More Related Content
![[DSO]勉強会_データサイエンス講義_Chapter7](https://cdn.slidesharecdn.com/ss_thumbnails/dsodatasciencelecturechapter7-191122112044-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DSO]勉強会_データサイエンス講義_Chapter7 ![[DL輪読会]DropBlock: A regularization method for convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/dlyokota20190222-190222002832-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]DropBlock: A regularization method for convolutional networks 
PDF

PDF
![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて- 
PDF

PDF
感覚運動随伴性、予測符号化、そして自由エネルギー原理 (Sensory-Motor Contingency, Predictive Coding and ... 
PDF
What's hot

PDF

PPTX

PPTX
学習時に使ってはいないデータの混入「リーケージを避ける」 
PDF

PDF

PDF

PPTX

PDF
教師なしGNNによるIoTデバイスの異常通信検知の検討 
PDF

PDF

PDF
BlackBox モデルの説明性・解釈性技術の実装 
PPTX

PDF
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX

PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces 
PPTX
forestFloorパッケージを使ったrandomForestの感度分析 ![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜 
PDF

PDF

PDF
Similar to [DSO]勉強会_データサイエンス講義_Chapter8

PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで 
PDF

PDF

PPT

PDF
ビジネス活用事例で学ぶデータサイエンス入門 #6 
PPTX
20140711 evf2014 hadoop_recommendmachinelearning 
PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V8 
PDF
Jubatus: 分散協調をキーとした大規模リアルタイム機械学習プラットフォーム 
PPTX
Introduction to search_and_recommend_algolithm 
PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V e-1 
PDF
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平 
PDF

PPTX
1028 TECH & BRIDGE MEETING 
PDF
SASによるインメモリ分散並列処理 レコメンドプロシジャ入門 
PDF
QConTokyo2015「Sparkを用いたビッグデータ解析 〜後編〜」 
PDF
「データサイエンティスト・ブーム」後の企業におけるデータ分析者像を探る 
PDF
Markezine day 2012 gdo nakazawa 
PDF

