Downloaded 90 times



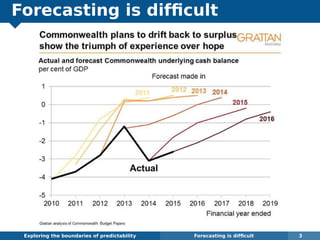









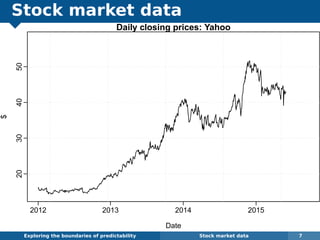
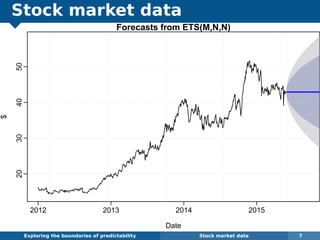
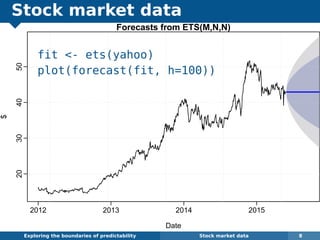
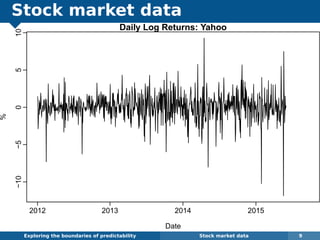
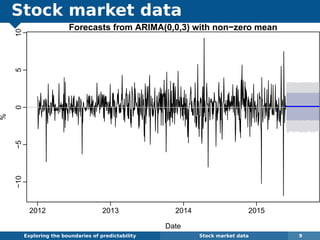
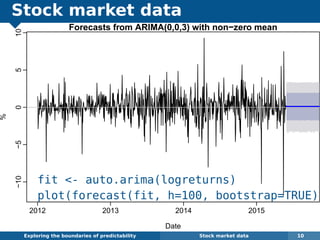
















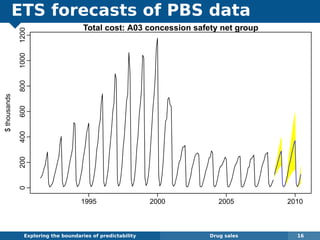
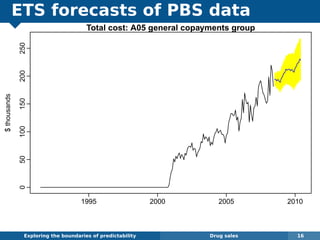
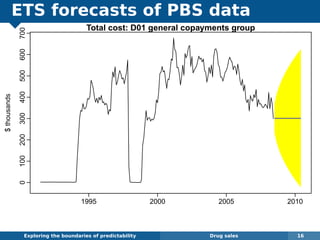
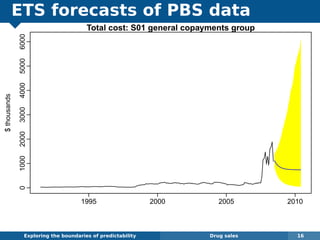
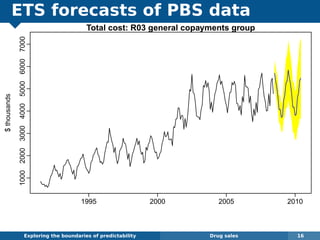








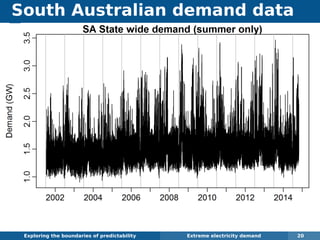
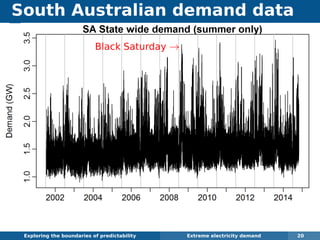

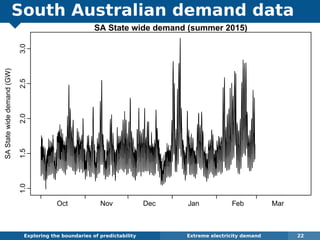
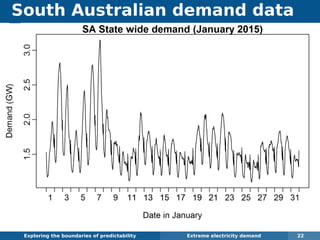
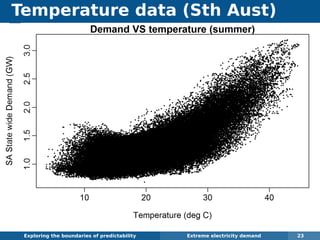



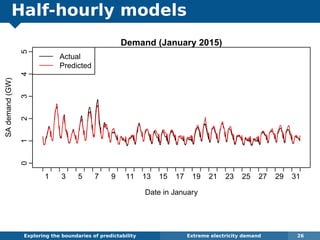
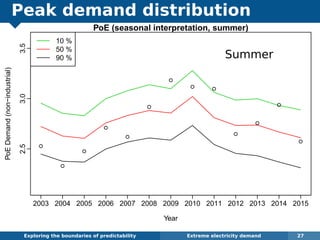




