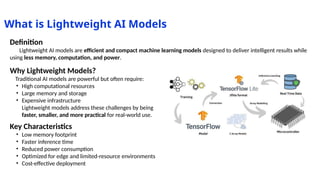
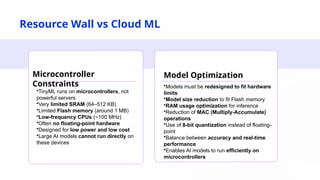
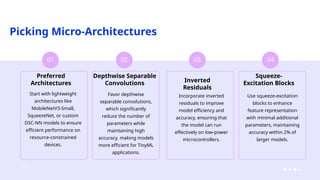
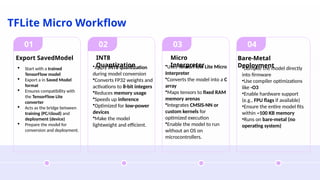
Why Lightweight Models?
Traditional AI models are powerful but often require:
High computational resources
Large memory and storage
Expensive infrastructure
Lightweight models address these challenges by being faster, smaller, and more practical for real-world use.