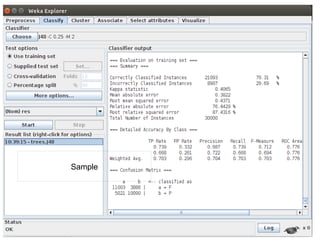
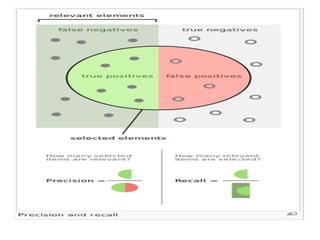
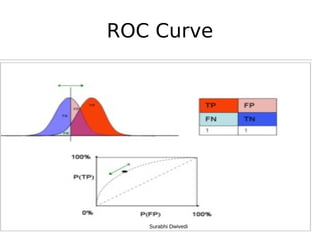
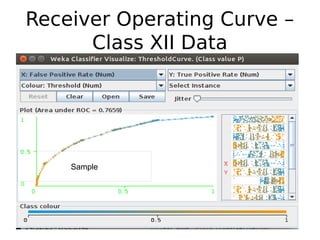
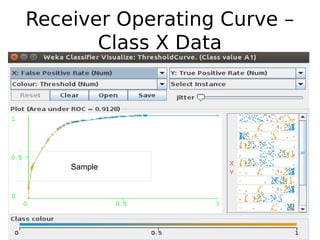
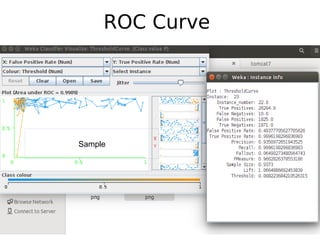
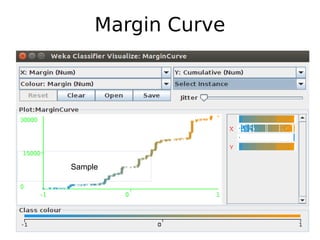
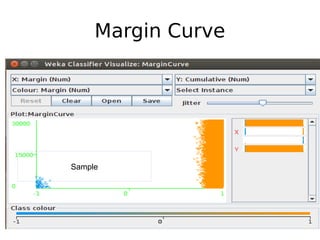
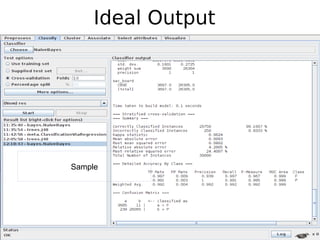
The document discusses key statistical terms for model classification in Weka, including confusion matrix, precision, recall, f-measure, kappa statistics, and ROC curve. It explains concepts such as how precision and recall measure the performance of algorithms and details the kappa statistic for assessing classification agreement. Additionally, the document describes test options for classifiers, emphasizing the importance of evaluating model performance through various statistical metrics.