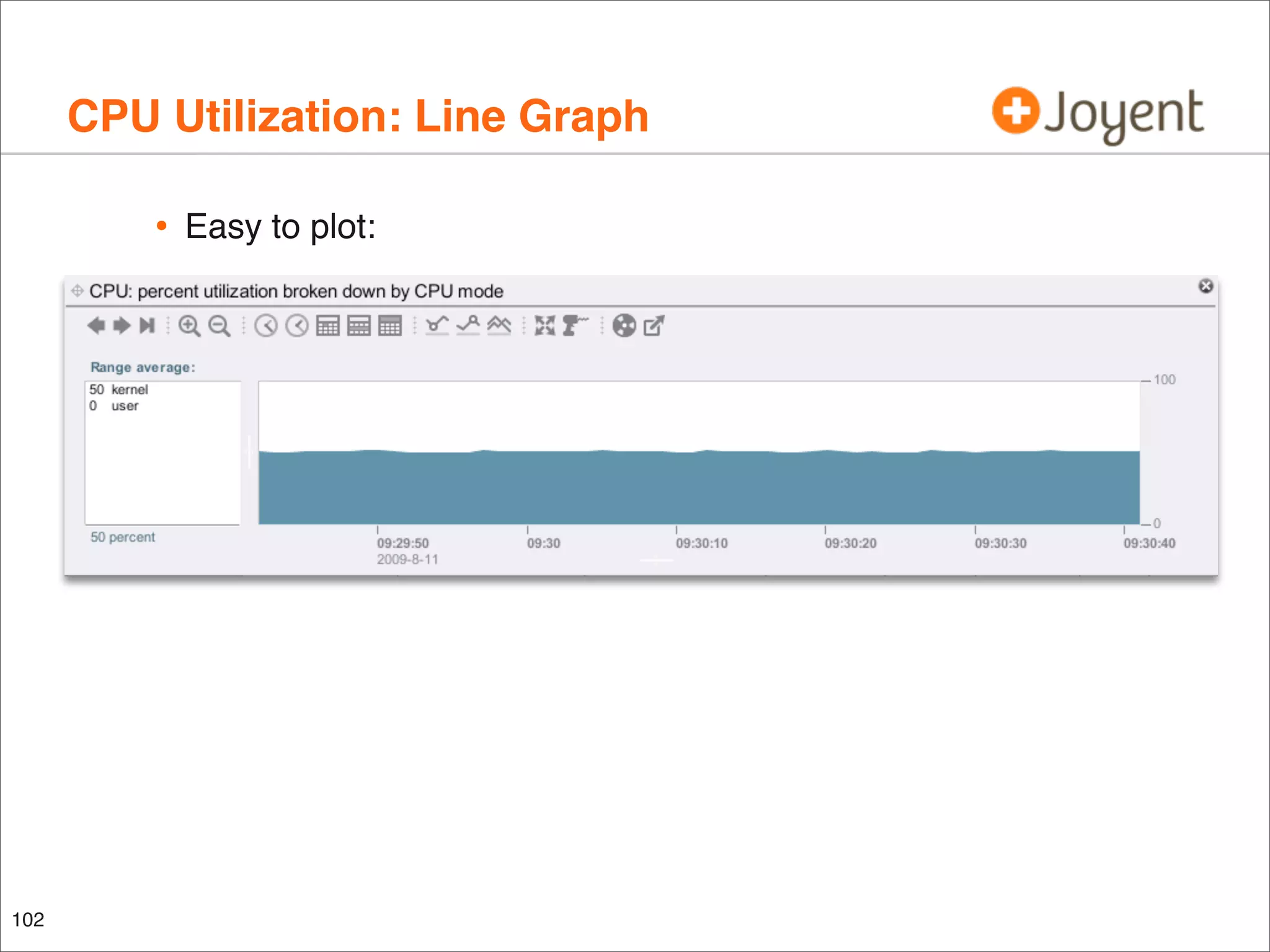
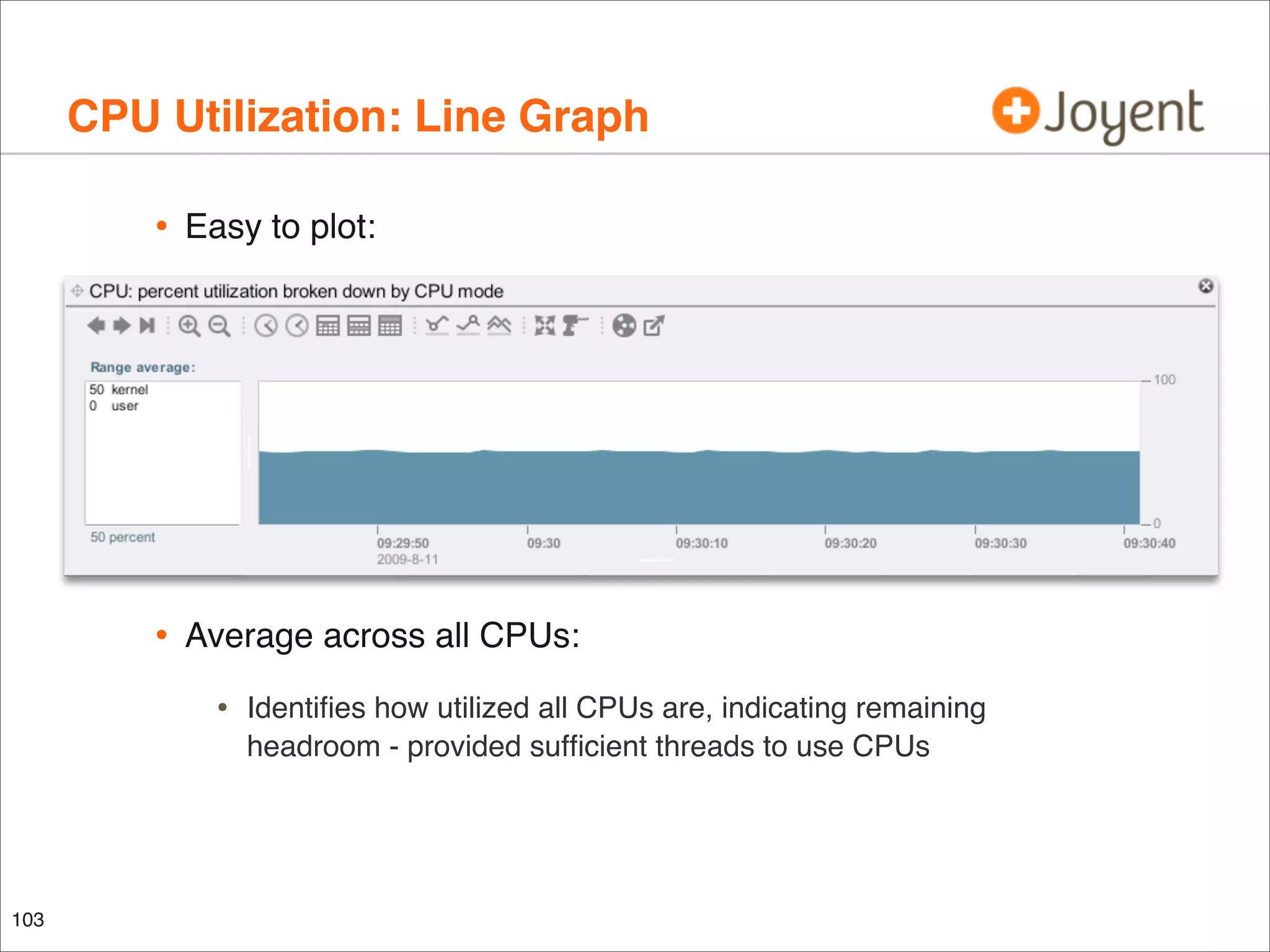
![CPU Utilization by CPU
•
mpstat(1M) can show utilization by-CPU:
$ mpstat 1
[...]
