Downloaded 49 times



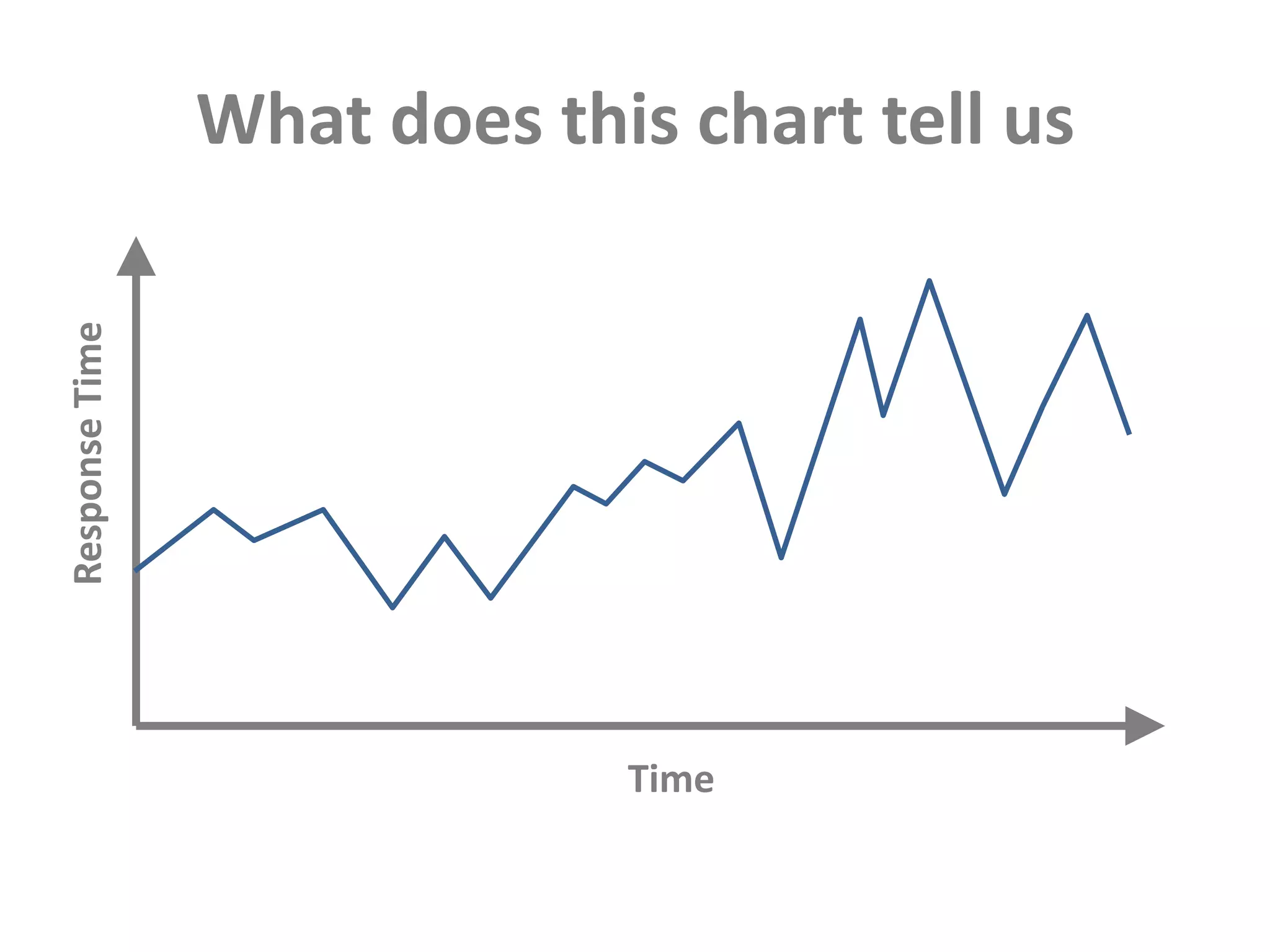



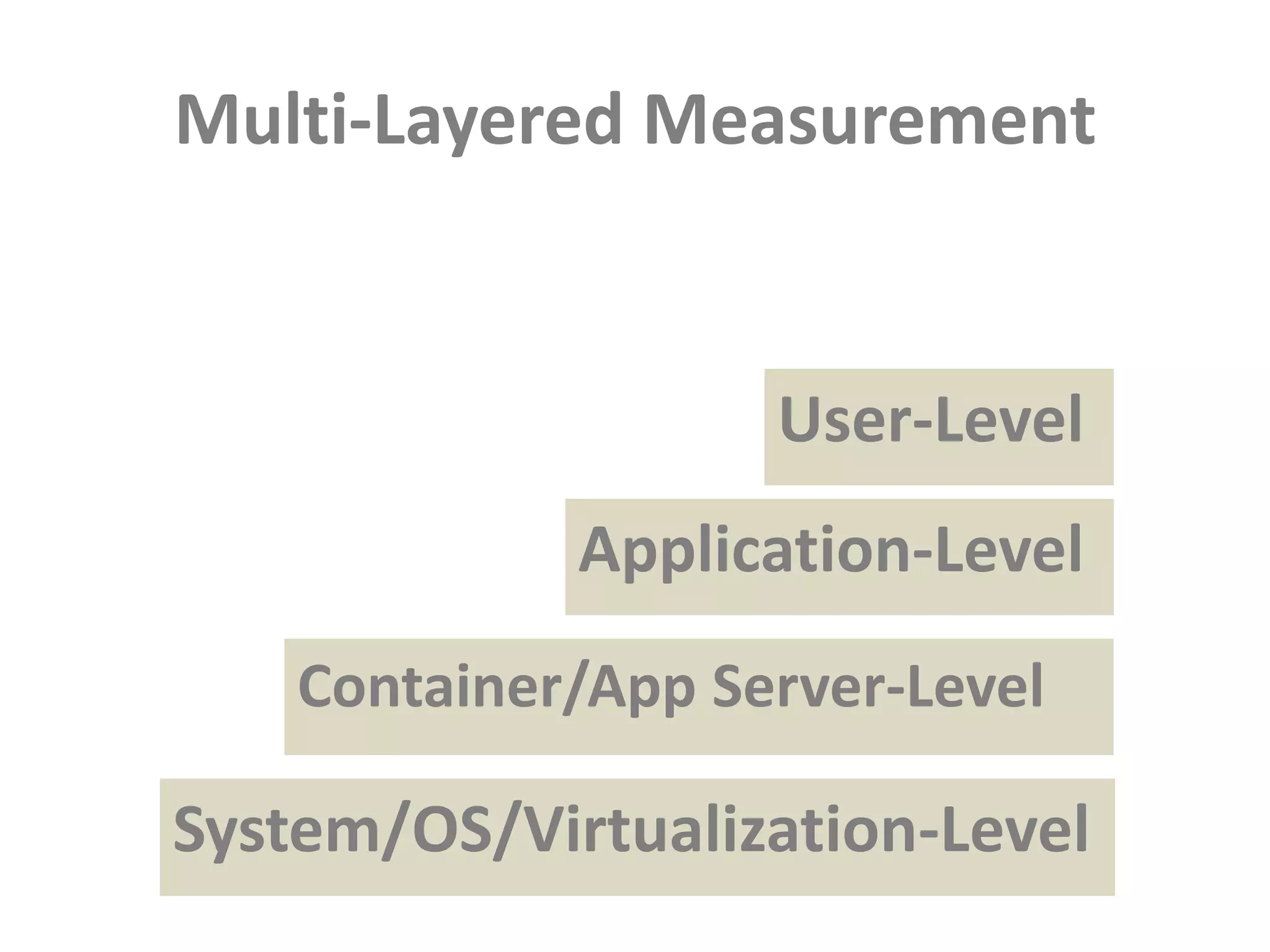
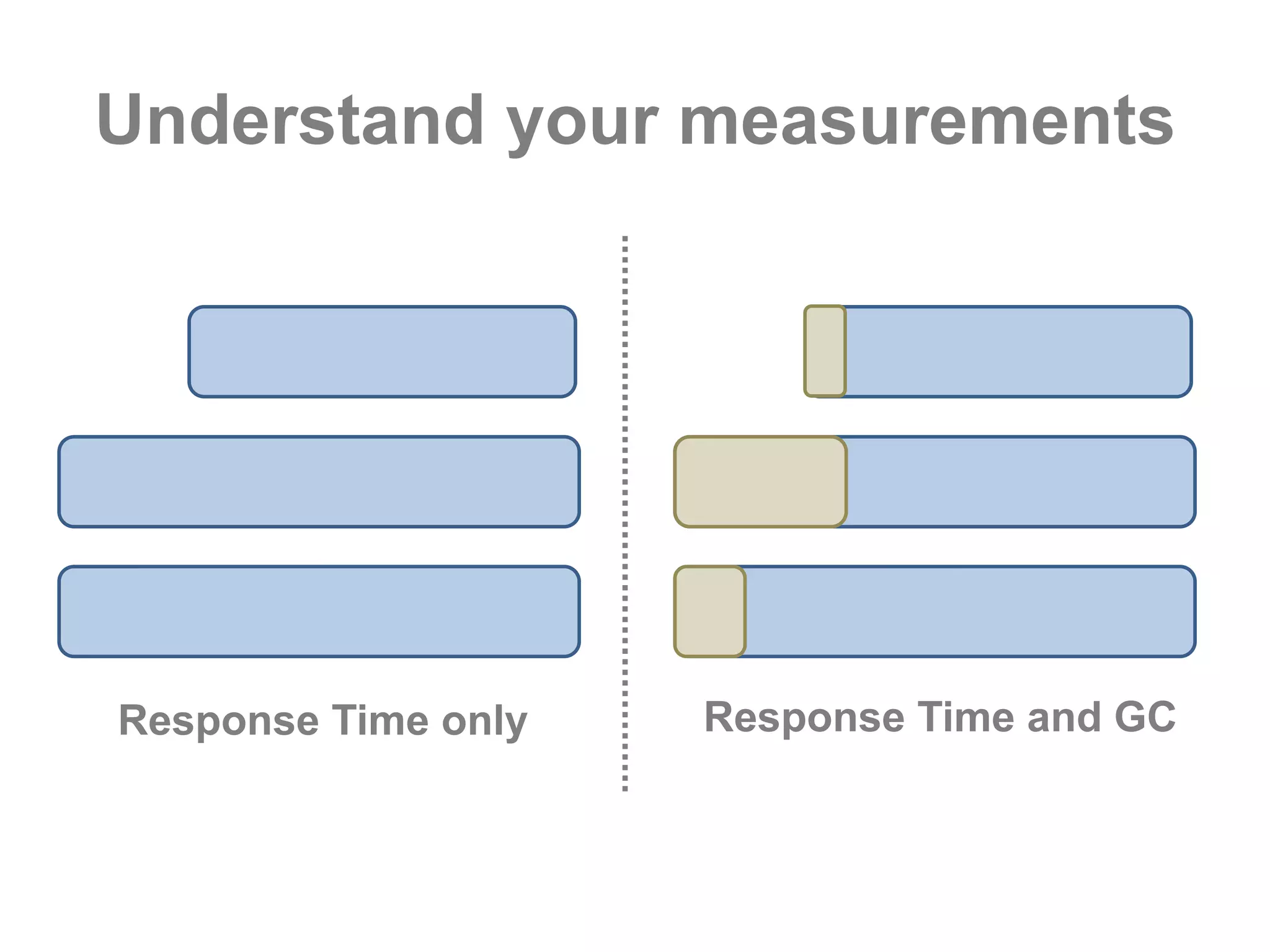

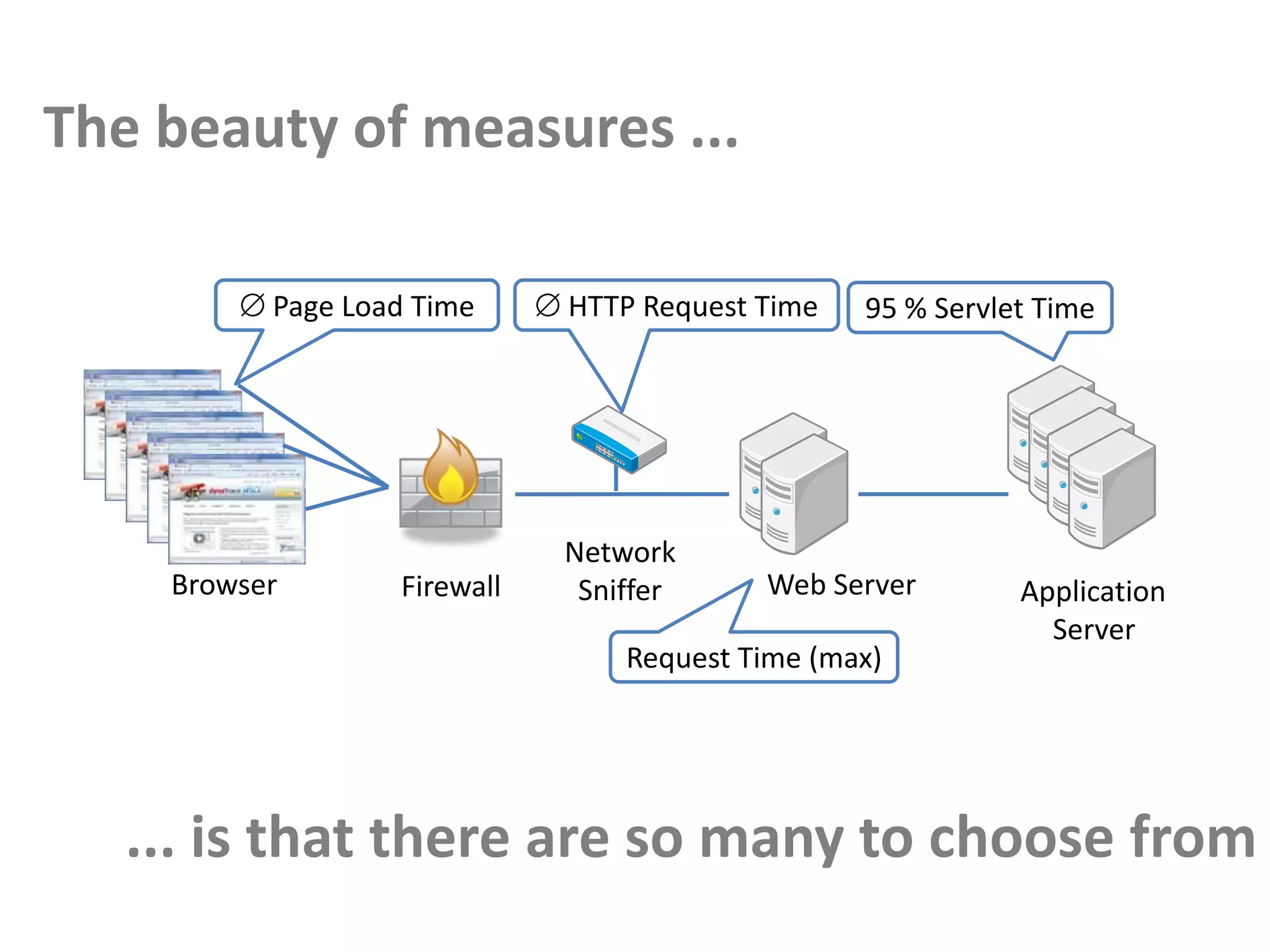


