Downloaded 26 times







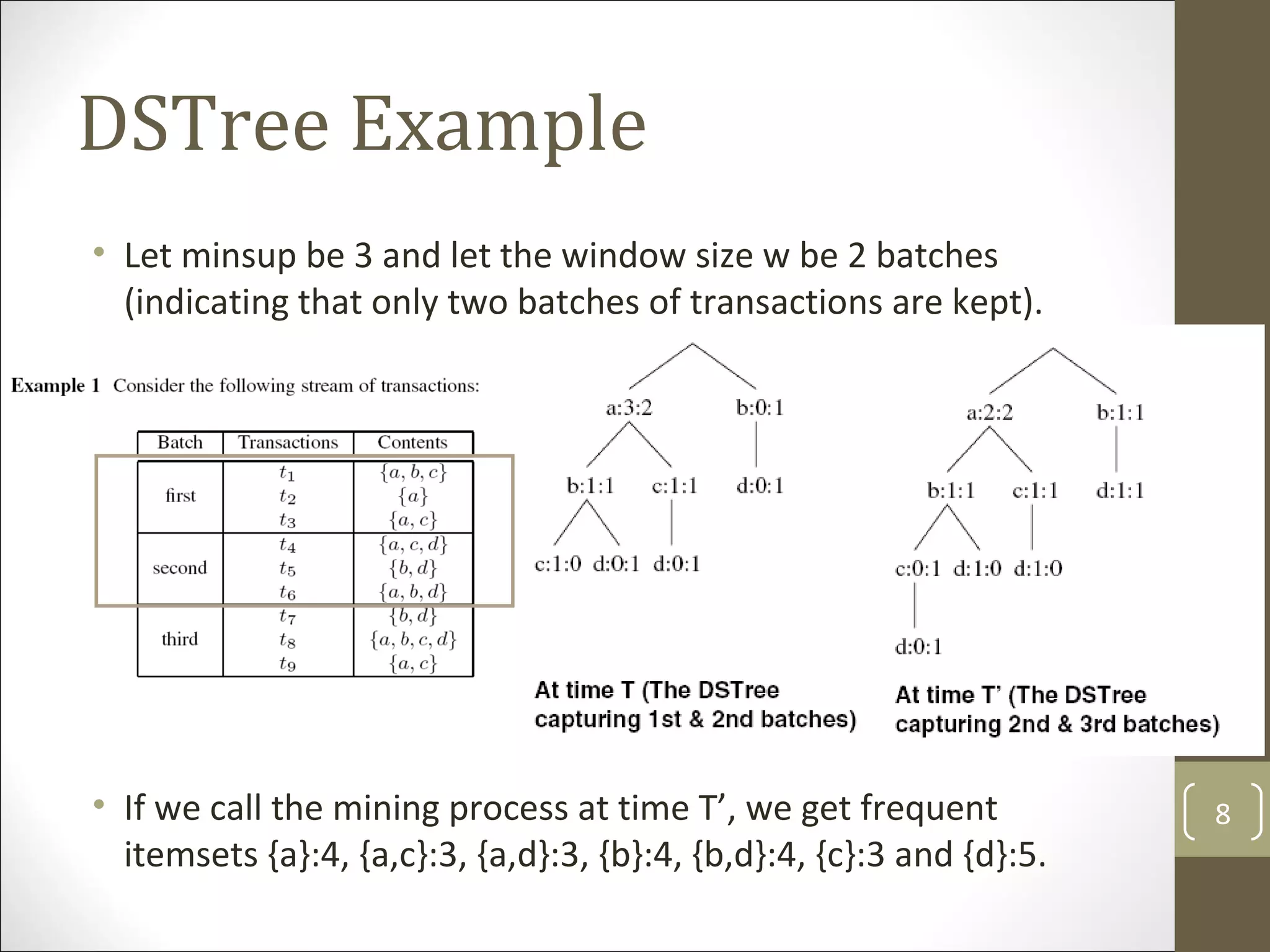






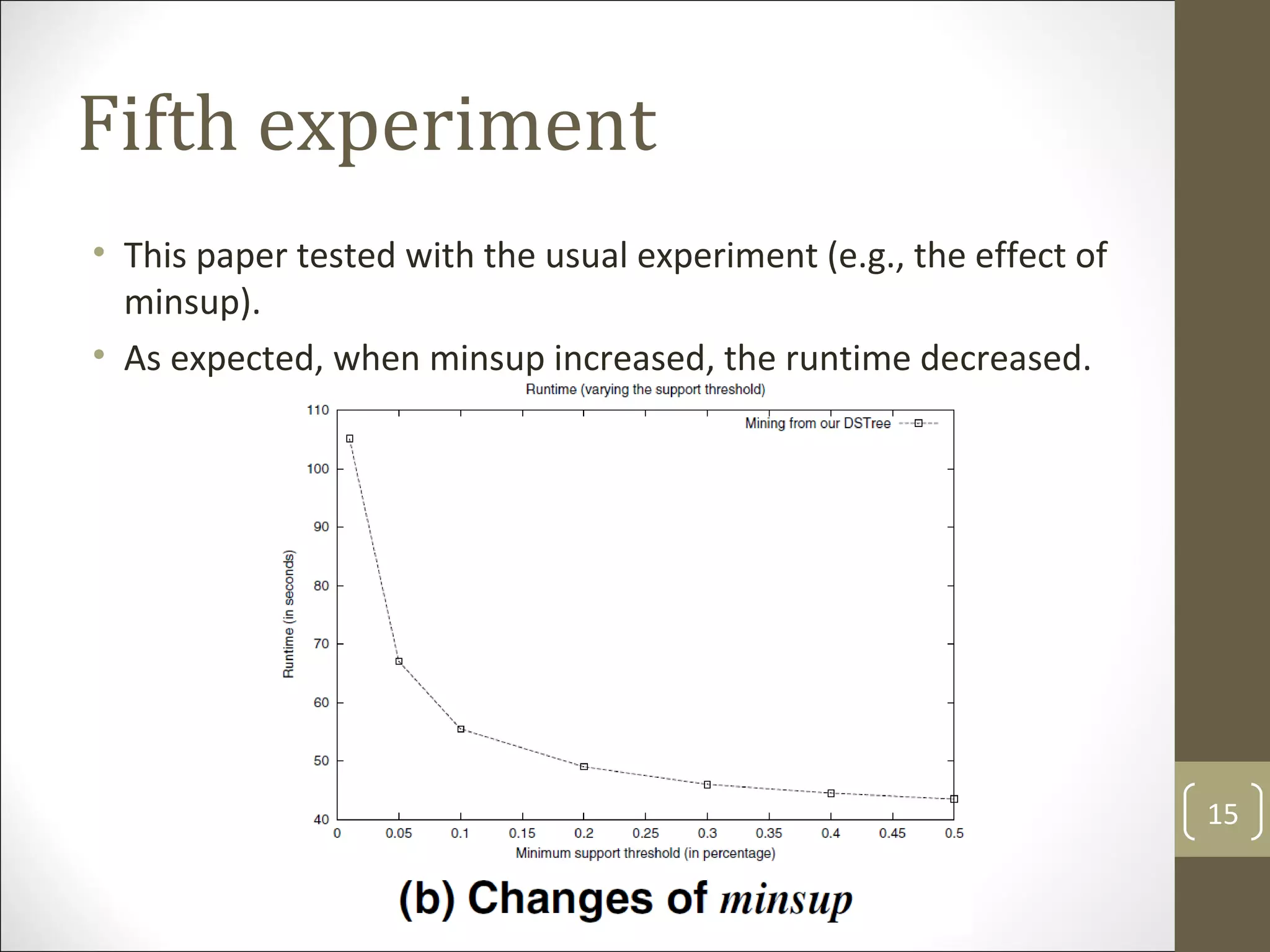
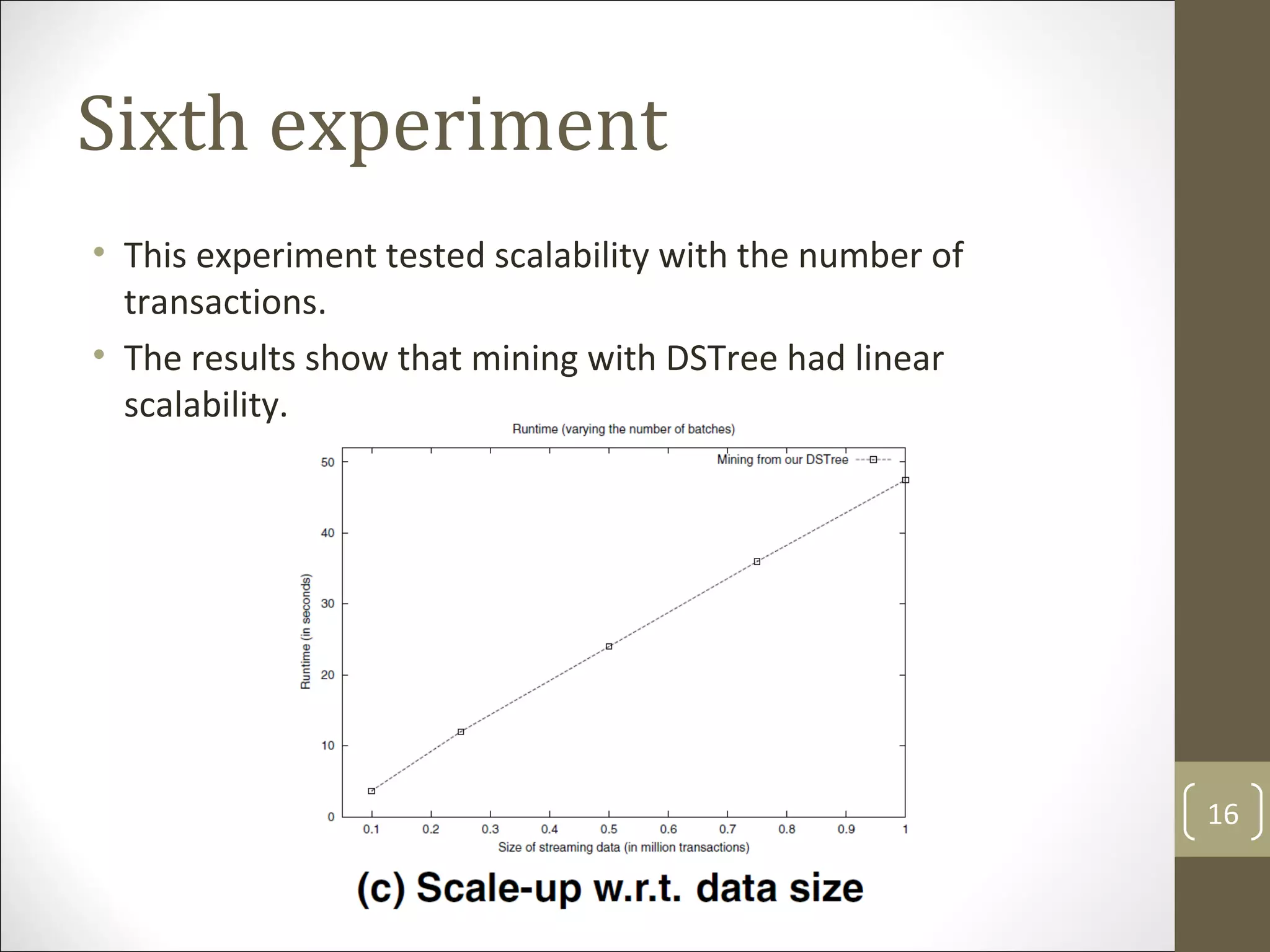


The document presents dstree, a novel data structure designed for exact stream mining of frequent itemsets in data streams. It compares dstree against existing algorithms like cantree and fp-streaming, demonstrating its efficiency, accuracy, and lower maintenance costs. The experimental results confirm that dstree maintains linear scalability and offers better performance in terms of memory usage and result accuracy compared to approximate mining techniques.




































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)




