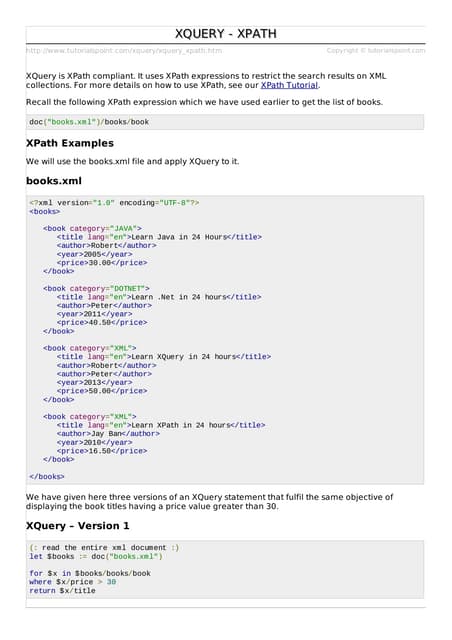
XQuery is a programming language used for querying and transforming XML data, enabling extraction and combination of XML documents. It supports features like variables, loops, conditionals, and functions, making it versatile for data manipulation tasks. XPath, a language for selecting nodes in XML documents, works with XQuery to efficiently query XML structures using various path expressions.













![5. Using Predicates (Conditions):
Predicates are used to filter nodes based on certain conditions. These are
enclosed in square brackets [].
//book[price > 20]
This selects all <book> elements where the <price> child element has a value
greater than 20.
● We can also use predicates to select specific occurrences of elements:
//book[2]
This selects the second <book> element.
14](https://image.slidesharecdn.com/seminar-xpathxquery-241222143825-4b74cbac/75/Xpath-Xquery-in-XML-documents-for-retreving-data-14-2048.jpg)
![XPath Examples:
1. Select all books:
//book
2. Select the title of the second book:
//book[2]/title
3. Select the price of books where the price is greater than 20:
//book[price > 20]/price
15](https://image.slidesharecdn.com/seminar-xpathxquery-241222143825-4b74cbac/75/Xpath-Xquery-in-XML-documents-for-retreving-data-15-2048.jpg)
![4. Select the id attribute of the first book:
//book[1]/@id
5. Select the text content of all titles:
//book/title/text()
6. Select all books that are written by "John Doe":
//book[author = "John Doe"]
7. Select the author of the first book:
//book[1]/author
16](https://image.slidesharecdn.com/seminar-xpathxquery-241222143825-4b74cbac/75/Xpath-Xquery-in-XML-documents-for-retreving-data-16-2048.jpg)