Downloaded 28 times




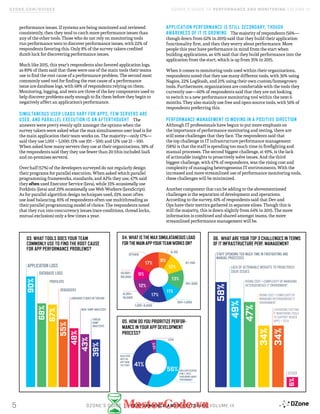

















![BOTTLENECKSBOTTLENECKS LATENCIESLATENCIES
2014
3630
42
42
13
3
APPLICATION CODE
31
19
40
10
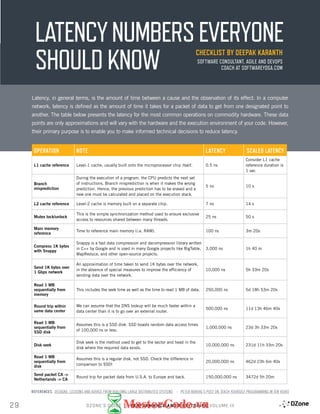
ONE CPU CYCLE
L1 CACHE ACCESS
L2 CACHE ACCESS
L3 CACHE ACCESS
SSD RANDOM FEED
INTERNET: SF TO NYC
READ 1M BYTES
SEQUENTIALLY FROM MEMORY
READ 1M BYTES
SEQUENTIALLY FROM SSD
READ 1M BYTES
SEQUENTIALLY FROM A SPINNING DISK
MAIN MEMORY ACCESS
WHICH = 1 SEC, OR IS
EQUAL TO CLAPPING
YOUR HANDS=.3NS
WHICH = 3 SEC, OR IS
EQUAL TO BLOWING YOUR
NOSE=.9NS
WHICH = 9 SEC, OR IS
EQUAL TO BILL GATES
EARNING $2,250=2.8NS
WHICH = 43 SEC, OR IS EQUAL TO
COMPLETING AN AVERAGE MARIO
BROS. LEVEL 1-1 SPEED RUN=12.9NS
WHICH = 6 MIN, OR IS EQUAL TO
LISTENING TO QUEEN’S
“BOHEMIAN RHAPSODY”=100NS
WHICH = 70 DAYS, OR IS EQUAL
TO PLANTING AND HARVESTING
A ZUCCHINI=2MS
WHICH = 7 YEARS, OR IS EQUAL
TO ATTENDING AND GRADUATING
HOGWARTS (IF YOU’RE A WITCH
OR WIZARD)
=71MS
WHICH = 9 HOURS, OR IS
EQUAL TO COMPLETING A
STANDARD US WORKDAY=9 S
WHICH = 14 HOURS, OR IS
EQUAL TO TAKING A FLIGHT
FROM NEW YORK TO BEIJING=16 S
8 DAYS, OR IS EQUAL TO, IF THERE
WERE 8 DAYS IN A WEEK, IT
WOULD NOT BE ENOUGH FOR THE
BEATLES TO SHOW THEY CARE=200 S
CLIENTS
APPLICATION
SERVER
STORAGE
MEMORY
DATABASE
NETWORK
4033
189
9
24
40
27
CPU
2623
43
7
DATABASE
HOW TO KEEP YOUR THREADS BUSY
SMART CONTENT FOR TECH PROFESSIONALS DZONE.COM
YOU AREN'T BUILDING SILICON, SO AS A DEVELOPER YOU
CAN'T CHANGE HOW LONG SOME THINGS TAKE. BUT THERE
ARE PLENTY OF BOTTLENECKS YOU CAN FIND AND FIX.
WHAT PERFORMANCE BOTTLENECKS ARE MOST COMMON? WE SURVEYED OVER 600
DEVELOPERS AND RESULTS SUMMARIZED THEIR RESPONSES ON THE LEFT. WHAT
LATENCIES ARE JUST WHAT THEY ARE? WE TOOK DATA GATHERED BY PETER NORVIG
AND JEFF DEAN AND VISUALIZED THEIR RESULTS BELOW.
FREQUENT ISSUES SOME ISSUES RARE ISSUES
SCALED WHERE ONE CPU CYCLE [.3NS] = 1 SEC
NO ISSUESKEY](https://image.slidesharecdn.com/dzone-performancemonitoring2016-mastercode-170414141246/85/Dzone-performancemonitoring2016-mastercode-vn-26-320.jpg)























This document summarizes the key findings from a survey of 594 IT professionals on performance and monitoring practices: - Application code and databases most commonly have frequent performance issues that need to be addressed within weeks. Database performance problems are the hardest to fix. - Finding the root cause of performance issues is still the most time-consuming part of the problem-solving process and it often takes teams less than a week on average to resolve issues. - Monitoring tools are most effective at discovering performance problems, followed by application logs and performance tests. However, manual firefighting and lack of actionable insights from tools remain key challenges. - Parallel programming and optimizing for multi-core processors is still not a primary
























![[Spring Camp 2018] 11번가 Spring Cloud 기반 MSA로의 전환 : 지난 1년간의 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/201804springcamp11stmsafinalpubslideshare-180527051608-thumbnail.jpg?width=640&height=640&fit=bounds)




















![Continuous Performance Monitoring of a Distributed Application [CON4730]](https://cdn.slidesharecdn.com/ss_thumbnails/con4730yuryeva-131008203609-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









