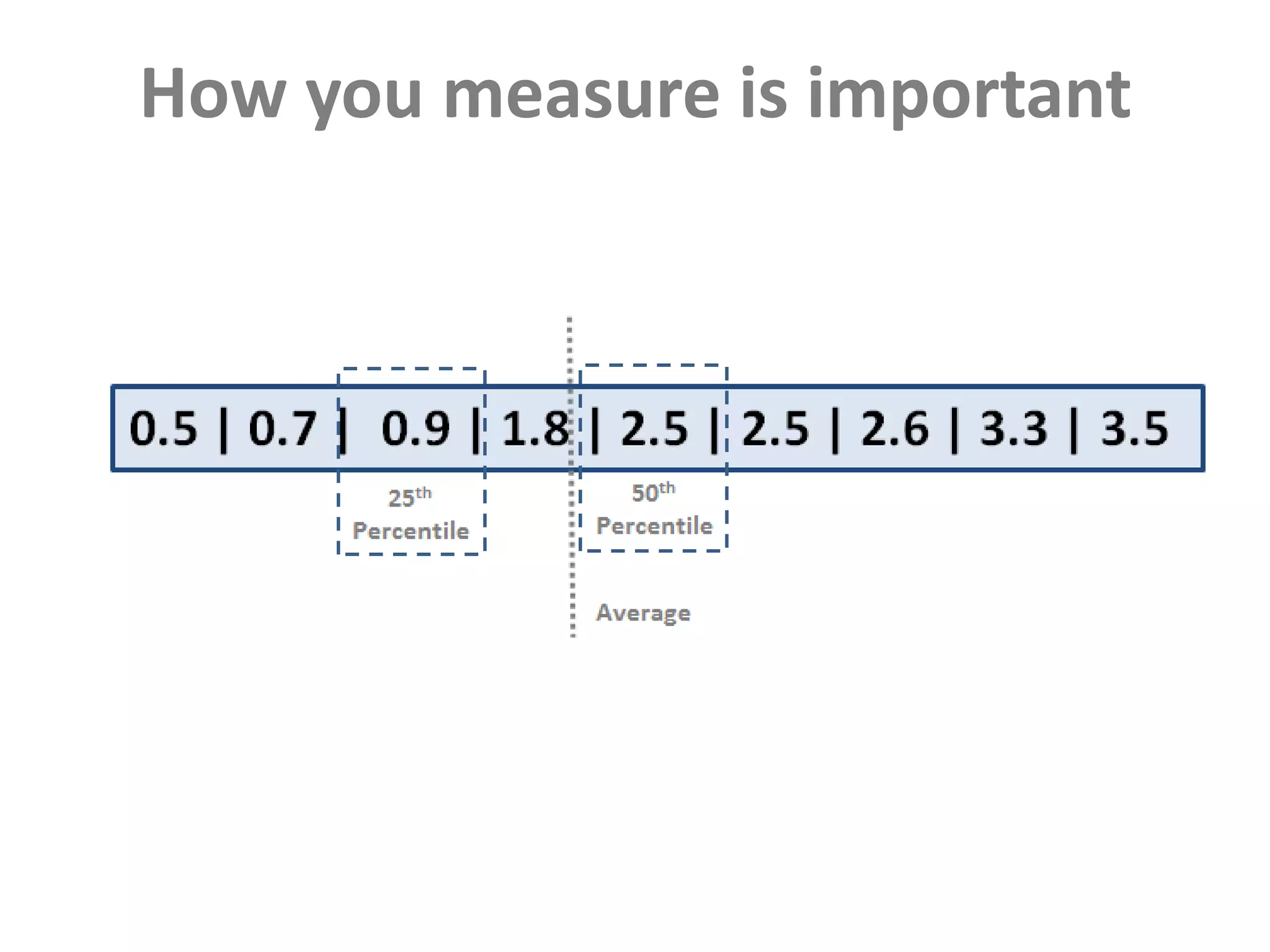

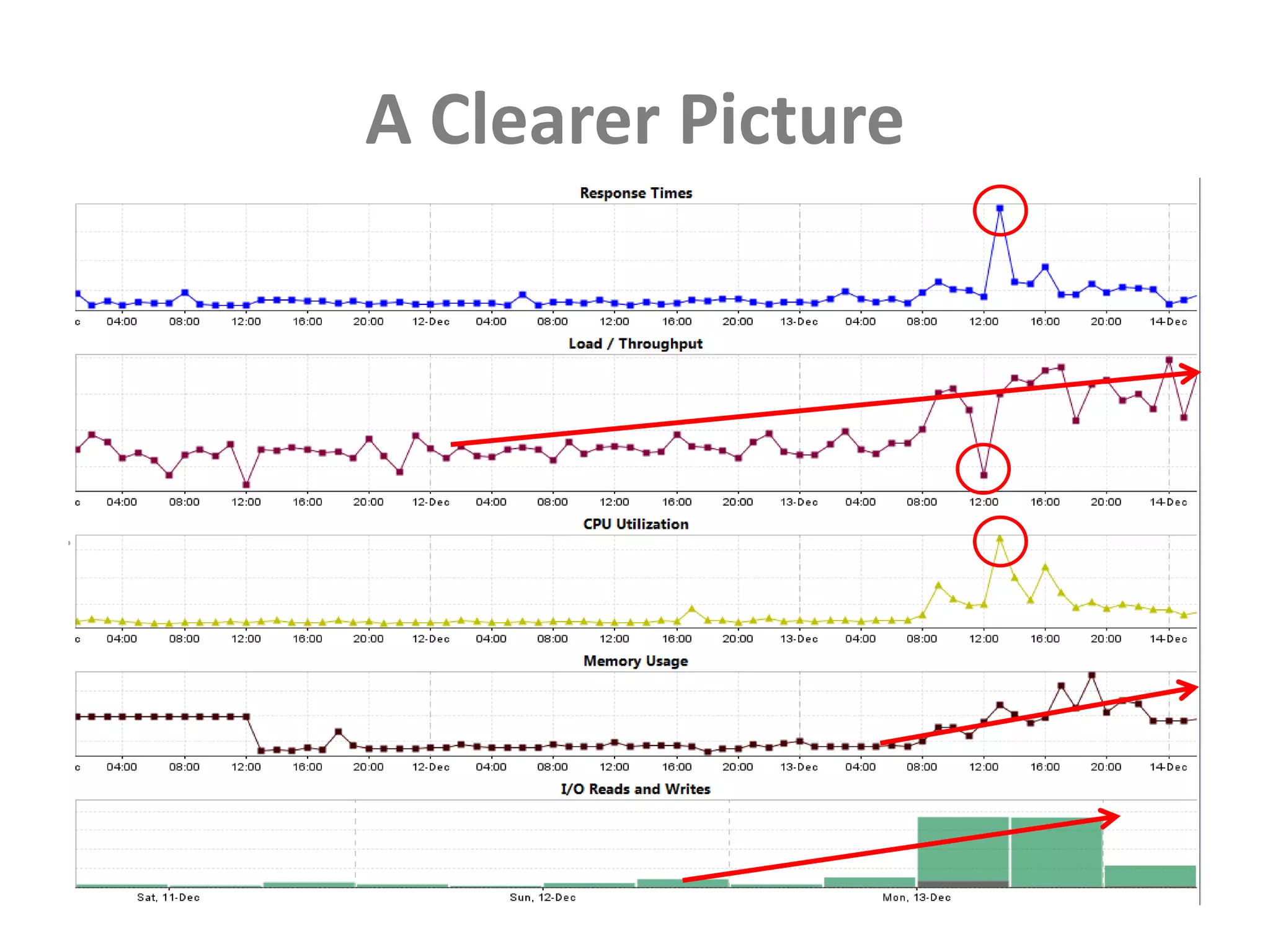




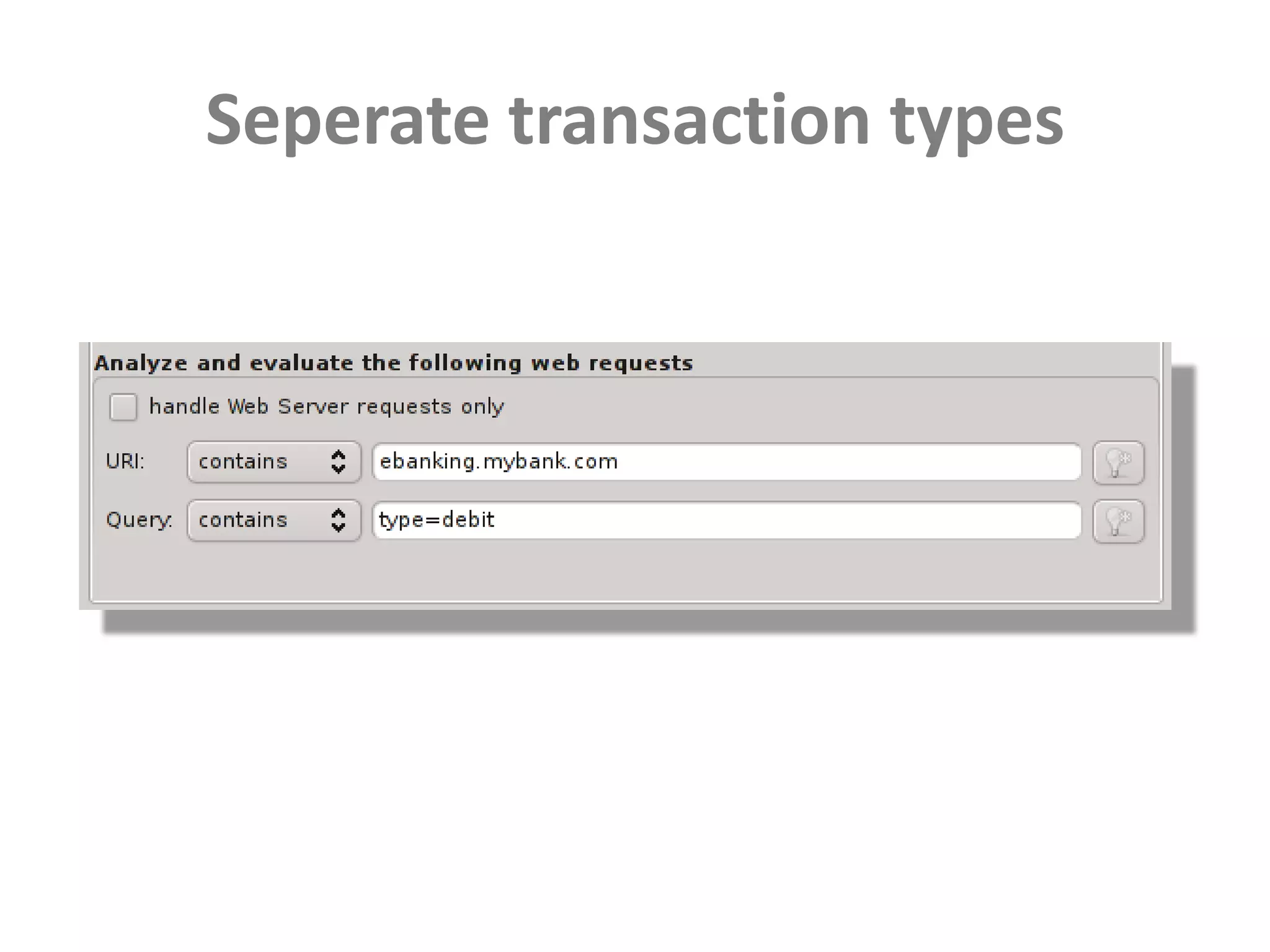

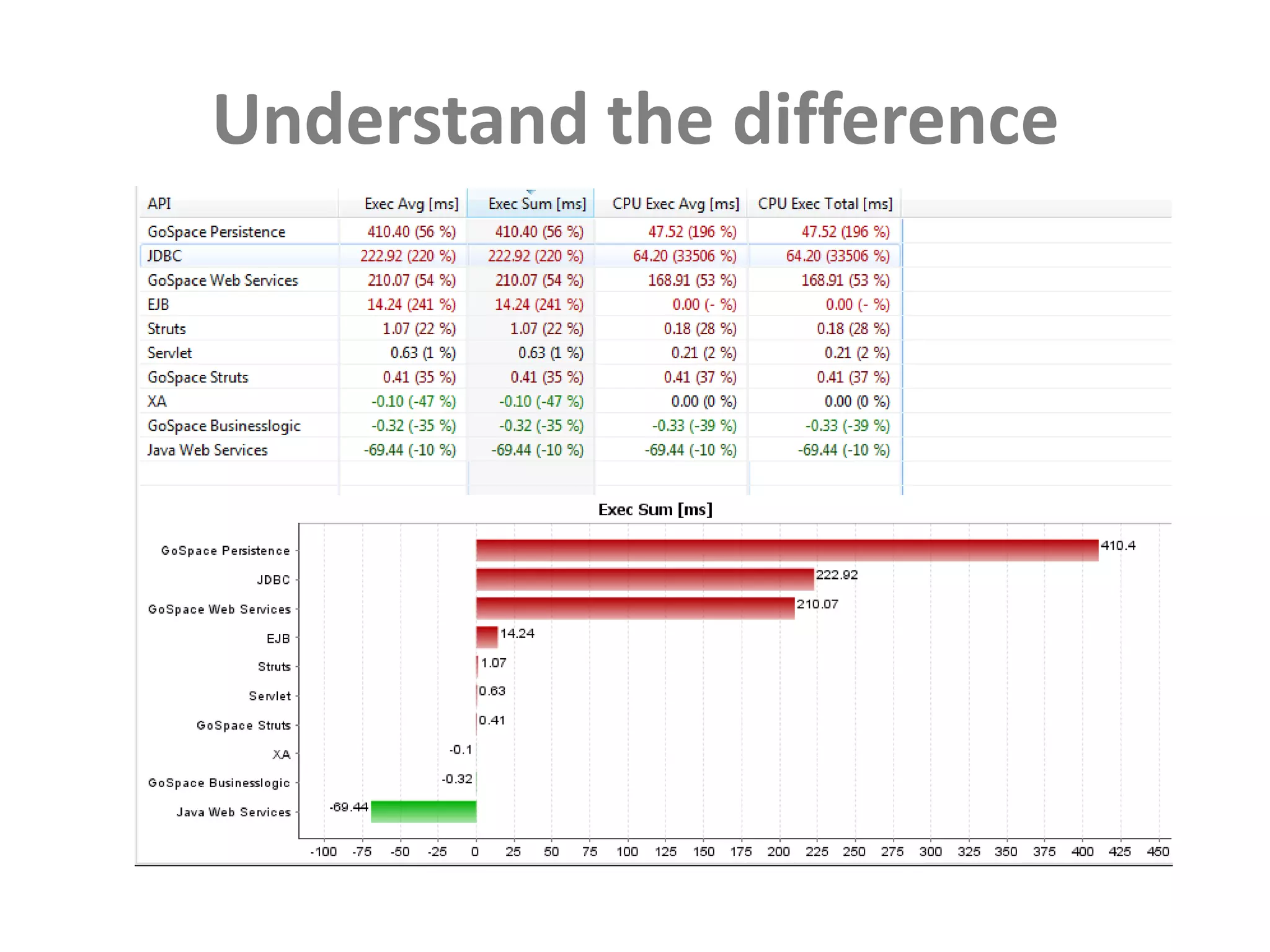







