





![org.apache.spark.SparkException: Job aborted due to stage failure: Task
0.0:0 failed 4 times, most recent failure: Exception failure in TID 6 on
host bottou02-10g.pa.cloudera.com: java.lang.ArithmeticException: / by
zero
$iwC$$iwC$$iwC$$iwC$$anonfun$1.apply$mcII$sp(<console>:13)
$iwC$$iwC$$iwC$$iwC$$anonfun$1.apply(<console>:13)
$iwC$$iwC$$iwC$$iwC$$anonfun$1.apply(<console>:13)
scala.collection.Iterator$$anon$11.next(Iterator.scala:328)
org.apache.spark.util.Utils$.getIteratorSize(Utils.scala:1016)
[...]
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.
org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages
(DAGScheduler.scala:1033)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.
apply(DAGScheduler.scala:1017)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.
apply(DAGScheduler.scala:1015)
[...]](https://image.slidesharecdn.com/sparkslides-150424123253-conversion-gate02/75/Why-is-My-Spark-Job-Failing-by-Sandy-Ryza-of-Cloudera-7-2048.jpg)
![org.apache.spark.SparkException: Job aborted due to stage failure: Task
0.0:0 failed 4 times, most recent failure: Exception failure in TID 6 on
host bottou02-10g.pa.cloudera.com: java.lang.ArithmeticException: / by
zero
$iwC$$iwC$$iwC$$iwC$$anonfun$1.apply$mcII$sp(<console>:13)
$iwC$$iwC$$iwC$$iwC$$anonfun$1.apply(<console>:13)
$iwC$$iwC$$iwC$$iwC$$anonfun$1.apply(<console>:13)
