An Industry Perspective on AI-Integrated IoT Systems
We possess end-to-end expertise in developing embedded systems based on System-on-Chip (SoC) architectures, supporting both product and platform development.
An Industry Perspective on AI-Integrated IoT Systems
1.
AIoT : TheAudio
Edge
An Industry Perspective on AI-Integrated IoT
Systems
Guhan Ganesamurthi
Director
nBase2 Systems Pvt Ltd
2.
About Us
DRIVING TECHNOLOGICAL
BREAKTHROUGHSSINCE
2018
Founded with a vision to
deliver cutting-edge
technology solutions for the
global market
COMPREHENSIVE
ENGINEERING SERVICES FOR
SEMICONDUCTOR, EMBEDDED
SYSTEMS AND WEB
DEVELOPMENT
Providing end-to-end services
from System Design and SW
Audio Tools to Web Development
and Test Automation
THE TRUSTED ENGINEERING
PARTNER FOR INNOVATION
The go-to experts for
semiconductor,
embedded product and
technology companies
DEEP DOMAIN
EXPERTISE
Over 8 decades of cumulative
experience in audio, signal
processing, embedded systems
and web development
FLEXIBLE ENGAGEMENT
MODELS
Offering tailored delivery
models, including turnkey
projects, staff augmentation,
and IP licensing
3.
Audio Tuning Tools
Registermaps, calibration tools, and debug interfaces
Multimedia EVM and SDK Configuration
Real-time parameter adjustment and visualization for DSP
algorithms, Codec and Speaker tuning
Semiconductor Device Configuration
Simplified setup, testing, and SDK feature control for
evaluation platforms
Key Offerings
These interfaces are often deployed as cross-platform desktop
apps or over the cloud to support engineering teams, end
users, or field technicians.
We design and develop graphical user
interfaces (GUIs) using modern web
technologies to simplify complex
workflows, enabling a smooth and
intuitive user experience for engineering
and system configuration tasks.
GUI
Development
for Engineering
Applications
SERVICES
4.
We possess end-to-endexpertise in developing embedded systems based on System-on-Chip (SoC) architectures,
supporting both product and platform development.
Embedded SoC Solutions
Embedded SoC
Design &
Development
Firmware development,
BSP integration,
peripheral drivers, RTOS
support
SDK
Development
Custom Software
Development Kits to
enable rapid application
development & third-
party integrations
Audio/Speech
Frameworks
Development and
tuning of embedded
audio/speech
frameworks, codecs,
and real-time DSP
applications
IoT System
Integration
Embedded firmware for
connected devices with
seamless integration to
cloud platforms
Key Offerings
Our solutions are optimized for performance, power efficiency, and scalability across platforms ranging from low-
power MCUs to high-performance embedded Linux systems.
SERVICES
5.
We provide robusttest and validation services to ensure reliability, compliance, and performance of embedded
and software system, spanning development, automation, and certification.
Test and Validation Engineering
SERVICES
Key Offerings
Test Framework Development and Maintenance
Custom test infrastructure tailored for embedded, software, and IoT systems
Device Driver and System Testing
Comprehensive white-box, grey-box, and black-box testing strategies
Focused on device drivers, protocols, application-layer and system validation
Microsoft WHQL Testing and Certification
End-to-end support for Windows Hardware Quality Labs (WHQL) submission, test
execution, result analysis, and compliance reporting for Windows drivers
We help reduce time-to-market and improve system reliability by embedding quality throughout the
development lifecycle.
The Problem withthe Cloud
• Scenario: A Smart Baby Monitor
• The 3 Critical Flaws:
1.Latency: Can you afford a 5-second delay when a baby is choking?
2.Privacy: Do you want audio of your home sent to a server in another
country?
3.Bandwidth: Streaming 24/7 HD audio kills Wi-Fi and costs money.
• The Solution: Process the data inside the monitor.
9.
The Evolution ofIoT
• IoT 1.0 (Connected): "Dumb" sensors sending raw
data to the Cloud.
• IoT 2.0 (AIoT): "Smart" sensors processing data
locally.
• The Shift: From Data Collection -> Insight Generation.
Why Edge? The
EnergyEquation
• "Transmission is
expensive. Computation
is cheap."
• Fact: Transmitting 1 bit of
data via Wi-Fi consumes
roughly the same energy
as performing 1,000+
computations on-chip.
12.
Audio: The GoldilocksSensor
• Comparison:
• Video: High Power, High Privacy Risk, Line-of-sight only.
• Audio: Low Power, Omnidirectional (hears around corners), High
Information density.
• Use Case: Predictive Maintenance (Hearing a machine break
before it happens).