CPU minf mjf xcal
0
0
0
2
1
0
0
0
2
0
0
0
3
0
0
0
4
0
0
0
5
0
0
0
6
2
0
0
7
0
0
0
8
0
0
0
9
0
0
30
10
0
0
0
11
0
0
0
12
0
0
0
13
38
0
15
14
0
0
0
15
0
0
0
•
csw icsw migr smtx
315
0
24
4
190
0
12
4
152
0
12
1
274
1
21
3
229
0
9
2
138
0
7
3
296
0
8
2
0
9
0
1
311
0
22
2
274
0
16
4
445
0
13
7
303
0
7
8
312
0
10
1
336
2
10
1
209
0
10
38
10
0
4
2
can identify a single hot CPU (thread)
•
104
intr ithr
313 105
65
28
64
20
127
74
32
5
46
19
109
32
30
8
169
68
111
54
69
29
78
36
74
34
456 285
2620 2497
20
8
and un-balanced configurations
srw syscl
0 1331
0
576
0
438
0
537
0
902
0
521
0 1266
0
0
0
847
0
868
0 2559
0 1041
0 1250
0 1408
0
259
0
2
usr sys
5
1
1
1
0
1
1
1
1
1
1
0
4
0
100
0
2
1
2
0
7
1
2
0
7
1
5
2
1
3
0
0
wt idl
0 94
0 98
0 99
0 98
0 98
0 99
0 96
0
0
0 97
0 98
0 92
0 98
0 92
0 93
0 96
