Download as PDF, PPTX





![What are multi-armed bandits?
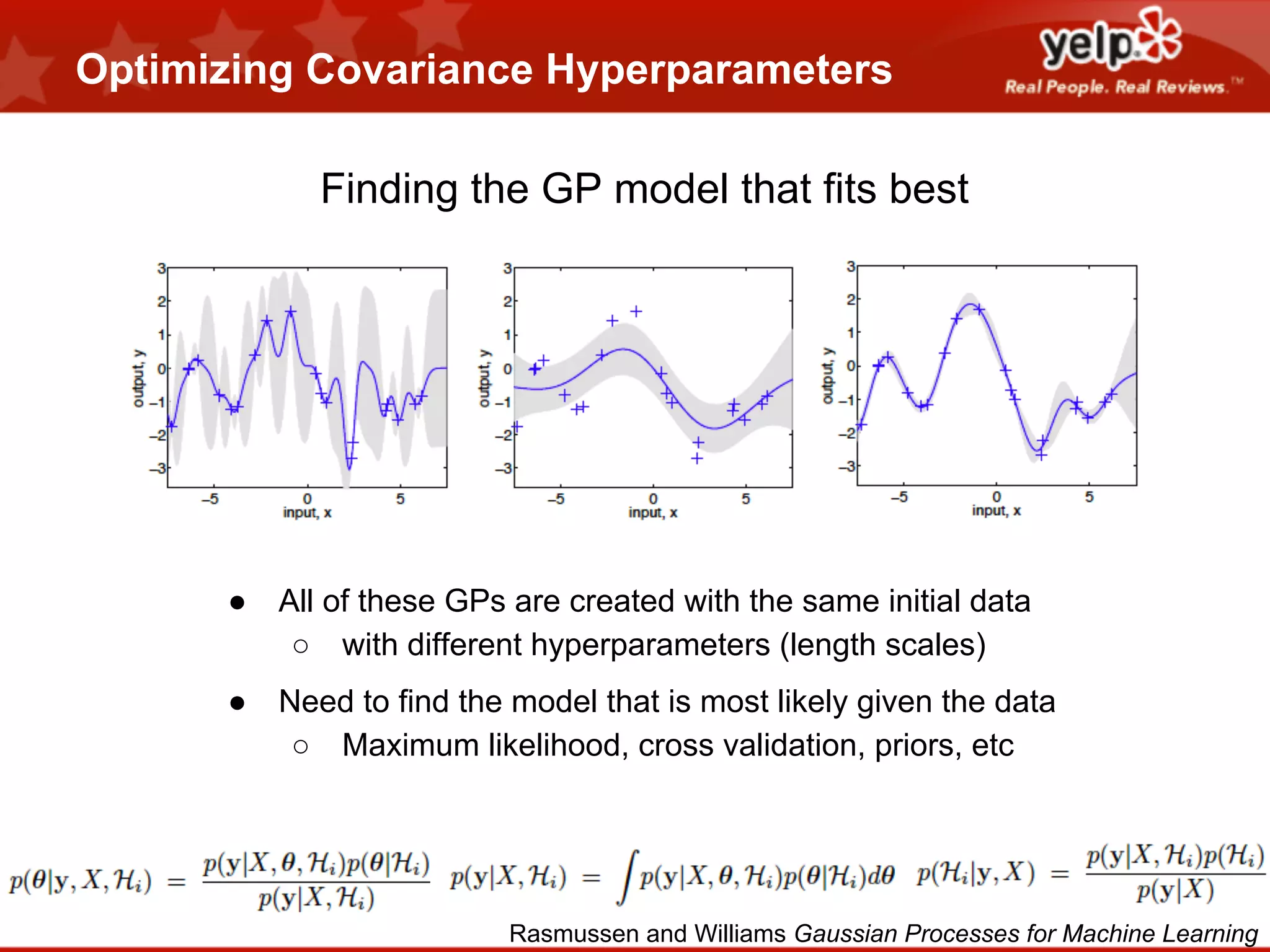
THE SETUP
(math version)
[Robbins 1952]](https://image.slidesharecdn.com/yelpopenhouse-optimallylearningforfunandprofit-131205154843-phpapp02/75/Optimal-Learning-for-Fun-and-Profit-by-Scott-Clark-Presented-at-The-Yelp-Engineering-Open-House-11-20-13-6-2048.jpg)