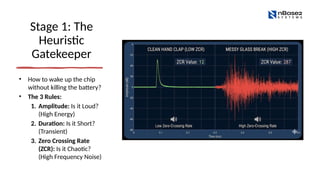
Stage 1: The
Heuristic
Gatekeeper
•How to wake up the chip
without killing the battery?
• The 3 Rules:
1. Amplitude: Is it Loud?
(High Energy)
2. Duration: Is it Short?
(Transient)
3. Zero Crossing Rate
(ZCR): Is it Chaotic?
(High Frequency Noise)
16.
The Limit ofSimple Math
• The Coin vs. Glass Problem
– Problem: Dropping a bag of coins vs. Breaking a window.
– Similarities: Both are Loud, Short, and Chaotic (High ZCR).
– Result: Simple math fails. We need Pattern Recognition.
17.
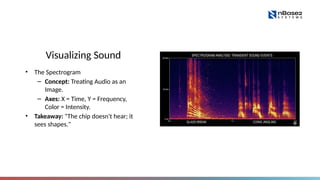
Visualizing Sound
• TheSpectrogram
– Concept: Treating Audio as an
Image.
– Axes: X = Time, Y = Frequency,
Color = Intensity.
• Takeaway: "The chip doesn't hear; it
sees shapes."
18.
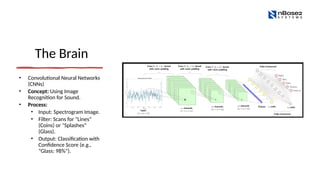
The Brain
• ConvolutionalNeural Networks
(CNNs)
• Concept: Using Image
Recognition for Sound.
• Process:
• Input: Spectrogram Image.
• Filter: Scans for "Lines"
(Coins) or "Splashes"
(Glass).
• Output: Classification with
Confidence Score (e.g.,
"Glass: 98%").
Machine Learning
• DifferentSurfaces: Wood, concrete, tile, carpet.
• Different Distances: Close to the mic, far away.
• Different Intensities: A single coin vs. a whole handful.
The Engineering Challenge
•Fitting a Brain on a Button
• Constraint:
• Cloud Model: Gigabytes of VRAM, Infinite Power.
• Edge Chip: Kilobytes of SRAM, Coin Battery.
• The Risk: Direct deployment kills the battery instantly.
23.
Solution A -Quantization
• Technique: Converting FP32 (32-bit Float) -> INT8 (8-
bit Integer).
• Benefit:
• Size: 4x Smaller.
• Speed: 10x Faster.
• Accuracy Loss: Negligible (<1%).
• Analogy: "Rounding 3.14159 to 3.14. It’s less precise,
but easier to calculate."
24.
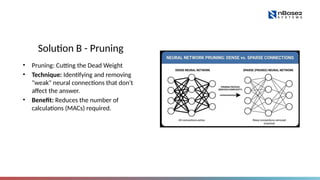
Solution B -Pruning
• Pruning: Cutting the Dead Weight
• Technique: Identifying and removing
"weak" neural connections that don't
affect the answer.
• Benefit: Reduces the number of
calculations (MACs) required.
Generative AI atthe Edge
• Shift: From Classification ("Is this a dog?") ->
Generation ("Create a response").
• Application: Offline Voice Assistants, Real-time
Translation, Speech Reconstruction.
27.
Summary
• Recap:
1.Why: Latency& Privacy drive us to the Edge.
2.How: Spectrograms & CNNs allow chips to "see" sound.
3.Tool: Quantization & Pruning make it fit.
28.
"We are buildinga world where objects don't just connect
—they perceive. And that revolution is happening on the
silicon, at the edge, right now."
#1 Hello All, good evening.
I am Guhan Ganesamurthi, Director of nBase2 Systems Pvt Ltd.
Today I will be talking about AI Integrated IoT Systems, also known as Edge AI. And I will specifically talking about audio related applications.
Hence the title, the Audio Edge.
#2 Before I jump into the topic, I would like to give a background on what we do as a company. This is mainly to give you a context, so that you will understand why I have chosen audio domain to explain AI in IoT.
<read slide contents>
#6 Because of experience with semi conductor companies working in the audio domain, I have chosen to discuss about Edge AI use cases in Audio.
As I understand this is a larger audience with various levels of experience, I am planning to talk only about the basic and the big picture stuff. I don't want to deep dive into machine learning or neural networks, as they are too vast a topic to be discussed in a short duration.
I would like to discuss three main items,
- Why AI is required in IoT devices
- How AI is run on IoT devices
- What tools/techniques are broadly used
#7 Think of traditional IoT (Internet of Things) like a nervous system 🧠.
It has nerves (sensors) that feel things—temperature, sound, vibration—and sends that signal all the way to the brain (the Cloud) to decide what to do.