scala.collection.Iterator$$anon$11.next(Iterator.scala:328)
org.apache.spark.util.Utils$.getIteratorSize(Utils.scala:1016)
[...]](https://image.slidesharecdn.com/sparkslides-150424123253-conversion-gate02/75/Why-is-My-Spark-Job-Failing-by-Sandy-Ryza-of-Cloudera-8-2048.jpg)
![org.apache.spark.SparkException: Job aborted due to stage failure: Task
0.0:0 failed 4 times, most recent failure: Exception failure in TID 6 on
host bottou02-10g.pa.cloudera.com: java.lang.ArithmeticException: / by
zero
$iwC$$iwC$$iwC$$iwC$$anonfun$1.apply$mcII$sp(<console>:13)
$iwC$$iwC$$iwC$$iwC$$anonfun$1.apply(<console>:13)
$iwC$$iwC$$iwC$$iwC$$anonfun$1.apply(<console>:13)
scala.collection.Iterator$$anon$11.next(Iterator.scala:328)
org.apache.spark.util.Utils$.getIteratorSize(Utils.scala:1016)
[...]](https://image.slidesharecdn.com/sparkslides-150424123253-conversion-gate02/75/Why-is-My-Spark-Job-Failing-by-Sandy-Ryza-of-Cloudera-9-2048.jpg)