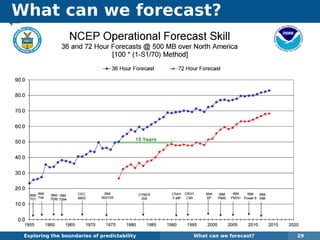




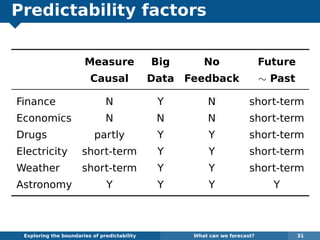







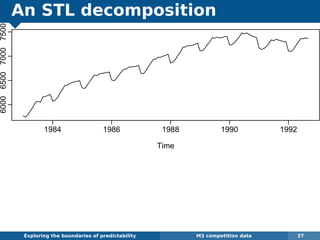
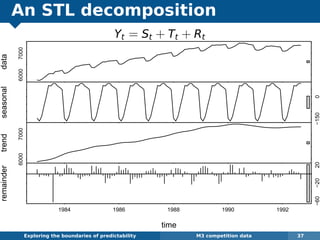







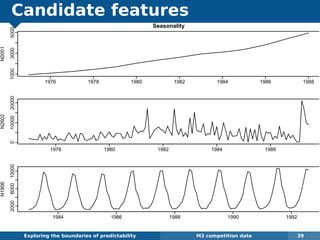
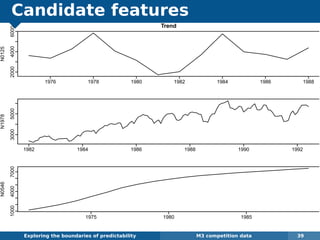
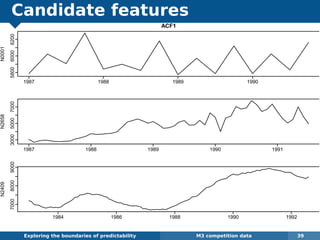
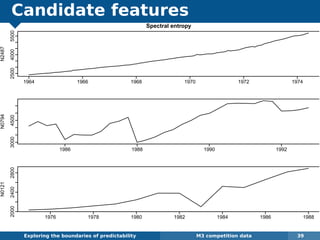
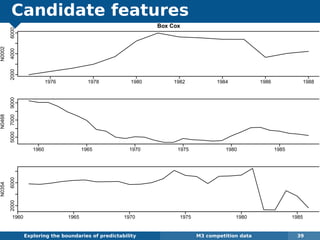