0 100](https://image.slidesharecdn.com/lisa2010visualizations-121206200321-phpapp02/75/LISA2010-visualizations-104-2048.jpg)

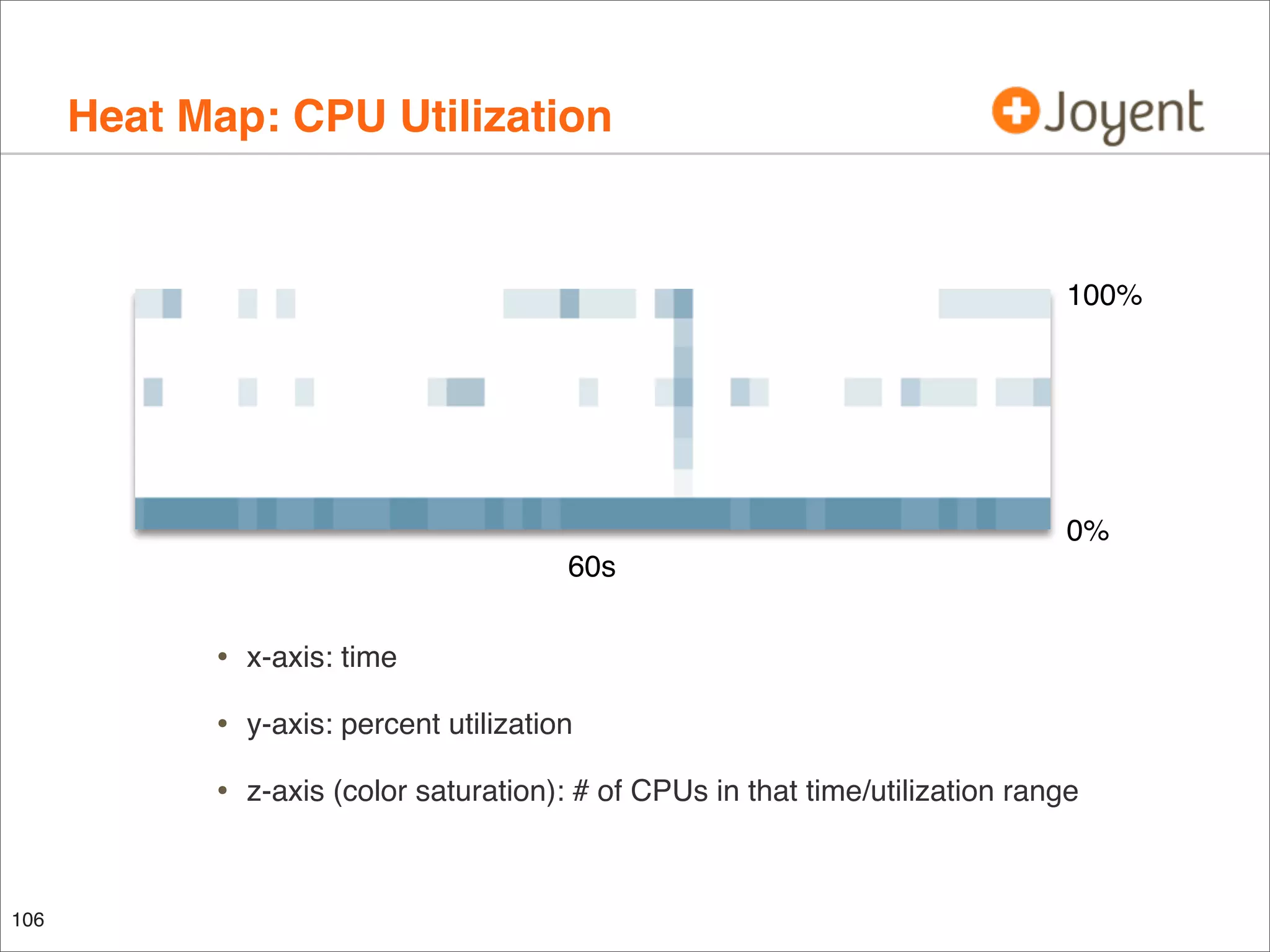
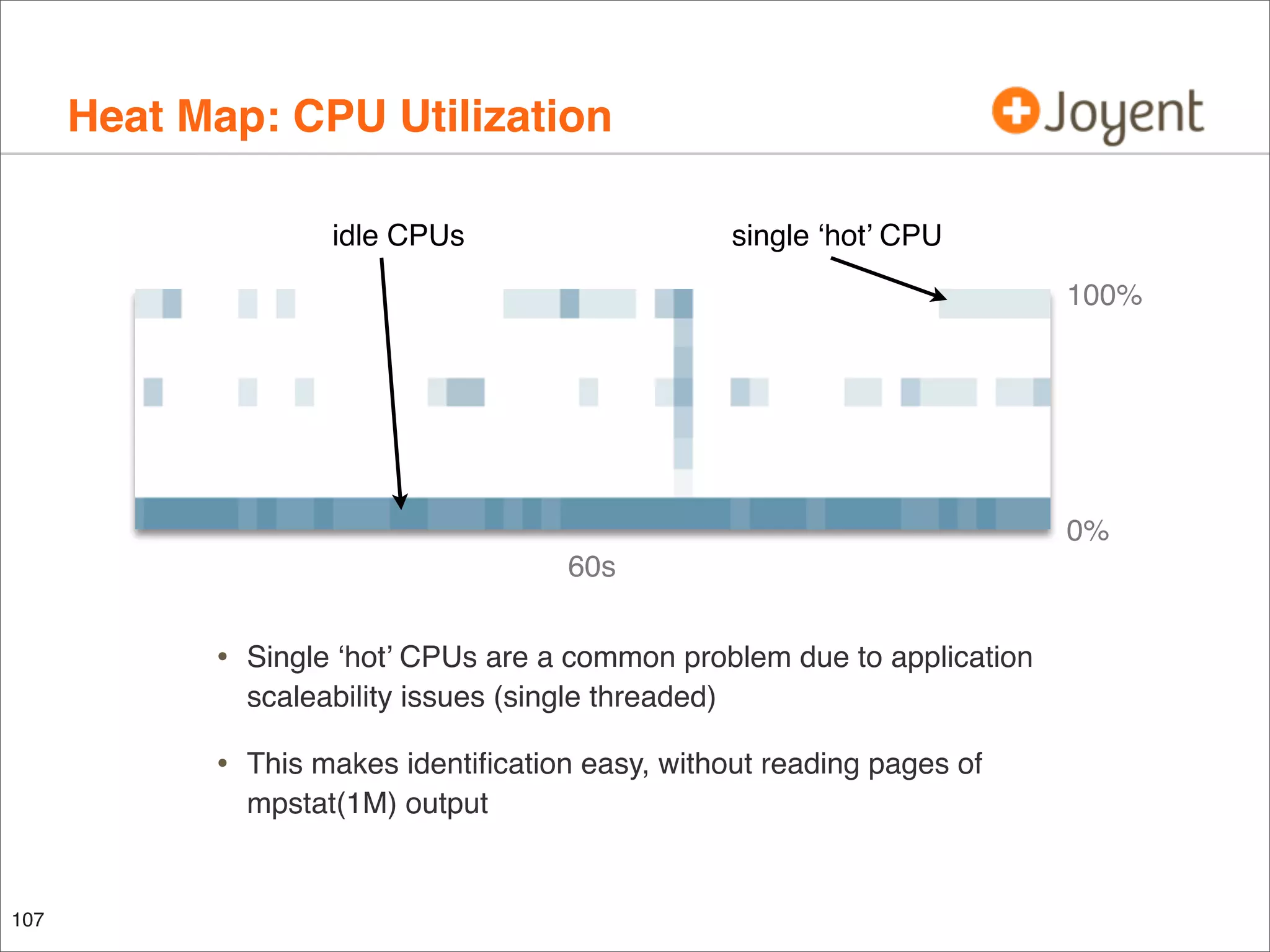















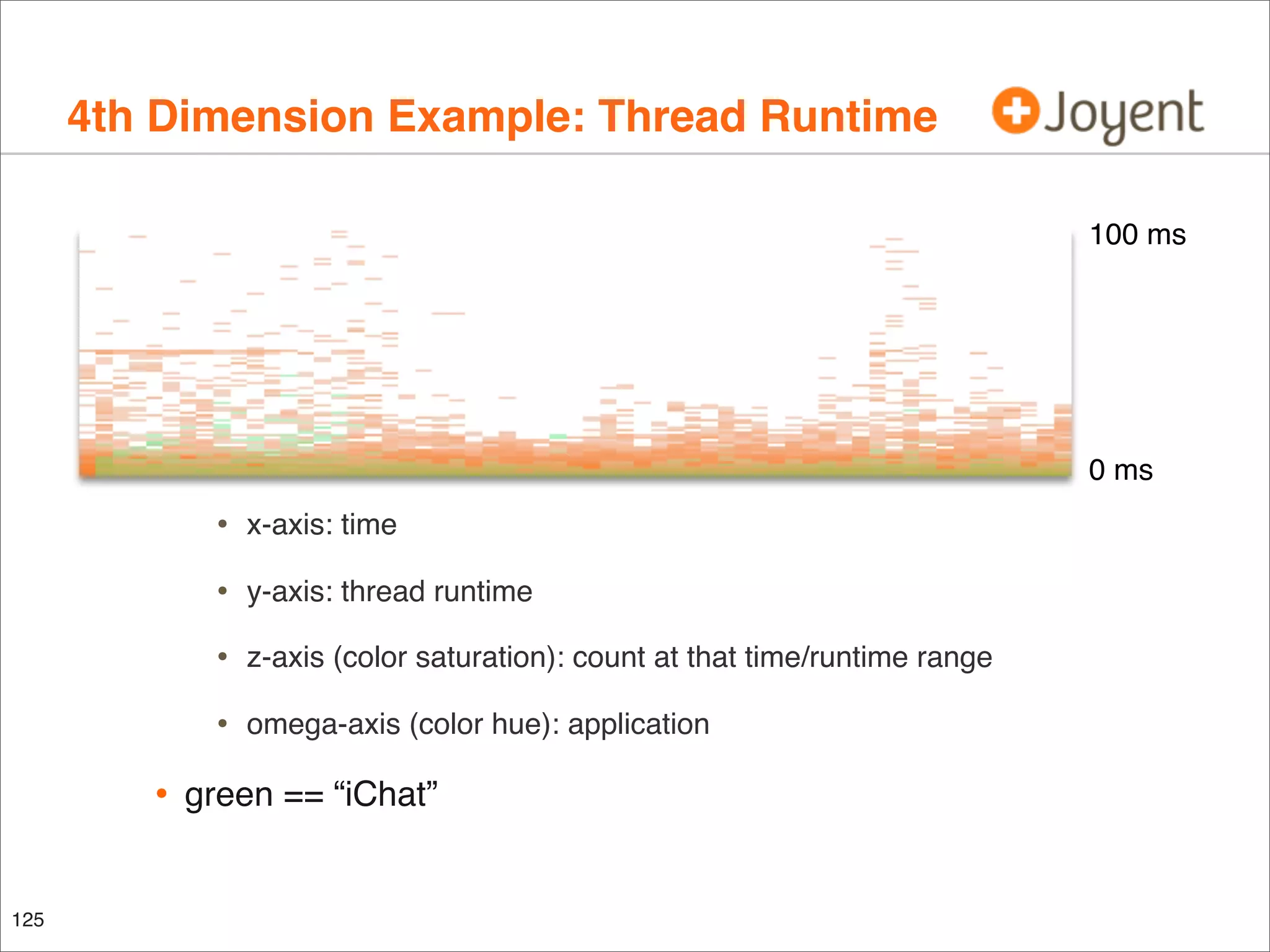

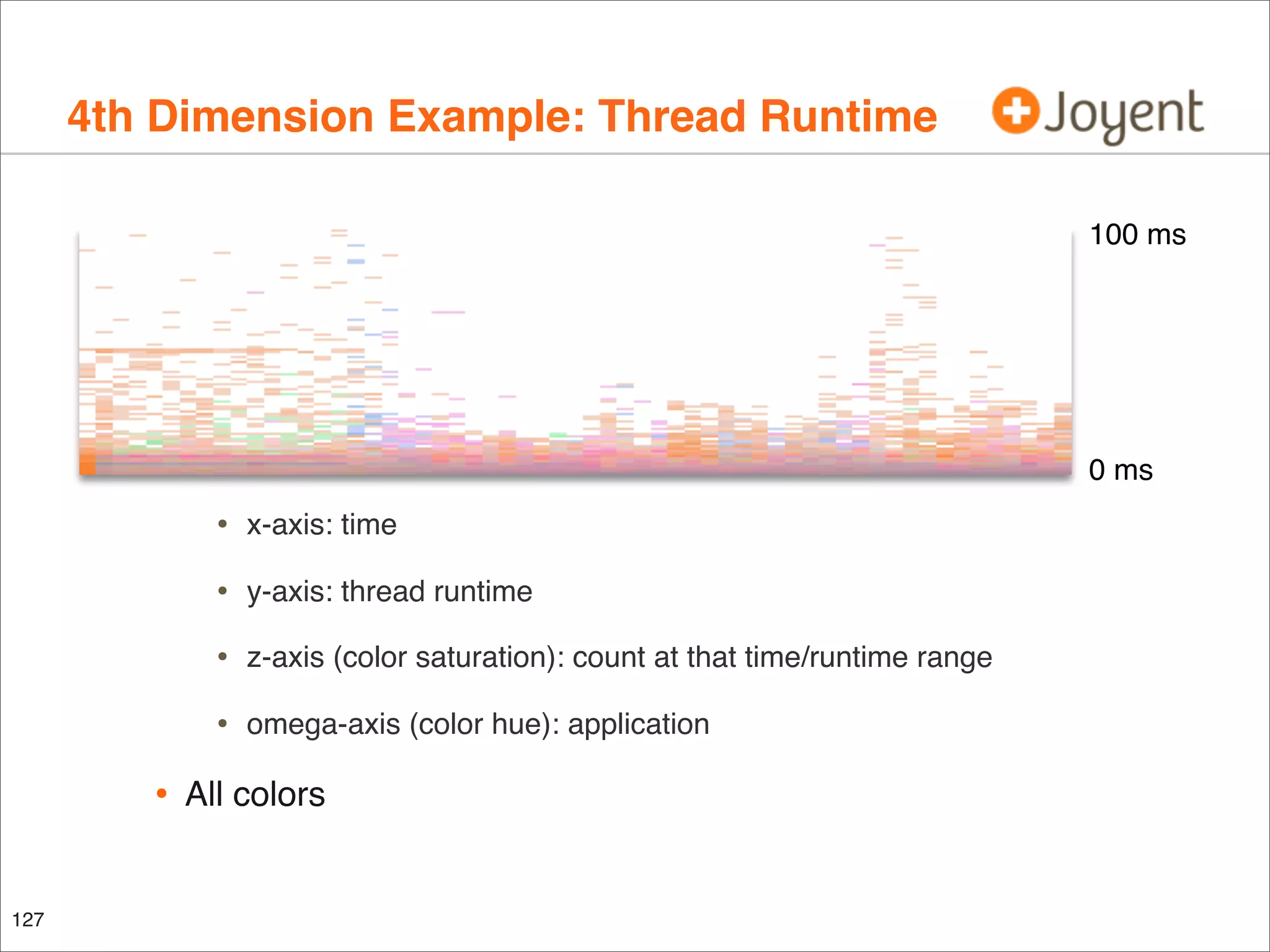