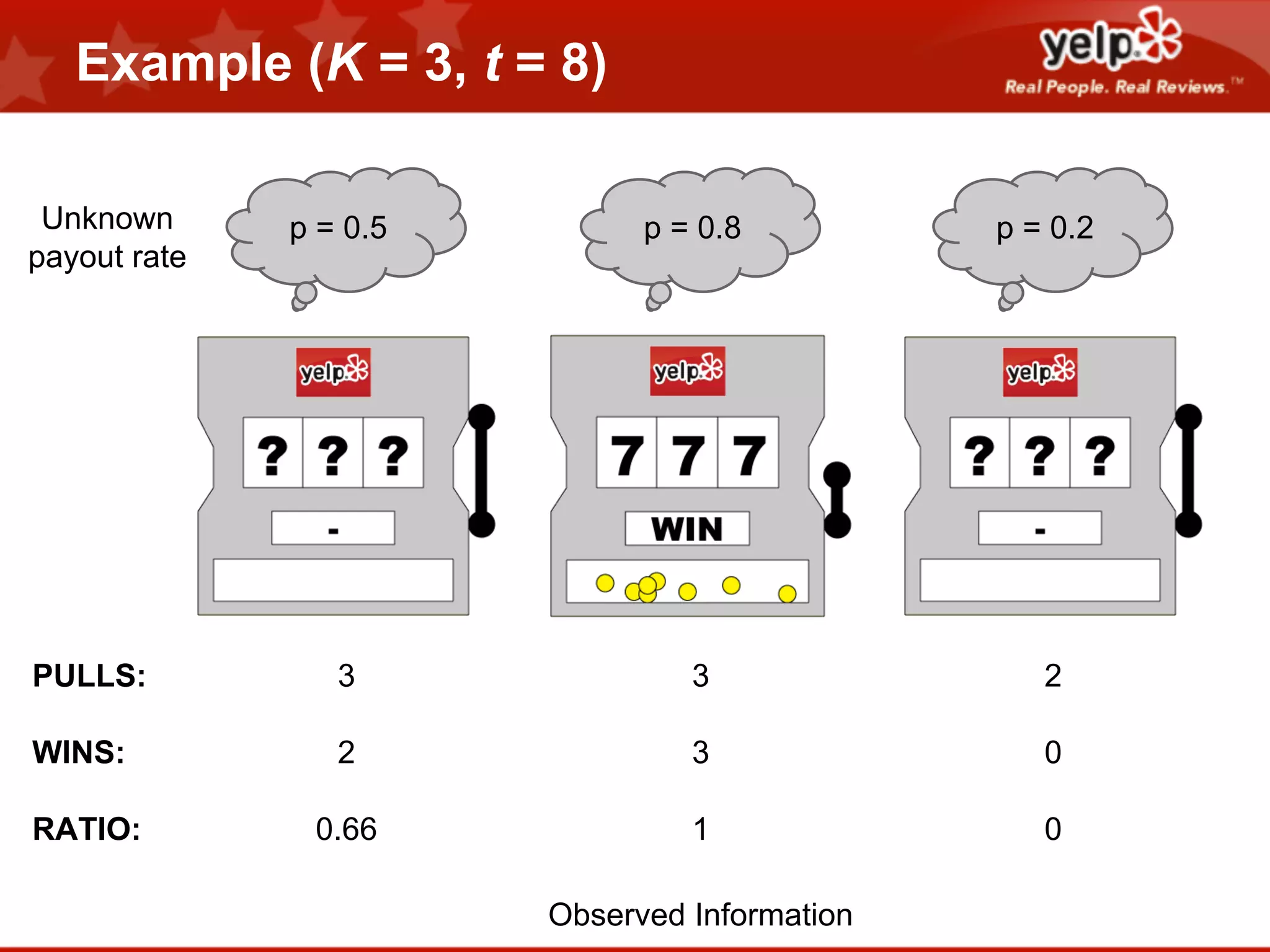
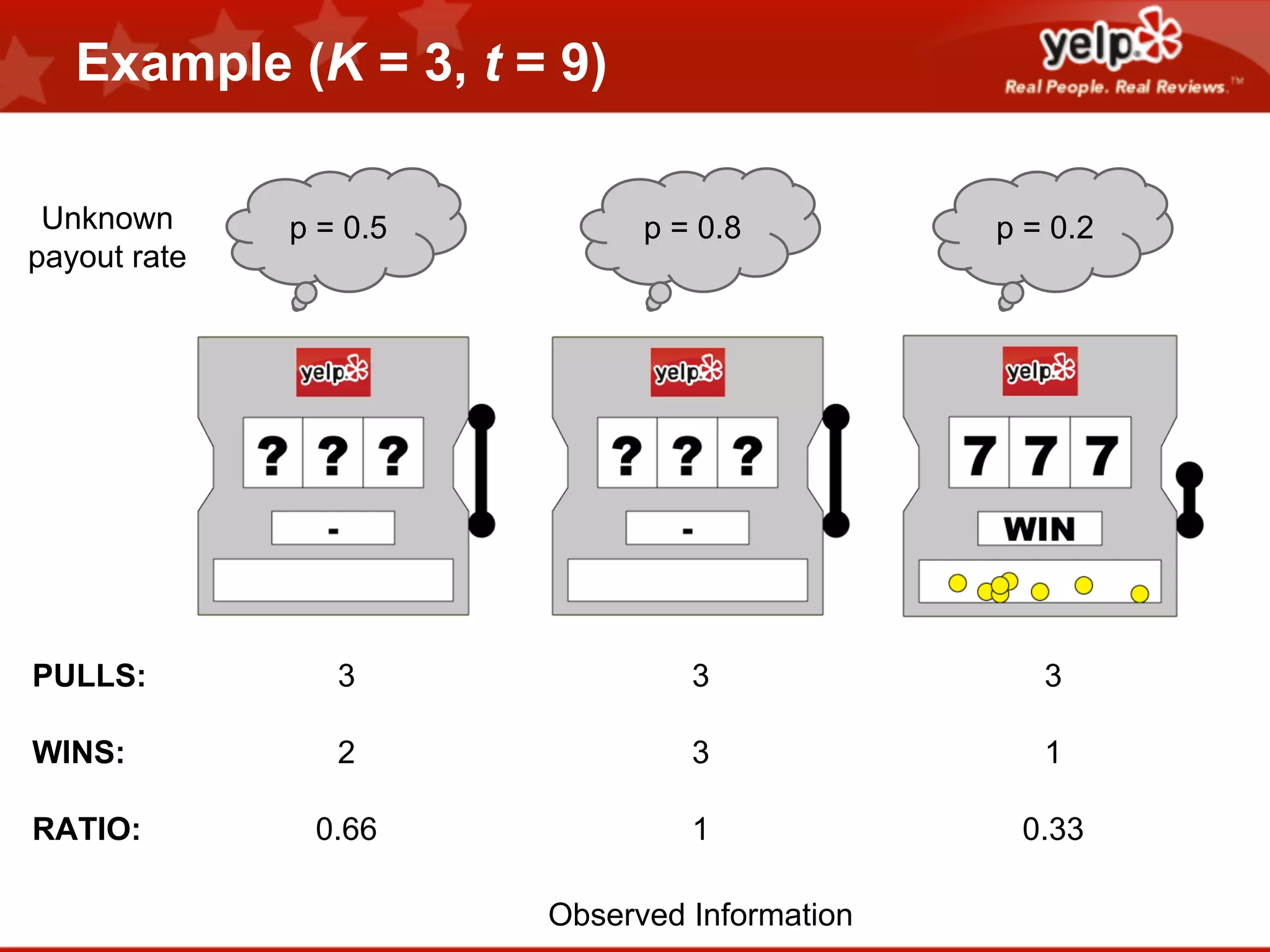












![Find point(s) of highest expected improvement
Expected Improvement of sampling two points
We want to find the point(s) that are expected to beat the best point seen so far the most.
