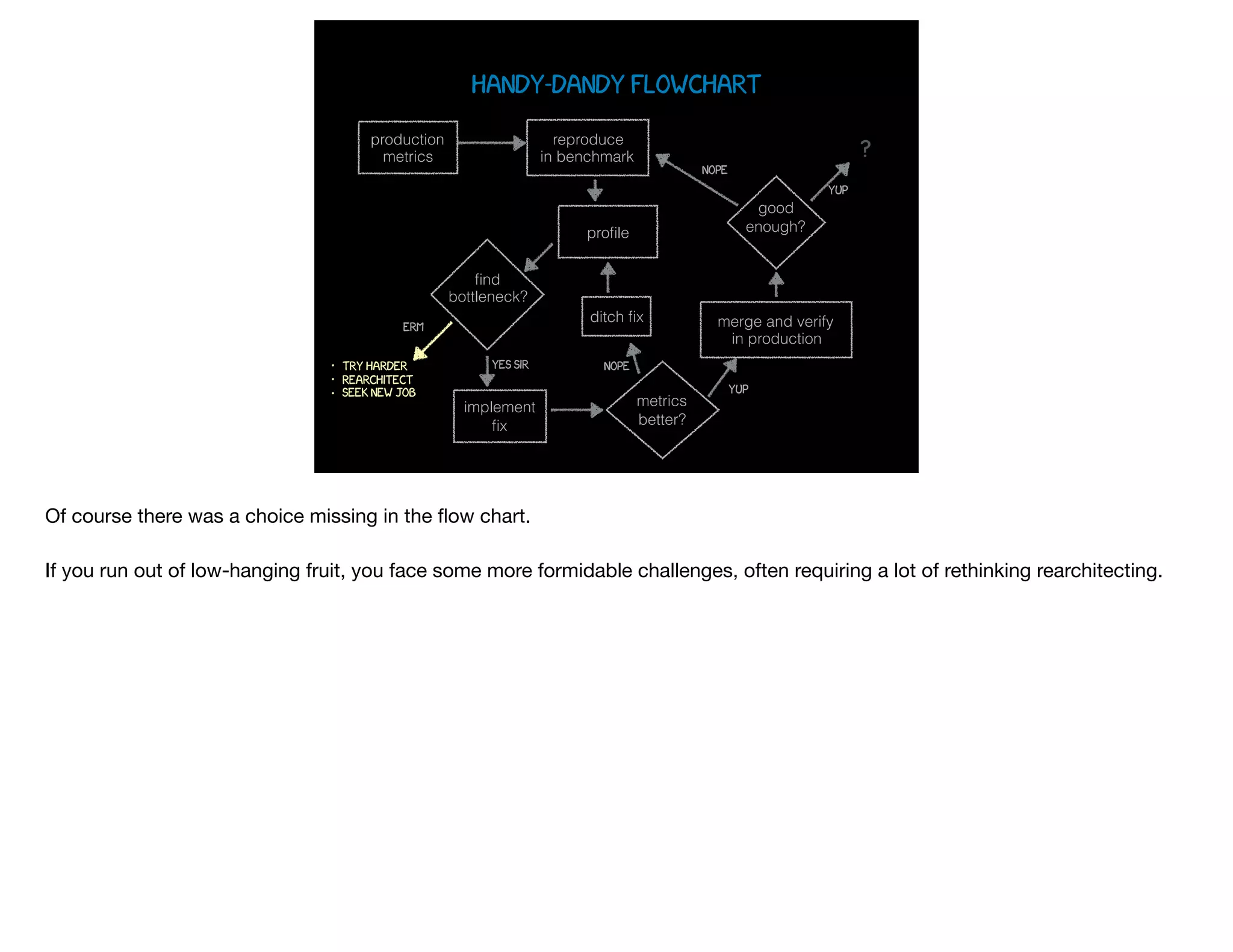
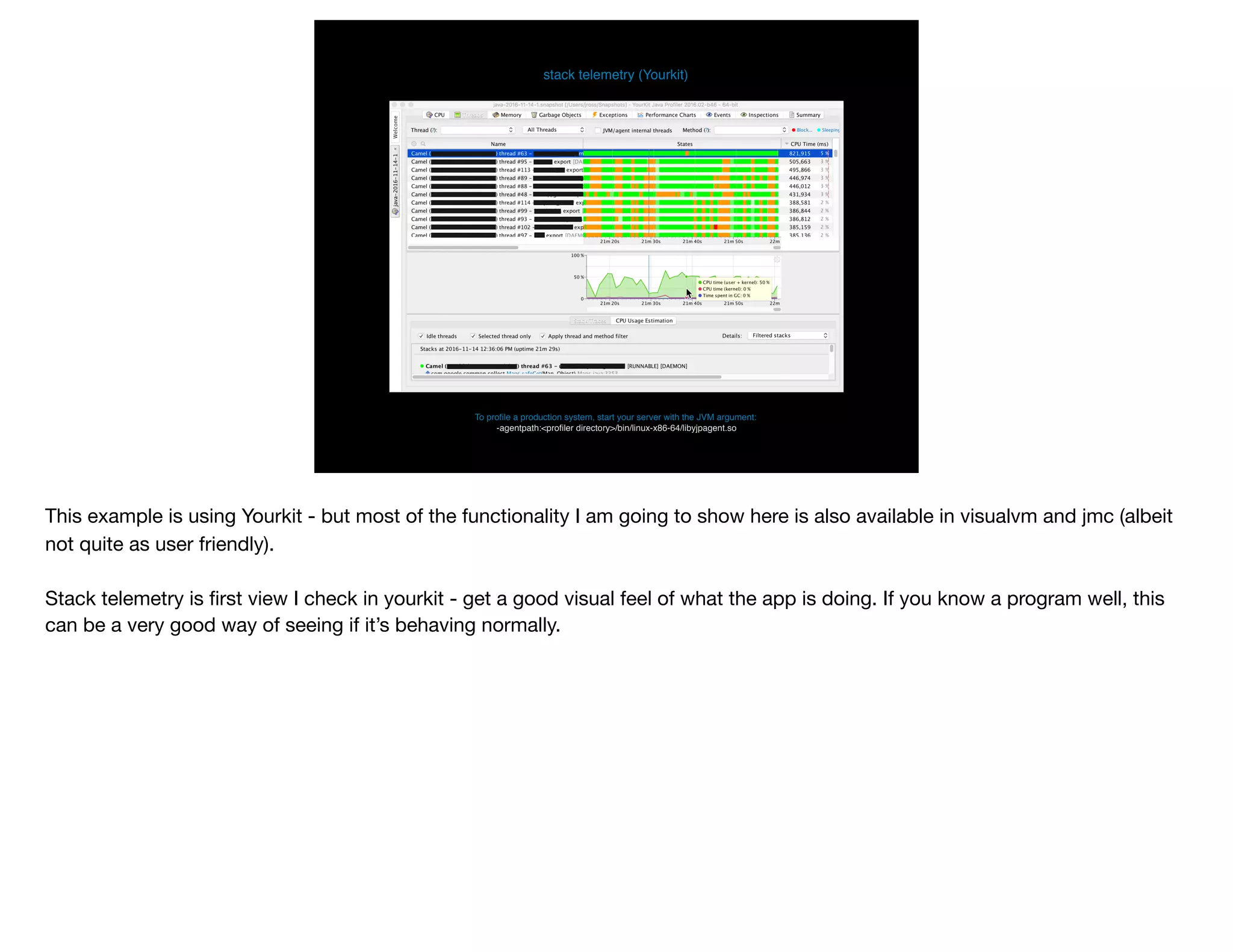
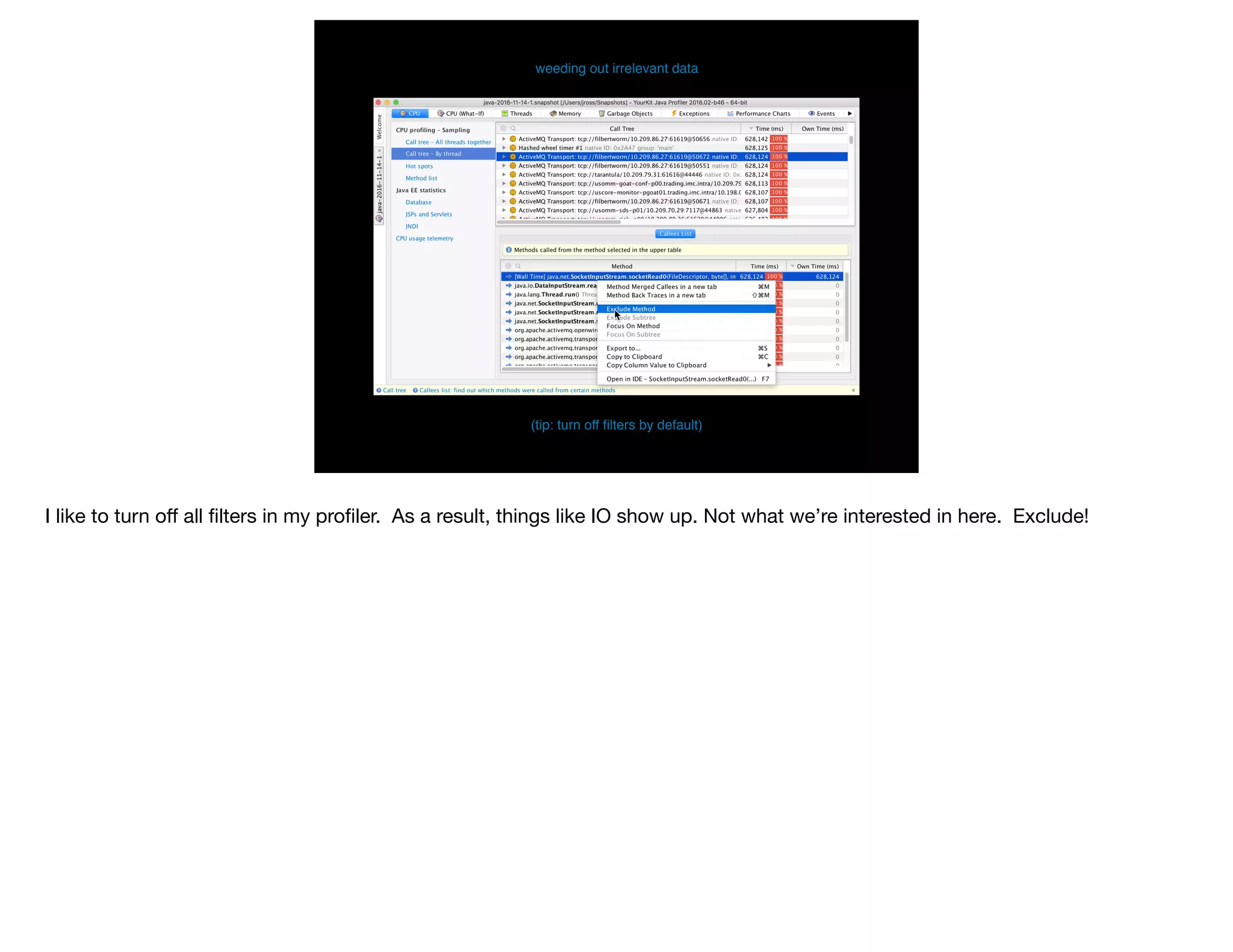