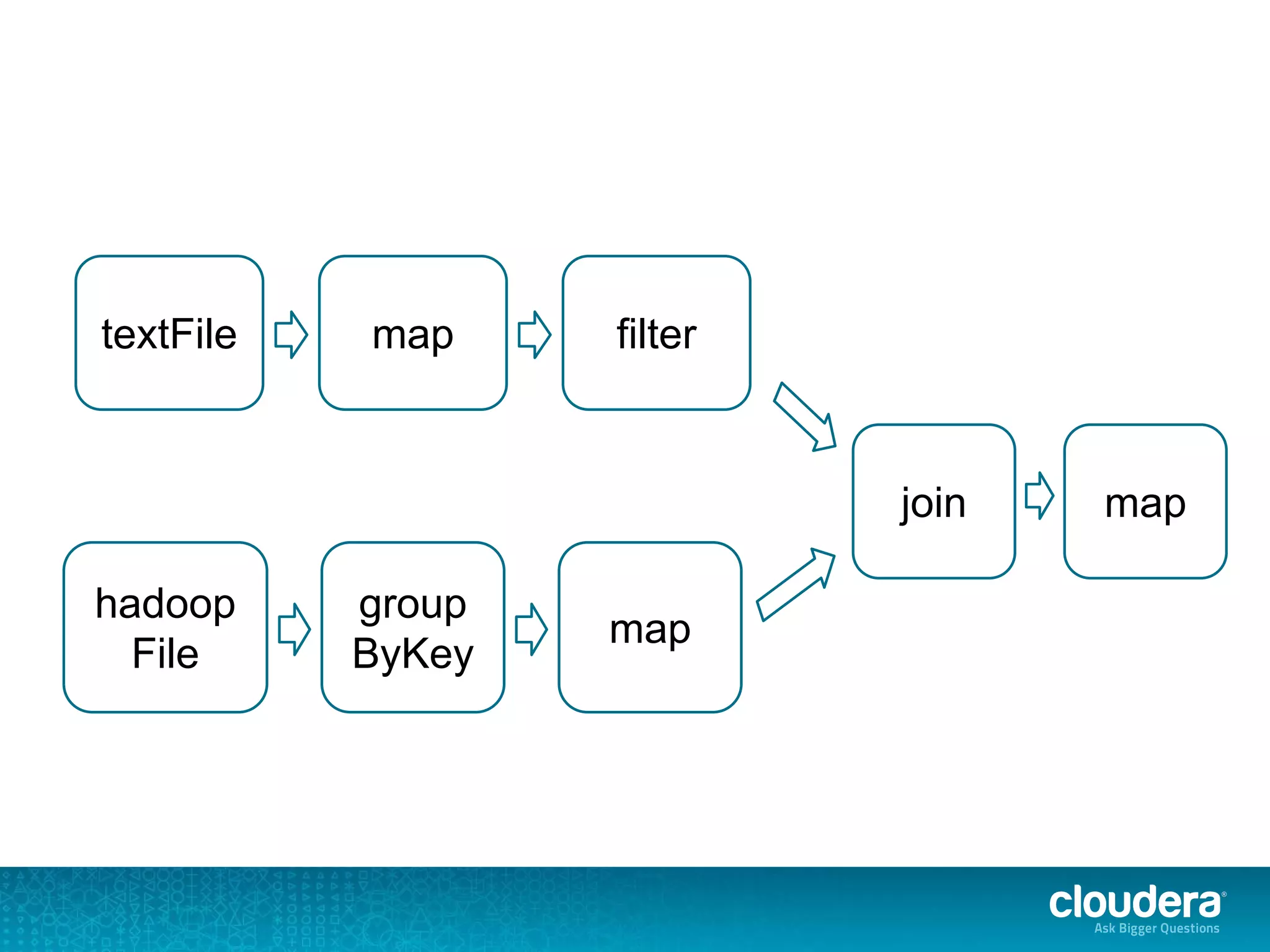
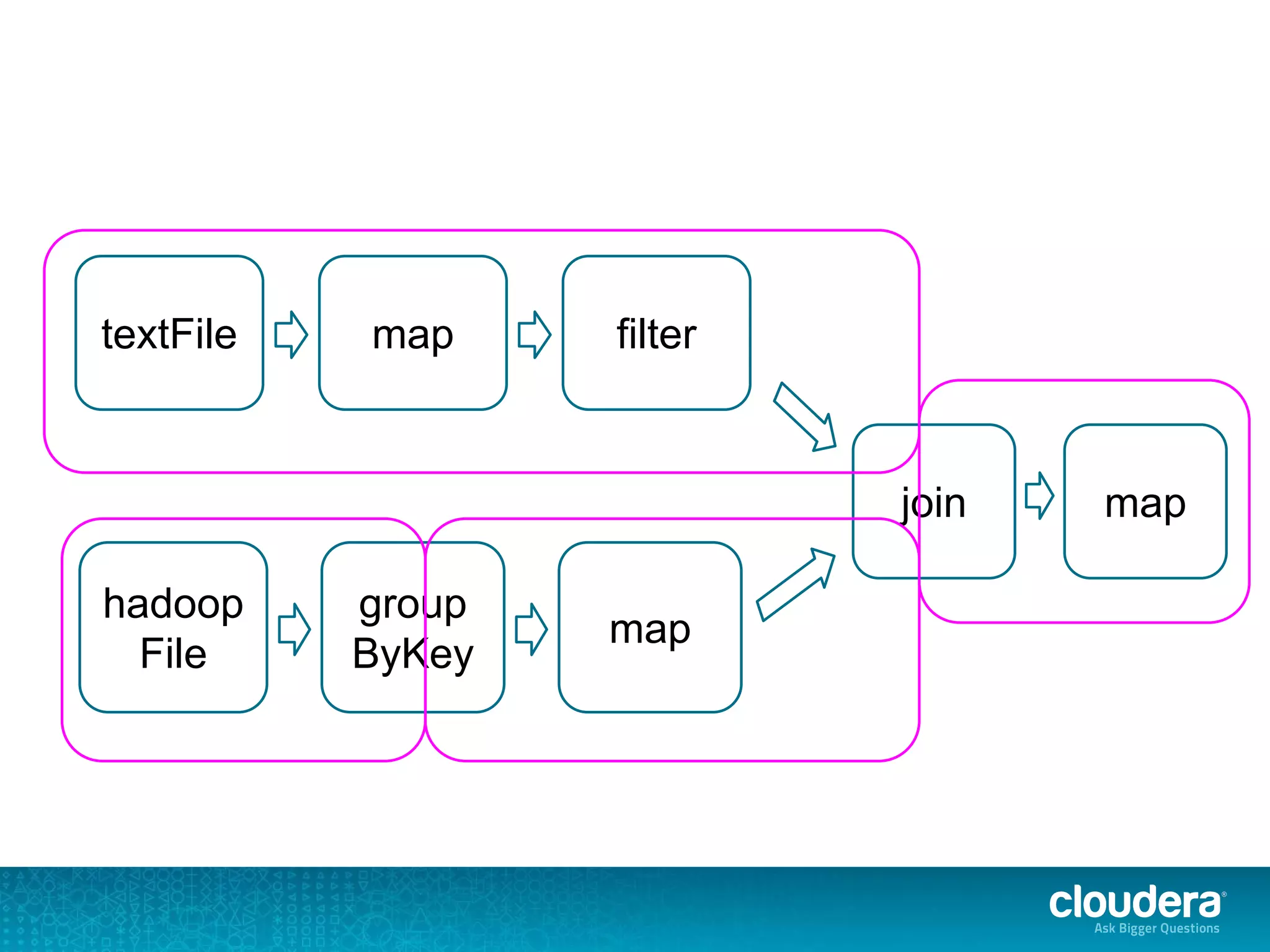
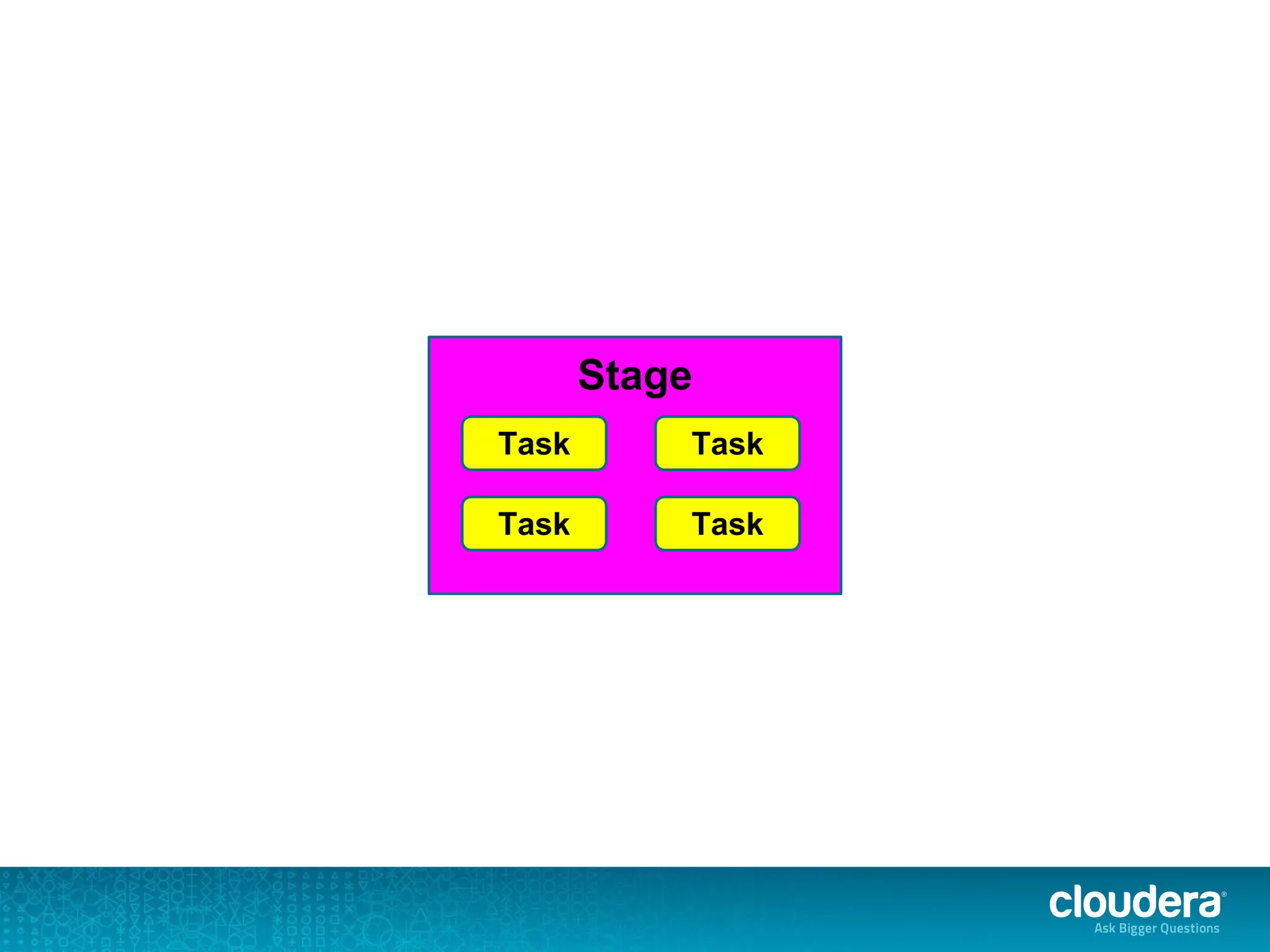

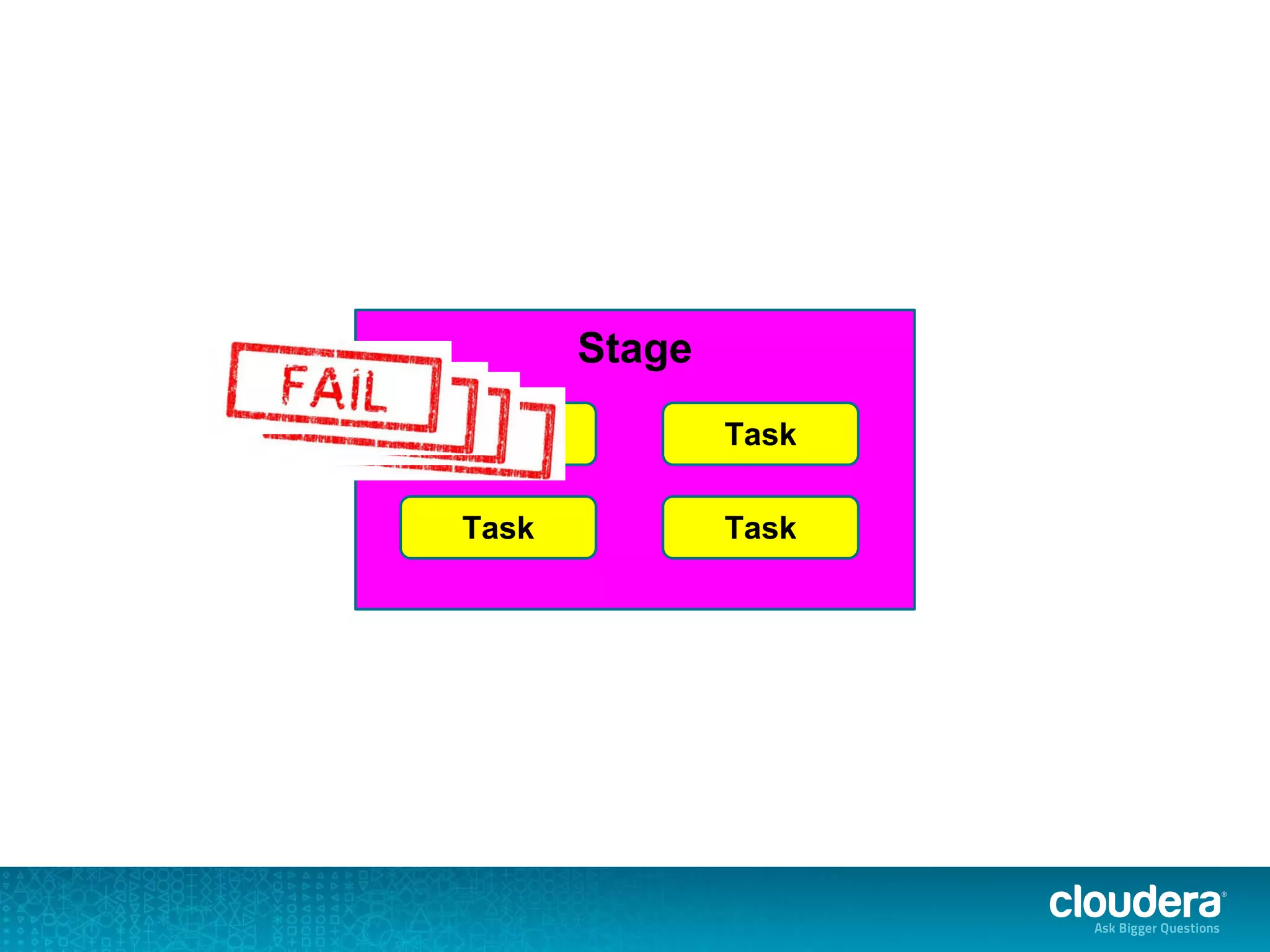
![org.apache.spark.SparkException: Job aborted due to stage failure: Task
0.0:0 failed 4 times, most recent failure: Exception failure in TID 6 on
host bottou02-10g.pa.cloudera.com: java.lang.ArithmeticException: / by
zero
$iwC$$iwC$$iwC$$iwC$$anonfun$1.apply$mcII$sp(<console>:13)