AIoT puts a mini-brain directly on the nerve ending. The device doesn't just send data; it processes it and makes decisions right there.
#8 There are three main reasons the industry is desperate to make this shift. Let's look at them:
Latency (Speed) ⚡: The Cloud is far away. Even at fiber speeds, sending data there, processing it, and sending an answer back takes time (milliseconds matter!).
Imagine if every time you touched a hot stove, your hand had to send a letter to your brain asking "Should I let go?" and wait for a reply. You'd get burned. Edge AI is like your spinal cord reflex—it reacts instantly.
Privacy 🔒: People are getting nervous about devices recording them.
If a smart speaker sends every sound to a server, that's a privacy risk.
If the chip processes the voice locally and never sends the audio out, users feel safer.
Bandwidth & Power 🔋: Data is heavy. Streaming high-definition audio or video 24/7 eats up incredible amounts of electricity and data (bandwidth). It's cheaper and more energy-efficient to process it on the device and only send a signal when something important happens.
imagine you are designing a smart baby monitor.
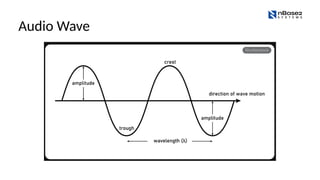
#14 Imagine you are monitoring a quiet room waiting for a window to break. Before the break, the room is silent. Then suddenly—CRASH!
If you were watching the waveform of that sound in real-time, what would happen to the height of the wave at the exact moment the glass breaks?
When that loud CRASH happens, the wave gets much taller instantly. The amplitude spikes.
The chip doesn't "see" a wavy line like we do. It reads a stream of numbers that represent that height, thousands of times a second.
It looks like this to the chip: 3, 5, 2, 4, 250, 890, 400, 5, 3...
To keep the chip energy-efficient, we don't want it analyzing the "3, 5, 2" parts. We only want it to wake up for the big numbers. We call the specific number that triggers the system a Threshold.
If we set our Threshold at 100, what simple logical rule would you give the chip to decide when to wake up?
"Wake up if the number is less than 100."
"Wake up if the number is greater than 100.”
Duration:
Think about the difference in time:
The Fan: It goes "Hmmmmmmmm..." continuously. It doesn't stop. ⏳
The Glass Break: It goes "CRASH!" and then silence. It is over in a split second. ⚡
If you looked at a timeline of these two sounds, the fan would be a long, flat line of noise, while the glass break would be a very short, sharp spike.
So, if we want our chip to ignore the fan but catch the break, we can tell it to look for Short Duration sounds.
#15 While a hand clap is usually a single, clean "pop," shattering glass is chaotic. As you said, it has multiple mini-bursts as the glass cracks, hits the floor, and pieces collide.
To a computer chip, this "chaos" looks like the signal is jumping up and down incredibly fast. We call this High Frequency noise.
To differentiate the "clean" clap from the "messy" glass, we use a metric called Zero Crossing Rate (ZCR).
Imagine drawing a horizontal line through the center of the wave.
Low Frequency (Smooth sound): The wave crosses the line slowly. 〰️
High Frequency (Noisy sound): The wave crosses the line frantically back and forth. 📉📈
So, for our Glass Break Detector, we can add a third rule:
Amplitude: Is it loud? (Yes)
Duration: Is it short? (Yes)
Zero Crossing Rate
#16 Our simple rules might confuse the coins with the glass! We need something smarter than simple math rules to tell the difference between "Jingling Coins" and "Shattering Glass."
Once the "Gatekeeper" wakes the chip up, what kind of advanced technology do we need to run next to analyze the sound pattern and make the final decision?
#17 At its core, an AI model is a program that has been trained on a set of data to recognize patterns or make decisions without being explicitly programmed for every specific task.
Think of it like teaching a child to recognize a dog 🐕. You don't give them a rule book with measurements of tails and ears. Instead, you show them lots of pictures of dogs. Eventually, they learn the "pattern" of a dog and can identify one they've never seen before. An AI model does something similar with data.
Since both coins and glass are loud, short, and "hisssy" (high Zero Crossing Rate), a basic detector gets confused. To solve this, we move from simple rules to Pattern Recognition using a tiny AI model.
To do this, the chip needs to "see" the sound. It converts the audio waveform into a visual "heat map" called a Spectrogram.
A Spectrogram plots three things:
X-axis: Time (going left to right).
Y-axis: Frequency (Pitch, low to high).
Color/Brightness: Loudness of that specific pitch at that specific time.
The AI looks at this image almost like a fingerprint scanner.
Think about the sound of a coin dropping. It often has that distinct metallic ringing sound that lingers for a split second.