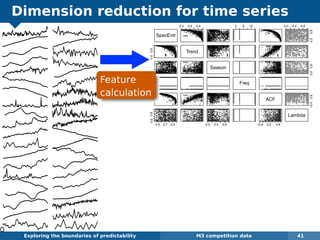
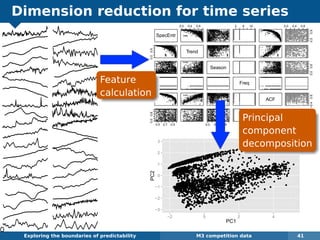
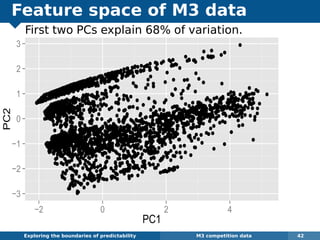
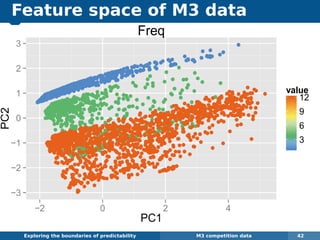
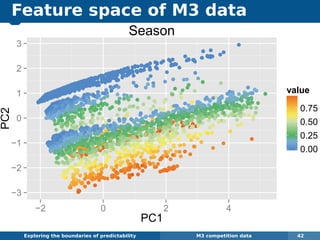
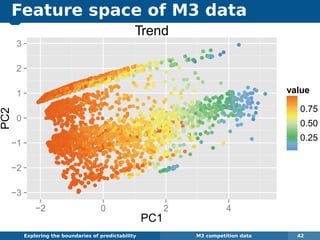
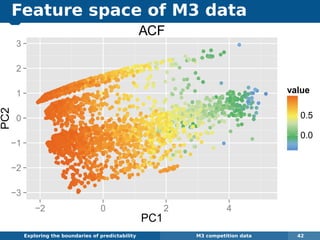
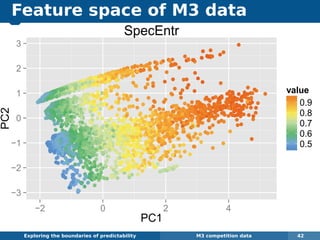
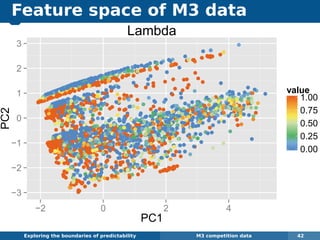
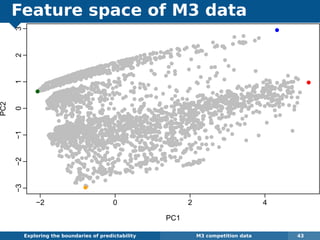
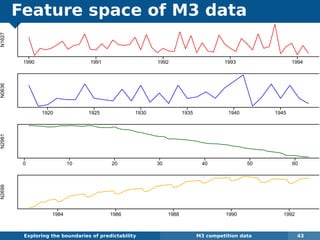
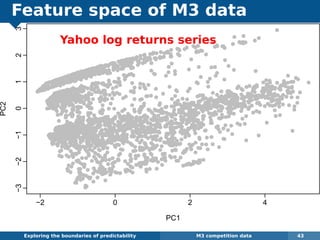
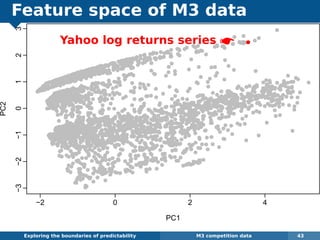
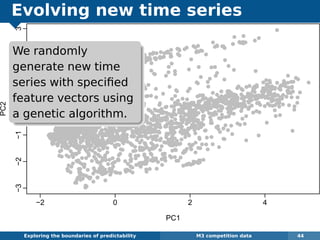
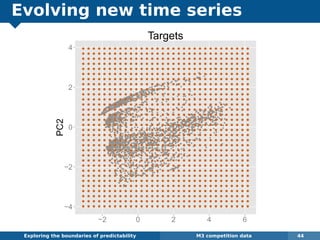
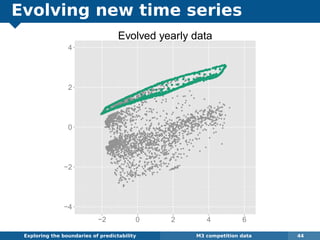
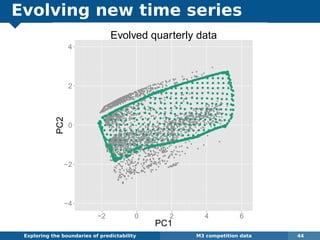
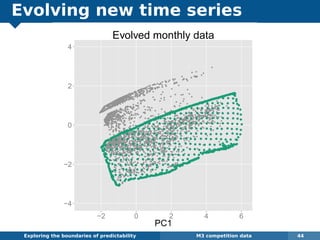


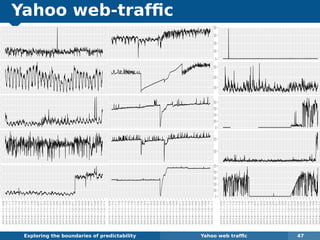

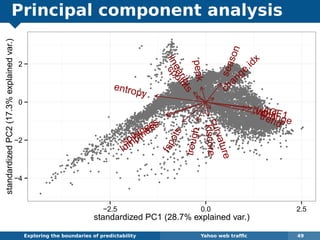
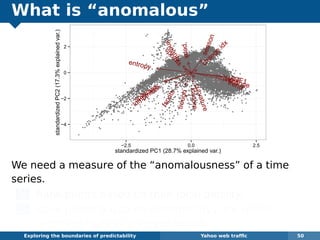
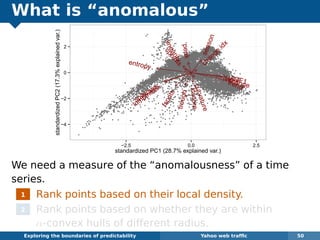





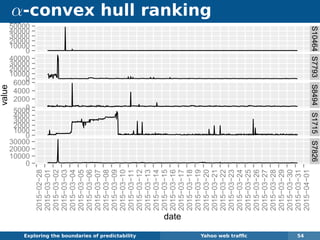
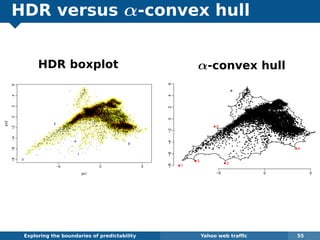
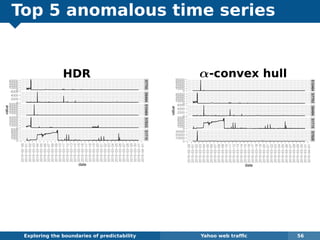










The document explores the challenges and methodologies of forecasting in various contexts, highlighting the inherent difficulties and limitations of predictive models. It examines specific case studies, including stock market trends, drug sales under the Australian Pharmaceutical Benefits Scheme, and peak electricity demand predictions in South Australia. The discussion emphasizes the need for robust forecasting models that account for volatility and changing environments while noting advancements in forecasting techniques, such as exponential smoothing state space models.