[Jones, Schonlau, Welsch 1998]
[Clark, Frazier 2012]](https://image.slidesharecdn.com/yelpopenhouse-optimallylearningforfunandprofit-131205154843-phpapp02/75/Optimal-Learning-for-Fun-and-Profit-by-Scott-Clark-Presented-at-The-Yelp-Engineering-Open-House-11-20-13-35-2048.jpg)



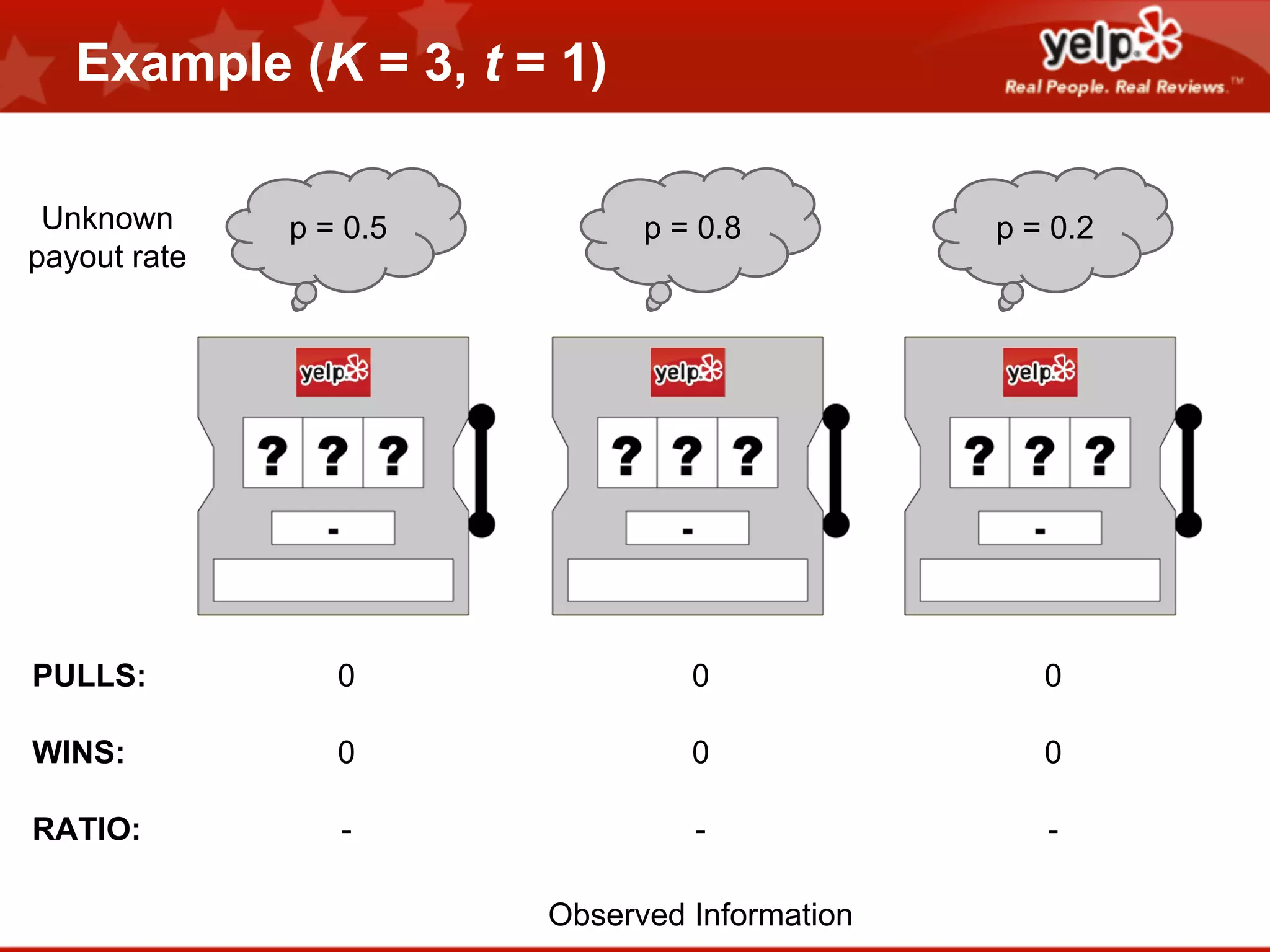
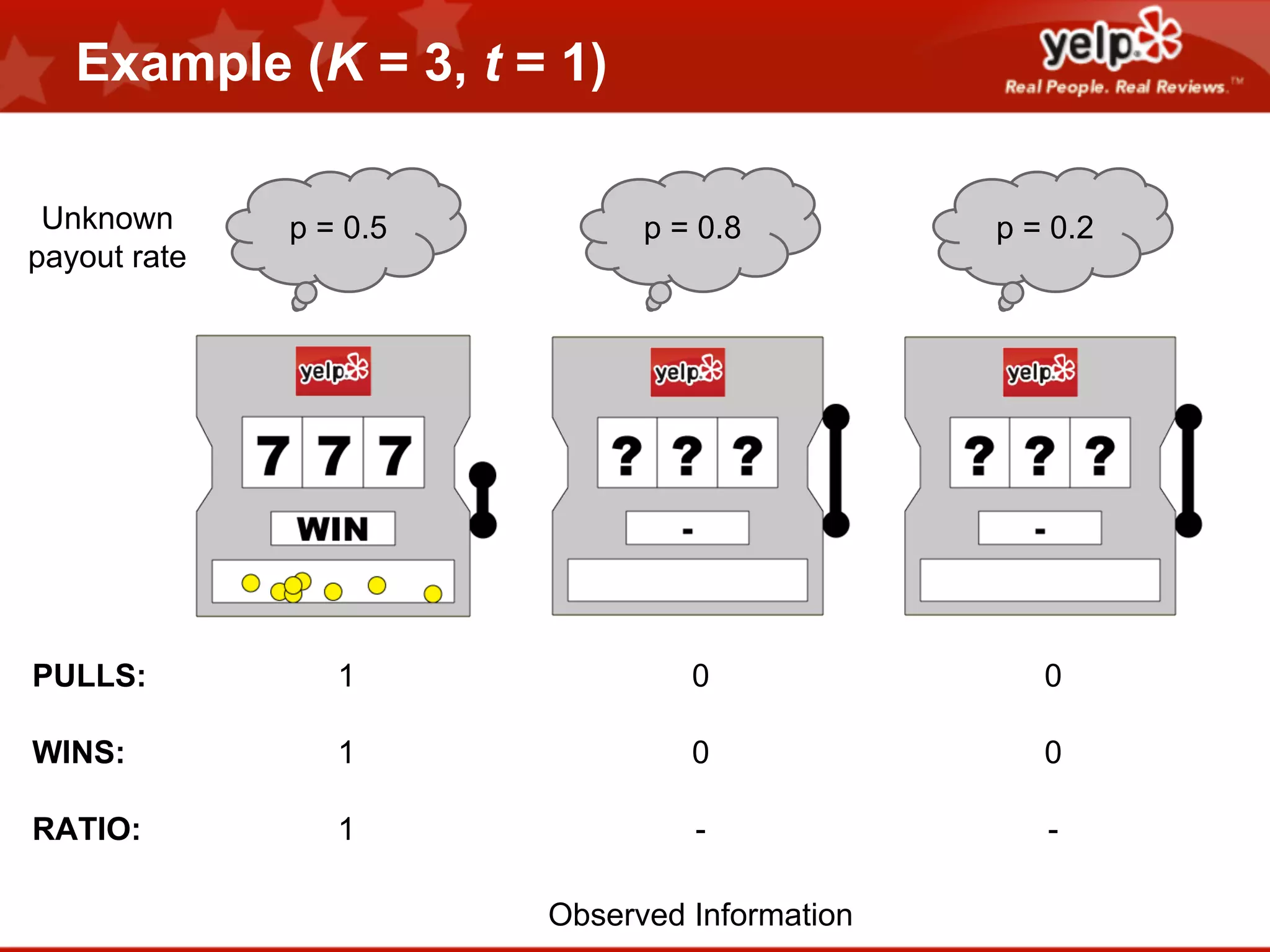
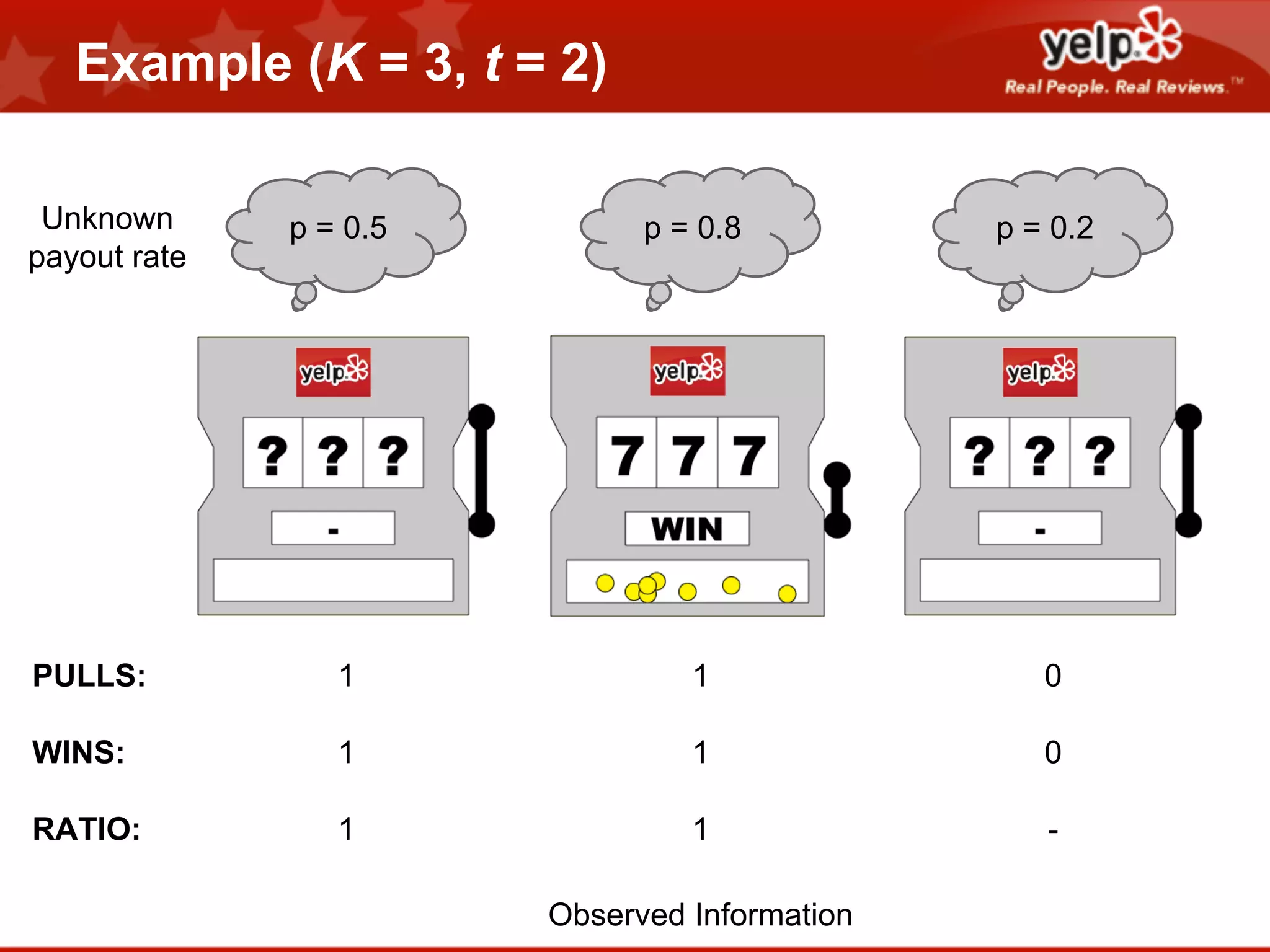
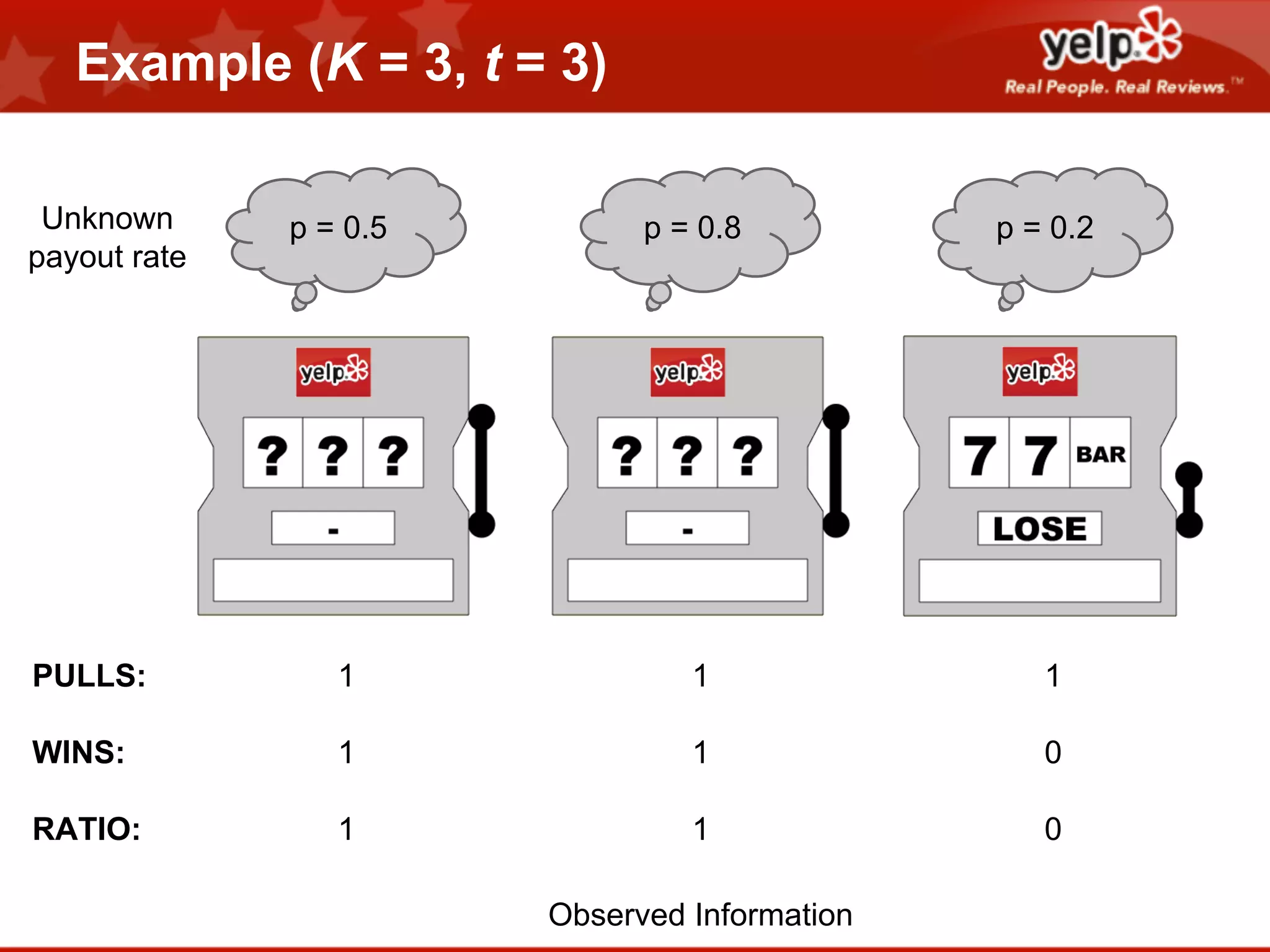
