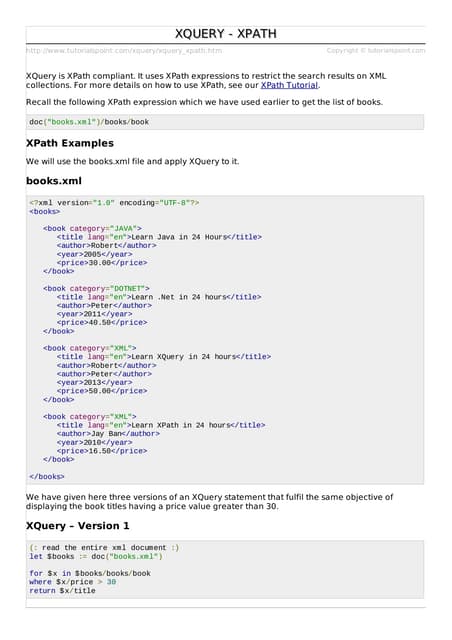
![XQuery
For each author of a book by Morgan
Kaufmann, list all books she published:
FOR $a IN distinct-values(doc ("books.xml")
/bib/book[publisher=“Morgan Kaufmann”]/author)
RETURN <result>
$a,
FOR $t IN /bib/book[author=$a]/title
RETURN $t
</result>
FOR $a IN distinct-values(doc ("books.xml")
/bib/book[publisher=“Morgan Kaufmann”]/author)
RETURN <result>
$a,
FOR $t IN /bib/book[author=$a]/title
RETURN $t
</result>
distinct = a function that eliminates duplicates](https://image.slidesharecdn.com/xquery-130610235912-phpapp02/75/X-Query-for-beginner-6-2048.jpg)


![XQuery
count = a (aggregate) function that returns the number of elms
<big_publishers>
FOR $p IN distinct-values(doc ("books.xml")//publisher)
LET $b := doc ("books.xml")/book[publisher = $p]
WHERE count($b) > 100
RETURN $p
</big_publishers>
<big_publishers>
FOR $p IN distinct-values(doc ("books.xml")//publisher)
LET $b := doc ("books.xml")/book[publisher = $p]
WHERE count($b) > 100
RETURN $p
</big_publishers>](https://image.slidesharecdn.com/xquery-130610235912-phpapp02/75/X-Query-for-beginner-9-2048.jpg)






![Sorting in XQuery
<publisher_list>
FOR $p IN distinct-values(doc("books.xml")//publisher)
RETURN <publisher> <name> $p/text() </name> ,
FOR $b IN doc("books.xml")//book[publisher = $p]
RETURN <book>
$b/title ,
$b/@price
</book> SORTBY(price DESCENDING)
</publisher> SORTBY(name)
</publisher_list>
<publisher_list>
FOR $p IN distinct-values(doc("books.xml")//publisher)
RETURN <publisher> <name> $p/text() </name> ,
FOR $b IN doc("books.xml")//book[publisher = $p]
RETURN <book>
$b/title ,
$b/@price
</book> SORTBY(price DESCENDING)
</publisher> SORTBY(name)
</publisher_list>](https://image.slidesharecdn.com/xquery-130610235912-phpapp02/75/X-Query-for-beginner-16-2048.jpg)





![Group-By in Xquery ??
FOR $b IN doc("http://www.bn.com")/bib/book,
$a IN $b/author,
$y IN $b/@year
RETURN GROUPBY $a, $y
IN <result> $a,
<year> $y </year>,
<total> count($b) </total>
</result>
FOR $b IN doc("http://www.bn.com")/bib/book,
$a IN $b/author,
$y IN $b/@year
RETURN GROUPBY $a, $y
IN <result> $a,
<year> $y </year>,
<total> count($b) </total>
</result>
FOR $Tup IN distinct-values(FOR $b IN doc("http://www.bn.com")/bib,
$a IN $b/author,
$y IN $b/@year
RETURN <Tup> <a> $a </a> <y> $y </y> </Tup>),
$a IN $Tup/a/node(),
$y IN $Tup/y/node()
LET $b = doc("http://www.bn.com")/bib/book[author=$a,@year=$y]
RETURN <result> $a,
<year> $y </year>,
<total> count($b) </total>
</result>
FOR $Tup IN distinct-values(FOR $b IN doc("http://www.bn.com")/bib,
$a IN $b/author,
$y IN $b/@year
RETURN <Tup> <a> $a </a> <y> $y </y> </Tup>),
$a IN $Tup/a/node(),
$y IN $Tup/y/node()
LET $b = doc("http://www.bn.com")/bib/book[author=$a,@year=$y]
RETURN <result> $a,
<year> $y </year>,
<total> count($b) </total>
</result>
with GROUPBY
Without GROUPBY ](https://image.slidesharecdn.com/xquery-130610235912-phpapp02/75/X-Query-for-beginner-22-2048.jpg)


XQuery is a query language for XML that includes FLWR expressions. FLWR stands for For-Let-Where-Return and allows iterating over nodes, binding variables, applying predicates, and constructing result trees. Key points covered include using FOR to bind node variables versus LET to bind collection variables, and how collections are handled in expressions. Sorting and conditional logic with IF-THEN-ELSE were also discussed. While XQuery does not currently support a GROUP BY clause, adding this capability was debated.