Downloaded 46 times

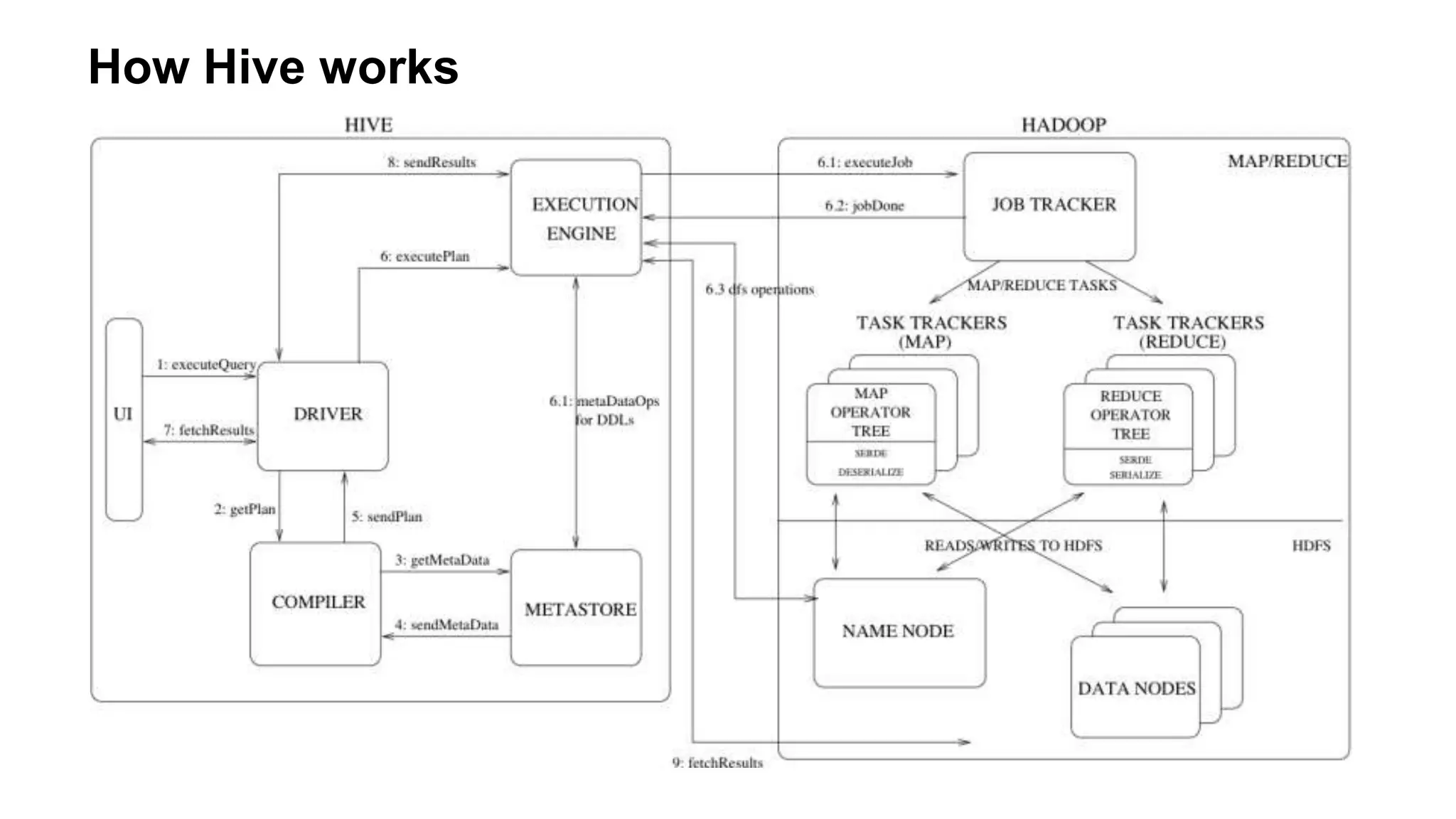







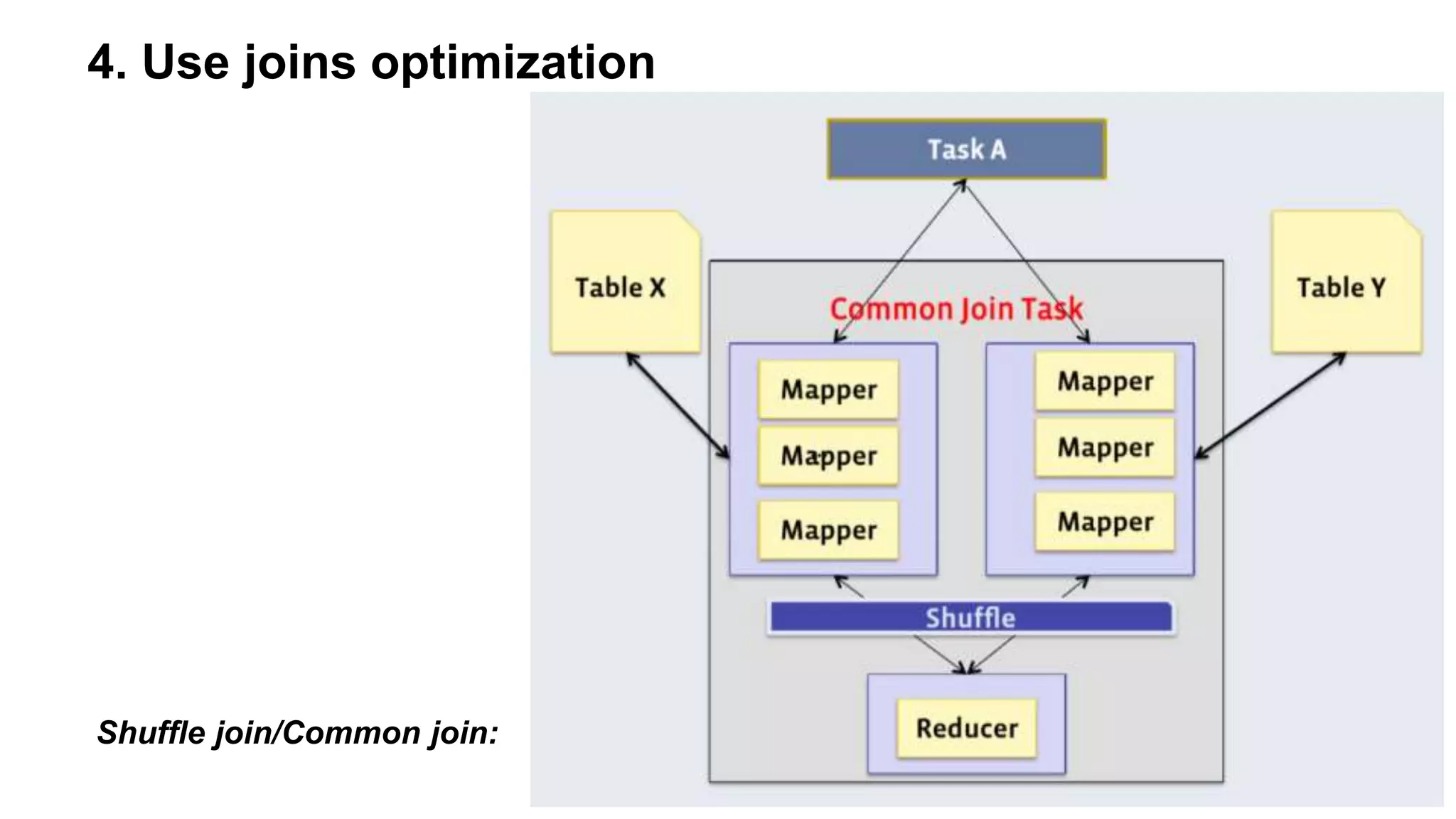