PDF

PDF
Matrix Factorizationを使った評価予測 More from tatsuyasakaeeda
![[DSO]勉強会データサイエンス講義_Chapter10](https://cdn.slidesharecdn.com/ss_thumbnails/dsodatasciencelecturechapter10-191227101558-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DSO]勉強会データサイエンス講義_Chapter10 ![[DSO]勉強会_データサイエンス講義_Chapter9](https://cdn.slidesharecdn.com/ss_thumbnails/dsodatasciencelecturechapter9-191227101324-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DSO]勉強会_データサイエンス講義_Chapter9 ![[DSO]勉強会_データサイエンス講義_Chapter6](https://cdn.slidesharecdn.com/ss_thumbnails/dsodatasciencelecturechapter6-190910041955-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DSO]勉強会_データサイエンス講義_Chapter6 ![[DSO]勉強会_データサイエンス講義_Chapter5](https://cdn.slidesharecdn.com/ss_thumbnails/dsodatasciencelecturechapter5-190828055857-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DSO]勉強会_データサイエンス講義_Chapter5 
PDF
データサイエンス講義 第4章 スパムフィルタ、単純ベイズ、データラングリング ![[DSO]勉強会_データサイエンス講義_Chapter3](https://cdn.slidesharecdn.com/ss_thumbnails/dsodatasciencelecturechapter3-190719101110-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DSO]勉強会_データサイエンス講義_Chapter3 ![[DSO]勉強会_データサイエンス講義_Chapter1,2](https://cdn.slidesharecdn.com/ss_thumbnails/dsodatasciencelecturechapter12-190617122319-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DSO]勉強会_データサイエンス講義_Chapter1,2 [DSO]勉強会_データサイエンス講義_Chapter8
- 1.
- 2.
教科書
2
Rachel Schutt, CathyO‘Neil (2014) 「データサイエンス講義」
(瀬戸山 雅人・石井 弓美子・河内 崇・河内 真理子・古畠 敦・
木下 哲也・竹田 正和・佐藤 正士・望月 啓充 訳)
1章 はじめに:データサイエンスとは
2章 統計的推論、探索的データ分析、データサイエンスのプロセス
3章 アルゴリズム
4章 スパムフィルタ、単純ベイズ、データラングリング
5章 ロジスティック回帰
6章 タイムスタンプと金融モデリング
7章 データから意味を抽出する
8章 レコメンデーションエンジン :ユーザが直接触れる大規模データ製品を構築する
9章 データ可視化と不正検出
10章 ソーシャルネットワークとデータジャーナリズム
11章 因果関係
12章 疫学
13章 データ分析のコンペティションから得られた教訓 :データのリークとモデルの評価
14章 データエンジニアリング :MapReduce、Pregel、Hadoop
15章 生徒たちの声
16章 次世代のデータサイエンティスト、データに対する過信と倫理
- 3.
- 4.
Leverages Marketing Department
●レコメンデーションエンジンとは
● 最近傍法の10個の問題点
○ 次元の呪い
○ オーバーフィッティング
● 機械学習による分類
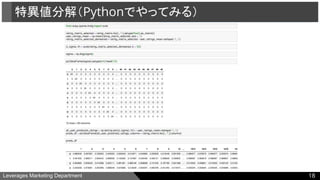
● 行列特異値分解
○ Pythonでやってみる
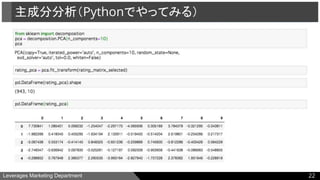
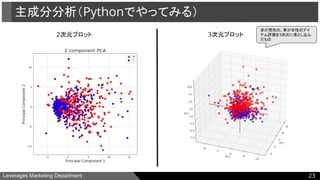
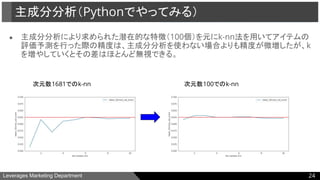
● 主成分分析
○ Pythonでやってみる
● フィルターバブル
● Appendix
● 参考文献
報告内容
4
- 5.
Leverages Marketing Department
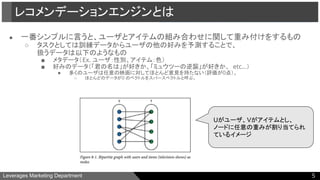
●一番シンプルに言うと、ユーザとアイテムの組み合わせに関して重み付けをするもの
○ タスクとしては訓練データからユーザの他の好みを予測することで、
扱うデータは以下のようなもの
■ メタデータ(Ex. ユーザ:性別、アイテム:色)
■ 好みのデータ(「君の名は」が好きか、「ミュウツーの逆襲」が好きか、 etc...)
