Download as PDF, PPTX











![2. Data cleansing
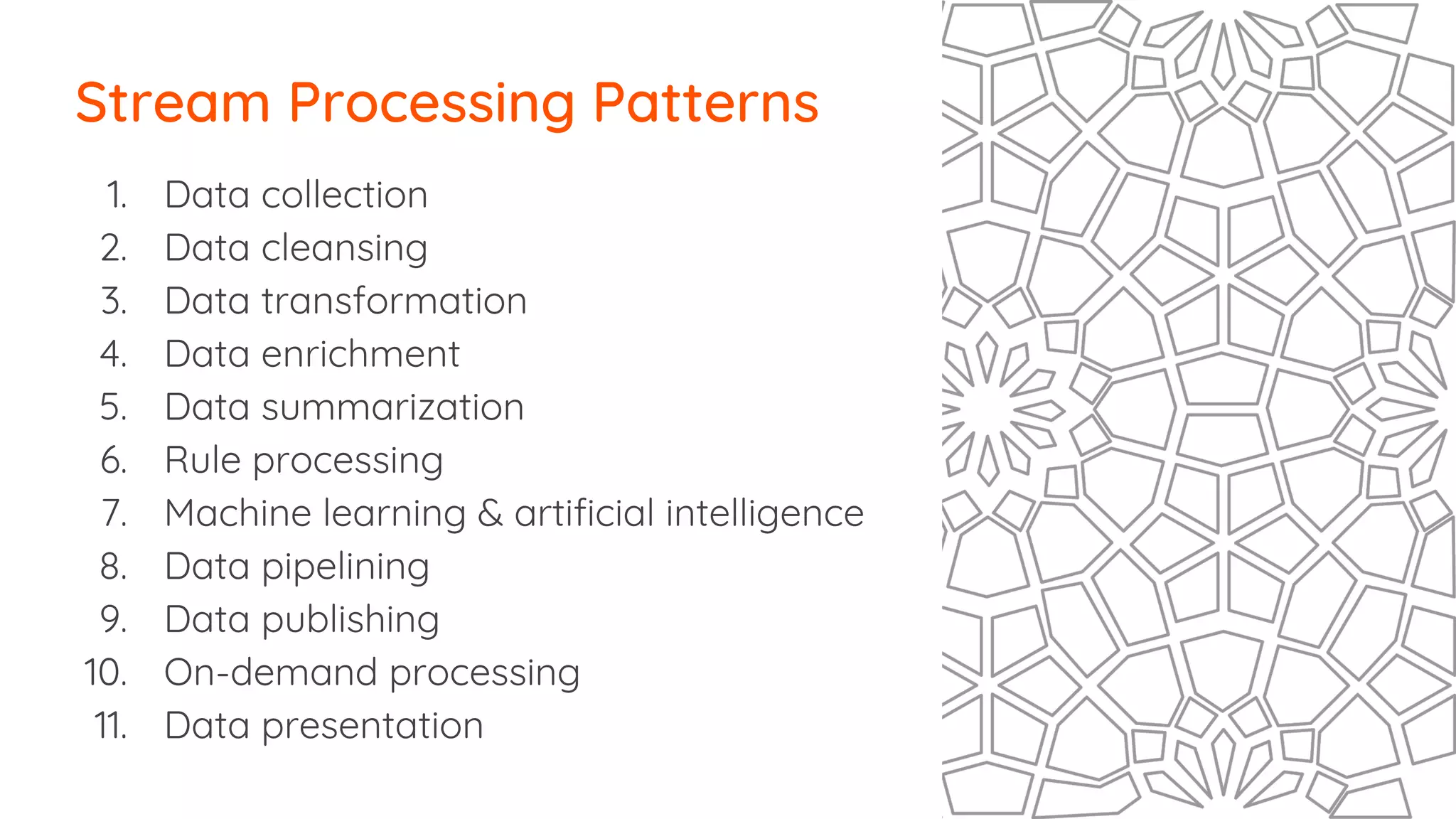
Types of data cleansing
● Filtering
○ value ranges
○ string matching
○ regex
● Setting Defaults
○ Null checks
○ If-then-else clouces
define stream ProductionStream
(name string, amount double);
from ProductionStream [name==“cake”]
select name, ifThenElse ( amount<0, 0.0,
amount) as amount
insert into CleansedProductionStream;](https://image.slidesharecdn.com/3-181113092919/75/WSO2Con-EU-2018-Patterns-for-Building-Streaming-Apps-15-2048.jpg)