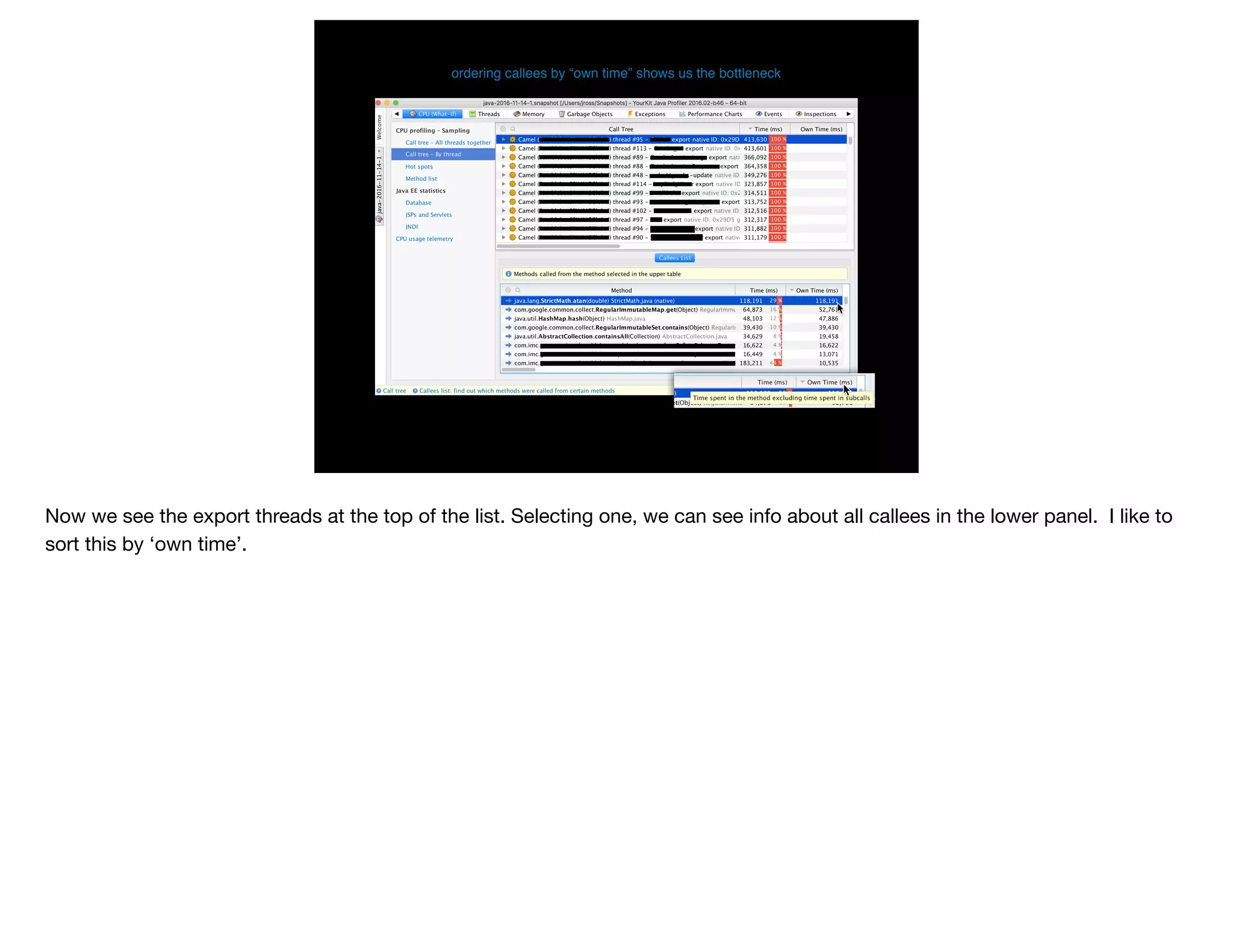
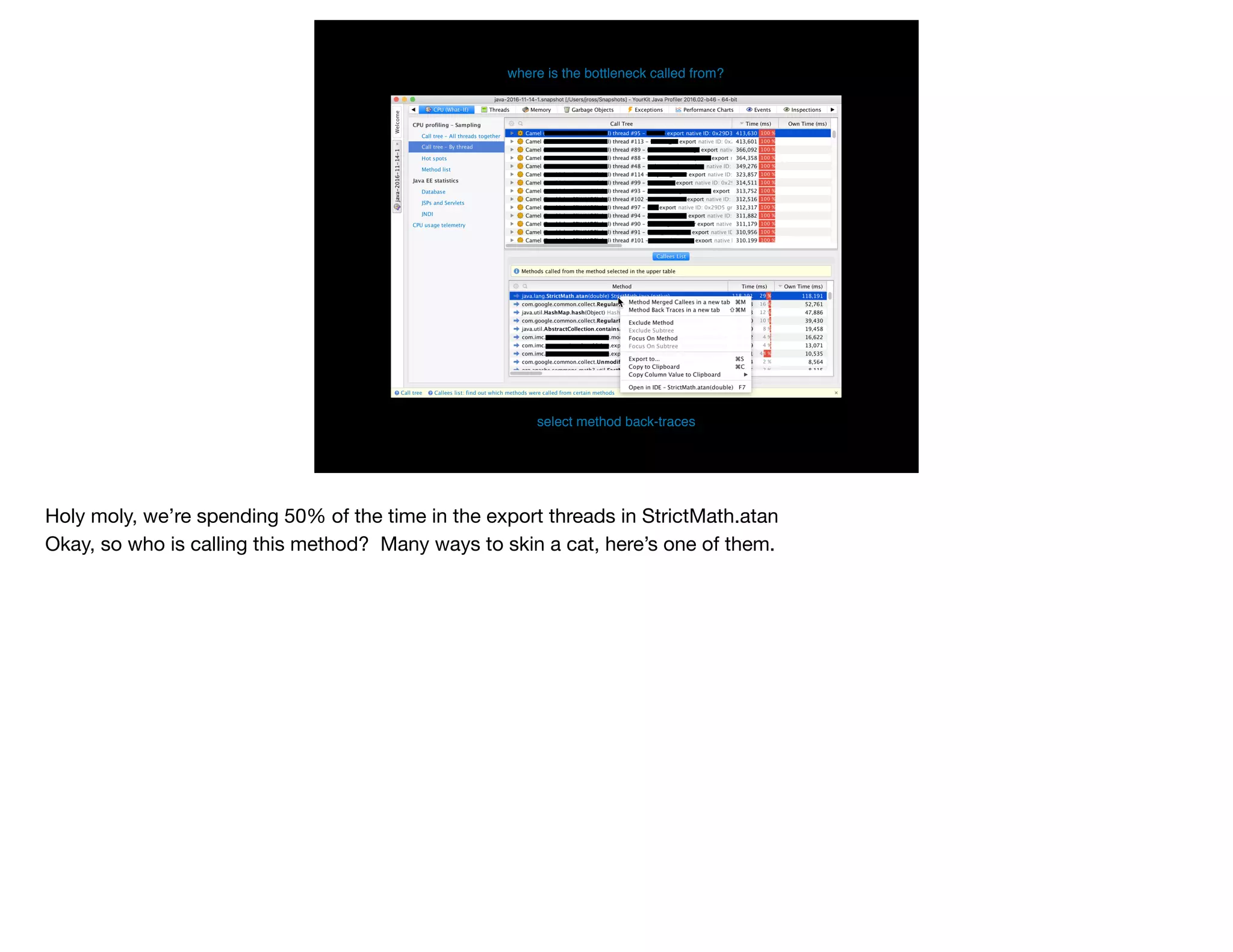
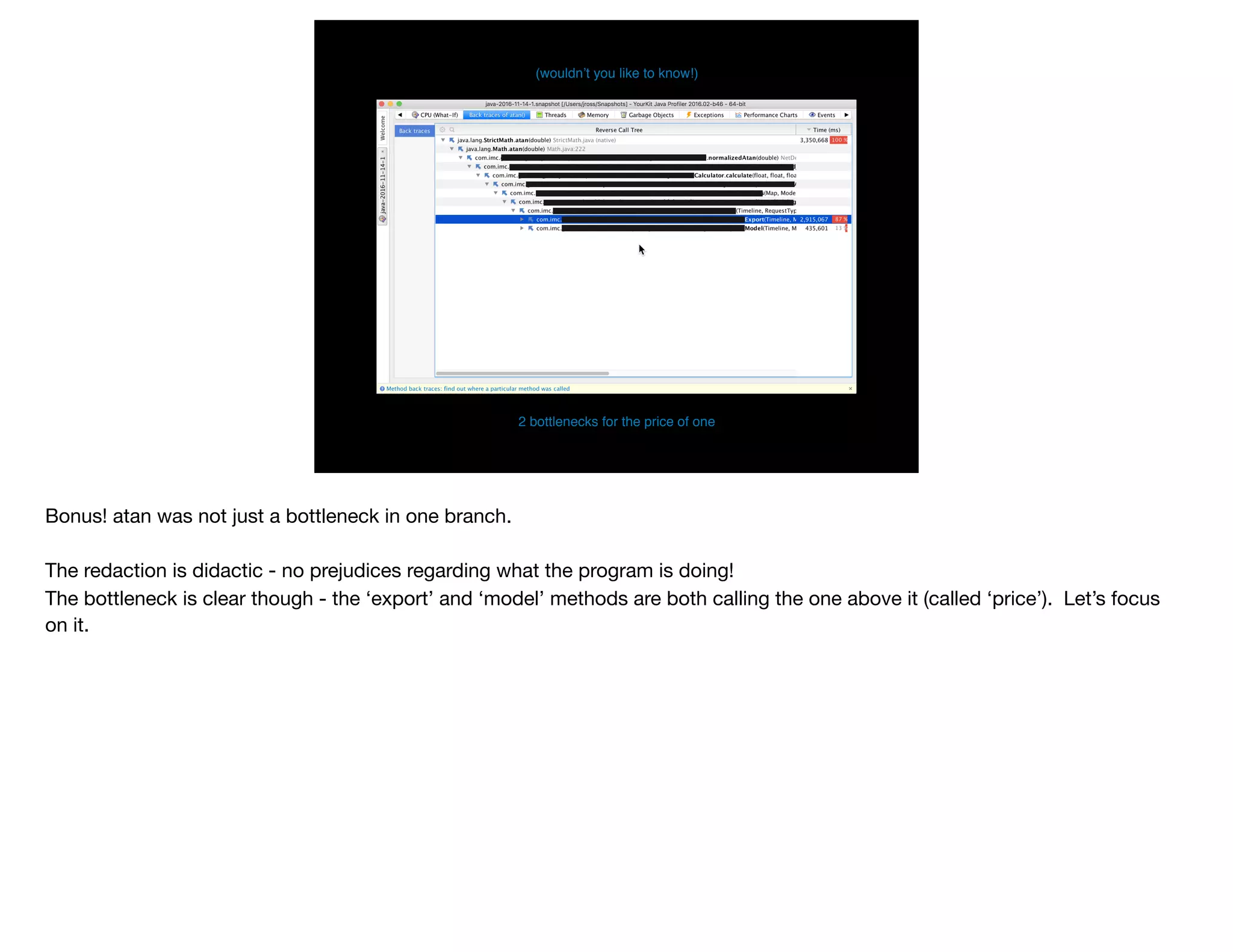