● 多くのユーザは任意の映画に対してほとんど意見を持たない(評価が0点)。
○ ほとんどのデータが0 のベクトルをスパースベクトルと呼ぶ。
レコメンデーションエンジンとは
Uがユーザ、Vがアイテムとし、
ノードに任意の重みが割り当てられ
ているイメージ
5
- 6.
Leverages Marketing Department
●最近傍法によるレコメンデーションについて
○ ユーザAの過去の映画評価と最も近い映画の評価をしているユーザBを見つけ、
Aの評価はBの評価と同様であると仮定します。
そして、Aがまだ見ていないが、Bが高く評価している映画をレコメンドに使います。
○ ユーザの評価の近さに関しては様々な指標がある。
■ ジャッカード距離
■ コサイン類似度
■ ユークリッド距離
最近傍法の10個の問題点
6
- 7.
Leverages Marketing Department
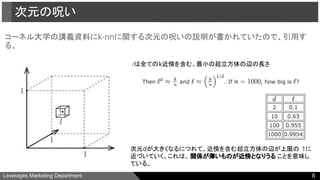
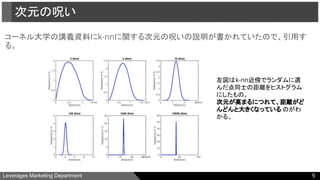
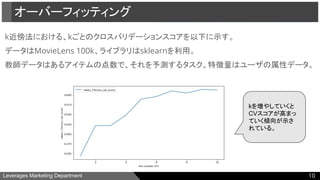
1.次元の呪い:次元が多いとユーザ/アイテム間の距離が遠くなりすぎる
2. オーバーフィッティング:kが小さいと任意の誰かの意見に引きづられ、
精度が出ない
3. 特徴間の相関:同じような変数に別々に重み付け(二重計上)し、
予測パフォーマンスに悪影響を及ぼす
4. 特徴の相対的な重要度:一律で変数を扱うのは良くない
5. スパースの程度:スパースな場合、ジャッカード距離だと意味がなくなる
6. 測定誤差:データが誤っている可能性もある
7. 計算の複雑さ:計算にコストがかかる
8. 距離指標の感度:ユークリッド距離の場合、値の大きさに敏感になる
9. 好みの経時的な変化:ユーザの好みの変化を捉えれない
10. 更新のためのコスト:データを追加した際のコストがかかる
※教科書で特に重要とされている1と2についてのみ深ぼる。
最近傍法の10個の問題点
7
- 8.
- 9.
- 10.
- 11.
Leverages Marketing Department
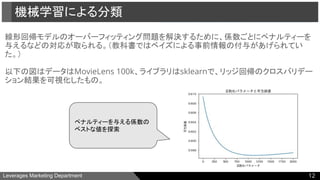
●線形回帰モデルの適用
○ メリット
■ 簡単に係数を推定できる
■ 特徴の重み付けを同時に行える
○ デメリット
■ 完璧なモデルにするには、アイテムの数と同じだけのモデルを用意する必要がある
■ 十分なデータがない場合にオーバーフィッティングが生じうる
(変数の絶対値よりも大きな係数は疑うのが良いとされている。)
機械学習による分類
11
- 12.
- 13.
Leverages Marketing Department
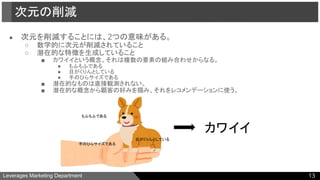
●次元を削減することには、2つの意味がある。
○ 数学的に次元が削減されていること
○ 潜在的な特徴を生成していること
■ カワイイという概念。それは複数の要素の組み合わせからなる。
● もふもふである
● 目がくりんとしている
● 手のひらサイズである
■ 潜在的なものは直接観測されない。
■ 潜在的な概念から顧客の好みを掴み、それをレコメンデーションに使う。
次元の削減
13
もふもふである
目がくりんとしている
手のひらサイズである
カワイイ
- 14.
Leverages Marketing Department
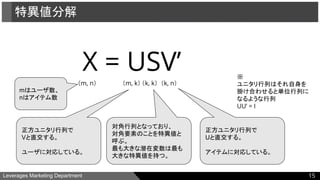
●特異値分解(Singular Value Decomposition, SVD)
特異値分解定理により、
あるm行n列の行列でランク数がk個の行列Xに関して、常に以下のように表すことがで
きる。
特異値分解
14
X = USV’
(m, n) (m, k) (k, k) (k, n)
- 15.
Leverages Marketing Department
特異値分解
15
X= USV’
(m, n) (m, k) (k, k) (k, n)
正方ユニタリ行列で
Vと直交する。
ユーザに対応している。
対角行列となっており、
対角要素のことを特異値と
呼ぶ。
最も大きな潜在変数は最も
大きな特異値を持つ。
正方ユニタリ行列で
Uと直交する。
アイテムに対応している。
mはユーザ数、
nはアイテム数
※
ユニタリ行列はそれ自身を
掛け合わせると単位行列に
なるような行列
UU’ = I
- 16.
Leverages Marketing Department
●列に関して、特異値の降順に並べ替えることで、次元が重要なものからそうでないもの
へと並び替わる。
その上から何個までを保持し、残りを捨てるかはトレーニングパラメータと見なすことがで
きる。
特異値分解
16
X = USV’
(m, n) (m, k) (k, k) (k, n)
- 17.
Leverages Marketing Department
●SVDを求めることができたら、それは同時にXの予測値が手に入ったと考えることもでき
る。値が大きく、まだそのユーザにレコメンドしていないアイテムに関してランク付けの予
測値として使うこともできる。
特異値分解
17
X = USV’
(m, n) (m, k) (k, k) (k, n)
^
- 18.
- 19.
- 20.
Leverages Marketing Department