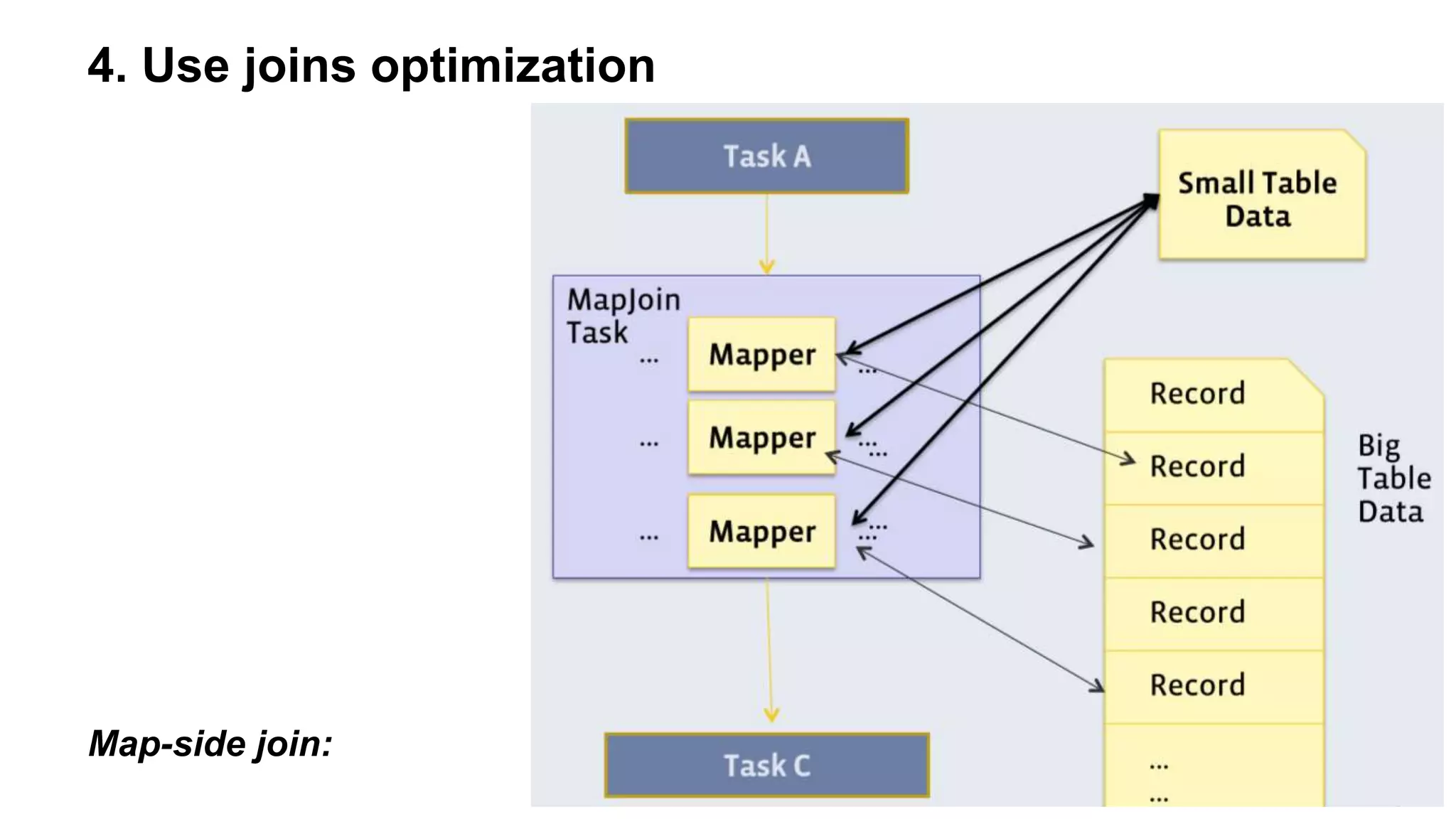
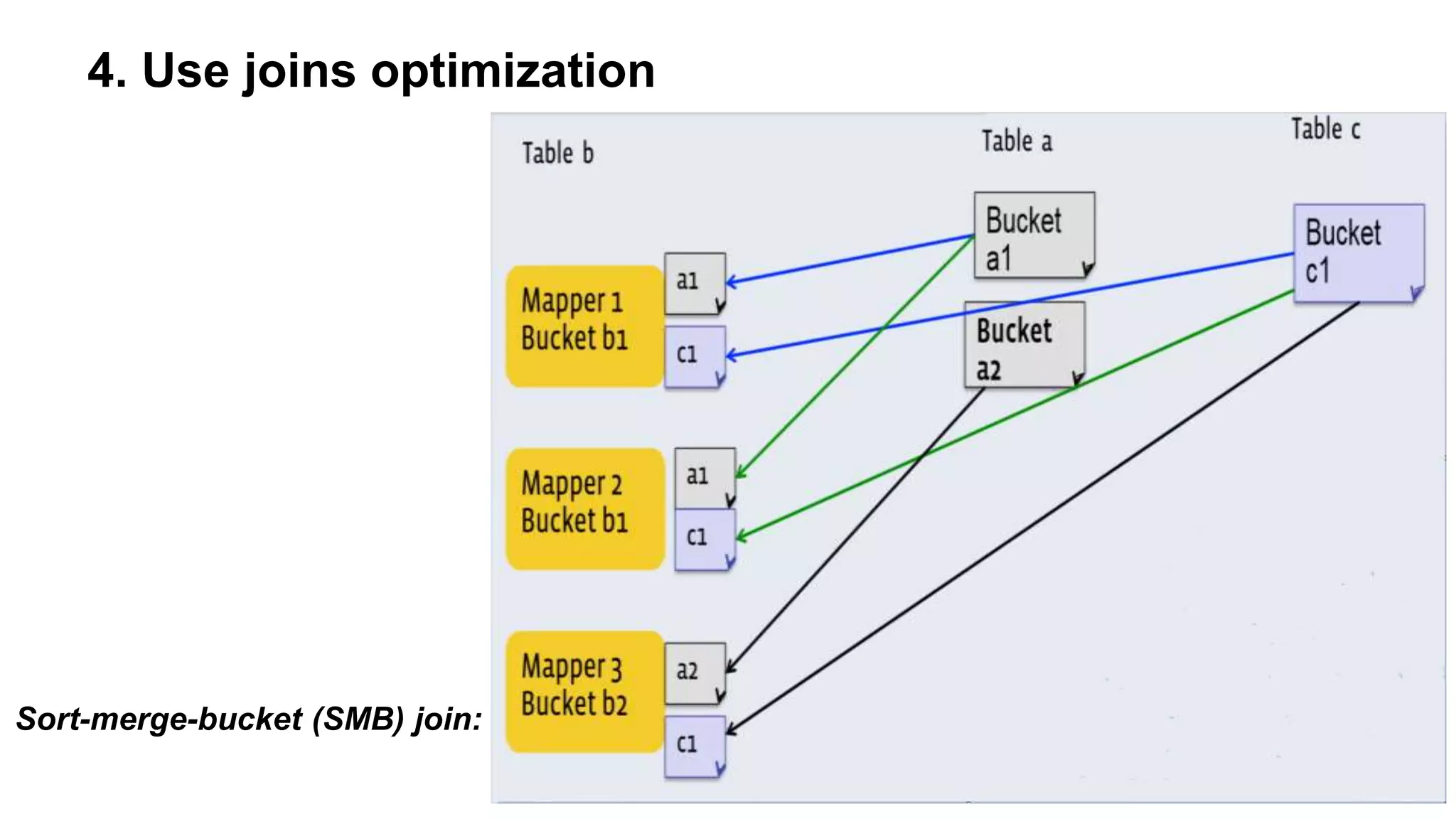
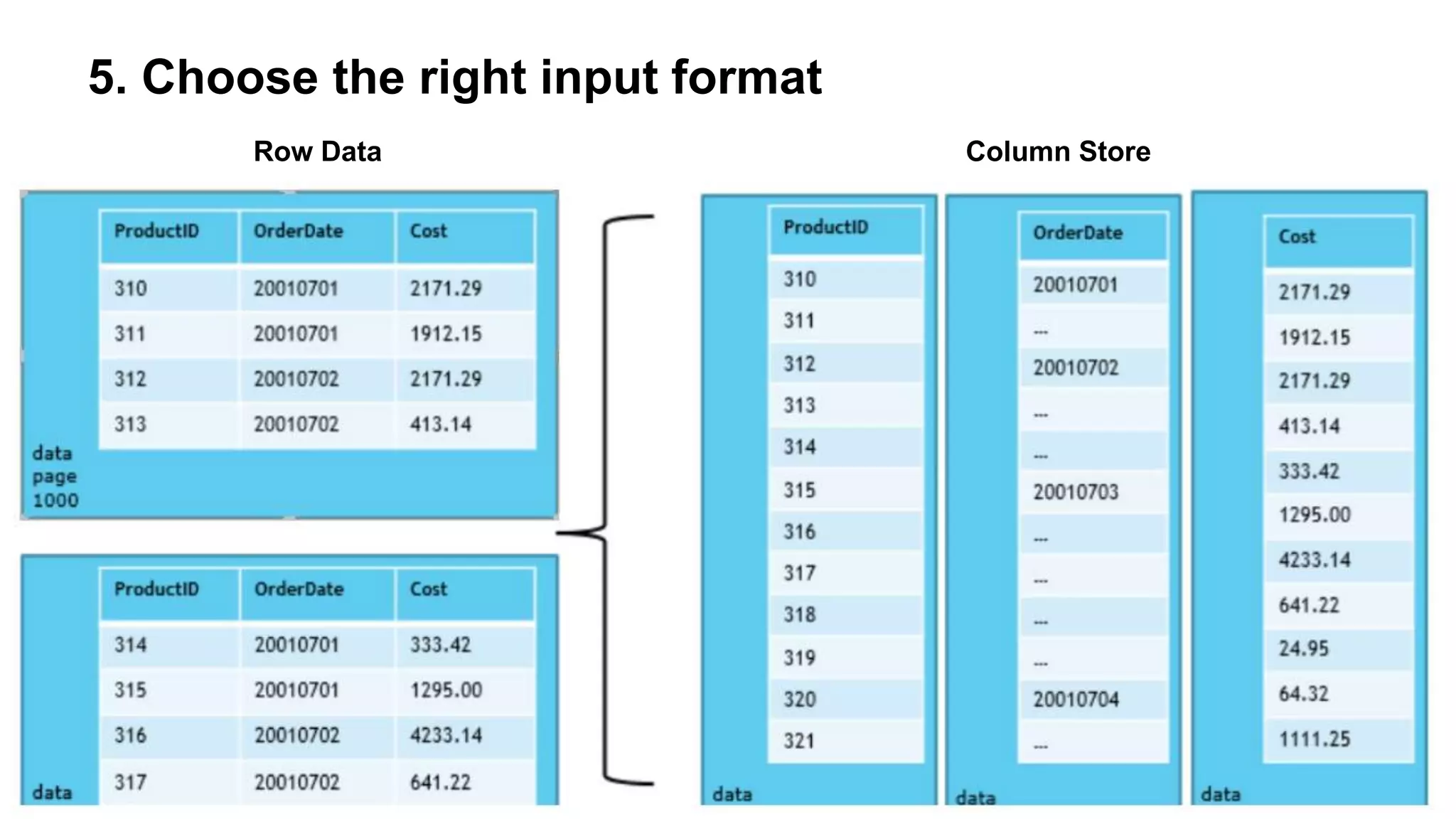