![Data type of Stream Processor is Tuple
Array[] containing values of
string, int, float, long, double, bool, object
JSON, XML,
Text, Binary,
Key-value,
CSV, Avro,
WSO2Event
Tuple
JSON, XML,
Text, Binary,
Key-value,
CSV, Avro,
WSO2Event
3. Data transformation](https://image.slidesharecdn.com/3-181113092919/75/WSO2Con-EU-2018-Patterns-for-Building-Streaming-Apps-17-2048.jpg)

![Transform data by
● Inline operations
○ math & logical operations
● Inbuilt function calls
○ 60+ extensions
● Custom function calls
○ Java, JS, R
3. Data transformation
myFunction(item, price) as discount
define function myFunction[lang_name] return return_type {
function_body
};
str:upper(ItemID) as IteamCode,
amount * price as cost](https://image.slidesharecdn.com/3-181113092919/75/WSO2Con-EU-2018-Patterns-for-Building-Streaming-Apps-19-2048.jpg)



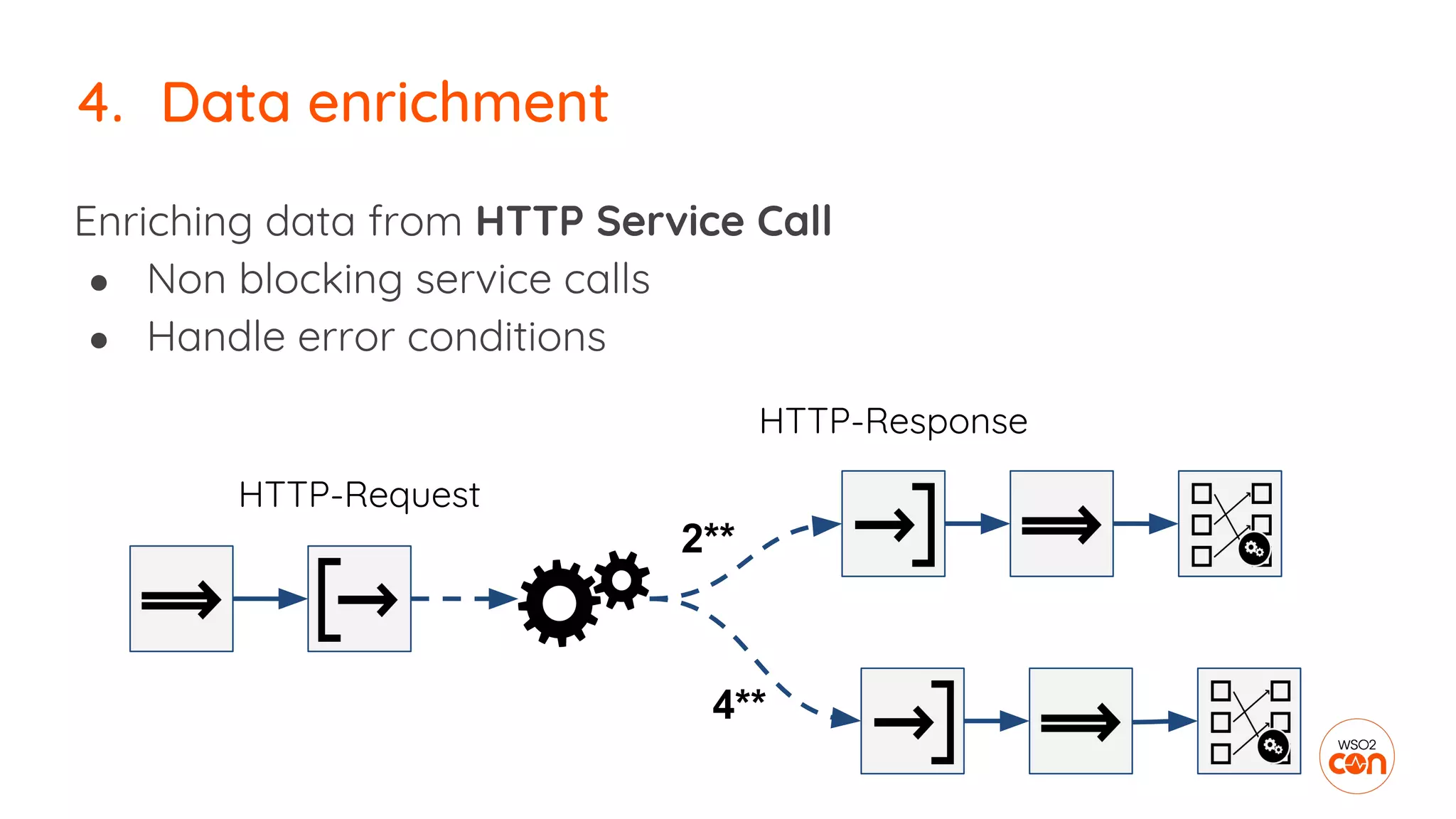




![No occurrence of event pattern detection
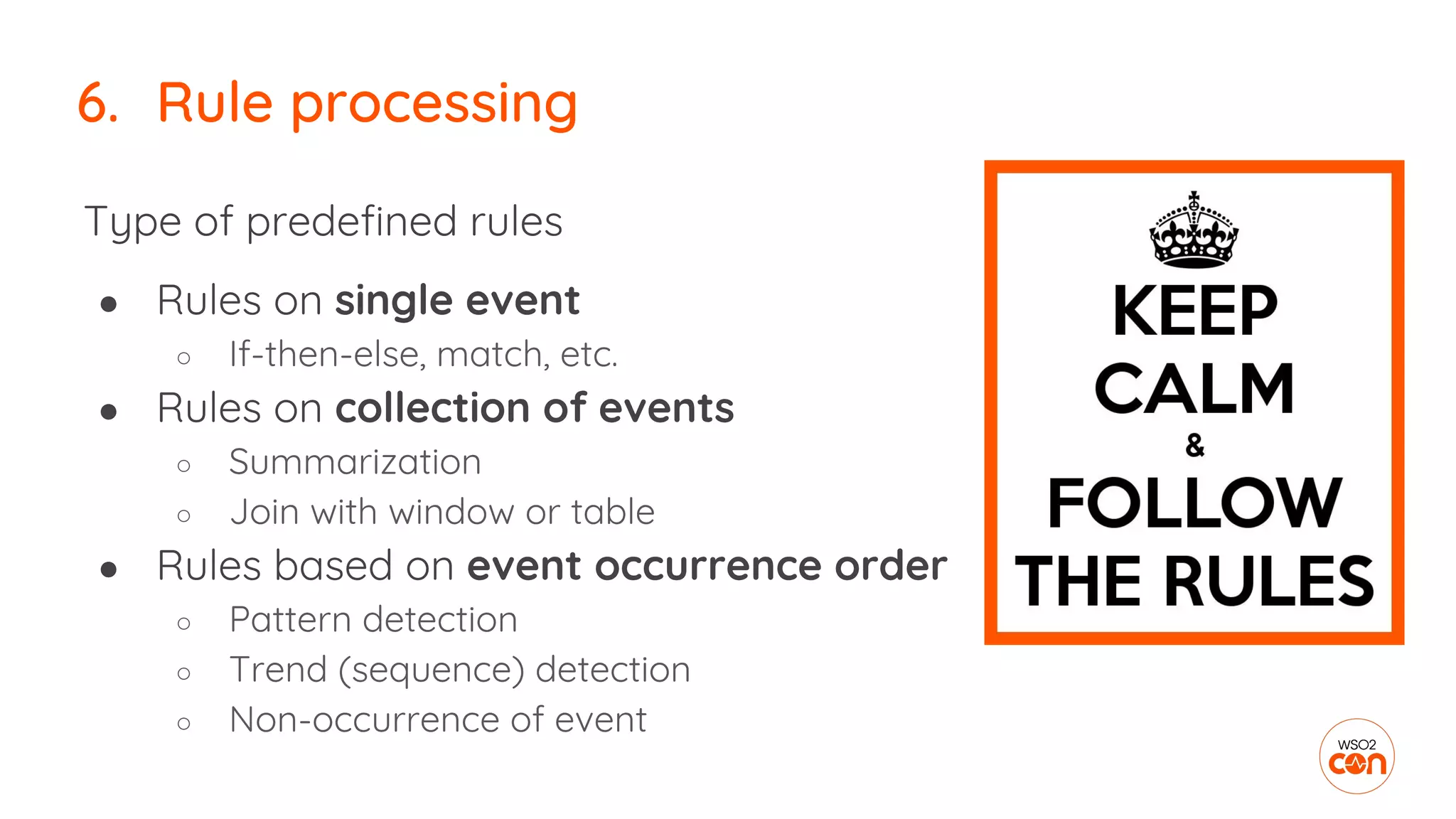
6. Rule processing
define stream DeliveryStream (orderId string, amount double);
define stream PaymentStream (orderId string, amount double);
