Downloaded 10 times











![SYSTEM AVAILABILITY DEFINED
• Availability of the entire
system:
n m
Asys = 1 – P(1-Pri)j
i=1 j=1 V
I
P
• Number of Parallel
Components Needed to
Parallel
Achieve Availability Amin:
Serial
Nmin =
[ln(1-Amin)/ln(1-r)]
Confidential and Proprietary](https://image.slidesharecdn.com/yessql08-inmemorydb-120412154310-phpapp02/85/Yes-sql08-inmemorydb-14-320.jpg)






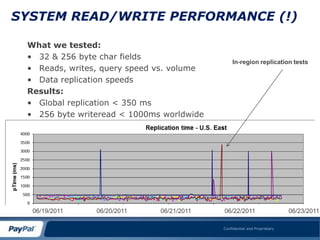
![The Commit Ordering Problem
• Why does commit ordering matter?
• Write operators are non-commutative
[W(d,t1),W(d,t2)] != 0 unless t1=t2
– Can lead to inconsistency
– Can lead to timestamp corruption
– Forcing sequential writes defeats Amdahl‟s
rule
• Can show up in GSLB scenarios
Confidential and Proprietary](https://image.slidesharecdn.com/yessql08-inmemorydb-120412154310-phpapp02/85/Yes-sql08-inmemorydb-23-320.jpg)





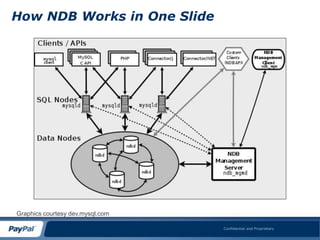
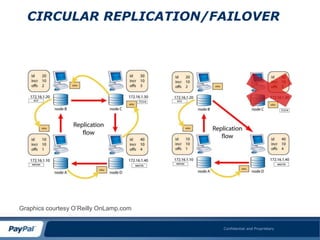
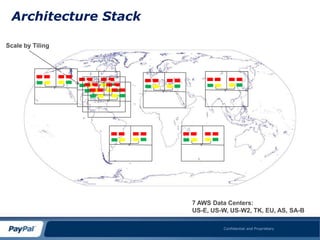
This document summarizes a presentation about using MySQL and the NDB storage engine to build a globally distributed in-memory database system on AWS. It proposes using MySQL/NDB clusters tiled across AWS availability zones to provide high availability and performance at a large scale. Key challenges discussed include managing data consistency across wide geographical distances and dealing with limitations of AWS like network performance and lack of global load balancing. Lessons learned are that NDB can successfully compete with NoSQL for most use cases by providing ACID compliance without sacrificing availability or performance.























































