On a Spectrogram:
The Coin (Tonal): Since it has a specific pitch, it stays at a specific height on the Y-axis. Because it "rings" (lasts for a while), it draws a horizontal line.
The Glass (Noise): A crash has every pitch at once (low thuds and high cracks). This covers the whole Y-axis from top to bottom, but only for a split second. It looks like a vertical splash or a column.
#18 The architecture is called a Convolutional Neural Network, or CNN for short. 🧠
CNNs are famous for "scanning" images to find features.
In a photo of a face: They scan for edges, then eyes, then noses.
In our spectrogram: They scan for those specific shapes we just talked about—horizontal lines (coins) or vertical splashes (glass).
#19 Collecting raw examples is the foundation of any good AI model. In the industry, we call this building your Dataset.
However, just recording "some" sounds isn't quite enough. To make a model that works in the real world (and not just in your quiet lab), we need to think about Variance.
If you only record coins dropping on a soft carpet, the model will learn that "Coins = Soft Thud." If you then drop a coin on a hard tile floor (which makes a sharp ping), the model might get confused and think it's glass!
So, you would want to record:
Different Surfaces: Wood, concrete, tile, carpet.
Different Distances: Close to the mic, far away.
Different Intensities: A single coin vs. a whole handful.
#20 Collecting raw examples is the foundation of any good AI model. In the industry, we call this building your Dataset.
However, just recording "some" sounds isn't quite enough. To make a model that works in the real world (and not just in your quiet lab), we need to think about Variance.
If you only record coins dropping on a soft carpet, the model will learn that "Coins = Soft Thud." If you then drop a coin on a hard tile floor (which makes a sharp ping), the model might get confused and think it's glass!
So, you would want to record:
Different Surfaces: Wood, concrete, tile, carpet.
Different Distances: Close to the mic, far away.
Different Intensities: A single coin vs. a whole handful.
If we just dump 1,000 mixed audio files into the model, it won't know what is what. It would be like handing a student a stack of unmarked photos of cats and dogs and expecting them to figure out the names "cat" and "dog" on their own.
Supervised Learning 🏷️
To teach the model, we use a method called Supervised Learning. This means we act as the "supervisor" or teacher. We have to explicitly tell the model what each example is.
We do this by adding a Label to every single audio file.
File 1 (Audio of crash): Label = "Glass"
File 2 (Audio of ping): Label = "Coin"
File 3 (Audio of crash): Label = "Glass"
#22 We just talked about training that AI model with 1,000 audio files. That usually happens on a massive computer with unlimited power (like a PC with a GPU).
But... we need to shove that brain onto a tiny silicon chip that runs on a battery the size of a button.
If you try to take a massive AI model from a PC and force it directly onto a tiny chip, what is the most likely thing that will happen?
It will run perfectly, just slower.
It won't fit (runs out of memory) or kills the battery instantly.
#23 One of the main ways we do this is called Quantization.
To understand how it works, imagine you need to write down the number 3.1415926535 on a tiny sticky note, but you only have space for 3 digits.
What would you write down to keep the number as accurate as possible?
The model becomes 4x smaller and runs much faster, consuming way less battery. The "cost" is a tiny drop in accuracy (usually less than 1%), just like using 3.14 is slightly less perfect than the full number but still works for building a fence.
#24 magine you have a neural network with thousands of connections. After training, you notice that about 30% of these connections are "weak"—they barely contribute to the final decision. They are like vestigial organs or muscles that are never used.
If you wanted to make the model lighter and faster without hurting its performance, what would you do with those "weak" connections?
The answer is actually simpler than you might think. We do exactly what a gardener does to a rose bush. 🌹
The Solution: Pruning ✂️
If a rose bush has dead or weak branches that aren't producing flowers, a gardener cuts them off. This helps the plant focus its energy only on the healthy, productive branches.
In an AI model, those "weak connections" (the ones with numbers very close to zero) are like dead branches. They consume battery power to calculate, but they don't really change the answer.
So, your software tool performs Pruning. It literally cuts those connections out of the code.
#26 - Imagine you got a restaurents where you see an offline voice assistant, that takes names of the customers and calls them one by one.











































![[DSC Europe 25] Andrej Zdravkovic - AI in Action: Can We Unlock 50% Productiv...](https://cdn.slidesharecdn.com/ss_thumbnails/gb3jwads9ehoagcmmzfz-1-251218084256-bf6869a1-thumbnail.jpg?width=640&height=640&fit=bounds)









