from every (e1 = DeliveryStream)
-> not PaymentStream [orderId == e1.orderId] for 15 min
select e1.orderId, e1.amount
insert into PaymentDelayedStream ;](https://image.slidesharecdn.com/3-181113092919/75/WSO2Con-EU-2018-Patterns-for-Building-Streaming-Apps-29-2048.jpg)

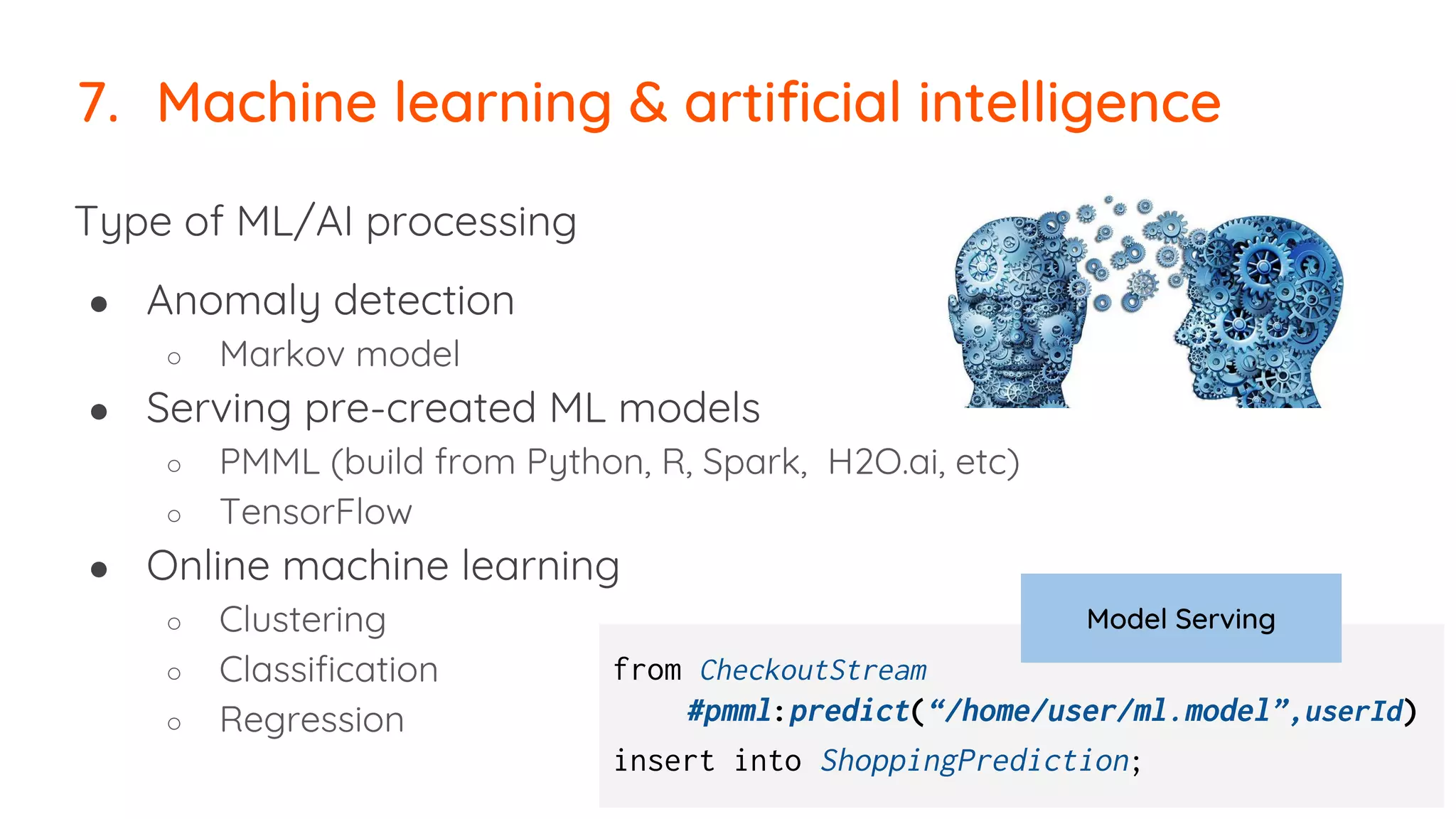


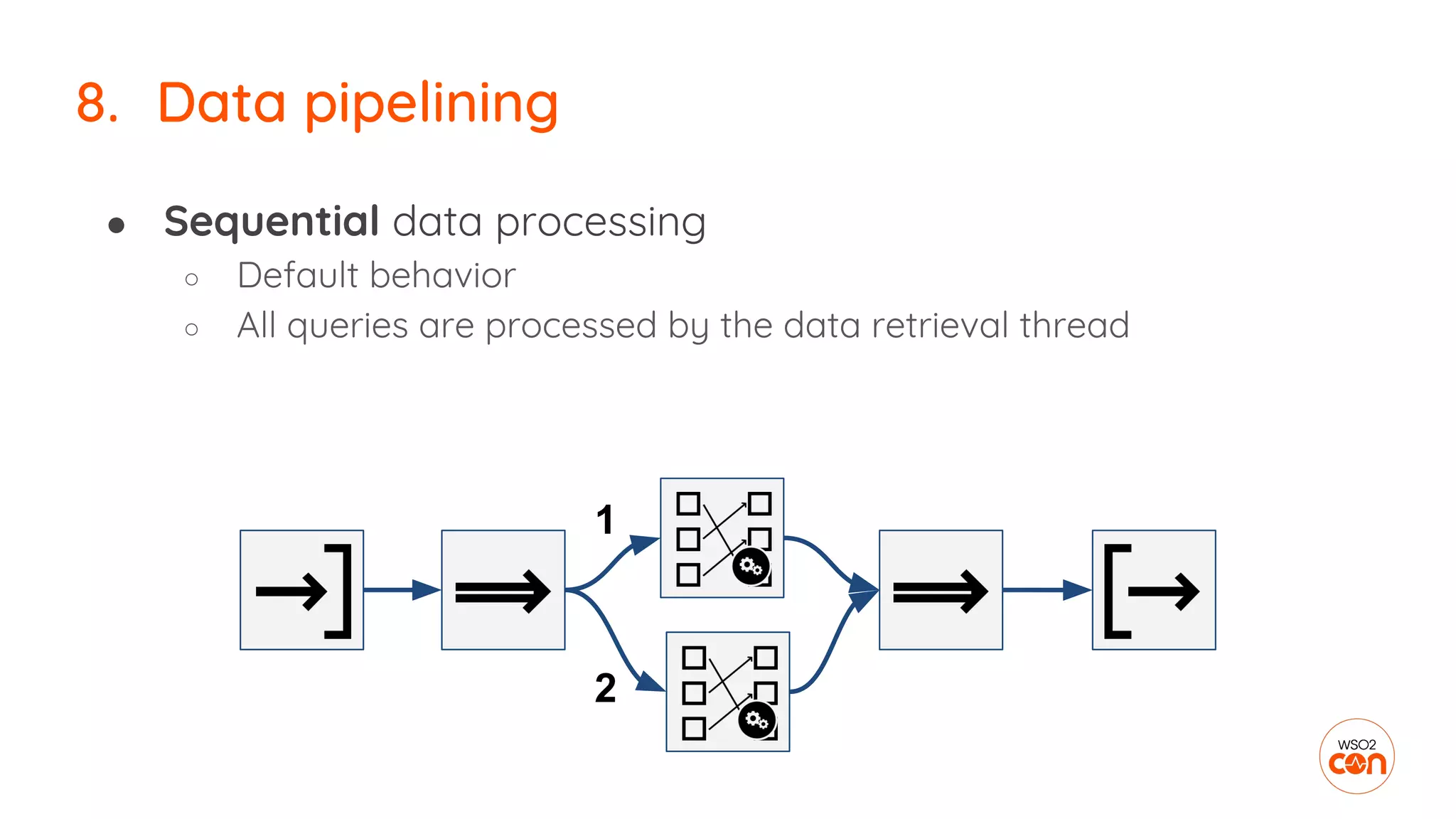
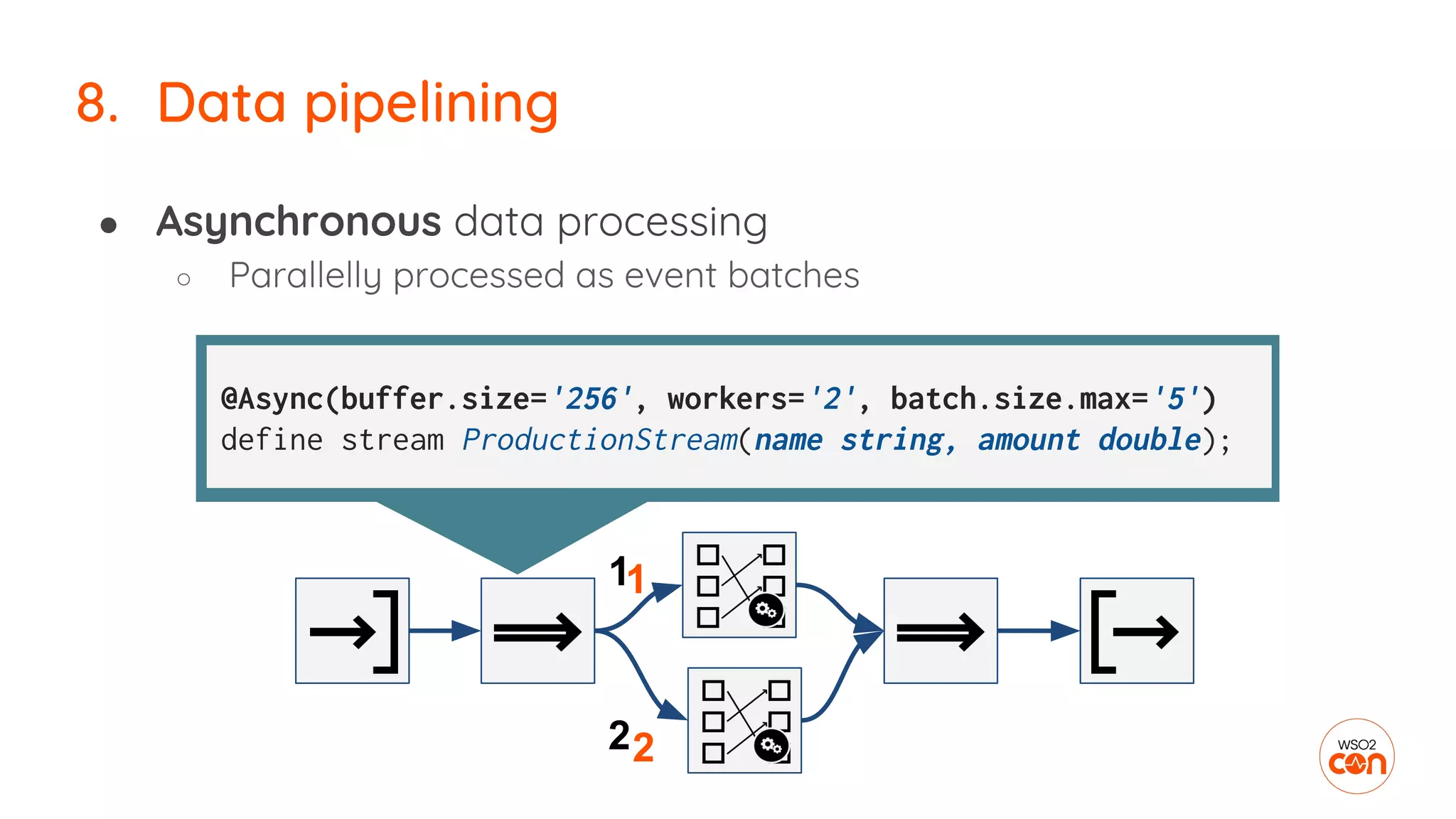
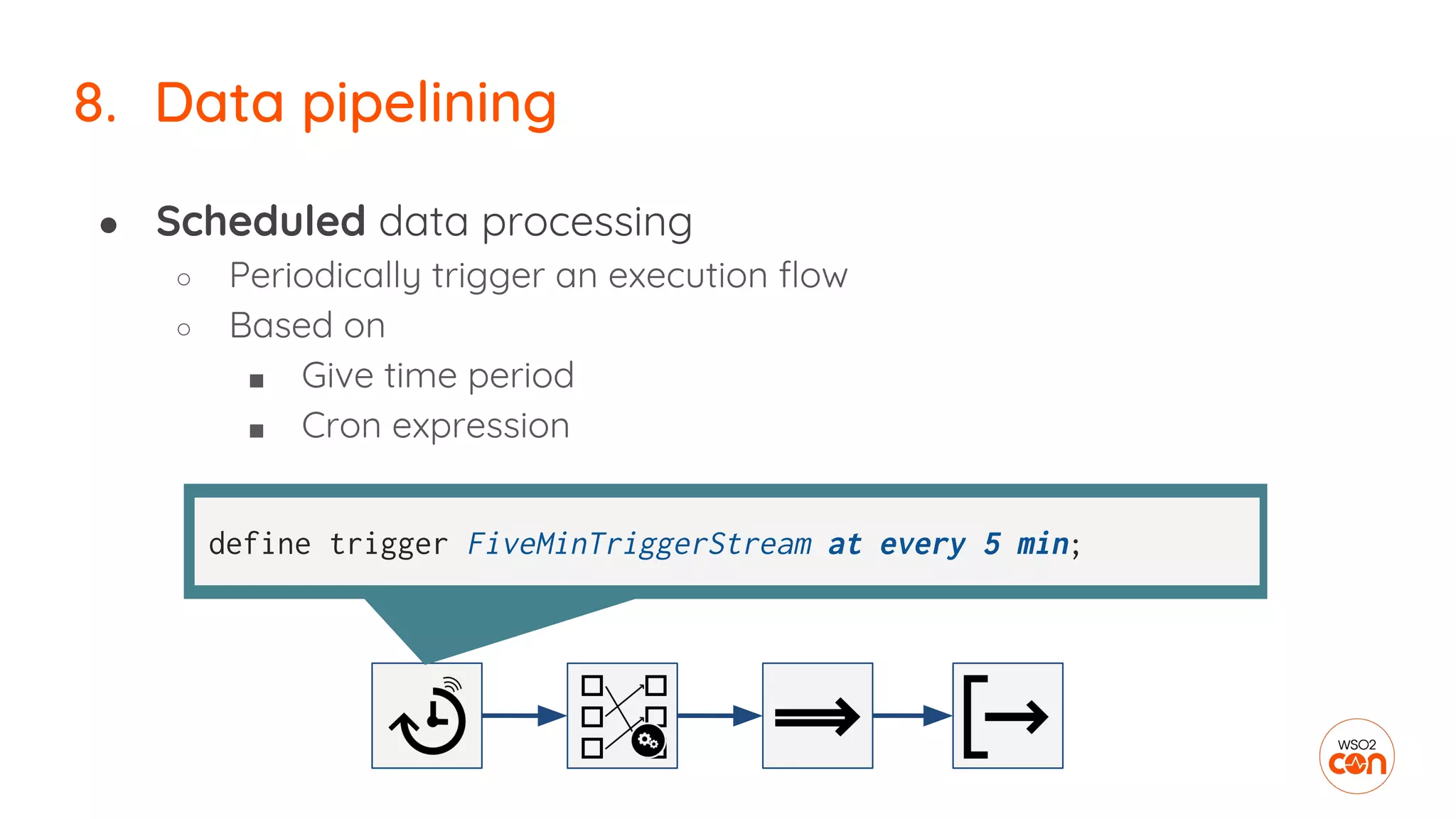
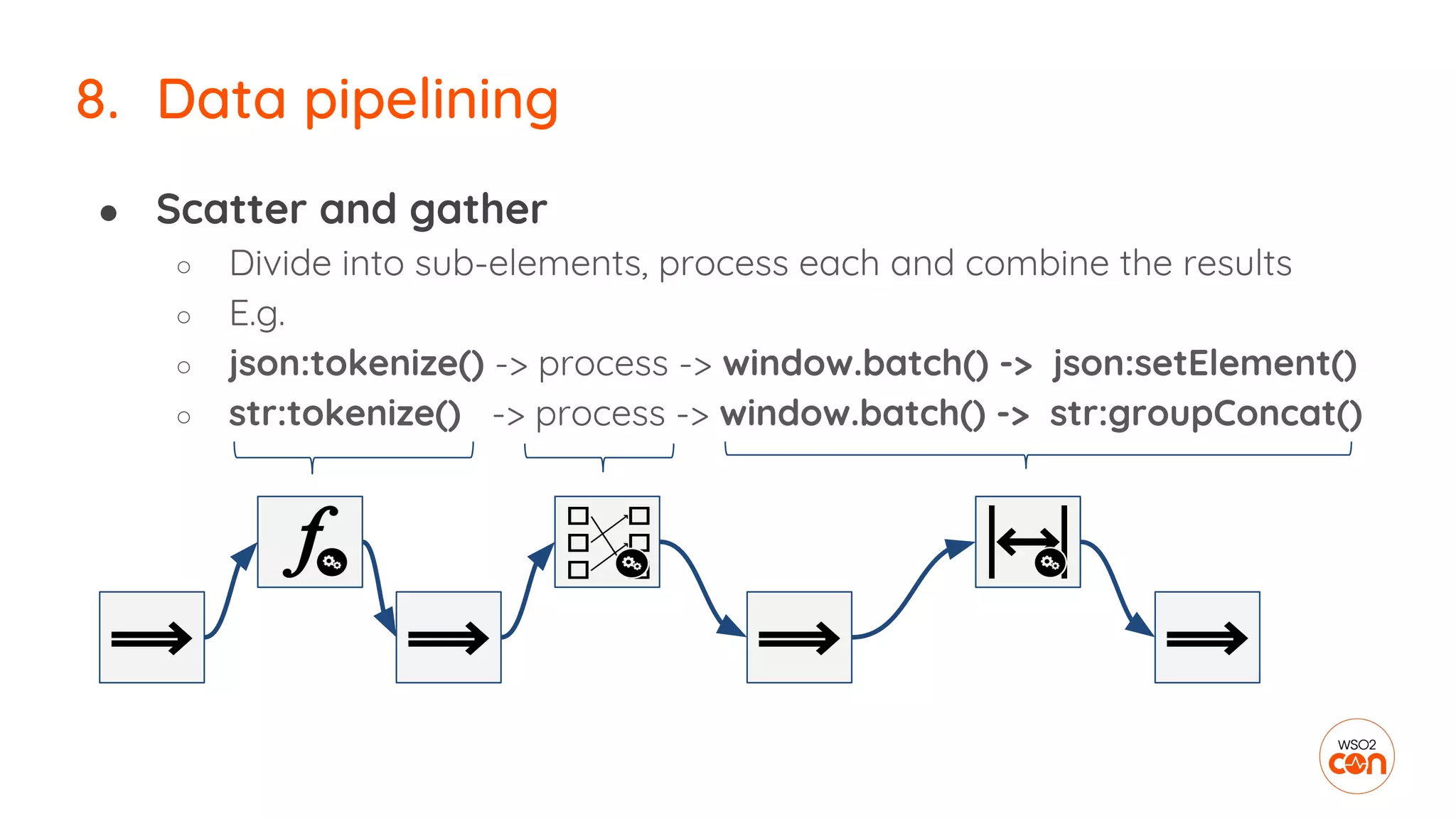
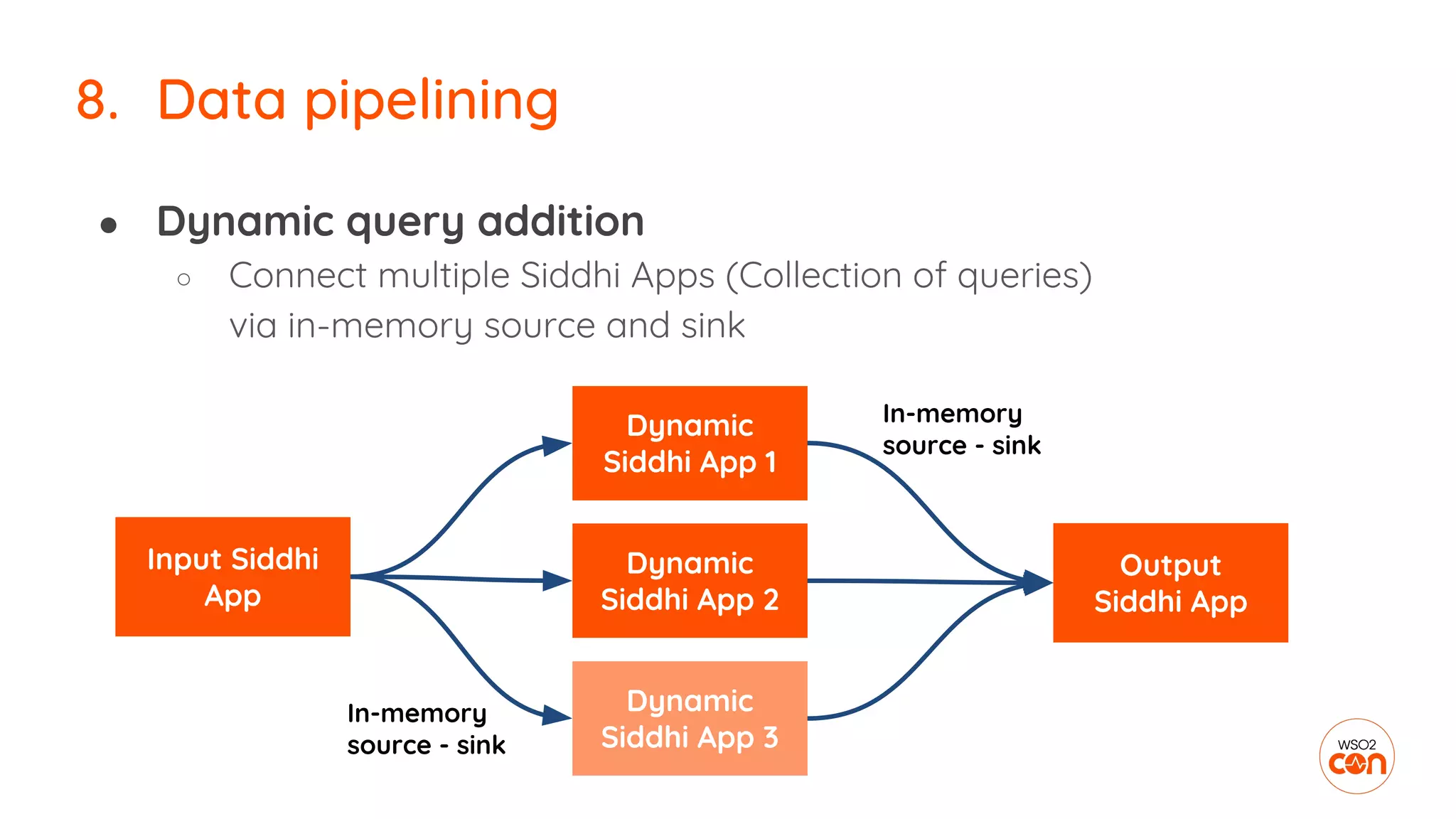




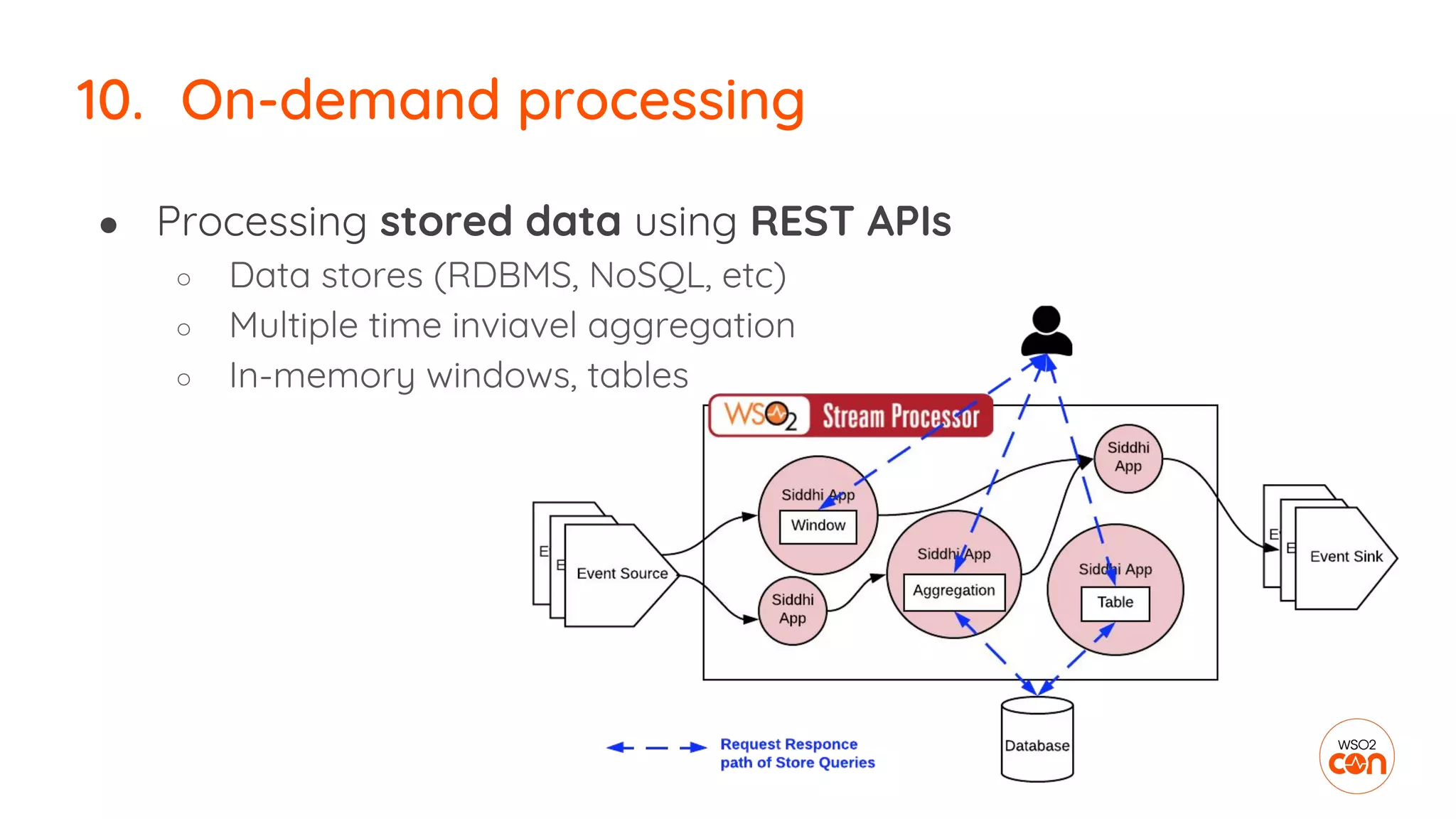
