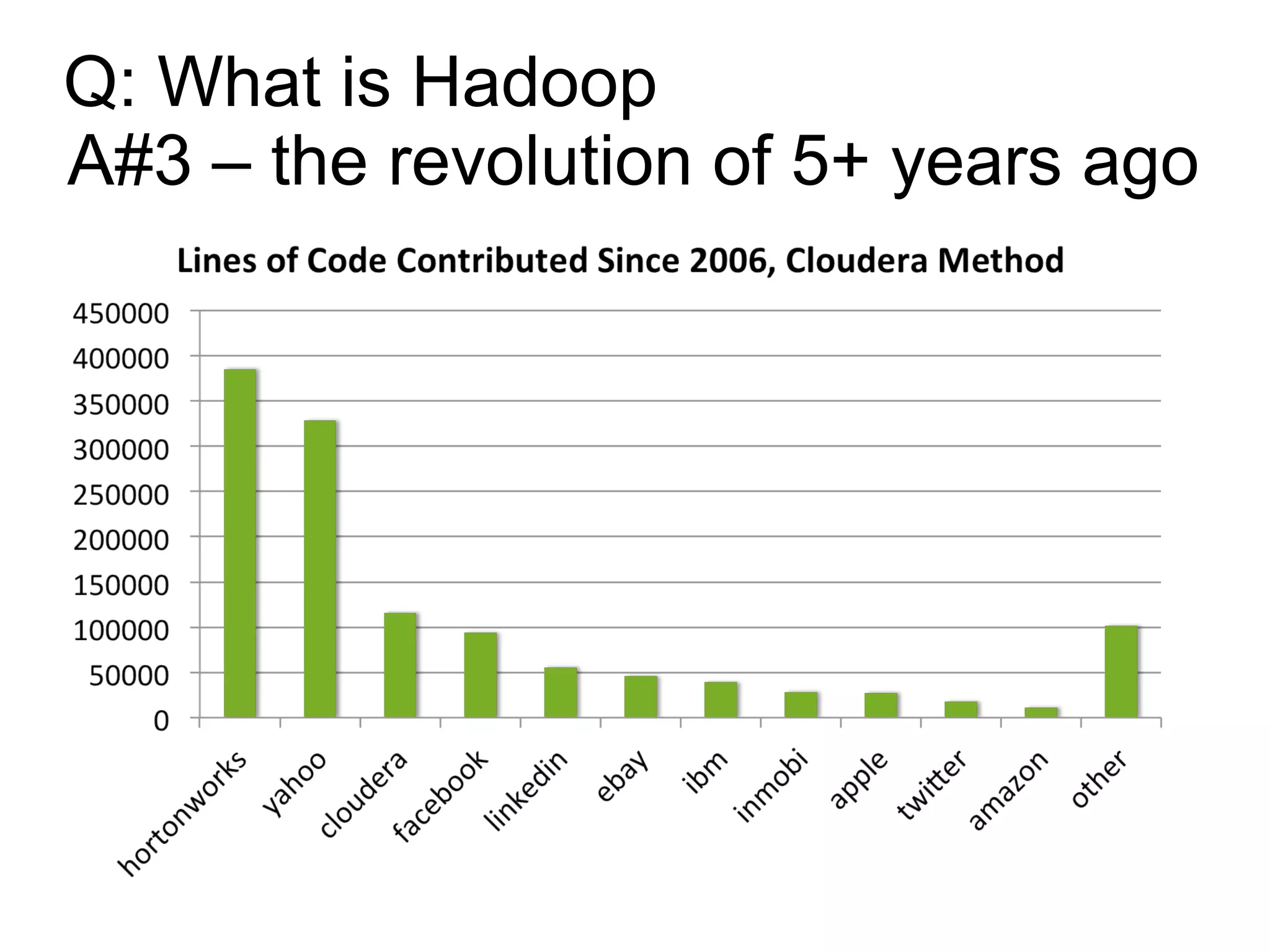
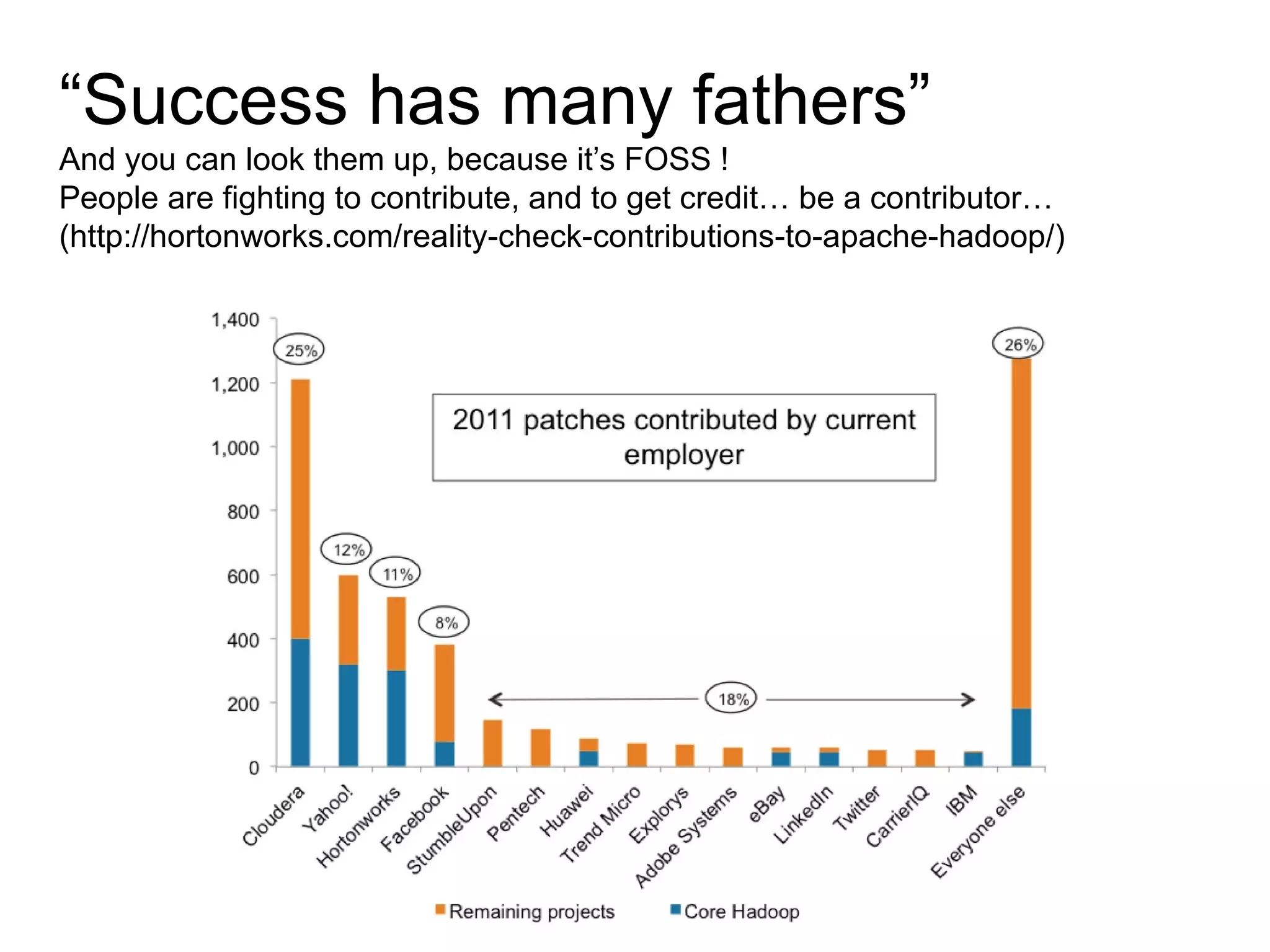
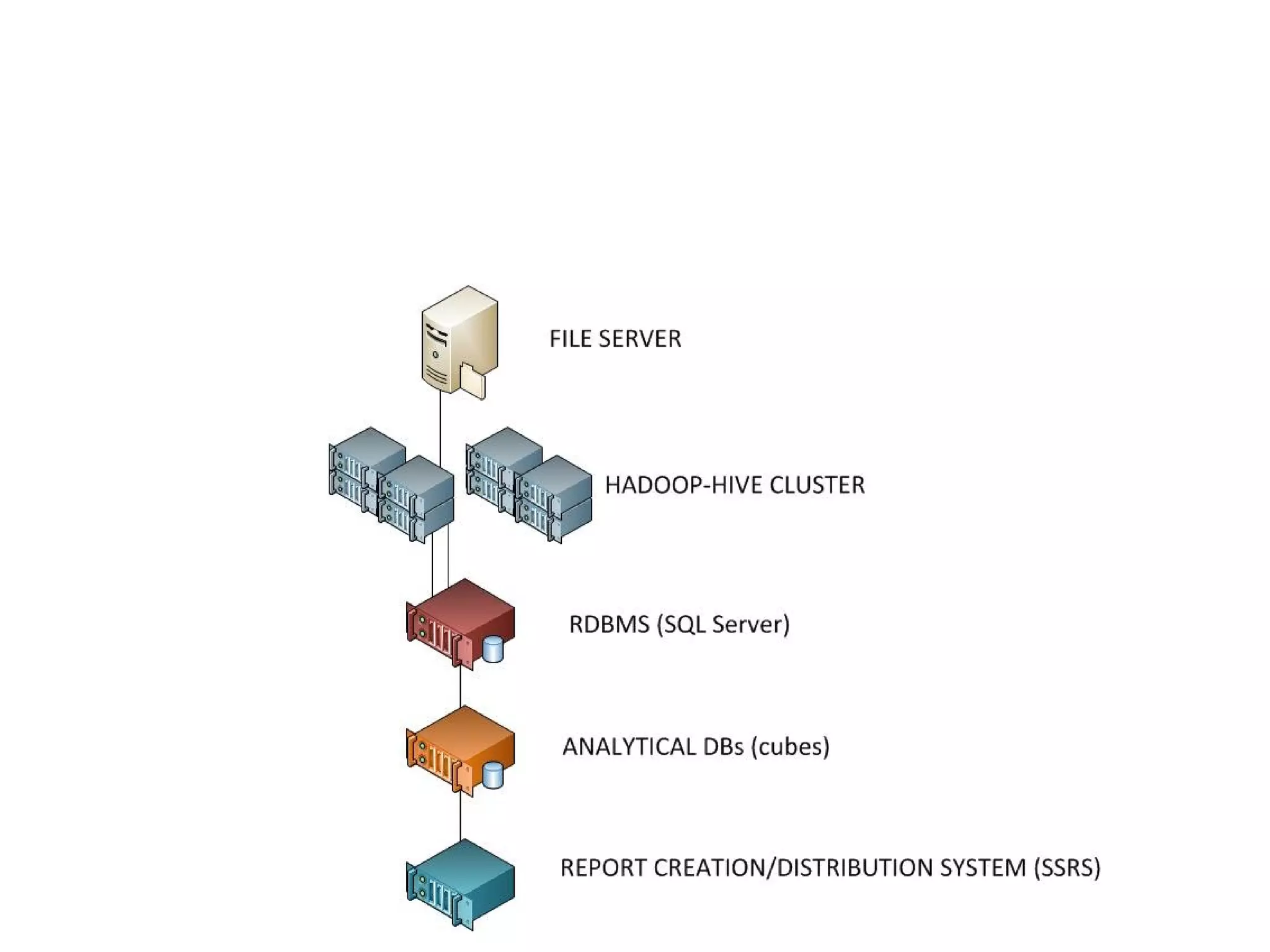
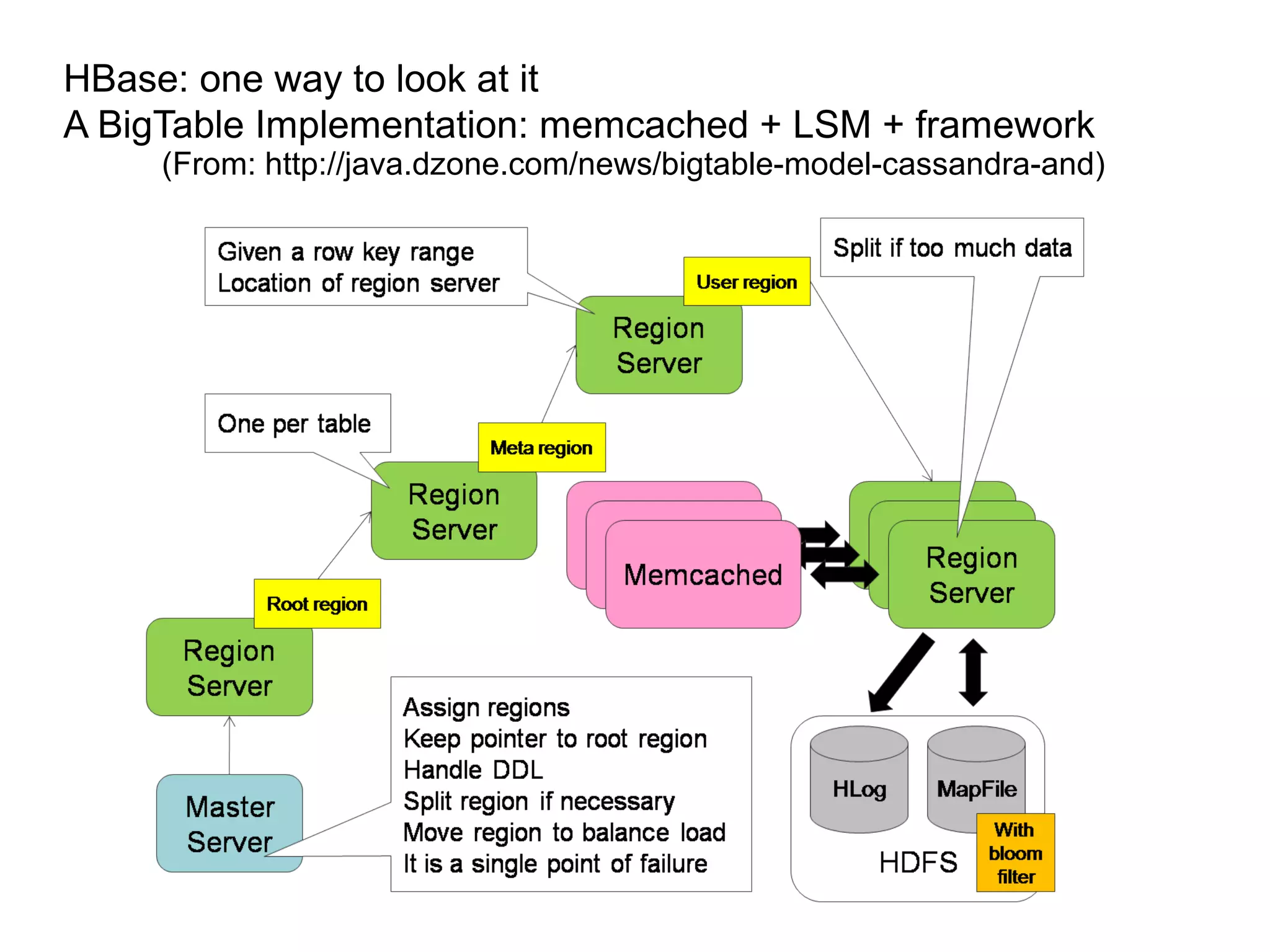
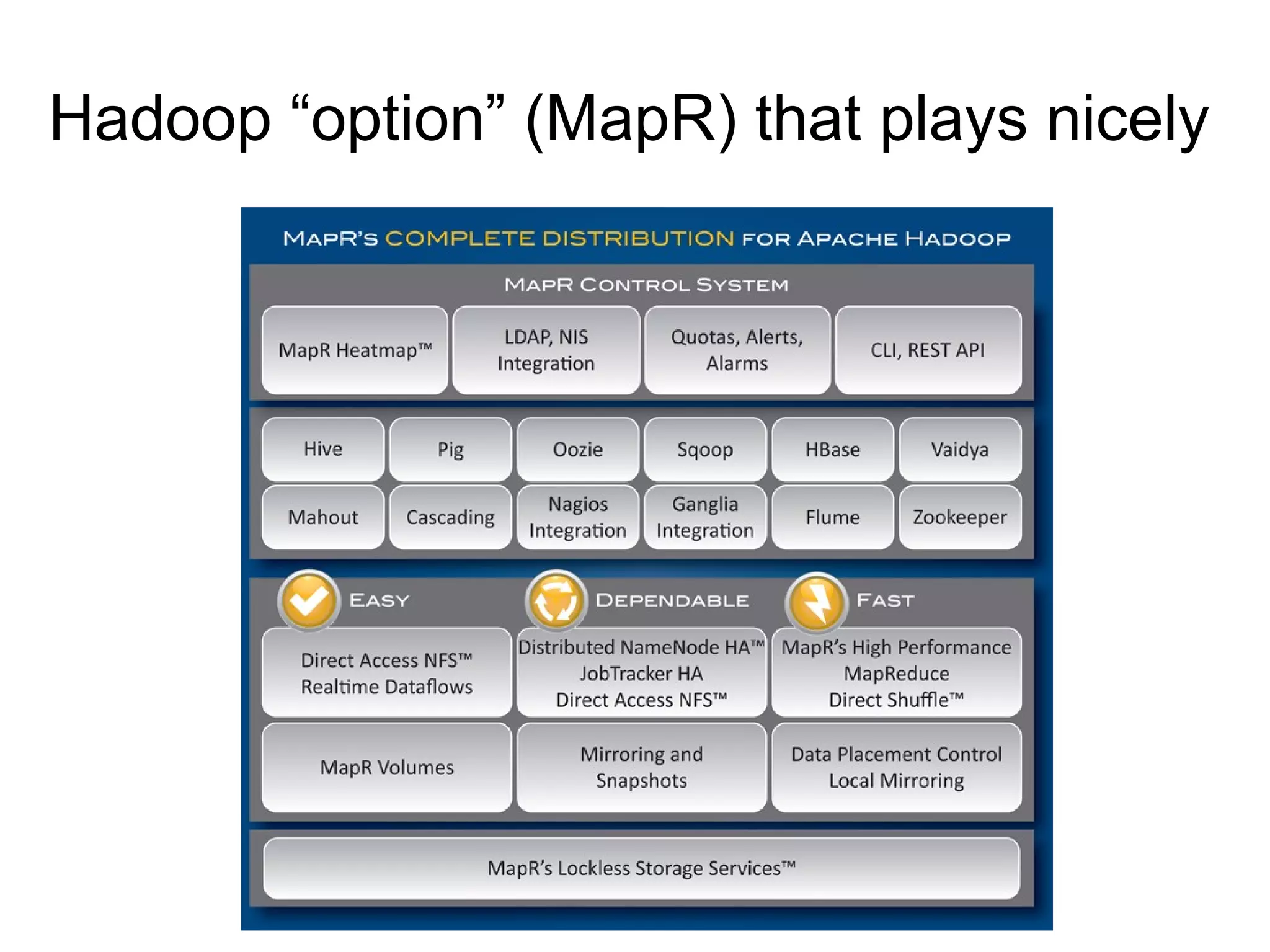