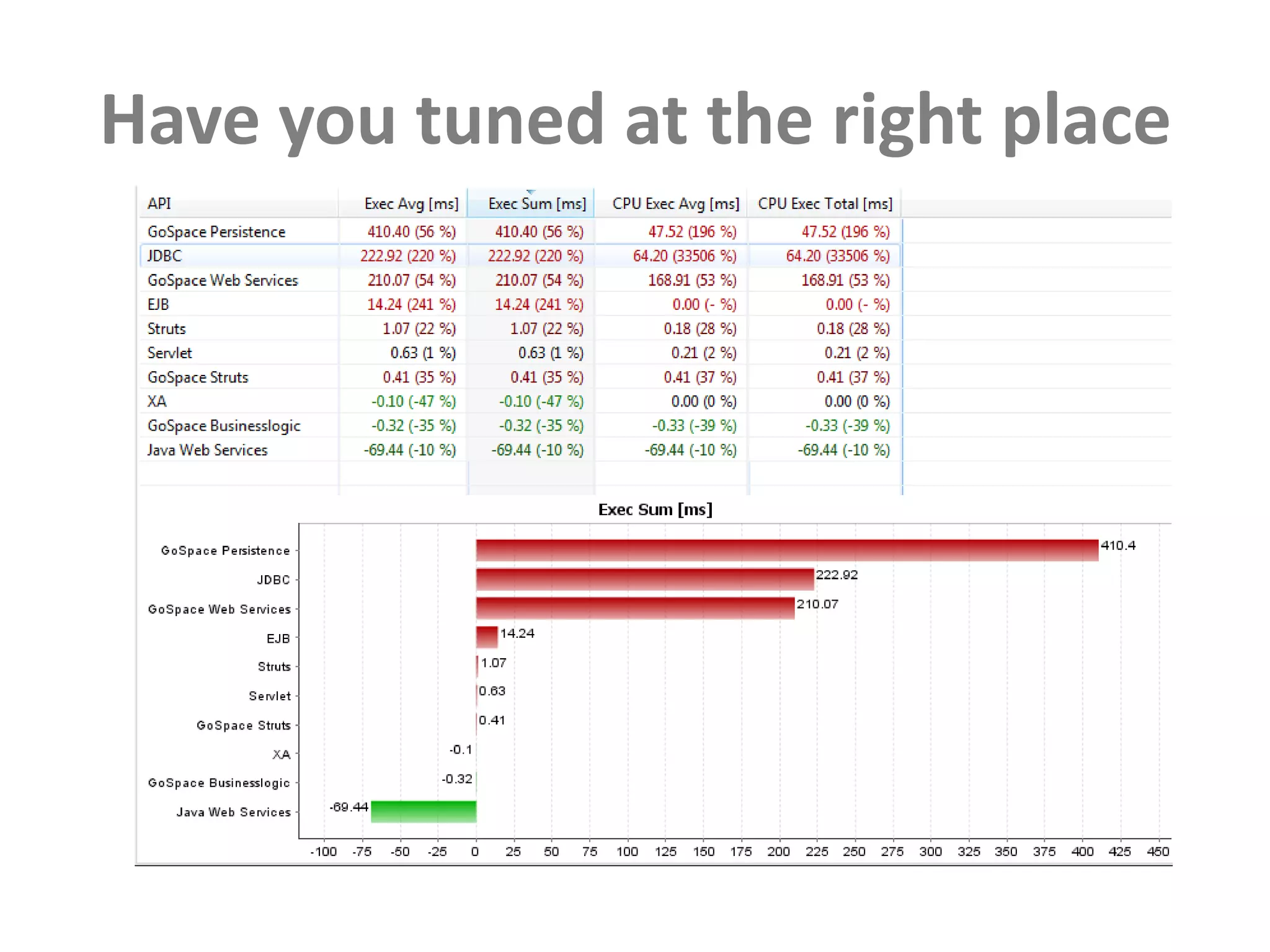


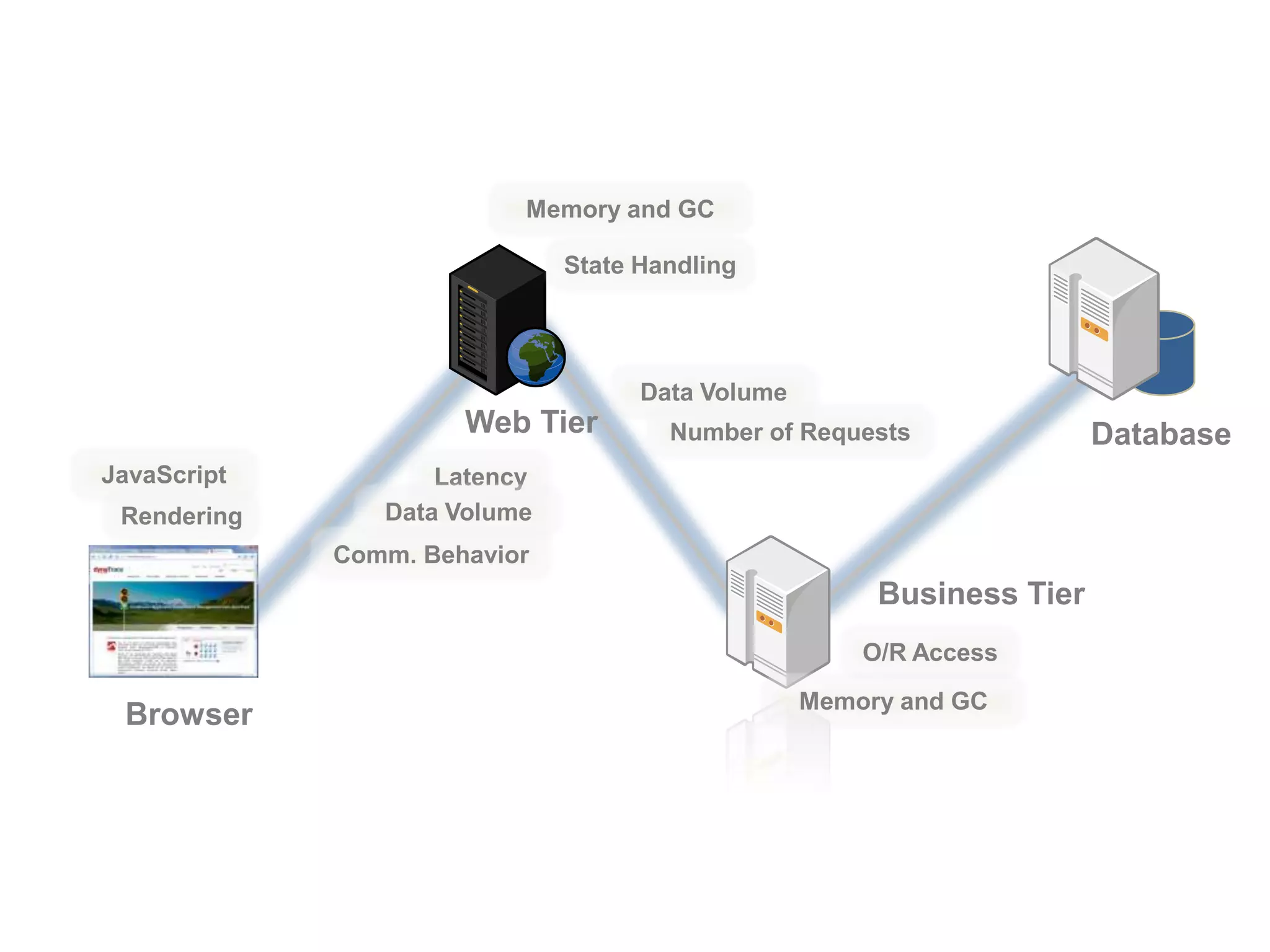
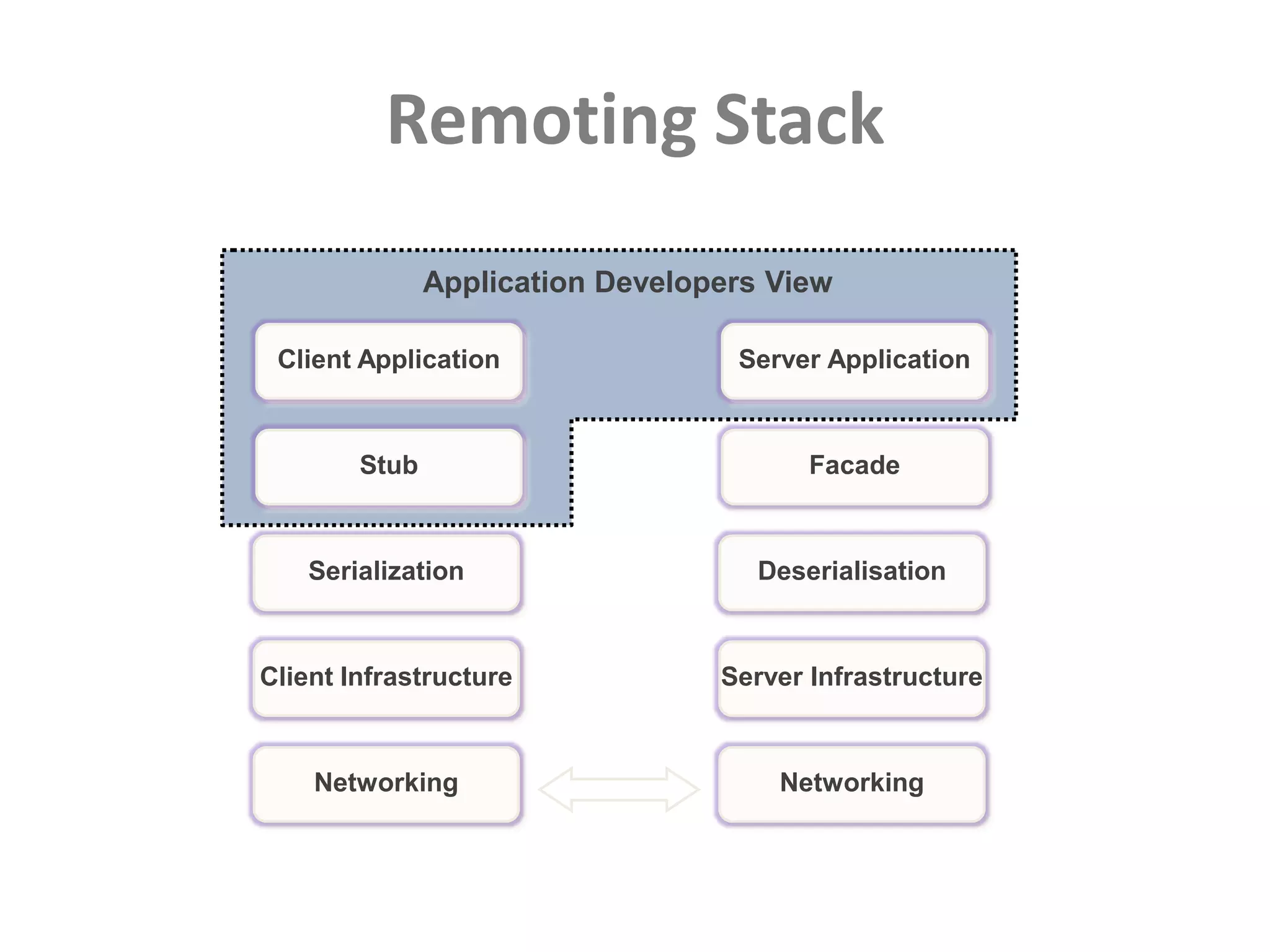
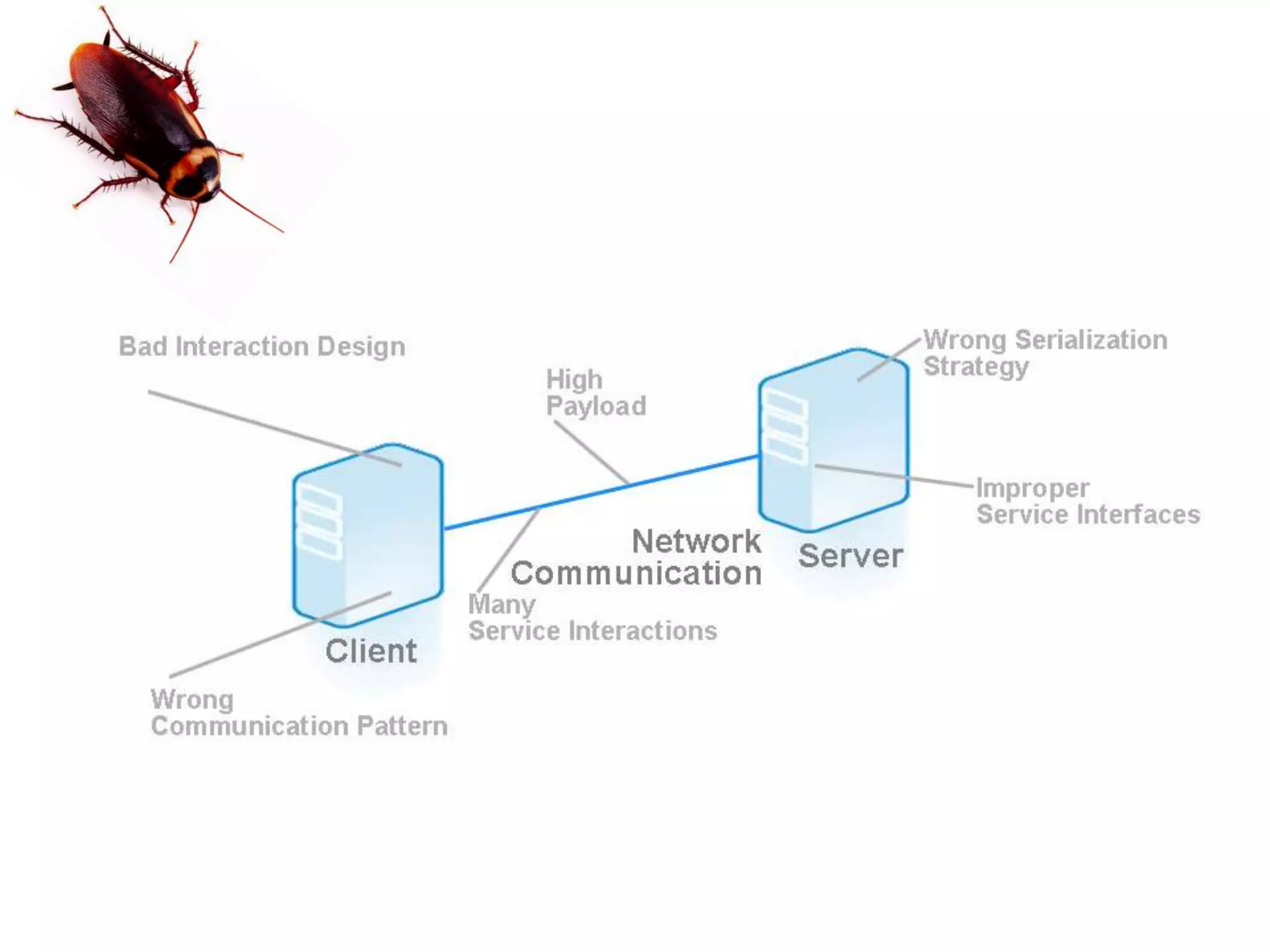
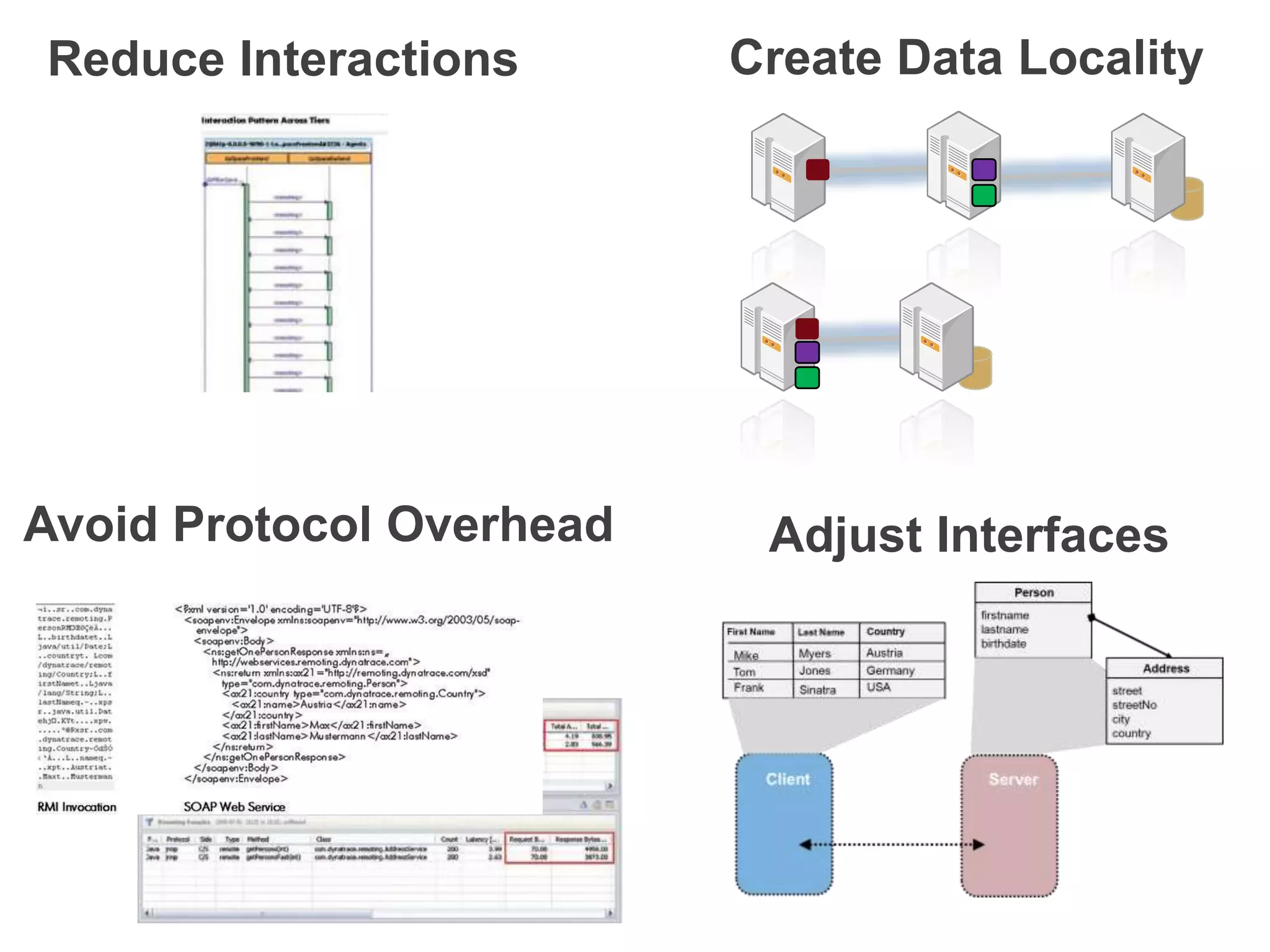