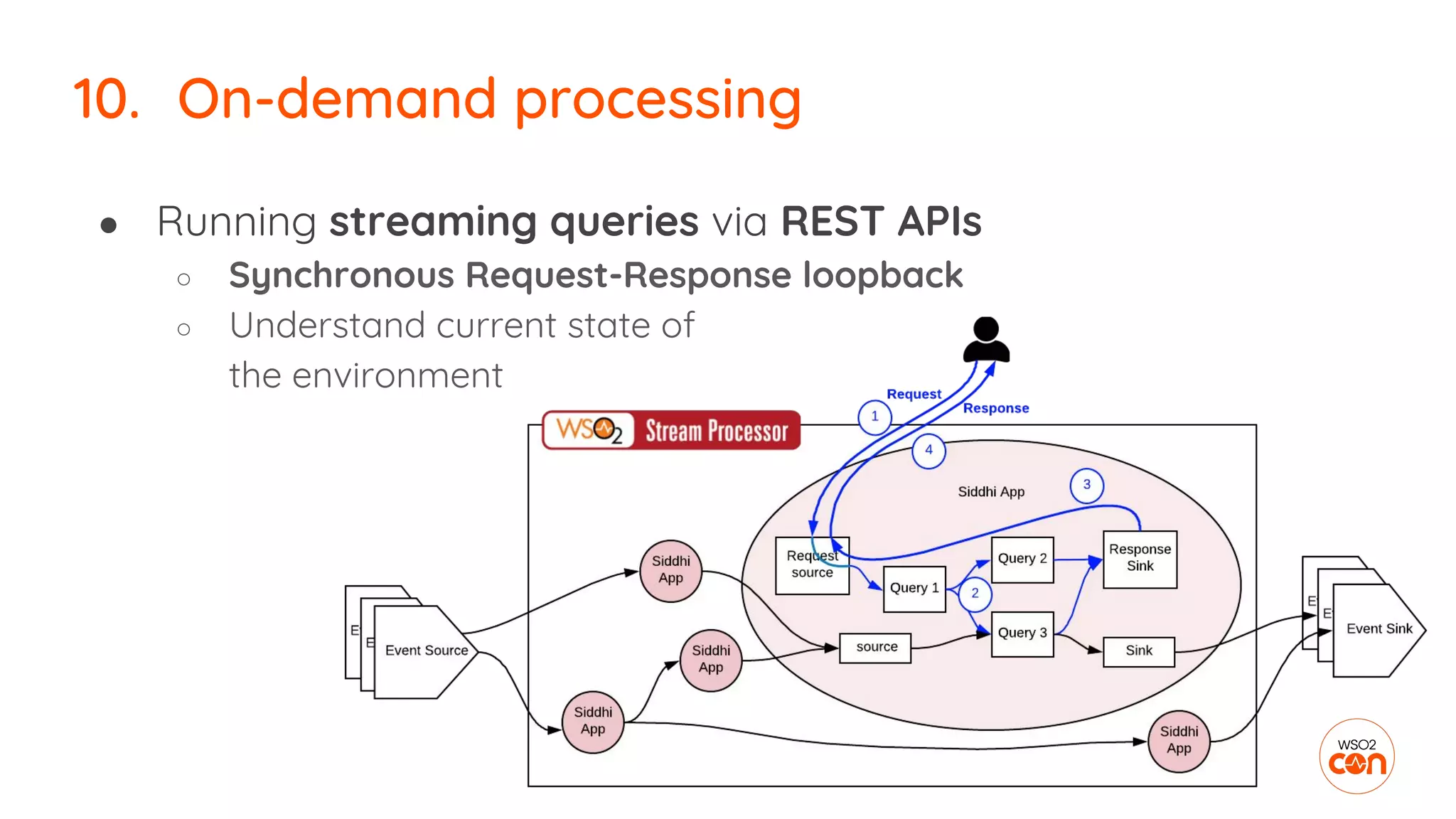



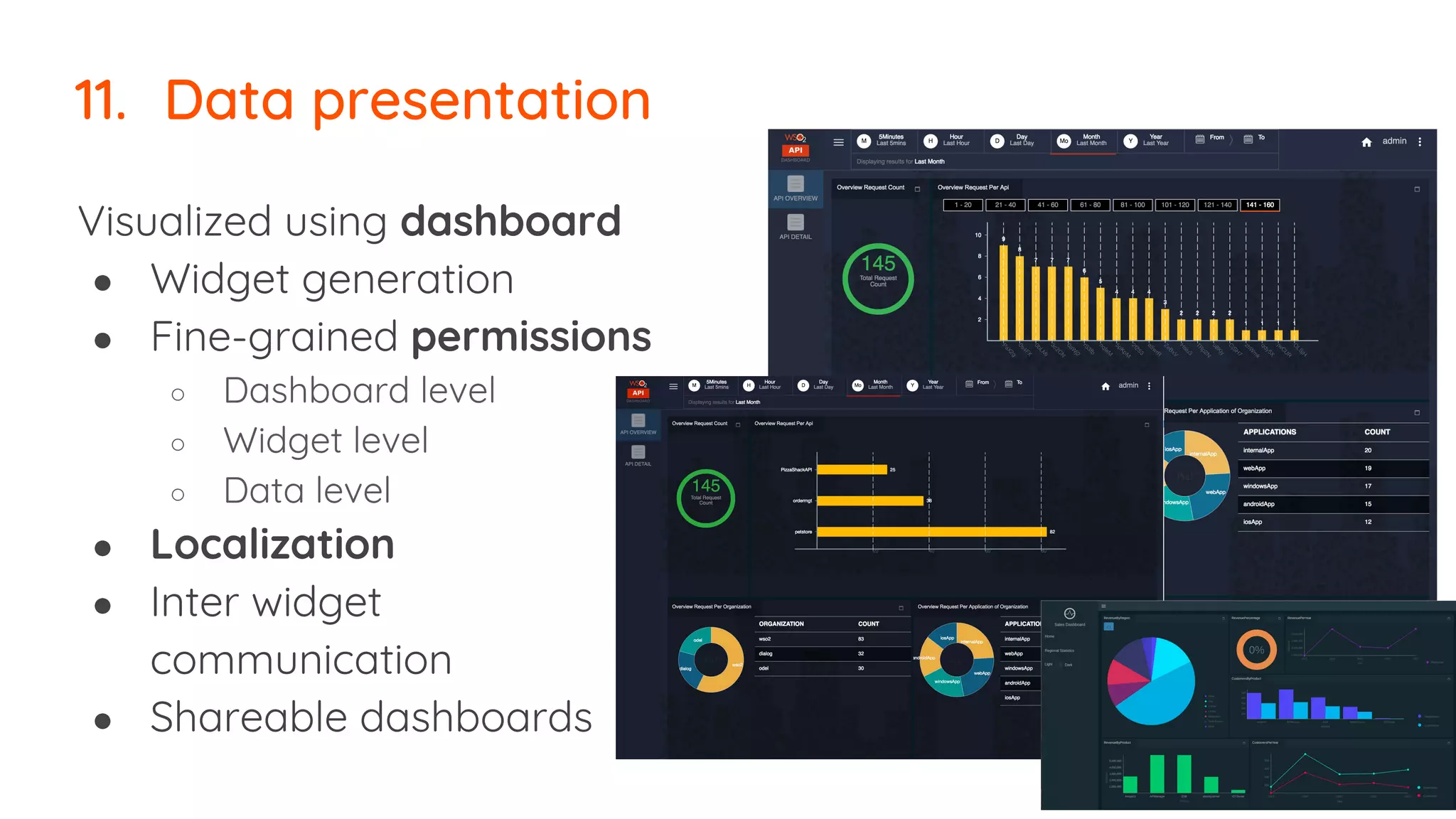
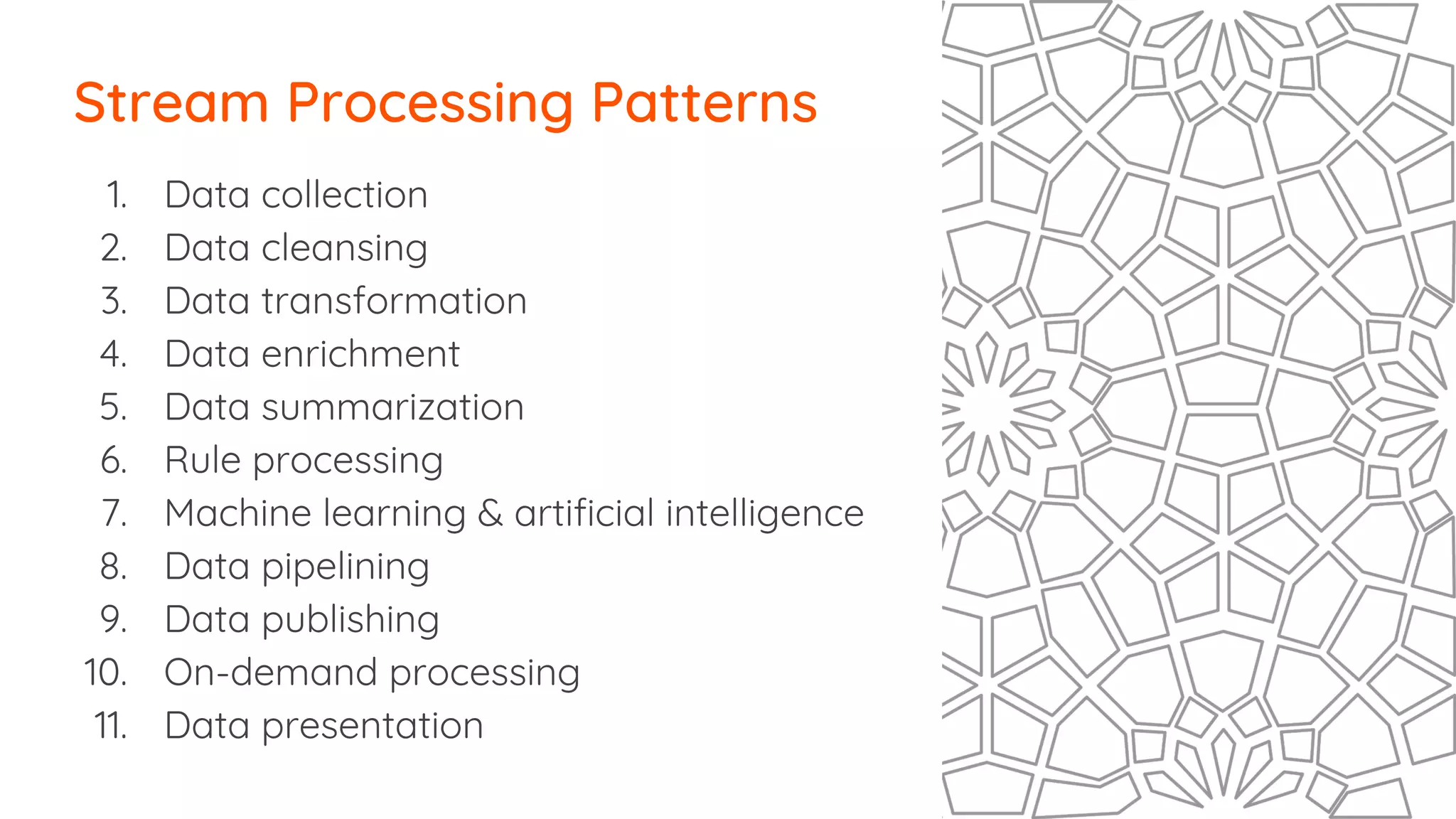

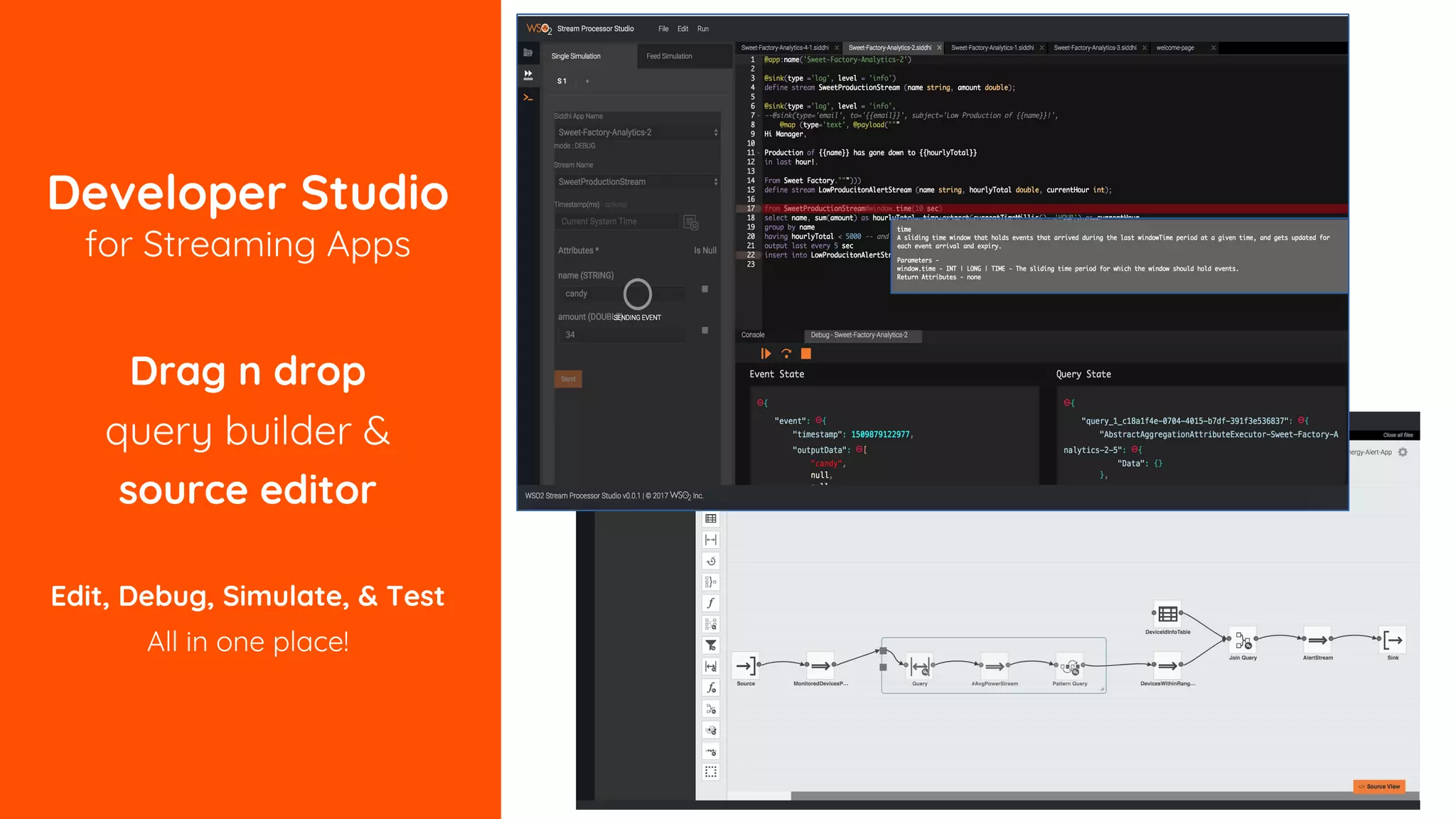



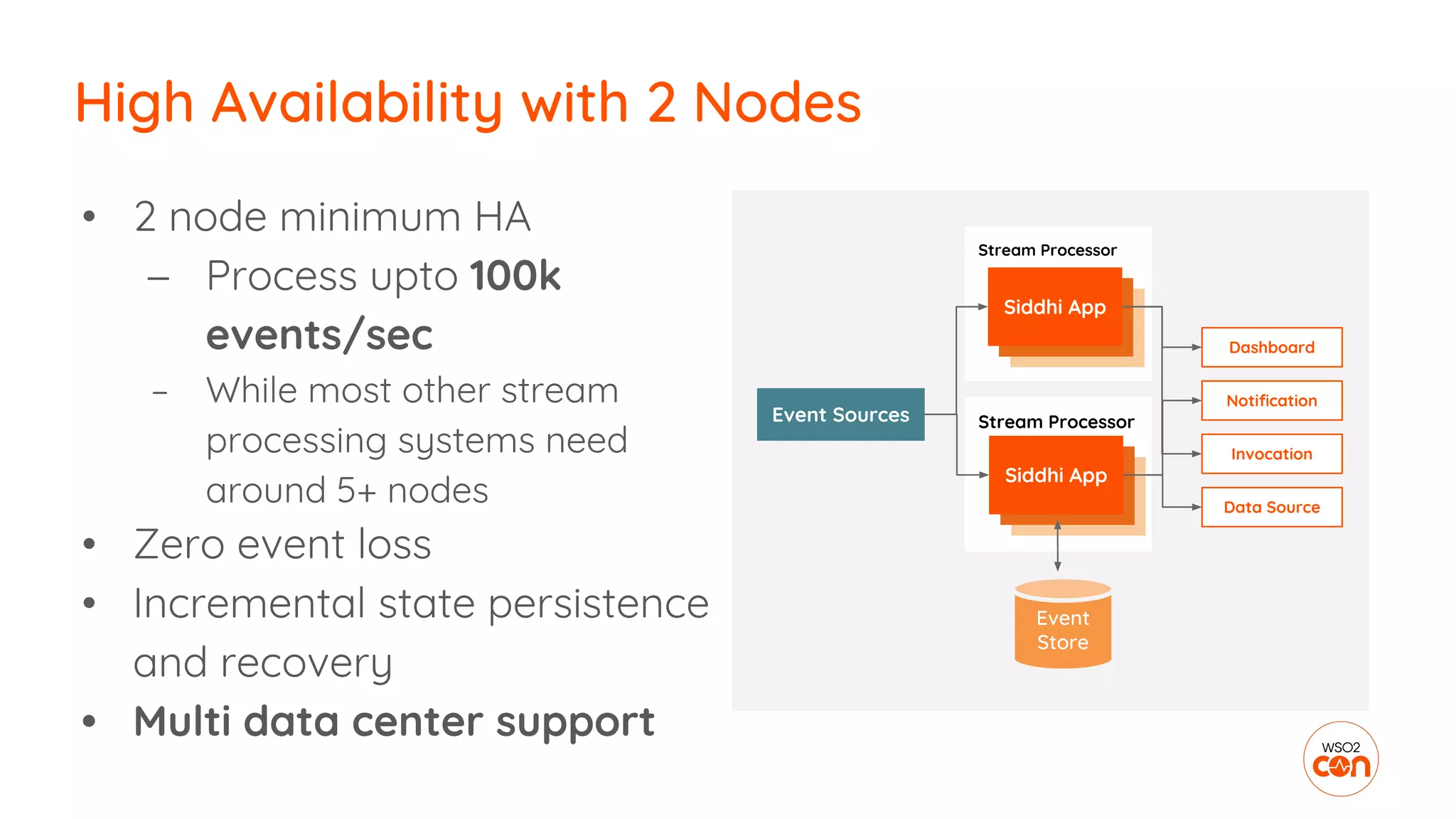
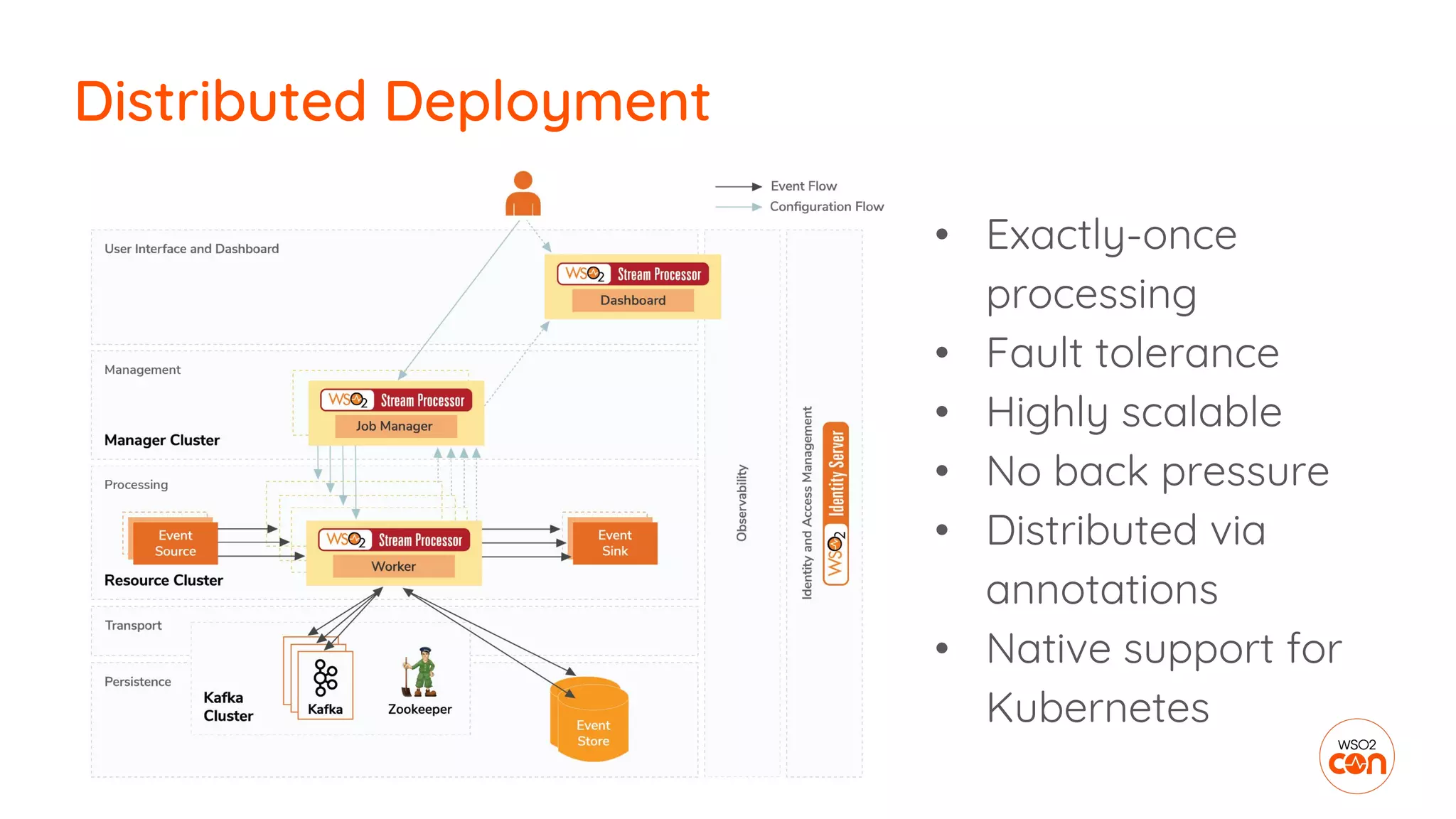








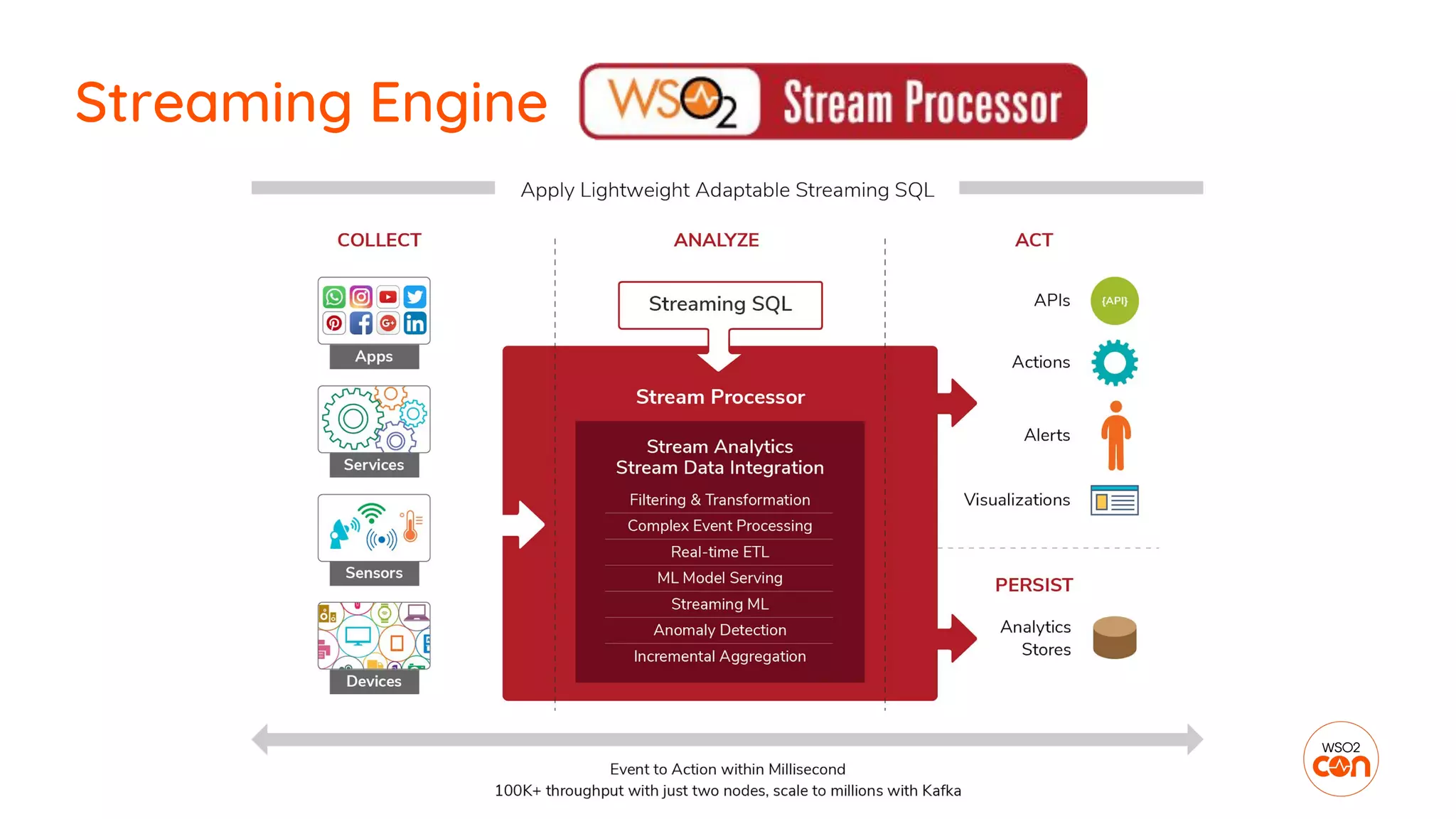
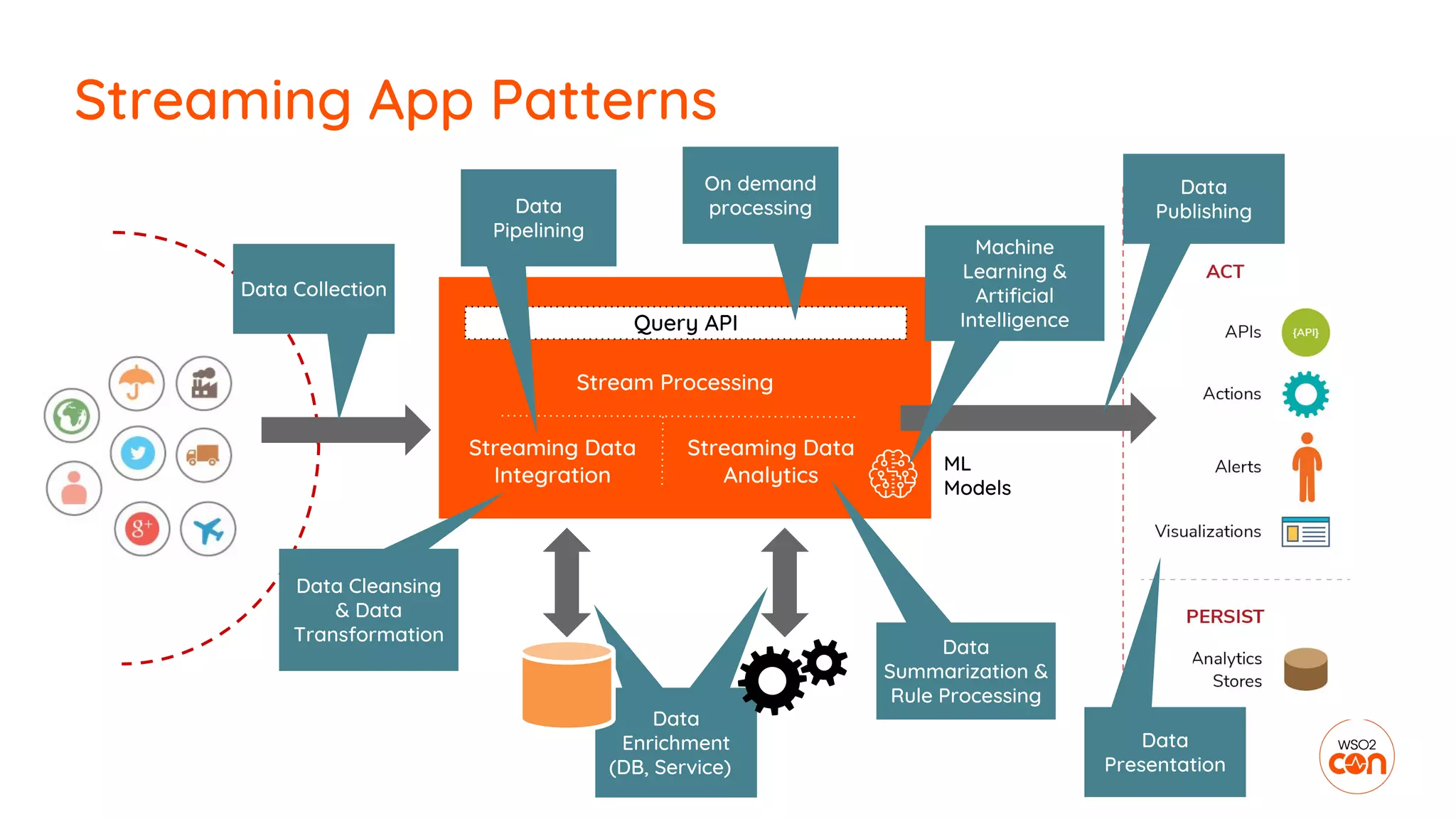
The document outlines essential strategies for building streaming applications using WSO2, detailing the importance of streaming patterns for real-time data processing across various business