Downloaded 37 times










































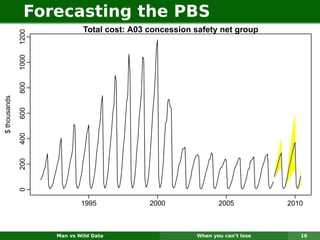
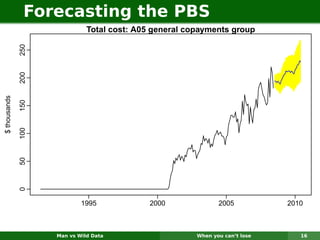
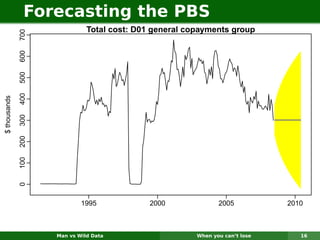
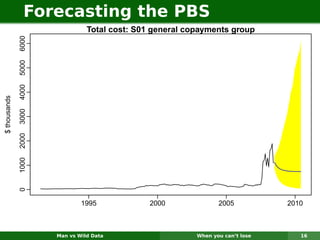
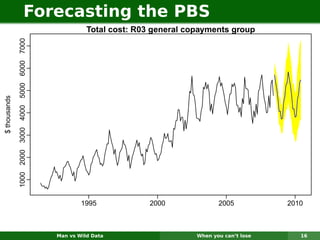



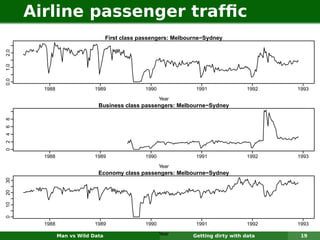
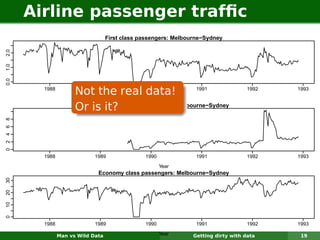
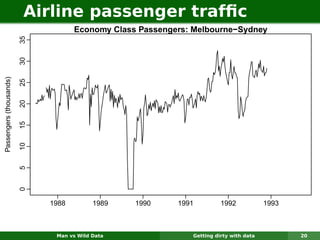
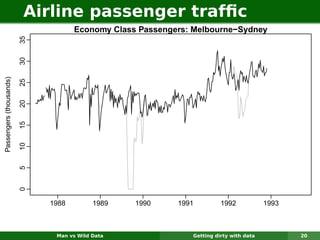
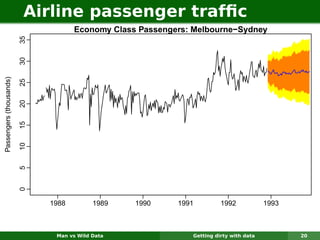











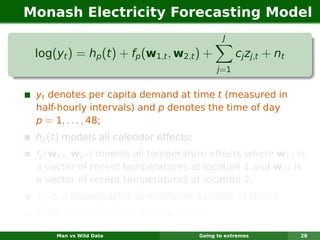

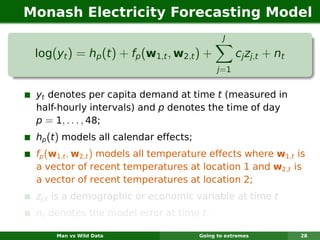
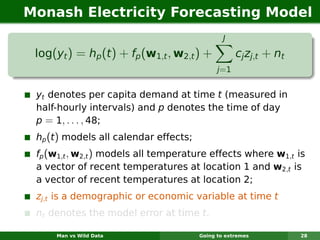







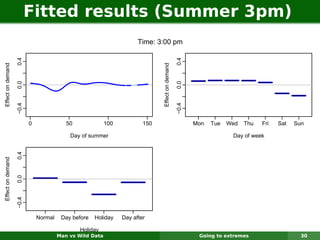







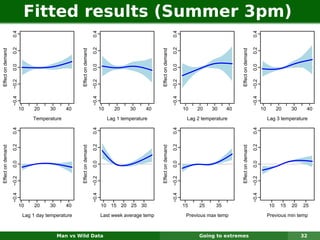




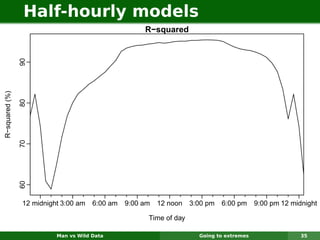
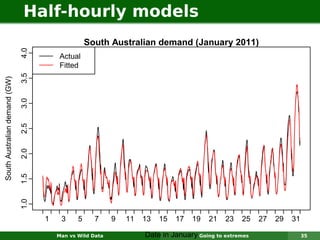
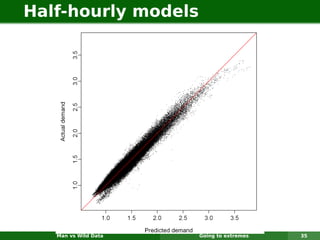
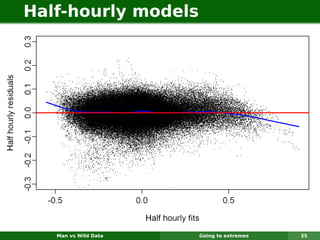




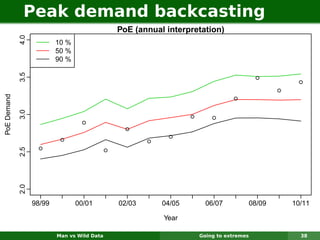
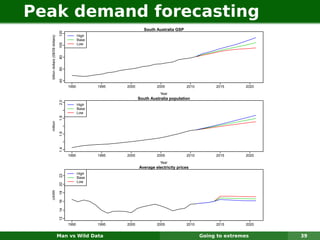
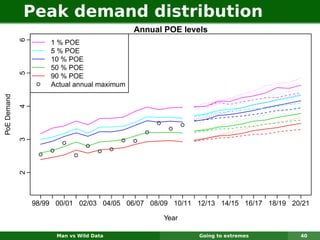














The document describes forecasting expenditures for Australia's Pharmaceutical Benefits Scheme (PBS). PBS forecasts billions in drug subsidies annually using simple Excel methods. The author developed an automated exponential smoothing algorithm in Excel, reducing forecast errors from 15-20% to 0.6%. Monthly data on thousands of drug groups was used to automatically select exponential smoothing models based on AIC.































![Production & Operation Management Chapter8[1]](https://cdn.slidesharecdn.com/ss_thumbnails/chapter81-140613051436-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![Chapter8[1]](https://cdn.slidesharecdn.com/ss_thumbnails/chapter81-140613050936-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)