Download to read offline













![13
xenctx
▌Turns out, a stack profiler for Xen already exists
Well, kinda
▌xenctx is bundled with Xen
Introspection tool
Option to print call stack
$ xenctx -f -s <symbol table file> <DOMID>
[...]
Call Trace:
[<0000000000004868>] three+0x58 <--
00000000000ffea0: [<00000000000044f2>] two+0x52
00000000000ffef0: [<00000000000046a6>] one+0x12
00000000000fff40: [<000000000002ff66>]
00000000000fff80: [<0000000000012018>] call_main+0x278](https://image.slidesharecdn.com/xpdds17uniprof-transparentunikernelperformanceprofilinganddebugging-florianschmidtnec-170804150202/85/XPDDS17-uniprof-Transparent-Unikernel-Performance-Profiling-and-Debugging-Florian-Schmidt-NEC-13-320.jpg)
![14
xenctx
▌Turns out, a stack profiler for Xen already exists
Well, kinda
▌xenctx is bundled with Xen
Introspection tool
Option to print call stack
▌So if we run this over and over, we have a stack profiler
Well, kinda
$ xenctx -f -s <symbol table file> <DOMID>
[...]
Call Trace:
[<0000000000004868>] three+0x58 <--
00000000000ffea0: [<00000000000044f2>] two+0x52
00000000000ffef0: [<00000000000046a6>] one+0x12
00000000000fff40: [<000000000002ff66>]
00000000000fff80: [<0000000000012018>] call_main+0x278](https://image.slidesharecdn.com/xpdds17uniprof-transparentunikernelperformanceprofilinganddebugging-florianschmidtnec-170804150202/85/XPDDS17-uniprof-Transparent-Unikernel-Performance-Profiling-and-Debugging-Florian-Schmidt-NEC-14-320.jpg)