scenarios. It elaborates on eleven streaming patterns, including data collection, cleansing, transformation, enrichment, summarization, rule processing, and machine learning integration. Additionally, it emphasizes deployment, monitoring, and the capabilities of WSO2 Stream Processor in developing and managing these applications effectively.
![[WSO2Con EU 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/1-181113084942-thumbnail.jpg?width=640&height=640&fit=bounds)
![[WSO2Con EU 2018] Streaming SQL in the Real World](https://cdn.slidesharecdn.com/ss_thumbnails/wso2coneu2018streamingsqlintherealworld-181113090808-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[WSO2Con Asia 2018] Patterns for Building Streaming Apps](https://cdn.slidesharecdn.com/ss_thumbnails/wso2conasia2018presentation-patternsforbuildingstreamingapps-180810110016-thumbnail.jpg?width=640&height=640&fit=bounds)
![[WSO2Con USA 2018] Patterns for Building Streaming Apps](https://cdn.slidesharecdn.com/ss_thumbnails/wso2conusa2018presentation-patternsforbuildingstreamingapps-180717043111-thumbnail.jpg?width=640&height=640&fit=bounds)



![[WSO2Con EU 2017] Streaming Analytics Patterns for Your Digital Enterprise](https://cdn.slidesharecdn.com/ss_thumbnails/lgqvq0vzqhygnya85esl-signature-6abac760590306a9c092f3ba66249d9a805ee6b52c9eb804a80eabb33b95c5ef-poli-171106133401-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[Roundtable] Choreo - The AI-Native Internal Developer Platform as a Service](https://cdn.slidesharecdn.com/ss_thumbnails/choreo-deck-250328074645-511dded7-thumbnail.jpg?width=640&height=640&fit=bounds)






