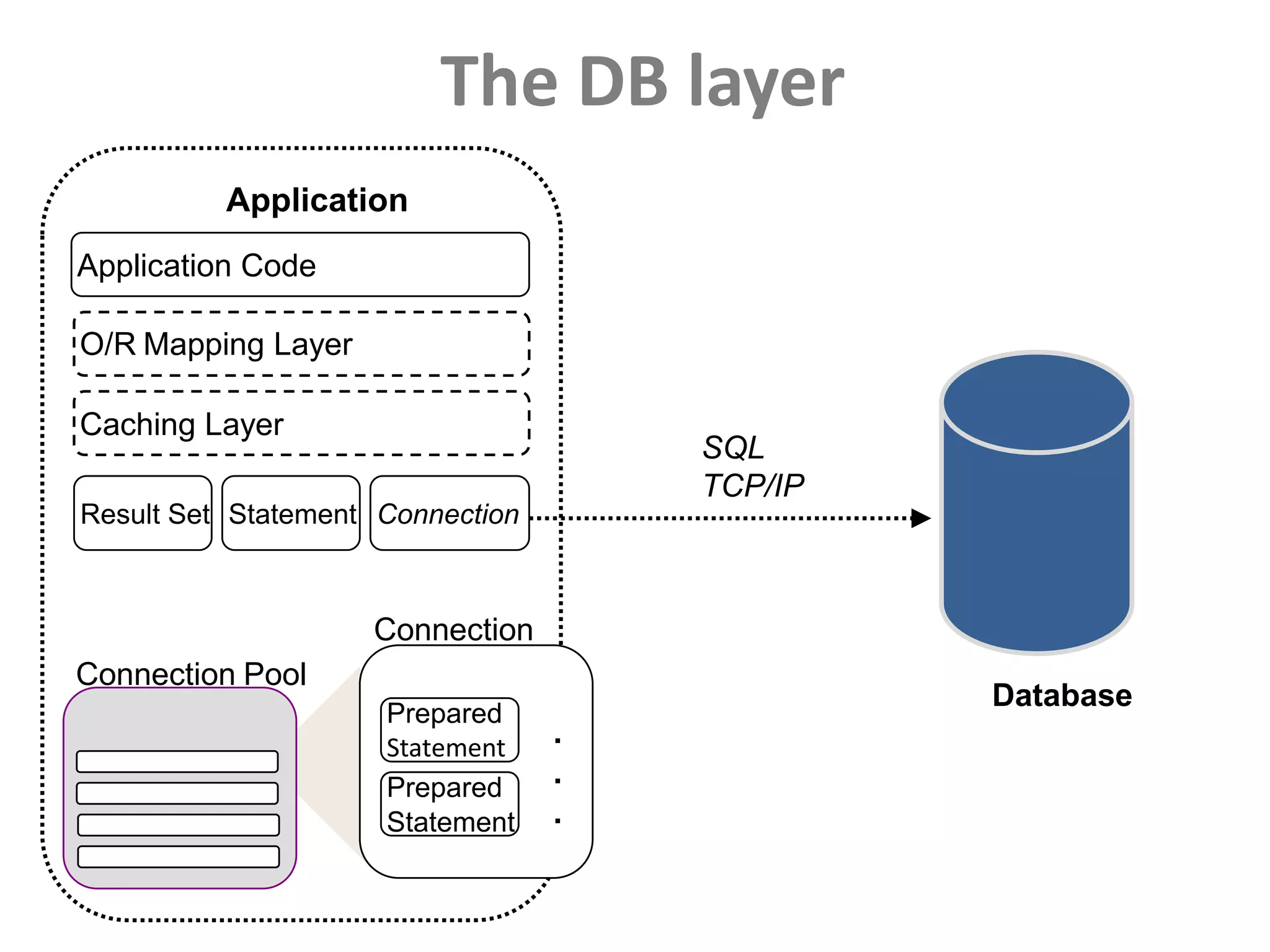
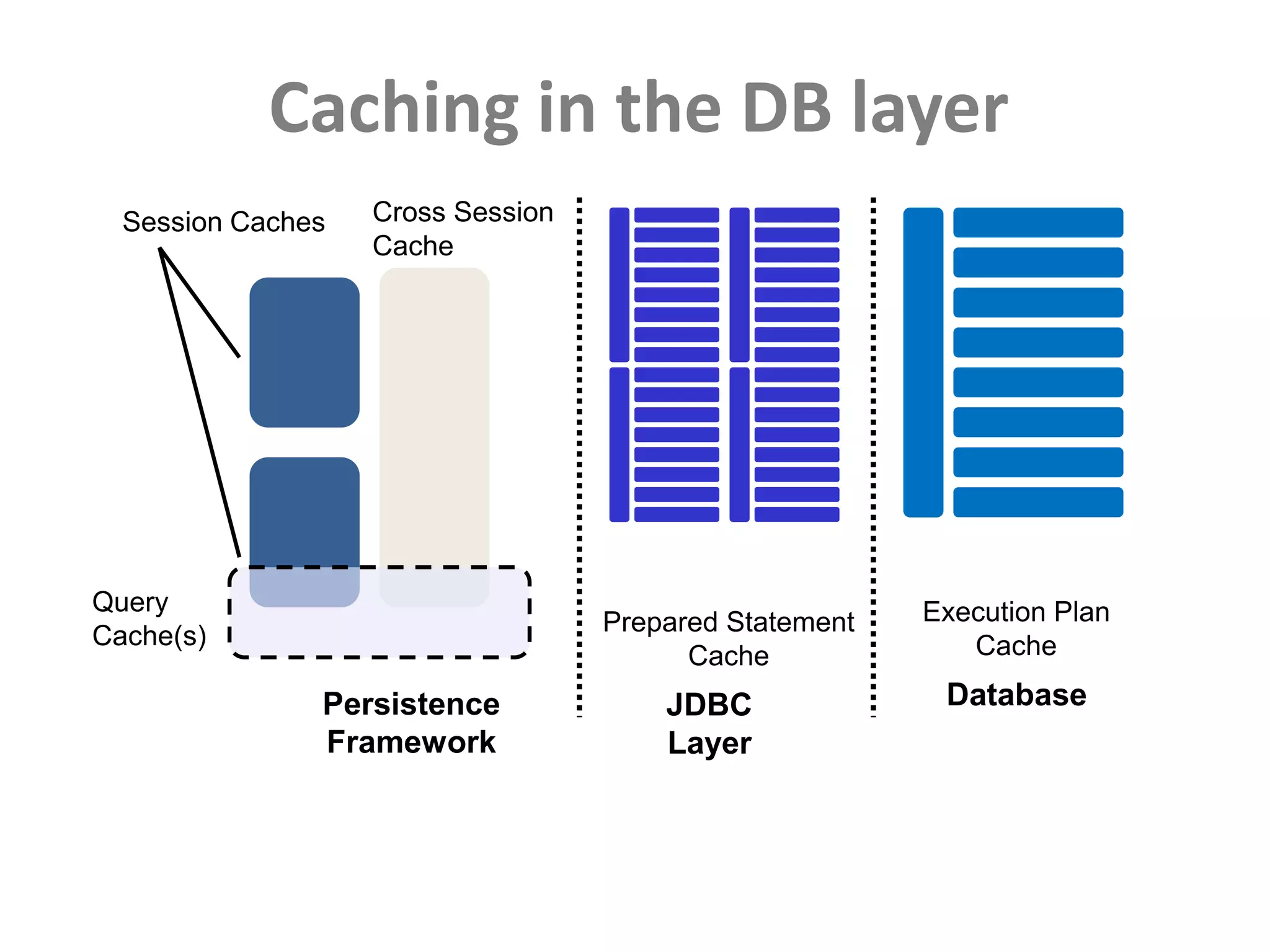
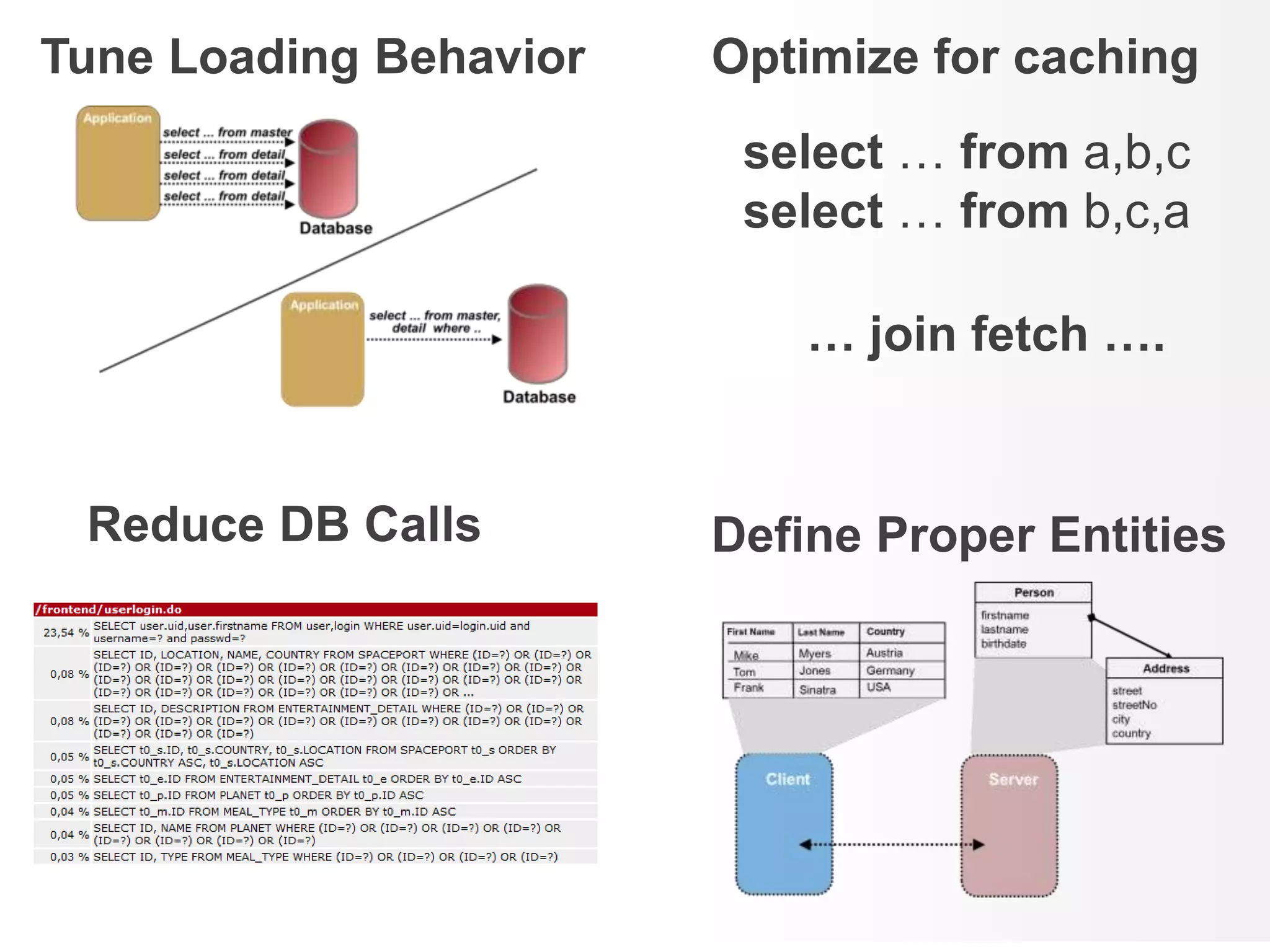

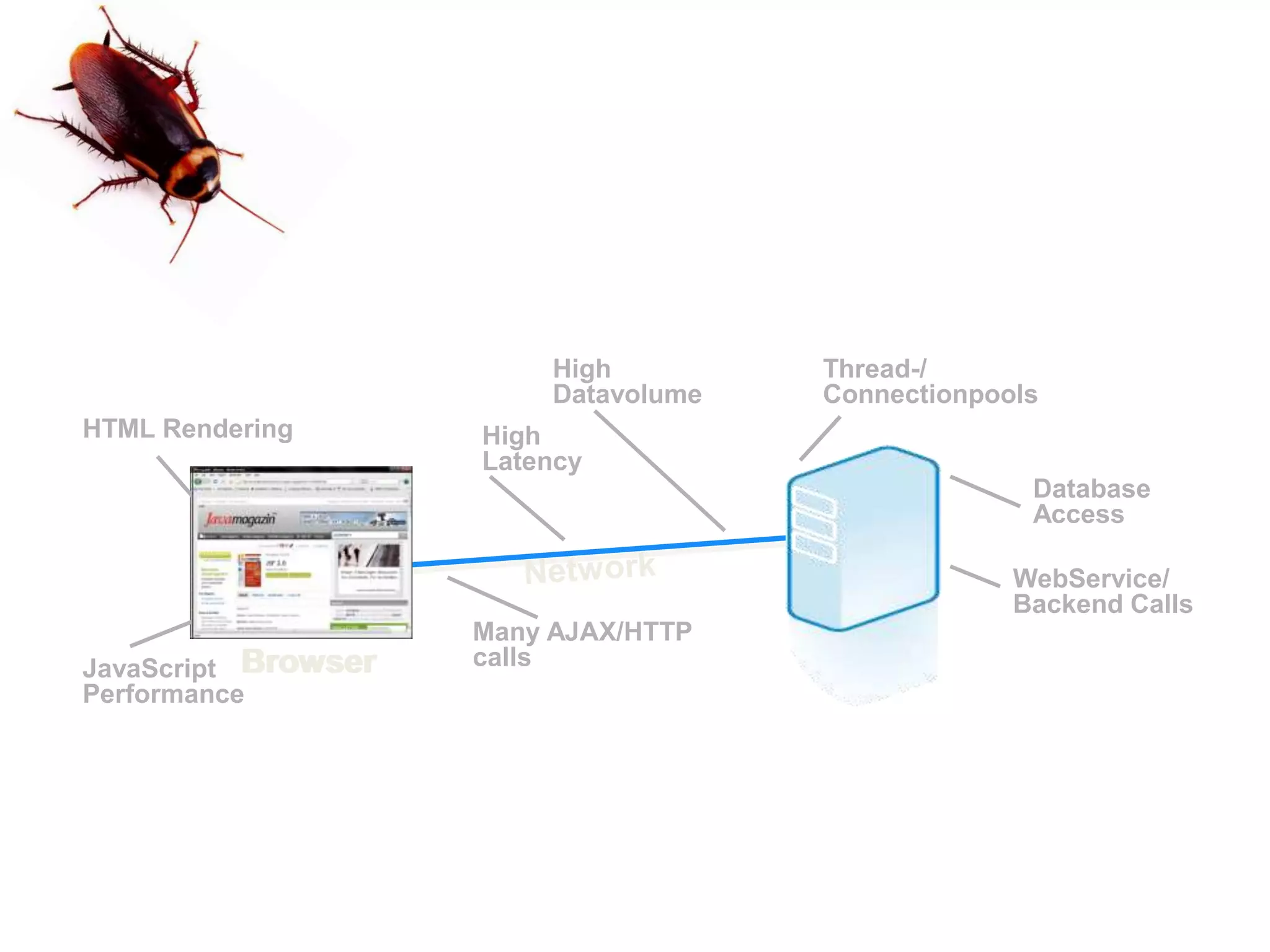