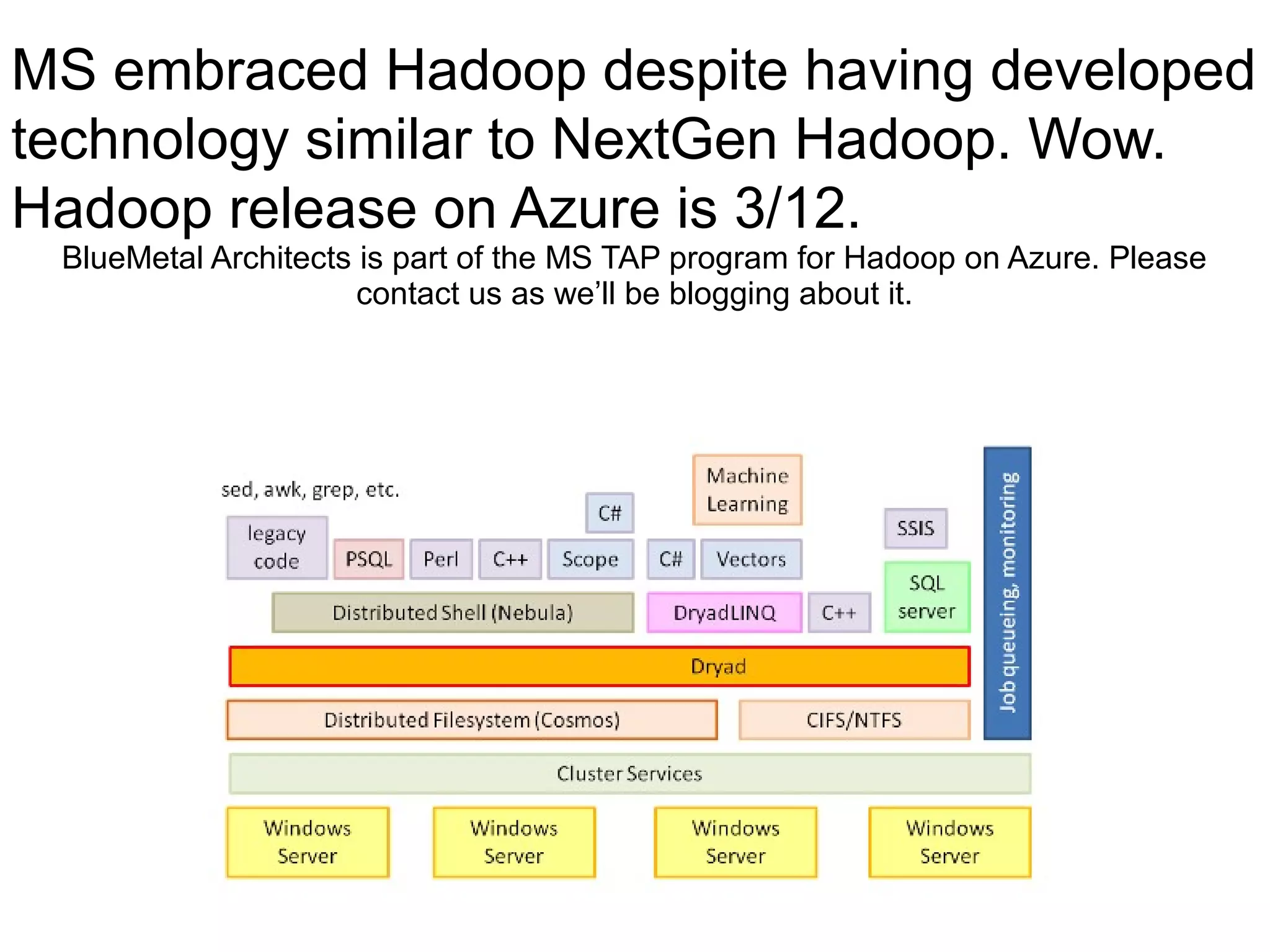
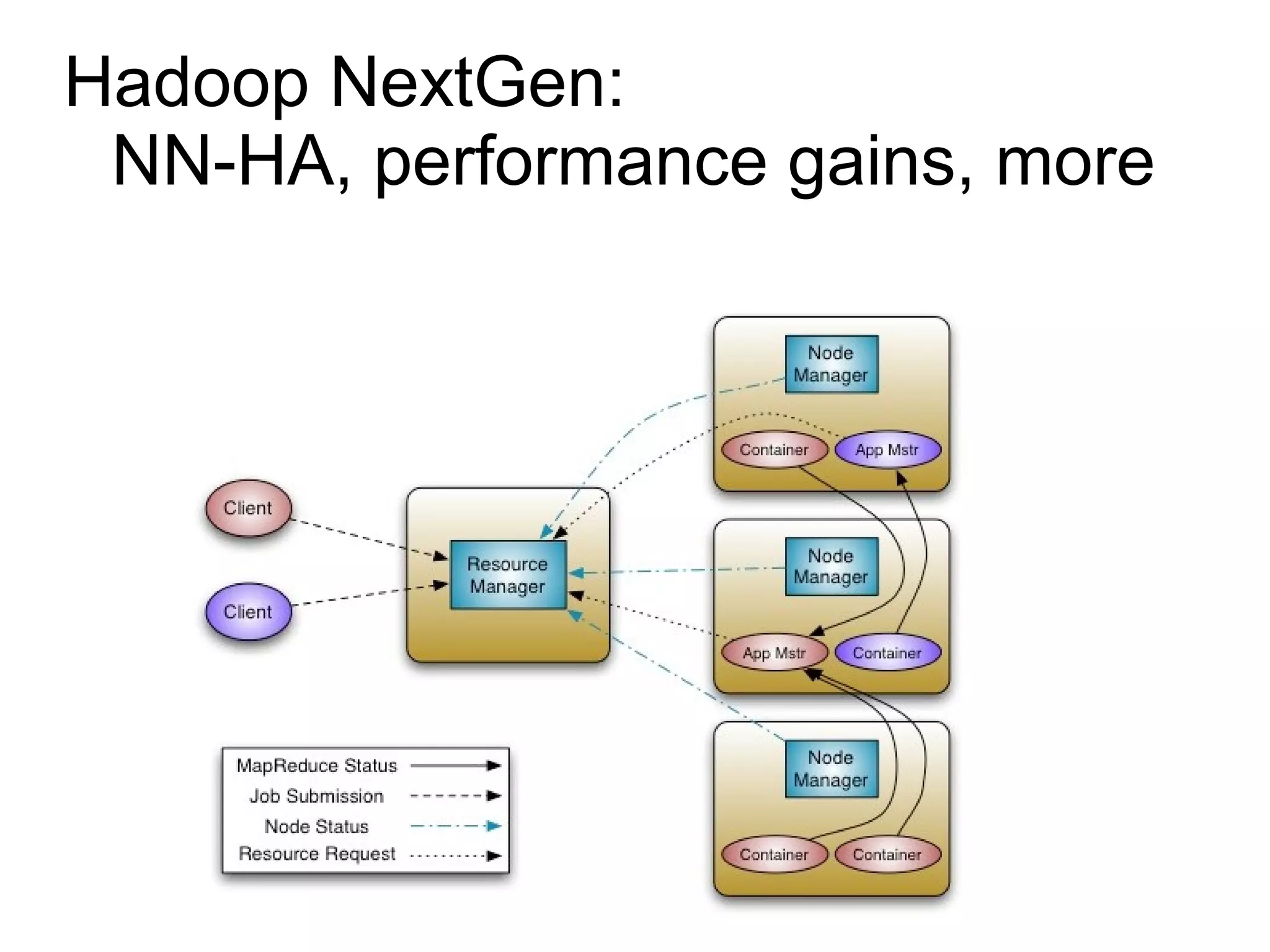
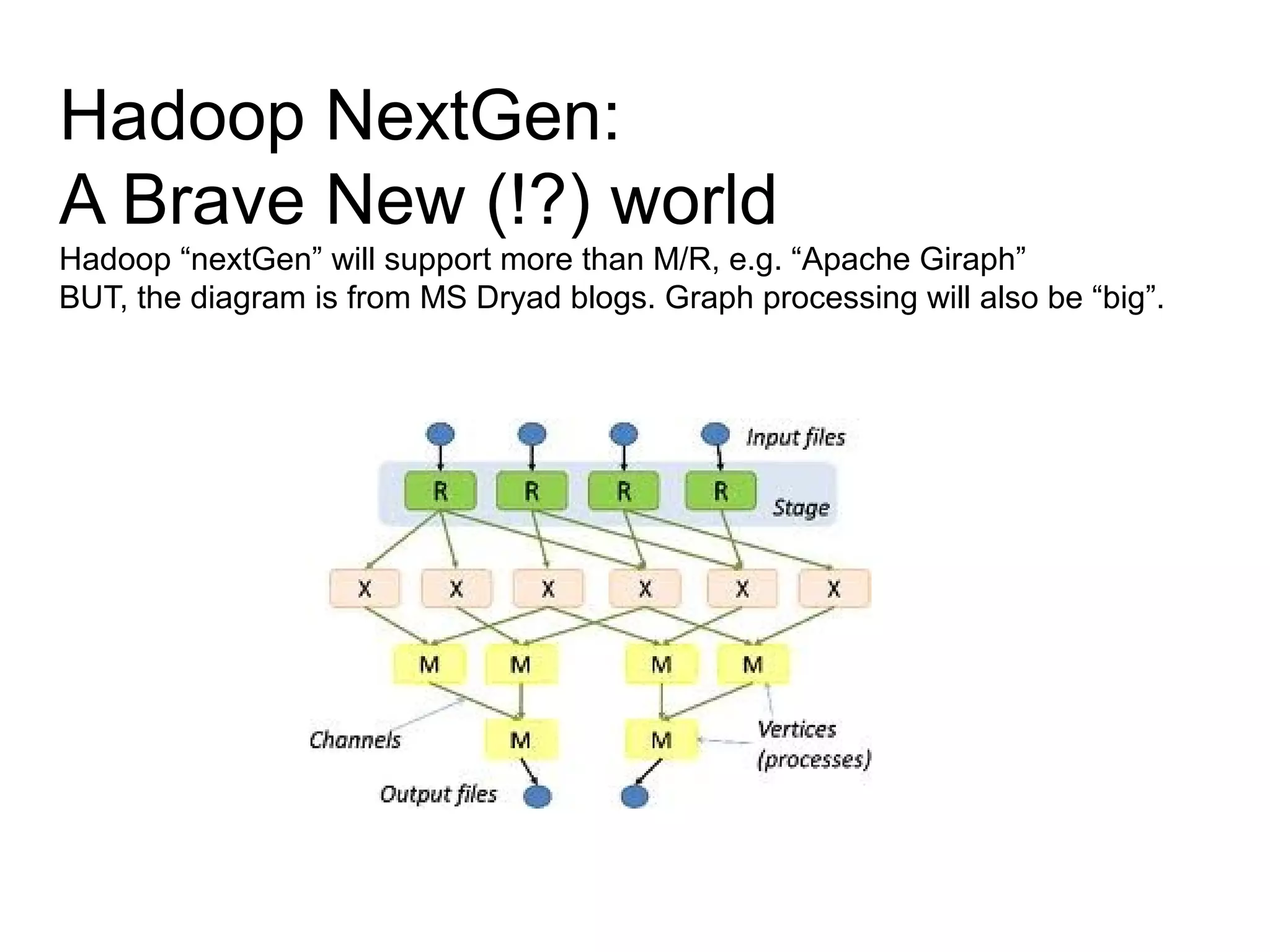
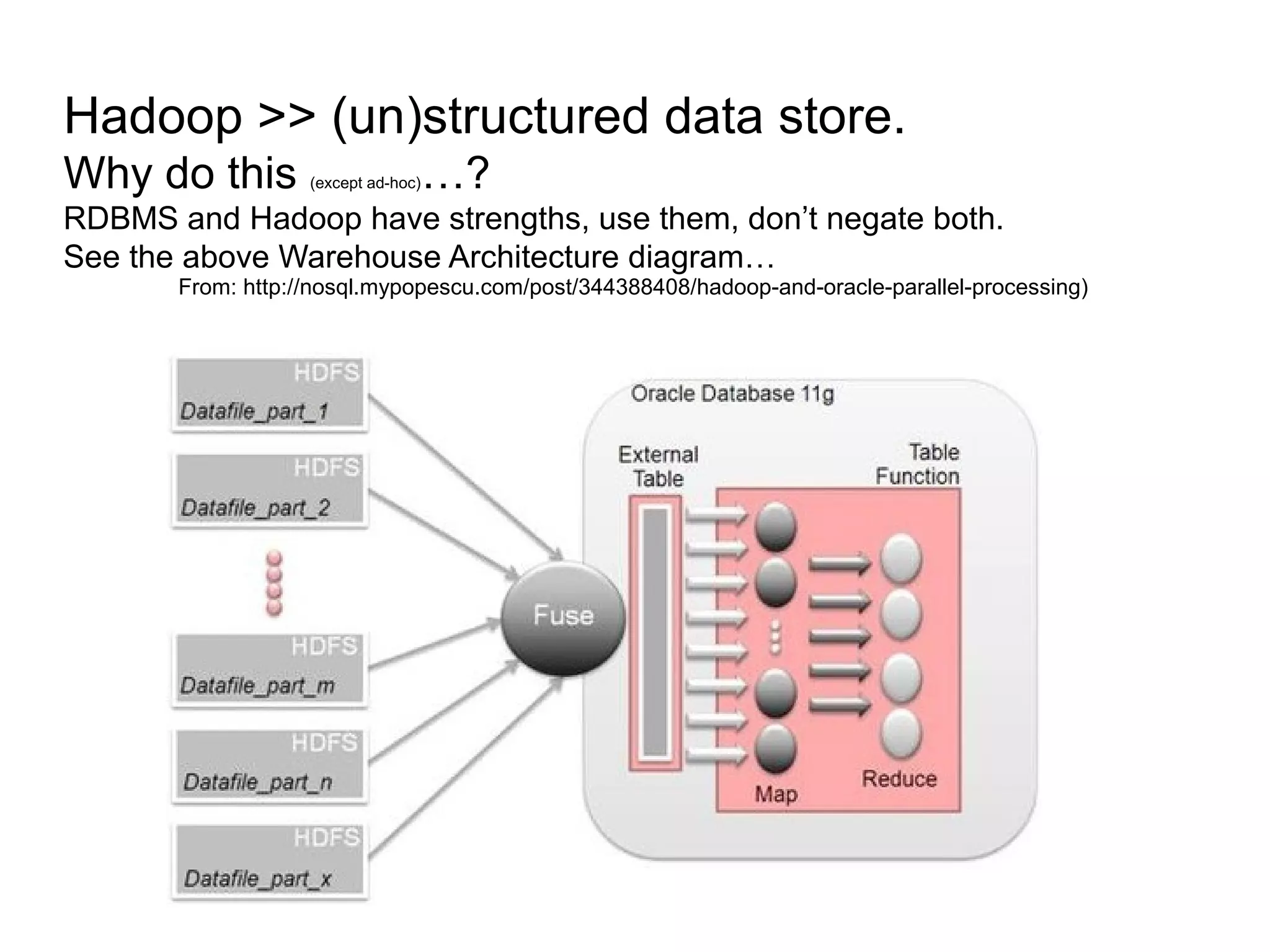
The document discusses Phil's extensive experience in data-centric system development and his focus on Hadoop, highlighting its integration into enterprise environments and successful migrations from traditional databases. It outlines key components of Hadoop, its functionalities including MapReduce, Hive, and HBase, and showcases projects that leverage Hadoop in various sectors, particularly healthcare. Additionally, the document touches on future trends in Hadoop and the collaboration between open-source and closed-source communities in enhancing Hadoop's ecosystem.
















![Hive Version…
The luxury of Hadoop space/power, means dimensional processing might not be
required
NOTE: Hive does support “column-oriented” storage, which is very efficient.
select t.*
from (
select ip_address, count(*) as cnt
from f_lookback
where ds = '2011-03-11'
group by ip_address
)t
order by cnt desc
Limit 10
– BUT – runtime is trickier
Time to run your job = HQL parse + M/R Job Submit + [ wait
in the queue for availability ] + M/R Job Runtime](https://image.slidesharecdn.com/hadoopdemoppt-130314172008-phpapp02/75/Hadoop-demo-ppt-27-2048.jpg)







































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
