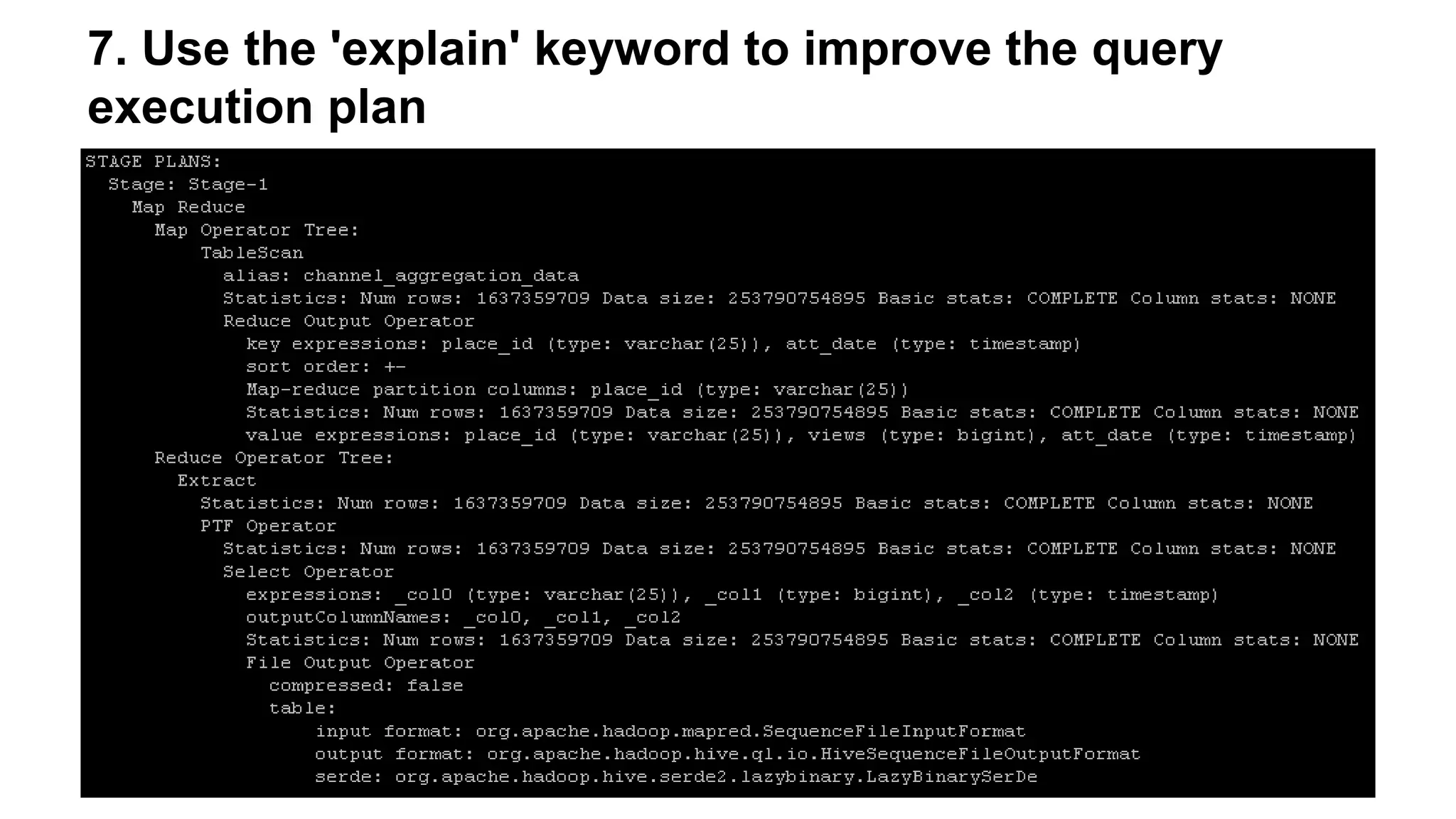

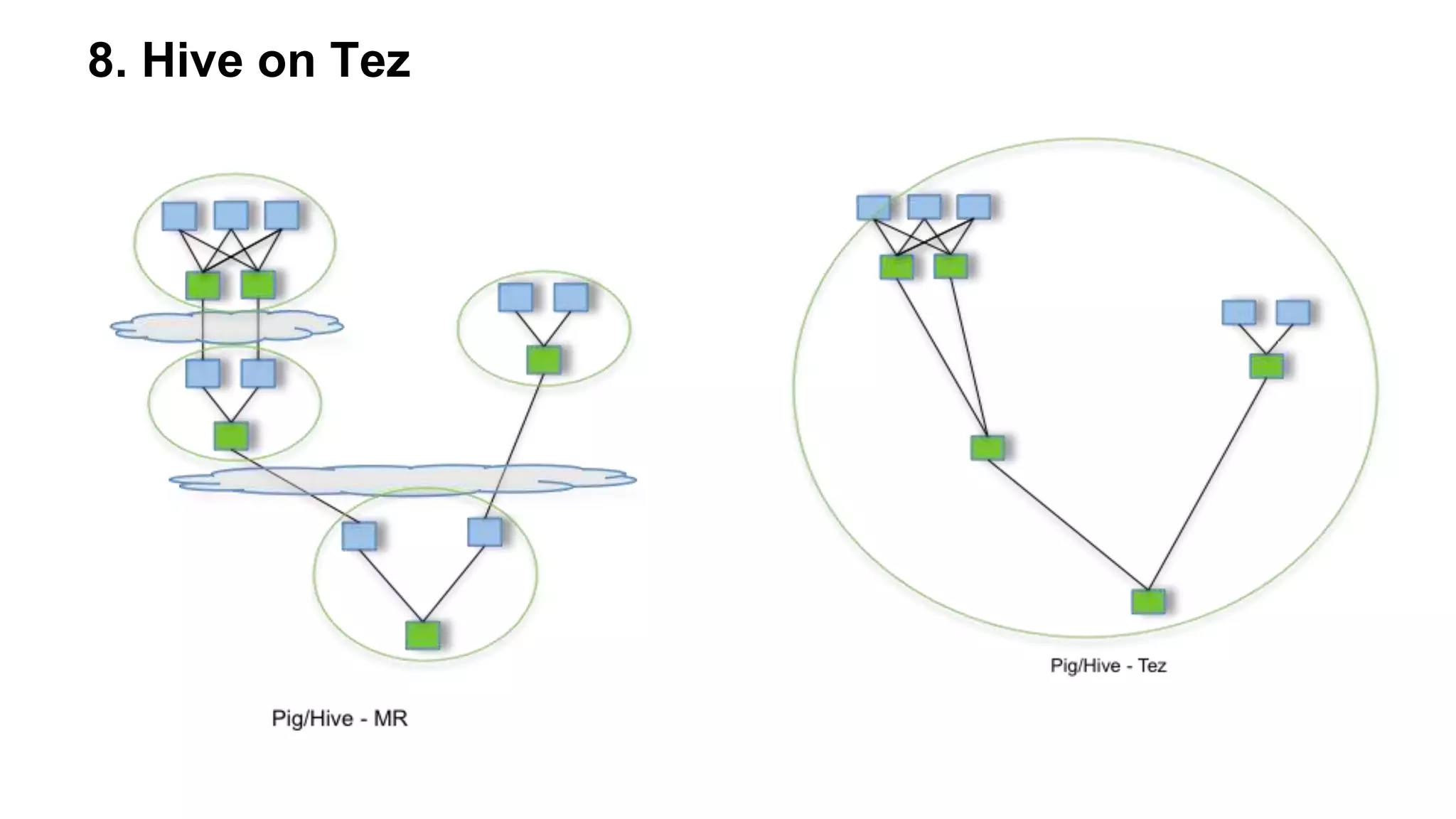