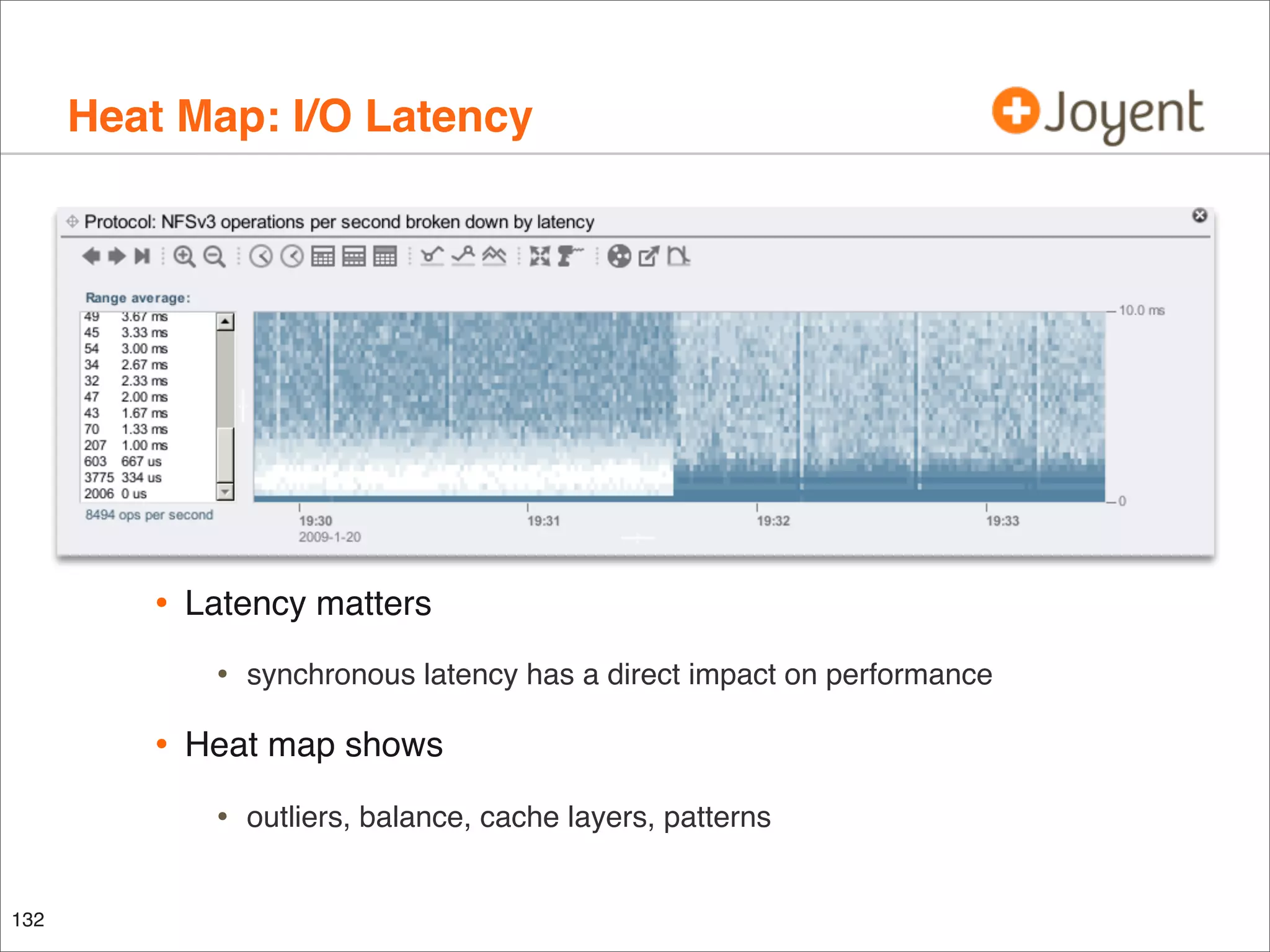
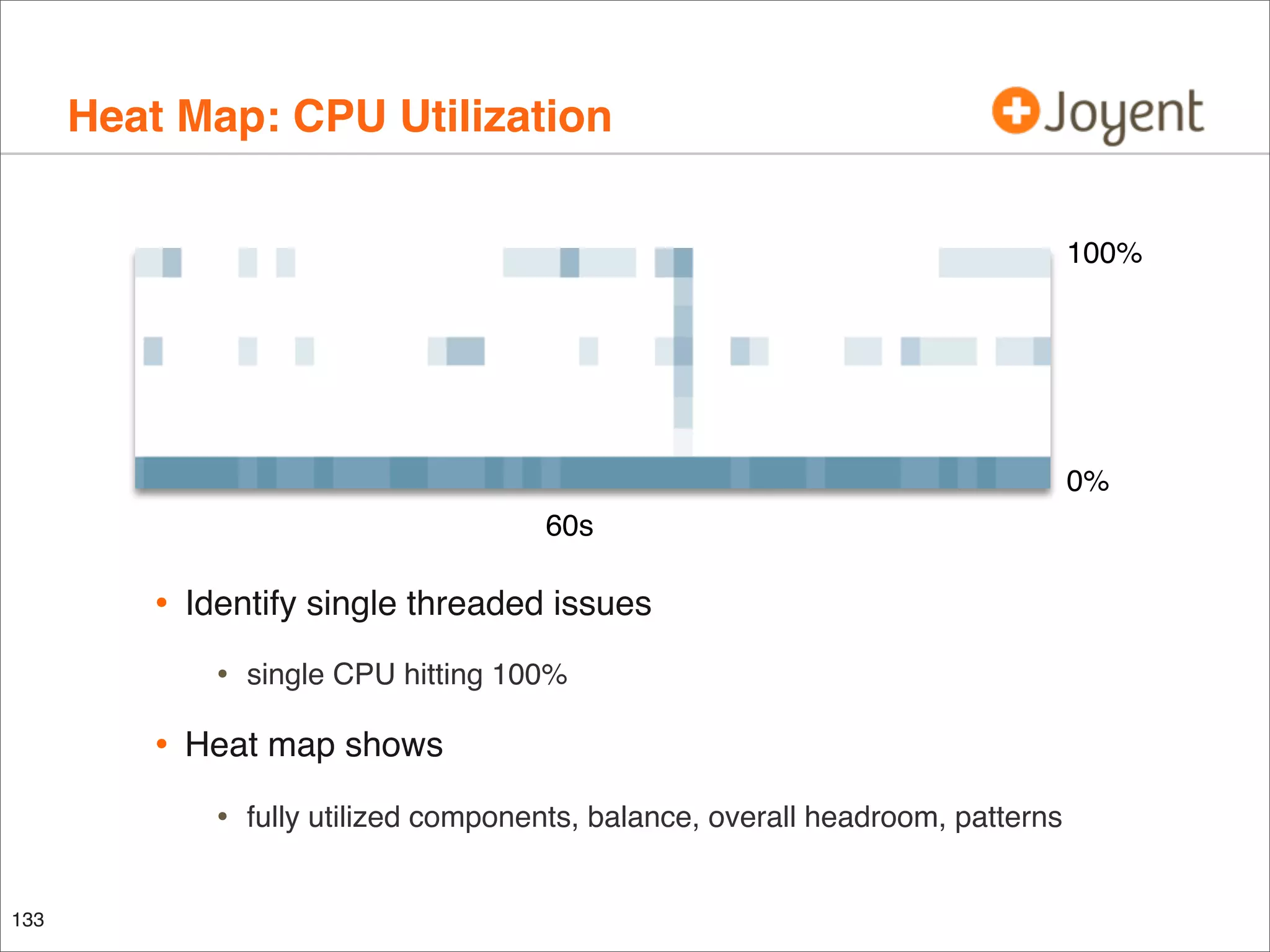


The document discusses performance analysis, focusing on workload analysis and resource monitoring using visualizations. It emphasizes the importance of understanding metrics before plotting and encourages the use of latency over IOPS for identifying and verifying performance issues. Additionally, it highlights the need for reliable metrics to quantify performance effectively.



































































