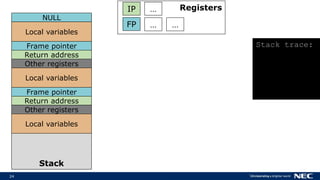
![25
Stack
Local variables
RegistersIP
FP
function three() {
[…]
}
…
… …
Frame pointer
NULL
Return address
Other registers
Local variables
Frame pointer
Return address
Other registers
Local variables
Stack trace:](https://image.slidesharecdn.com/xpdds17uniprof-transparentunikernelperformanceprofilinganddebugging-florianschmidtnec-170804150202/85/XPDDS17-uniprof-Transparent-Unikernel-Performance-Profiling-and-Debugging-Florian-Schmidt-NEC-25-320.jpg)
![26
Stack
Local variables
RegistersIP
FP
function three() {
[…]
}
…
… …
Frame pointer
NULL
Return address
Other registers
Local variables
Frame pointer
Return address
Other registers
Local variables
Stack trace:
three +0xcaIP](https://image.slidesharecdn.com/xpdds17uniprof-transparentunikernelperformanceprofilinganddebugging-florianschmidtnec-170804150202/85/XPDDS17-uniprof-Transparent-Unikernel-Performance-Profiling-and-Debugging-Florian-Schmidt-NEC-26-320.jpg)
![27
Stack
Local variables
RegistersIP
FP
function three() {
[…]
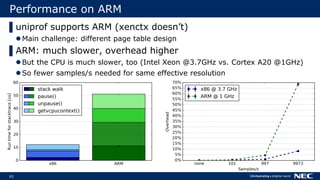
}
…
… …
Frame pointer
NULL
Return address
Other registers
Local variables
Frame pointer
Return address
Other registers
Local variables
Stack trace:
three +0xcaIP](https://image.slidesharecdn.com/xpdds17uniprof-transparentunikernelperformanceprofilinganddebugging-florianschmidtnec-170804150202/85/XPDDS17-uniprof-Transparent-Unikernel-Performance-Profiling-and-Debugging-Florian-Schmidt-NEC-27-320.jpg)
![28
Stack
Local variables
RegistersIP
FP
function two() {
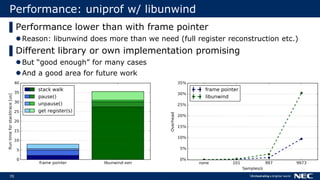
[…]
three();
}
function three() {
[…]
}
…
… …
Frame pointer
NULL
Return address
Other registers
Local variables
Frame pointer
Return address
Other registers
Local variables
Stack trace:
three +0xcaIP](https://image.slidesharecdn.com/xpdds17uniprof-transparentunikernelperformanceprofilinganddebugging-florianschmidtnec-170804150202/85/XPDDS17-uniprof-Transparent-Unikernel-Performance-Profiling-and-Debugging-Florian-Schmidt-NEC-28-320.jpg)
![29
Stack
Local variables
RegistersIP
FP
function two() {
[…]
three();
}
function three() {
[…]
}
…
… …
Frame pointer
NULL
Return address
Other registers
Local variables
Frame pointer
Return address
Other registers
Local variables
Stack trace:
three +0xca
two +0xc1
IP
FP+1word](https://image.slidesharecdn.com/xpdds17uniprof-transparentunikernelperformanceprofilinganddebugging-florianschmidtnec-170804150202/85/XPDDS17-uniprof-Transparent-Unikernel-Performance-Profiling-and-Debugging-Florian-Schmidt-NEC-29-320.jpg)
![30
Stack
Local variables
RegistersIP
FP
function one() {
[…]
two();
[…]
}
function two() {
[…]
three();
}
function three() {
[…]
}
…
… …
Frame pointer
NULL
Return address
Other registers
Local variables
Frame pointer
Return address
Other registers
Local variables
Stack trace:
three +0xca
two +0xc1
IP
FP+1word](https://image.slidesharecdn.com/xpdds17uniprof-transparentunikernelperformanceprofilinganddebugging-florianschmidtnec-170804150202/85/XPDDS17-uniprof-Transparent-Unikernel-Performance-Profiling-and-Debugging-Florian-Schmidt-NEC-30-320.jpg)
![31
Stack
Local variables
RegistersIP
FP
function one() {
[…]
two();
[…]
}
function two() {
[…]
three();
}
function three() {
[…]
}
…
… …
Frame pointer
NULL
Return address
Other registers
Local variables
Frame pointer
Return address
Other registers
Local variables
Stack trace:
three +0xca
two +0xc1
one +0x0d
IP
FP+1word
*FP+1word](https://image.slidesharecdn.com/xpdds17uniprof-transparentunikernelperformanceprofilinganddebugging-florianschmidtnec-170804150202/85/XPDDS17-uniprof-Transparent-Unikernel-Performance-Profiling-and-Debugging-Florian-Schmidt-NEC-31-320.jpg)
![32
Stack
Local variables
RegistersIP
FP
function one() {
[…]
two();
[…]
}
function two() {
[…]
three();
}
function three() {
[…]
}
…
… …
Frame pointer
NULL
Return address
Other registers
Local variables
Frame pointer
Return address
Other registers
Local variables
Stack trace:
three +0xca
two +0xc1
one +0x0d
IP
FP+1word
*FP+1word](https://image.slidesharecdn.com/xpdds17uniprof-transparentunikernelperformanceprofilinganddebugging-florianschmidtnec-170804150202/85/XPDDS17-uniprof-Transparent-Unikernel-Performance-Profiling-and-Debugging-Florian-Schmidt-NEC-32-320.jpg)
![33
Stack
Local variables
RegistersIP
FP
function one() {
[…]
two();
[…]
}
function two() {
[…]
three();
}
function three() {
[…]
}
…
… …
Frame pointer
NULL
Return address
Other registers
Local variables
Frame pointer
Return address
Other registers
Local variables
Stack trace:
three +0xca
two +0xc1
one +0x0d
[done]
IP
FP+1word
*FP+1word
**FP==NULL](https://image.slidesharecdn.com/xpdds17uniprof-transparentunikernelperformanceprofilinganddebugging-florianschmidtnec-170804150202/85/XPDDS17-uniprof-Transparent-Unikernel-Performance-Profiling-and-Debugging-Florian-Schmidt-NEC-33-320.jpg)
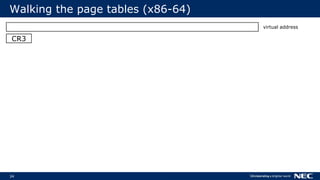
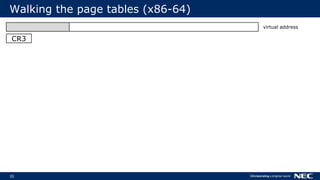
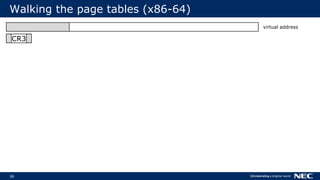

