Download to read offline




























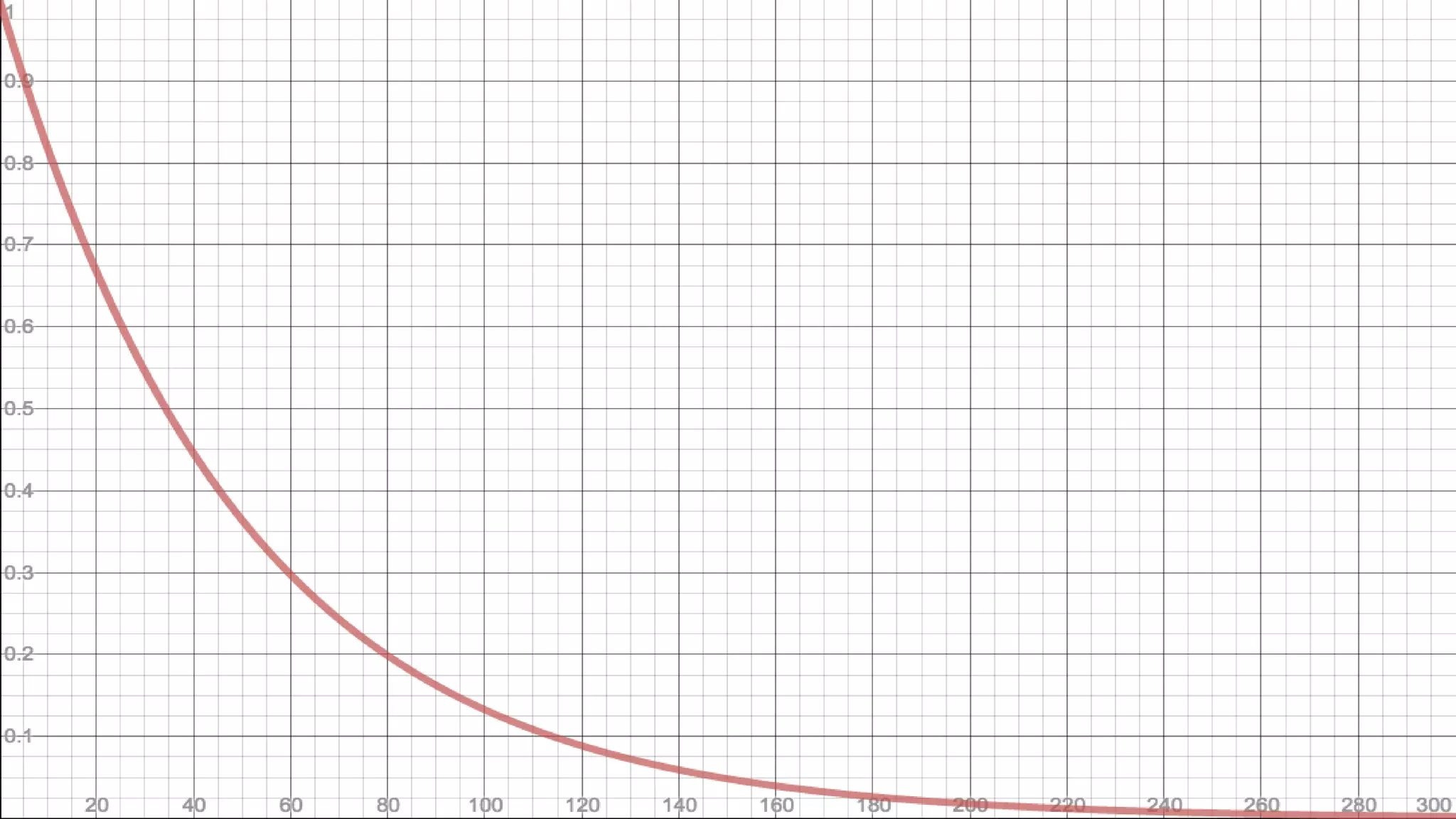
















































1) The document discusses how human fallibility and increased development teams can lead to an exponential decay in the probability of successful deployments over time as the number of changes increases. 2) It recommends approaches like implementing a service-oriented architecture, focusing on mean time to recovery rather than just preventing failures, and establishing "DevOps deputies" to help mitigate this problem. 3) The key message is that organizations should embrace DevOps culture, tailor their approaches to their specific teams, plan for inevitable changes over time, and view components as distributed from the beginning.






























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

