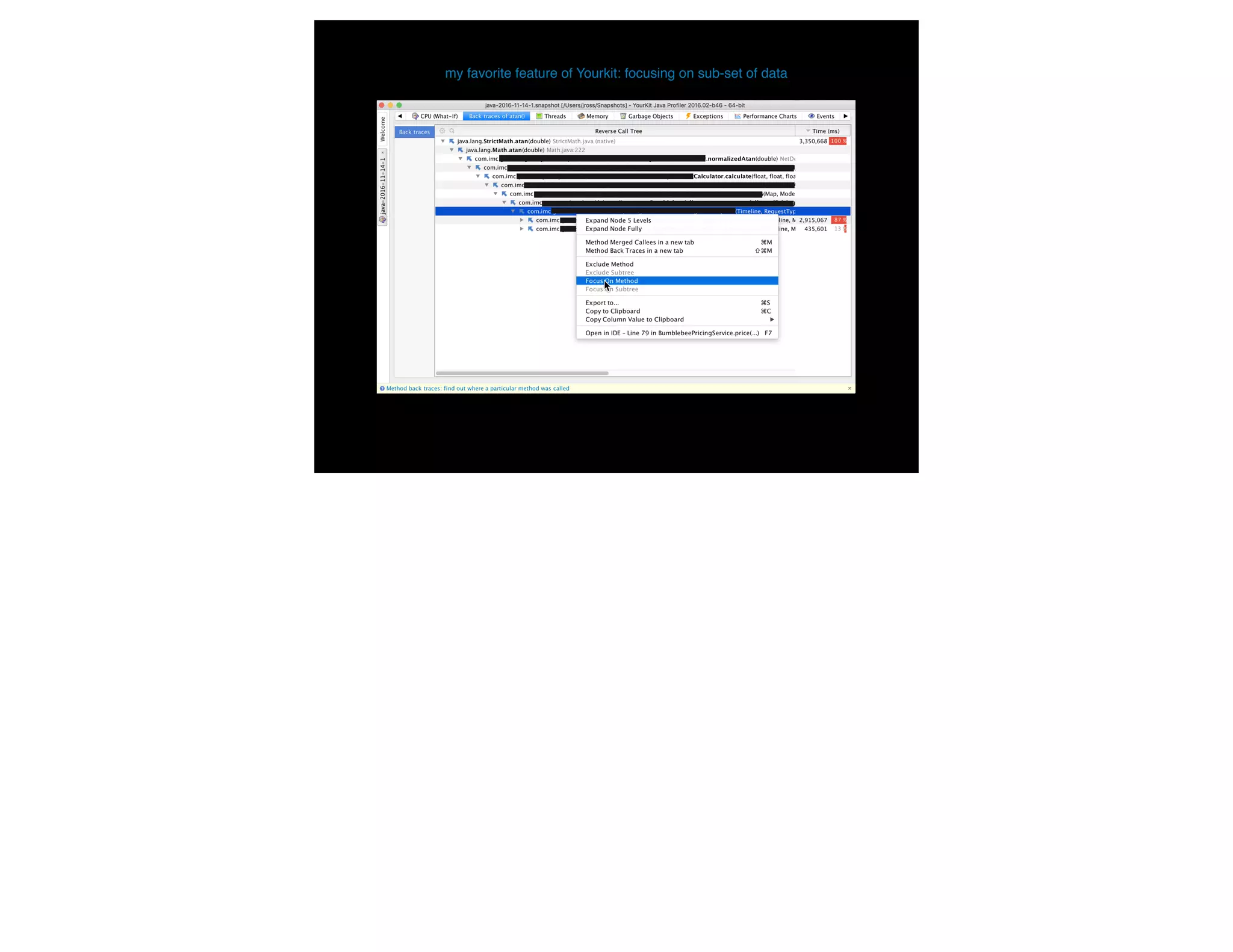
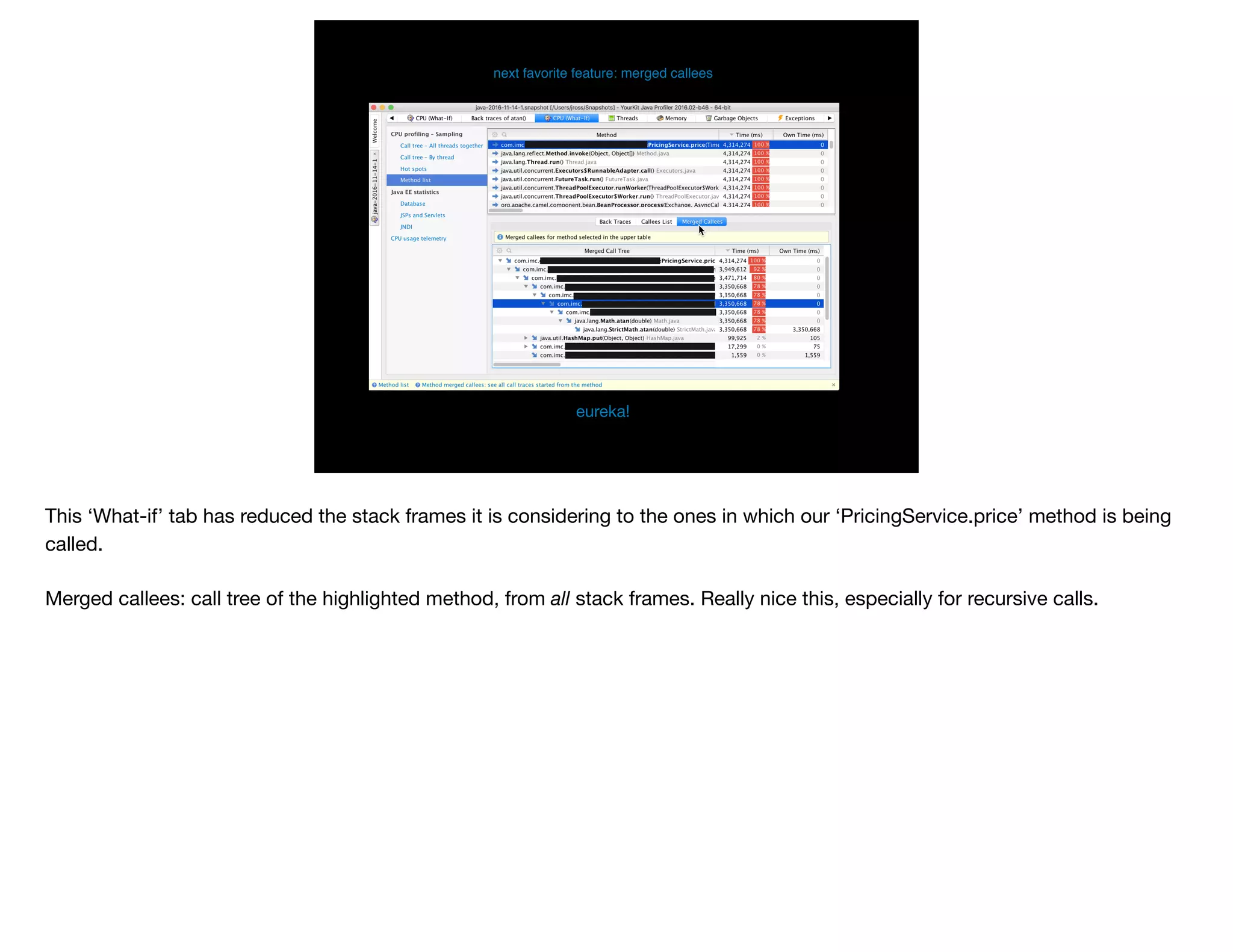
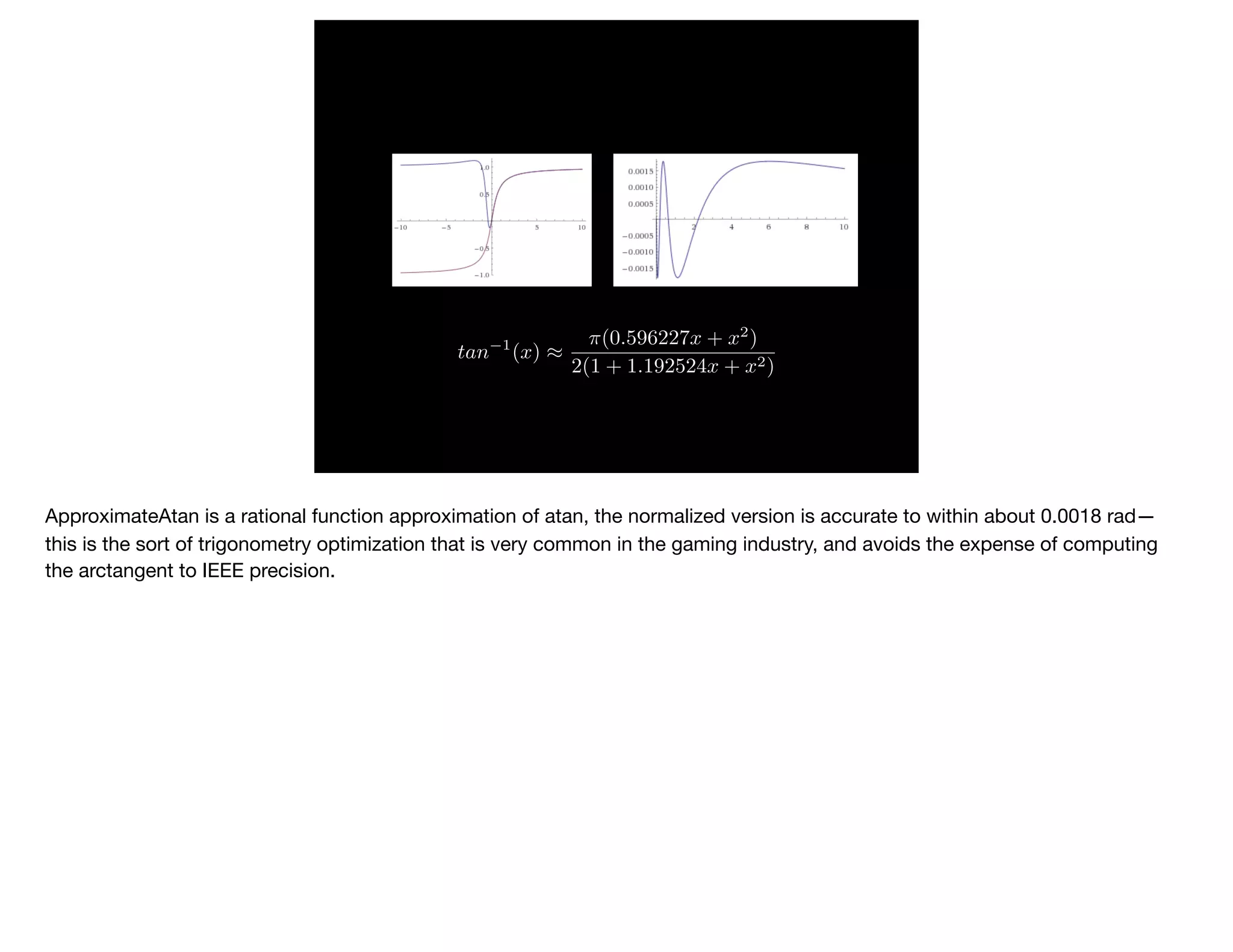