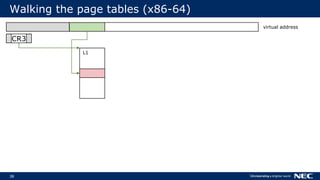
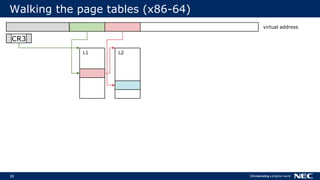
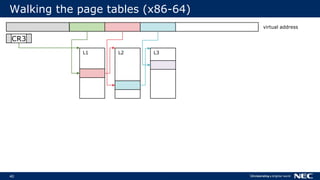
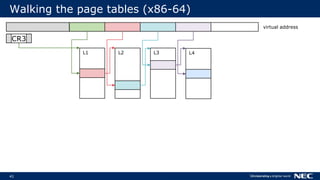












![63
No Frame Pointer? No Problem!
▌Stack walking relies on frame pointer
Optimizations can reuse FP as general-purpose register (-fomit-frame-pointer)
▌But we can do without FPs
Use stack unwinding information
• It’s already included if you use C++ (for exception handling)
• It doesn’t change performance
• Only binary size
DWARF standard
$ readelf –S <ELF>
There are 13 section headers, starting at offset 0x40d58:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[...]
[ 4] .eh_frame PROGBITS 0000000000035860 00036860
00000000000066f8 0000000000000000 A 0 0 8
[ 5] .eh_frame_hdr PROGBITS 000000000003bf58 0003cf58
000000000000128c 0000000000000000 A 0 0 4
[...]](https://image.slidesharecdn.com/xpdds17uniprof-transparentunikernelperformanceprofilinganddebugging-florianschmidtnec-170804150202/85/XPDDS17-uniprof-Transparent-Unikernel-Performance-Profiling-and-Debugging-Florian-Schmidt-NEC-63-320.jpg)








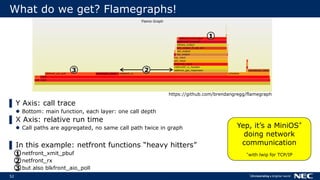
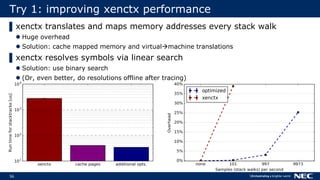
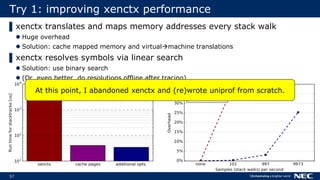
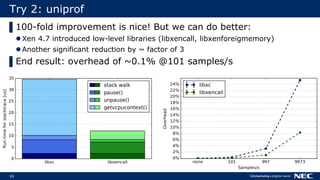
The document discusses Uniprof, a performance profiling tool that aims to improve debugging processes for unikernels by providing minimal overhead and requiring no code changes. It contrasts Uniprof with existing tools like Xenctx, which although functional, suffers from performance issues. The goal is to facilitate better profiling in production environments by creating flamegraphs that visualize call traces and identify performance bottlenecks.























![Ilfak Guilfanov - Decompiler internals: Microcode [rooted2018]](https://cdn.slidesharecdn.com/ss_thumbnails/ilfak-keynote-180312223906-thumbnail.jpg?width=640&height=640&fit=bounds)
![Eloi Sanfelix - Hardware security: Side Channel Attacks [RootedCON 2011]](https://cdn.slidesharecdn.com/ss_thumbnails/esanfelix-sidechannelattacks-110307125844-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






































![XPDDS19: [ARM] OP-TEE Mediator in Xen - Volodymyr Babchuk, EPAM Systems](https://cdn.slidesharecdn.com/ss_thumbnails/xendevsummit2019-babchuk-op-tee-190812095541-thumbnail.jpg?width=640&height=640&fit=bounds)