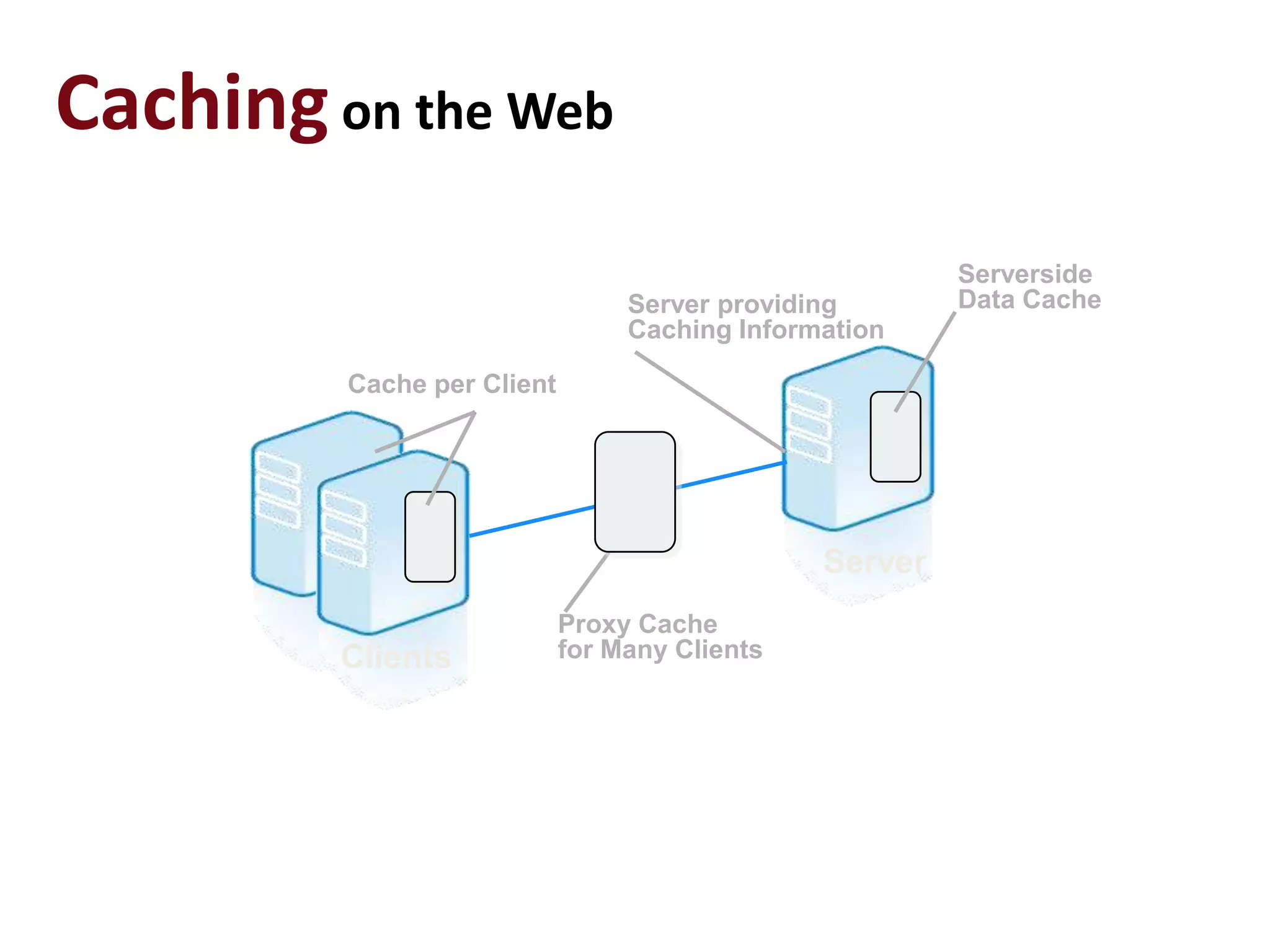


This document discusses performance forensics and optimization techniques. It emphasizes the importance of collecting multi-layered measurements from the user level down to the system level to understand performance problems. Common measurements include response time, memory usage, CPU usage, database queries and latency. Identifying the problem area and isolating it is key before applying optimizations like caching, reducing interactions and data locality. Tuning may be needed at the application, web or database layers. The goal is to make problems reproducible and ensure optimizations address the underlying issues rather than just symptoms.











































