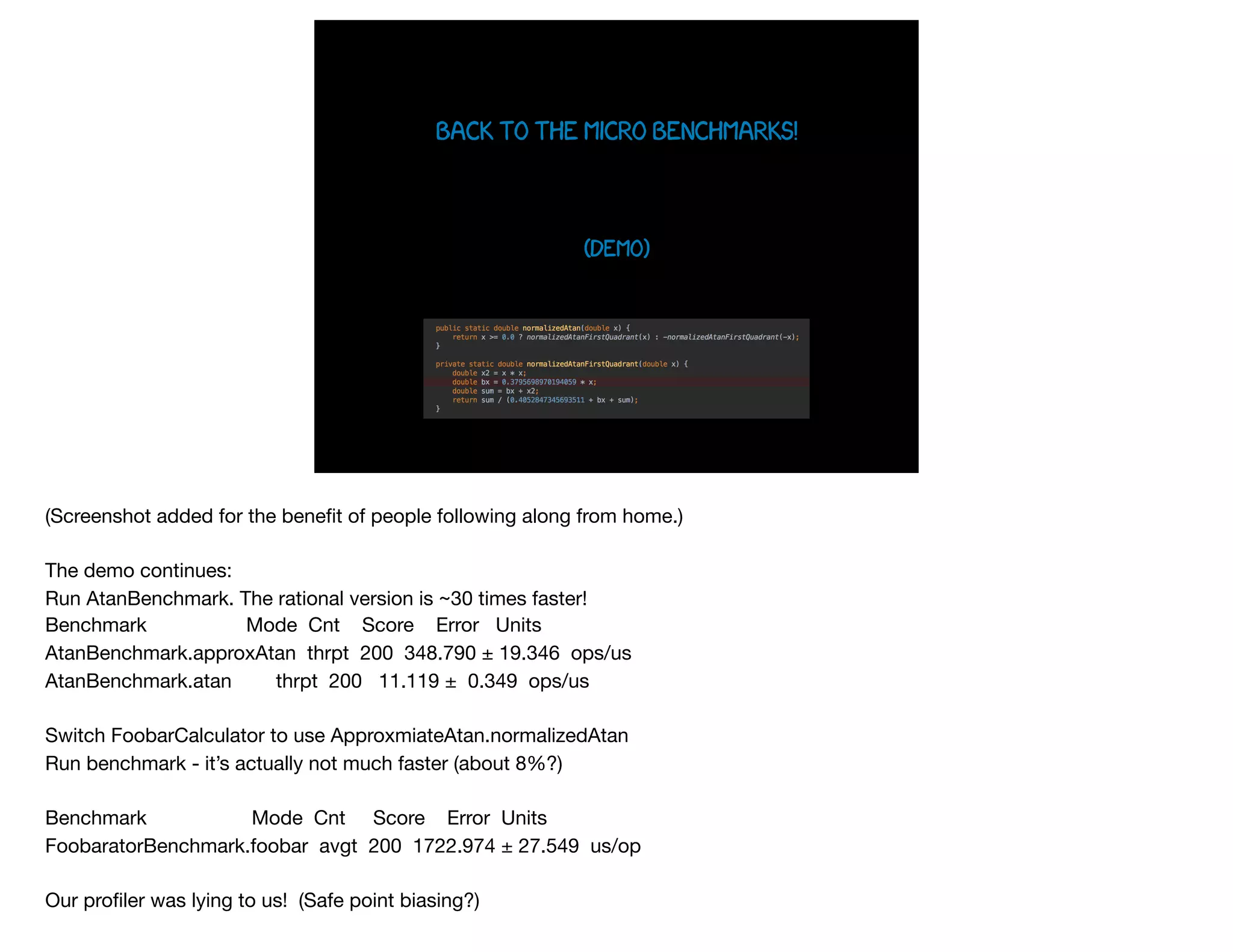
The document presents slides from Jonathan Ross's talk on performance tuning at JavaOne 2017, emphasizing the importance of using scientific methods and profiling to address performance issues in Java applications. It covers challenges, methodologies, and hands-on practices related to performance profiling, benchmarking, and tackling bottlenecks, with specific demos of profiling tools like YourKit and JMC. The session aims to equip developers, especially those less experienced with profiling, with practical techniques for improving application performance.