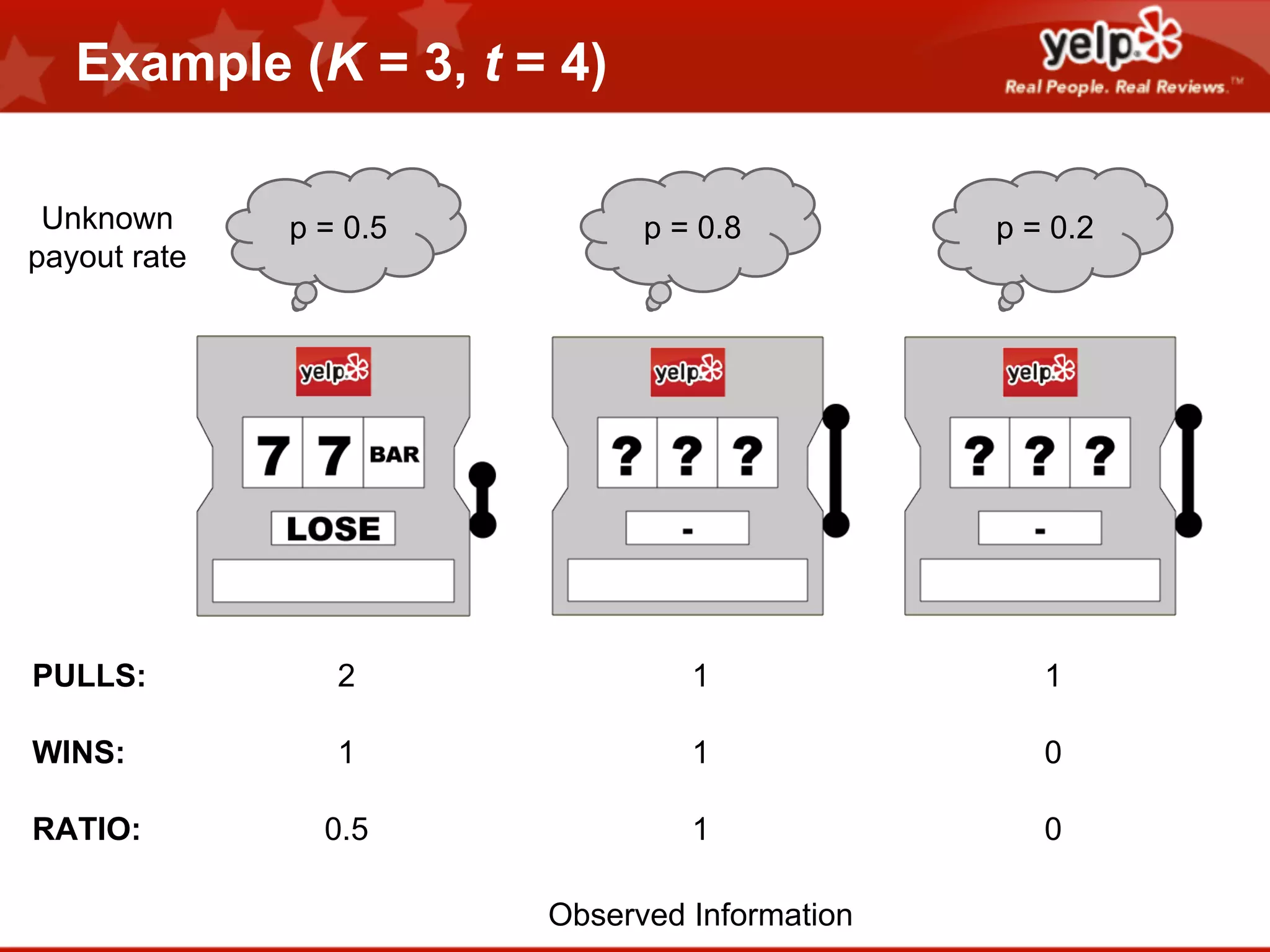
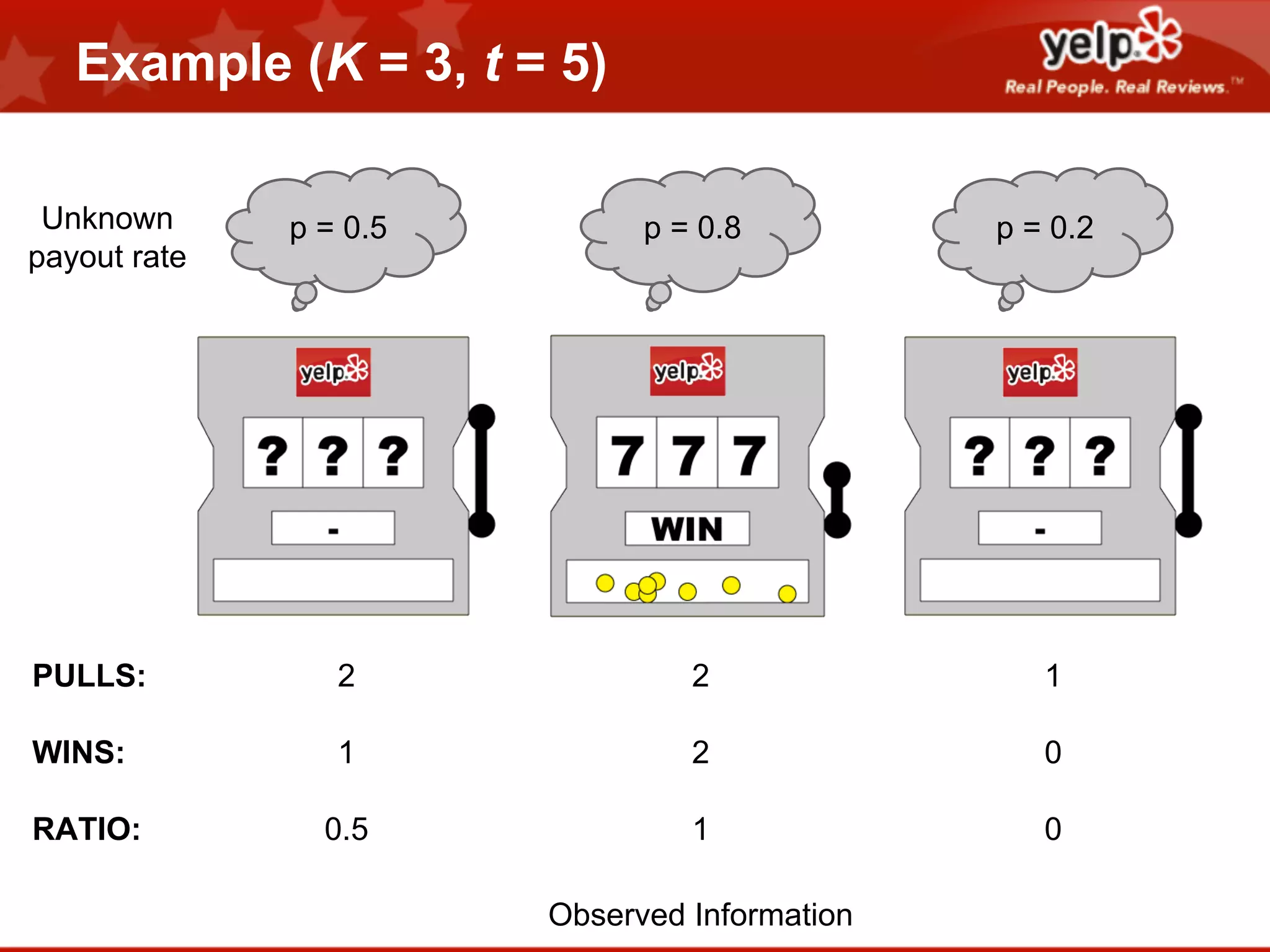
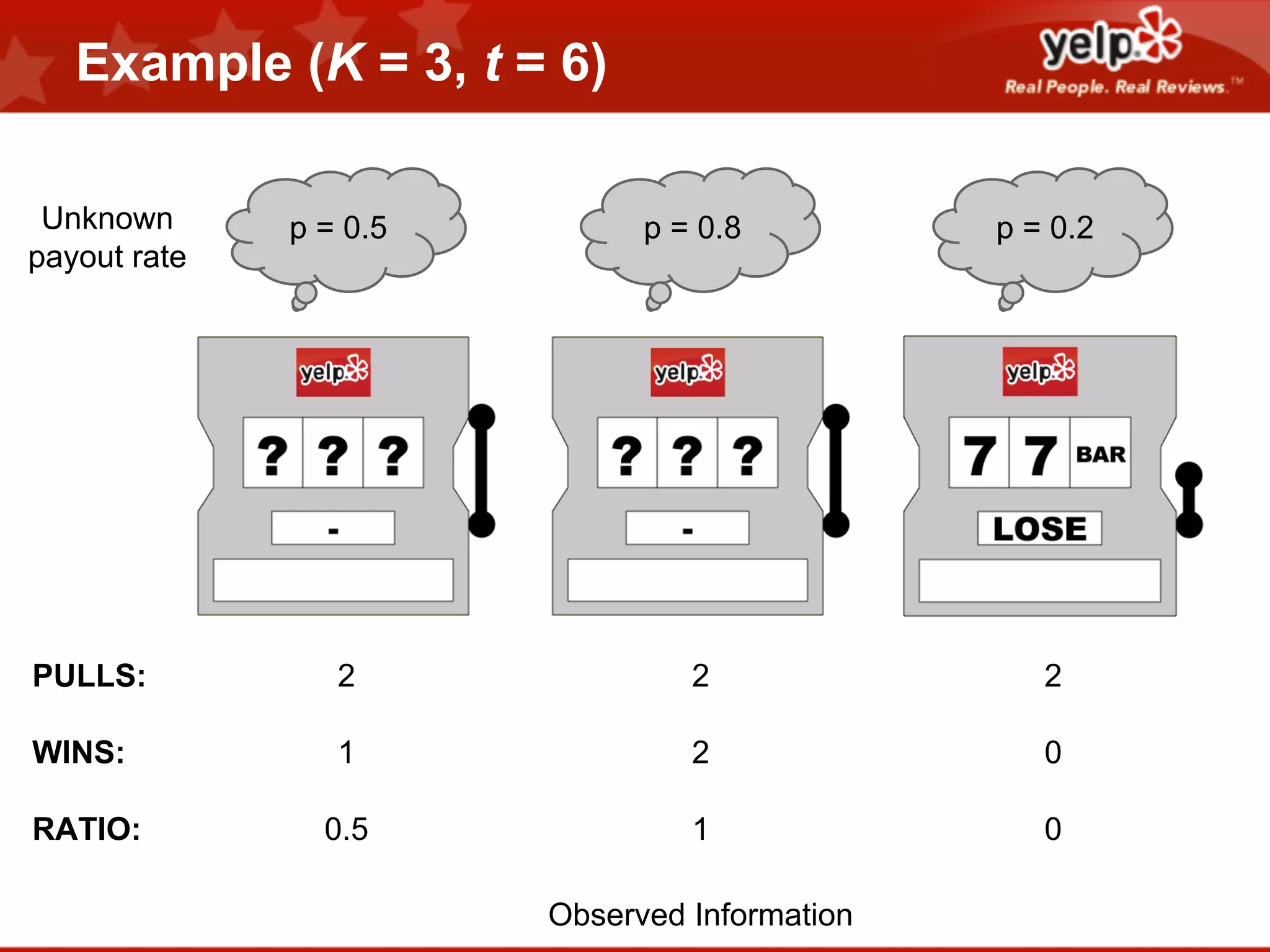
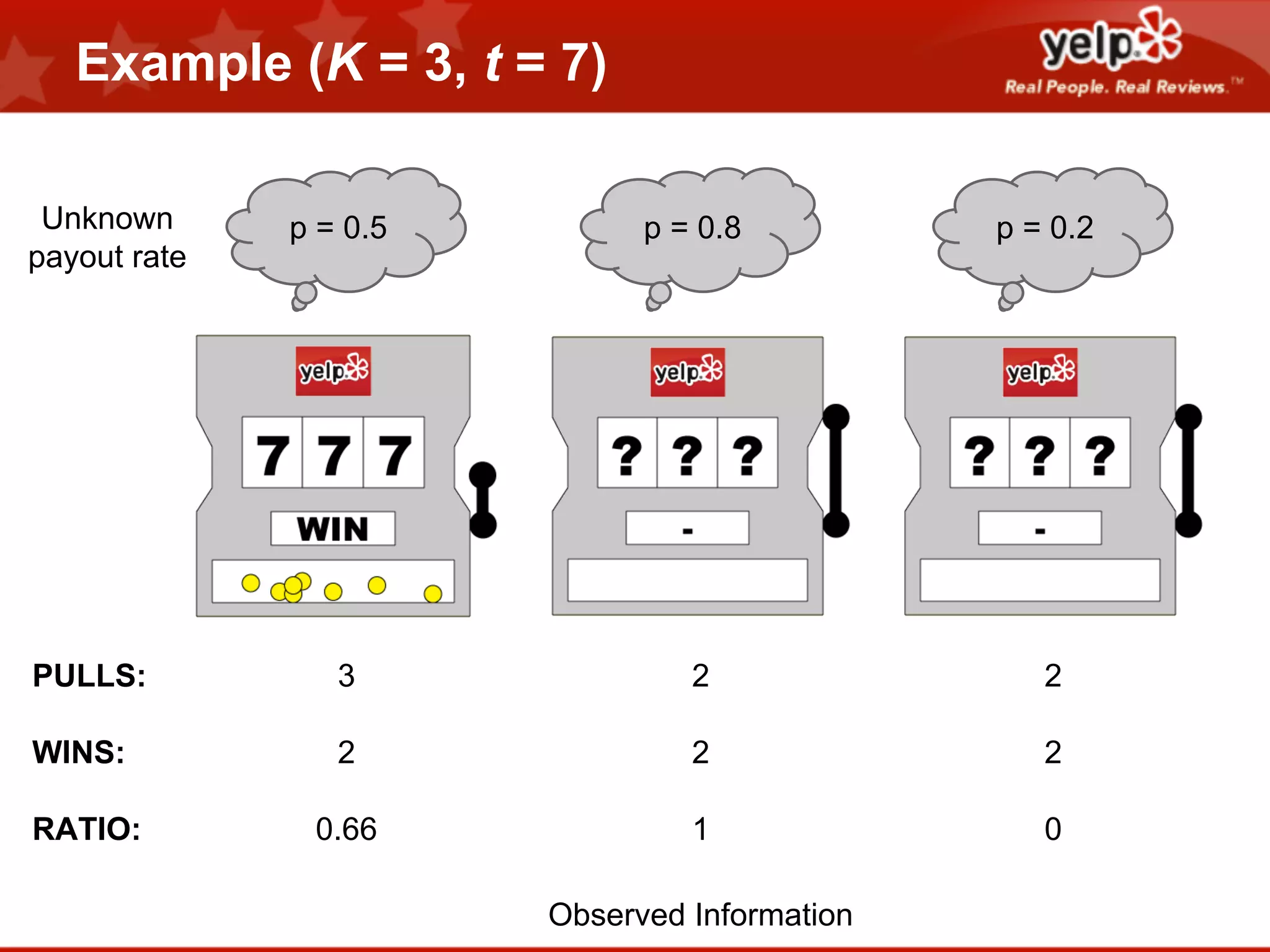
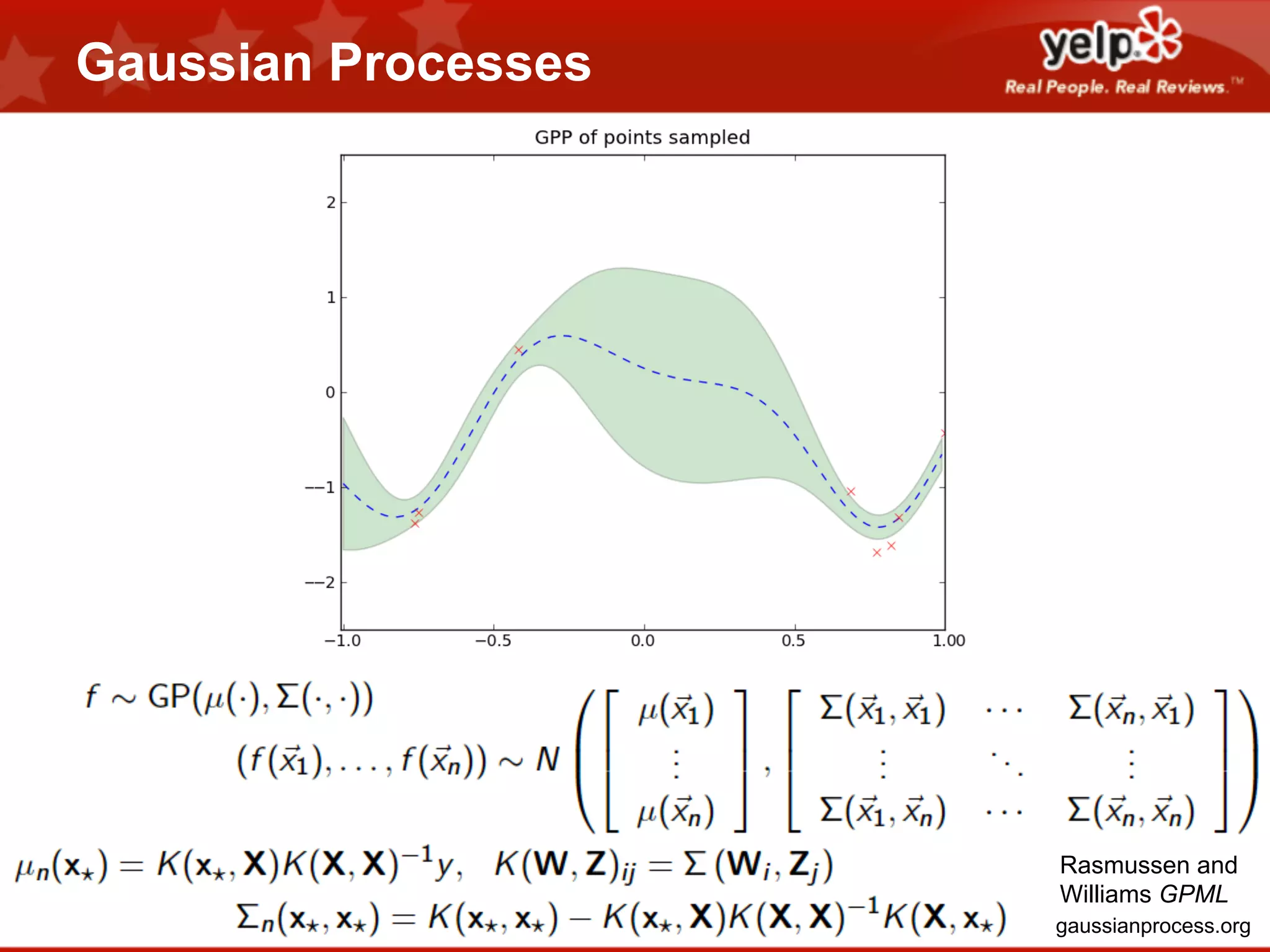
Scott Clark gave a presentation on optimal learning techniques. He discussed multi-armed bandits, which address the challenge of collecting information efficiently from multiple options with unknown outcomes. He provided an example of exploring various slot machines to maximize rewards. Clark also discussed Bayesian global optimization and Yelp's Metrics Optimization Engine (MOE), which uses Gaussian processes to suggest optimal parameters for A/B tests based on past experiment results, in order to efficiently optimize metrics. MOE is now being used in Yelp's live experiments to continuously improve performance.




































