●主成分分析(Principal Component Analysis, PCA)
以下のように表現できるようなUとVを勾配降下法などで推定する。
(実際のXと、UとVを使って近似したXとの相違を最小化)
※dの数は100個程度が教科書では推奨されている。
主成分分析
20
(m, n) (m, d) (d, n)
- 21.
- 22.
- 23.
- 24.
- 25.
Leverages Marketing Department
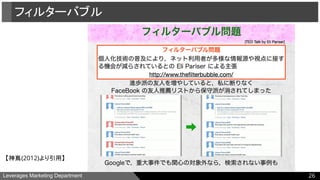
●フィルターバブルとは
神嶌(2012)より引用
“個人化技術の普及により生じたと、Eli Pariser が主張する問題
○ 関心のある話題のみに集中し、多様な話題を知る機会を失う
○ 関心のない話題は、どんなに重大であっても除外される”
フィルターバブルへの対応としては、
”利用者などが指定した、特定の視点に対して、推薦結果ができる
だけ中立性を保つように配慮する推薦システム”
などがあげられている。
フィルターバブル
25
- 26.
- 27.
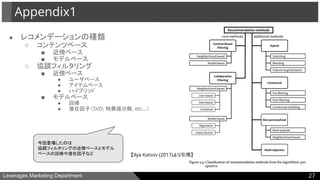
Leverages Marketing Department
●レコメンデーションの種類
○ コンテンツベース
■ 近傍ベース
■ モデルベース
○ 協調フィルタリング
■ 近傍ベース
● ユーザベース
● アイテムベース
● ハイブリッド
■ モデルベース
● 回帰
● 潜在因子(SVD, 特異値分解, etc...)
Appendix1
27
今回登場したのは
協調フィルタリングの近傍ベースとモデル
ベースの回帰や潜在因子など 【Ilya Katsov (2017)より引用】
- 28.
Leverages Marketing Department
●Cold-Start問題
○ 対ユーザ
■ 新たにシステムを利用し始めた利用者に対して適切な推薦をする難しさ
○ 対アイテム
■ 推薦対象として新たにシステムに導入されたアイテムを推薦する難しさ
● Counterfactual【比較的新しいテーマ】
○ Upliftモデリング
■ レコメンドをしなくても購買した可能性がある。
レコメンドをすれば購買してくれるような人にレコメンドできないか。
● 予測精度
○ オフライン評価
■ 過去のデータをもとに推薦結果の評価を行う。一般の機械学習と同様に、交差確認によって汎化誤
差を推定し、その汎化誤差で予測精度を評価
○ オンライン評価
■ 被験者に実際にシステムを利用させ、推薦が適合したかどうかを調査するもの。
Appendix2
28
- 29.
Leverages Marketing Department
[1]Machine Learning for Intelligent Systems, "Lecture 2: k-nearest neighbors"
[2] Julian Avila ,Trent Hauck (2019), 『Python機械学習ライブラリ scikit-learn活用レシピ
80+』, インプレス
[3] Nick Becker (2016), "Matrix Factorization for Movie Recommendations in
Python"
[4] 神嶌・赤穂・麻生・佐久間 (2012) , "情報中立推薦システム"
[5] Ilya Katsov (2017) , "Introduction to Algorithmic Marketing: Artificial Intelligence
for Marketing Operations"
[6] 神嶌 (2016) , "推薦システムのアルゴリズム"
[7] Sato et al. (2019) , "Uplift-based Evaluation and Optimization of
Recommenders", RecSys2019
参考文献
29















![Leverages Marketing Department
[1] Machine Learning for Intelligent Systems, "Lecture 2: k-nearest neighbors"
[2] Julian Avila ,Trent Hauck (2019), 『Python機械学習ライブラリ scikit-learn活用レシピ
80+』, インプレス
[3] Nick Becker (2016), "Matrix Factorization for Movie Recommendations in
Python"
[4] 神嶌・赤穂・麻生・佐久間 (2012) , "情報中立推薦システム"
[5] Ilya Katsov (2017) , "Introduction to Algorithmic Marketing: Artificial Intelligence
for Marketing Operations"
[6] 神嶌 (2016) , "推薦システムのアルゴリズム"
[7] Sato et al. (2019) , "Uplift-based Evaluation and Optimization of
Recommenders", RecSys2019
参考文献
29](https://image.slidesharecdn.com/data-science-lecture-chapter8-ver2-191018120312/85/DSO-_-_Chapter8-29-320.jpg)