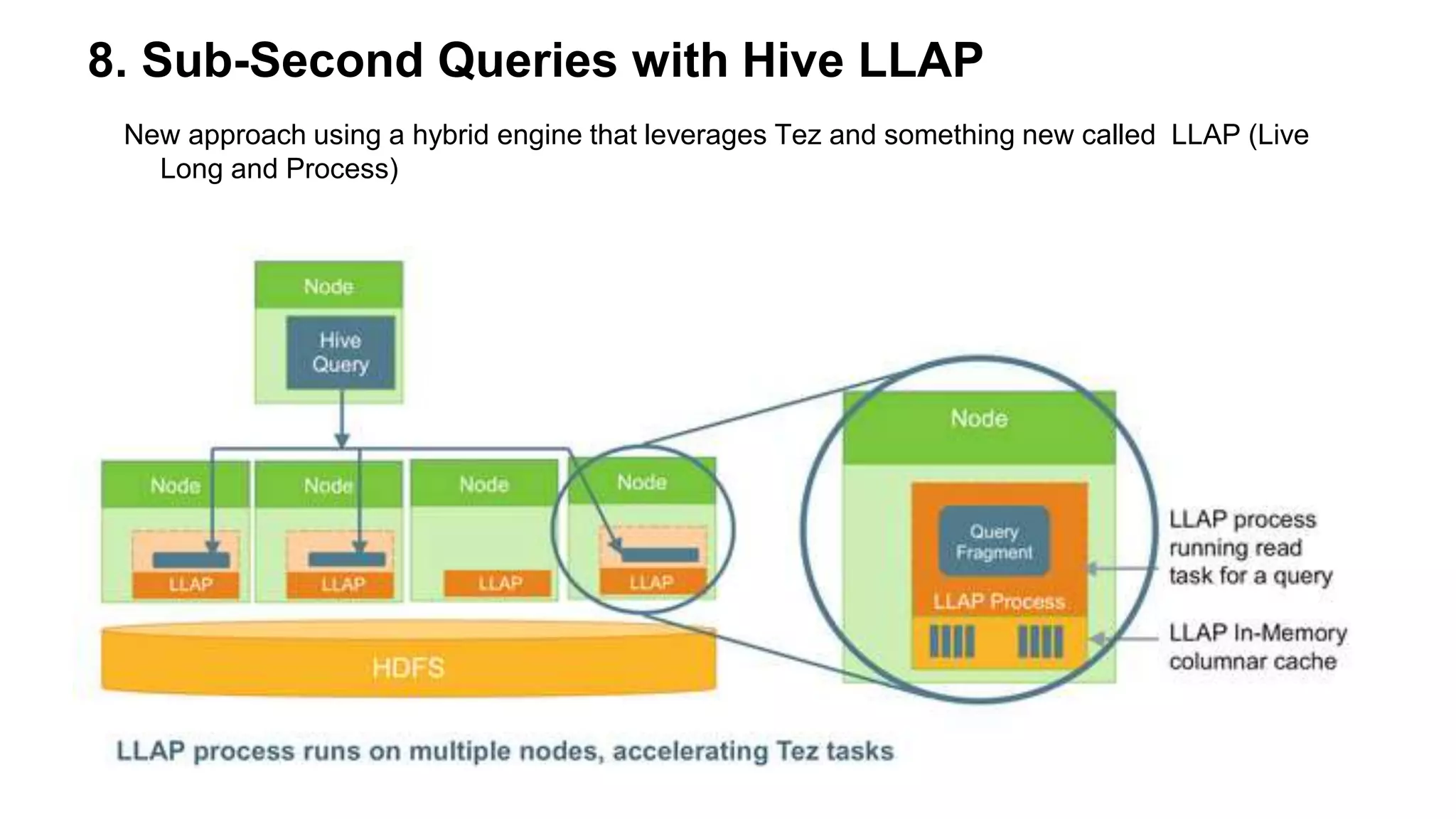


The document outlines practical steps to enhance Hive query performance, including the use of data partitioning, bucketing, and optimized joins. It emphasizes creating structured tables and utilizing various optimization techniques such as compression and vectorization. Additionally, the document suggests leveraging the explain keyword for better query execution insights and mentions advancements like Hive on Tez and LLAP for faster query processing.



































