$iwC$$iwC$$iwC$$iwC$$anonfun$1.apply(<console>:13)
$iwC$$iwC$$iwC$$iwC$$anonfun$1.apply(<console>:13)
scala.collection.Iterator$$anon$11.next(Iterator.scala:328)
org.apache.spark.util.Utils$.getIteratorSize(Utils.scala:1016)
[...]](https://image.slidesharecdn.com/sparkslides-150424123253-conversion-gate02/75/Why-is-My-Spark-Job-Failing-by-Sandy-Ryza-of-Cloudera-22-2048.jpg)

![Container [pid=63375,
containerID=container_1388158490598_0001_01_00
0003] is running beyond physical memory
limits. Current usage: 2.1 GB of 2 GB physical
memory used; 2.8 GB of 4.2 GB virtual memory
used. Killing container.](https://image.slidesharecdn.com/sparkslides-150424123253-conversion-gate02/75/Why-is-My-Spark-Job-Failing-by-Sandy-Ryza-of-Cloudera-29-2048.jpg)
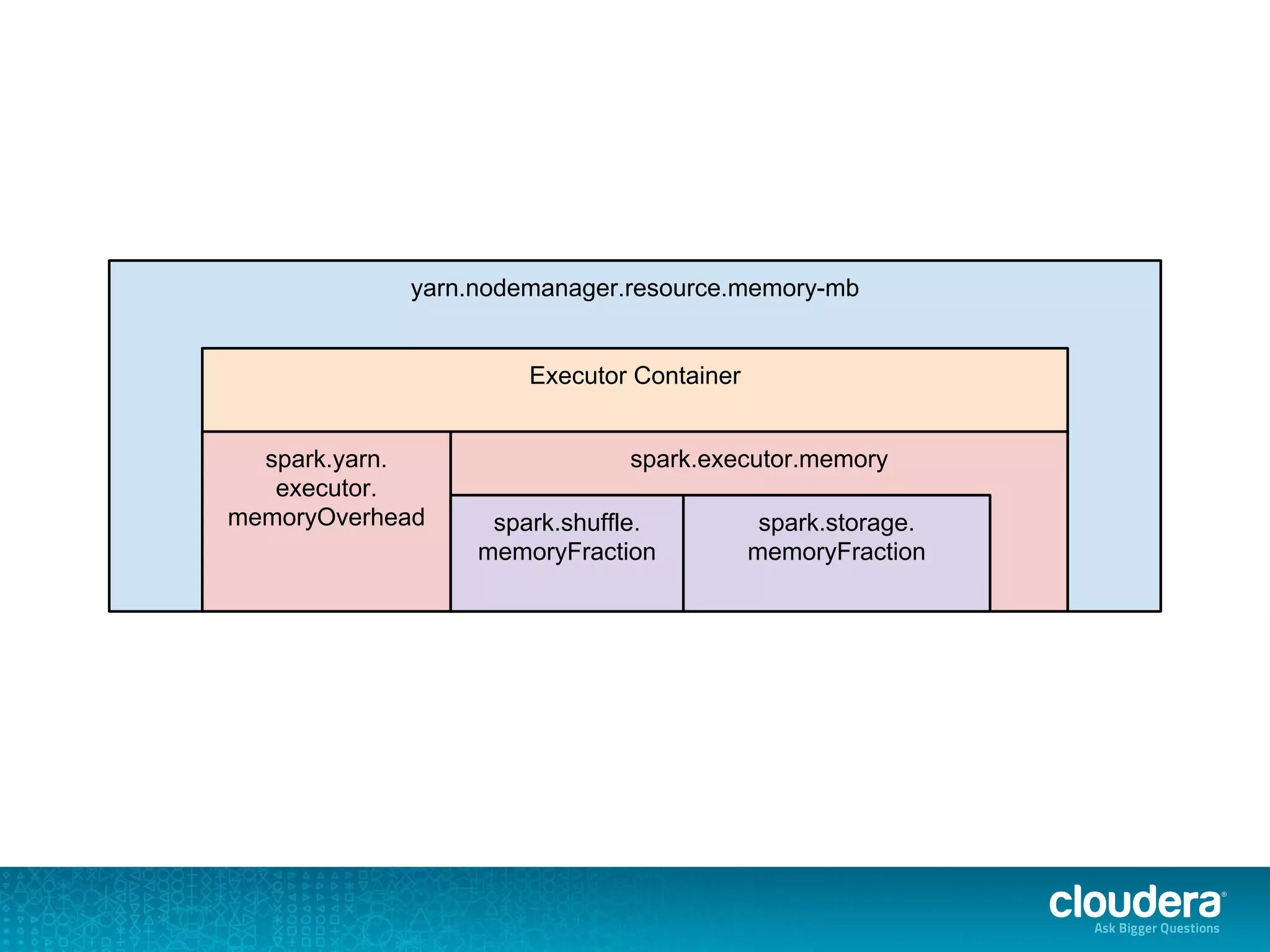




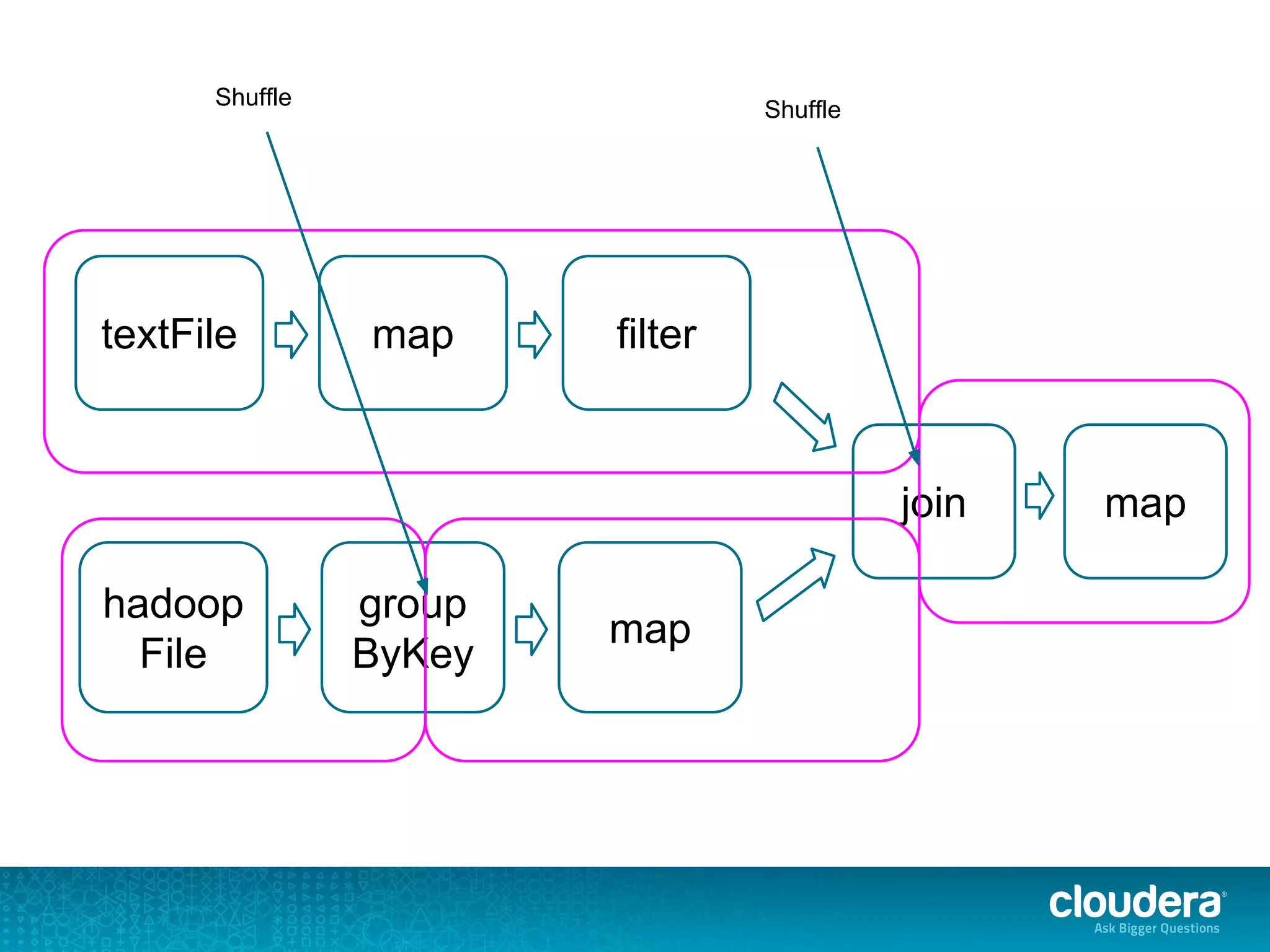


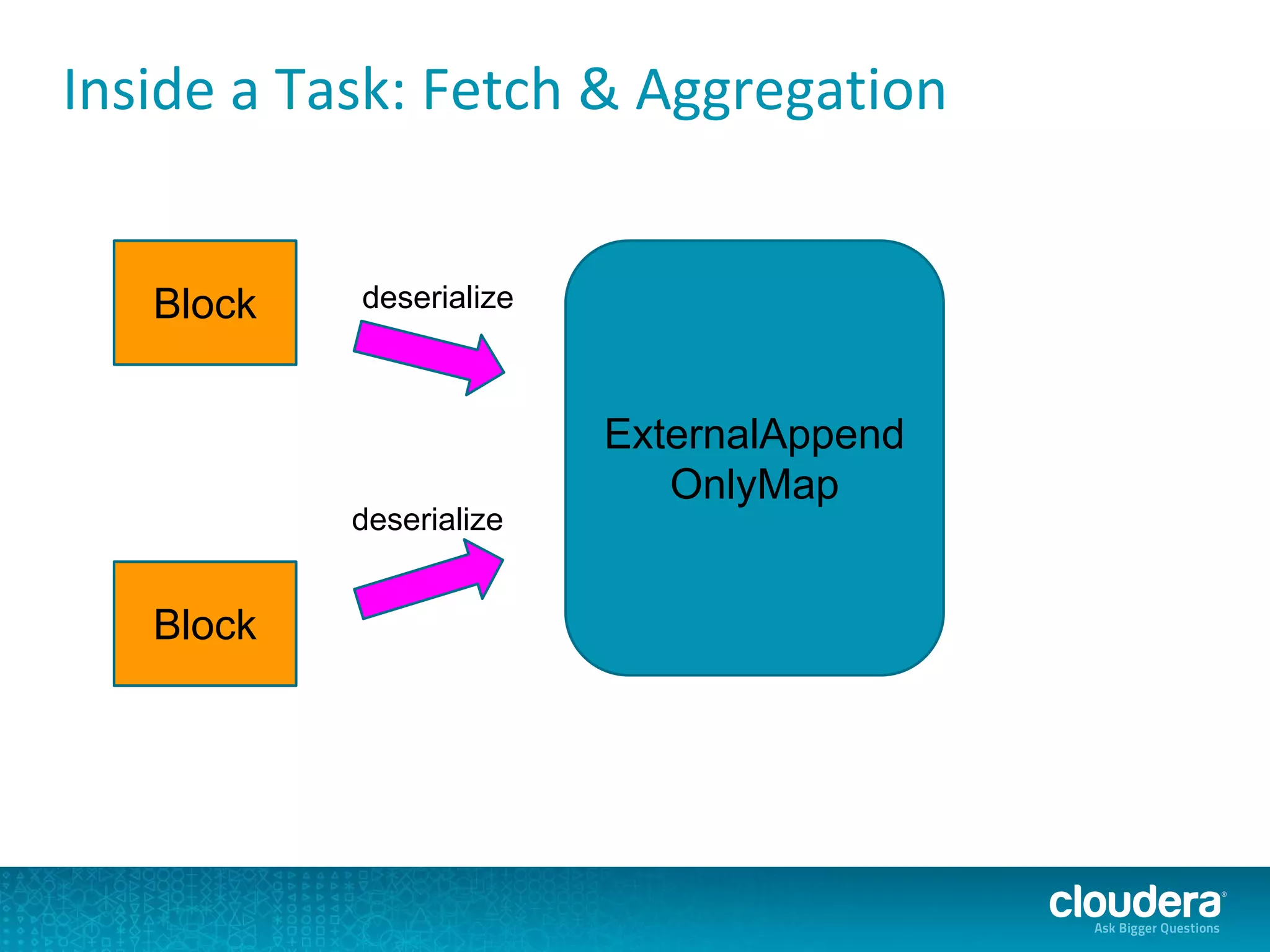
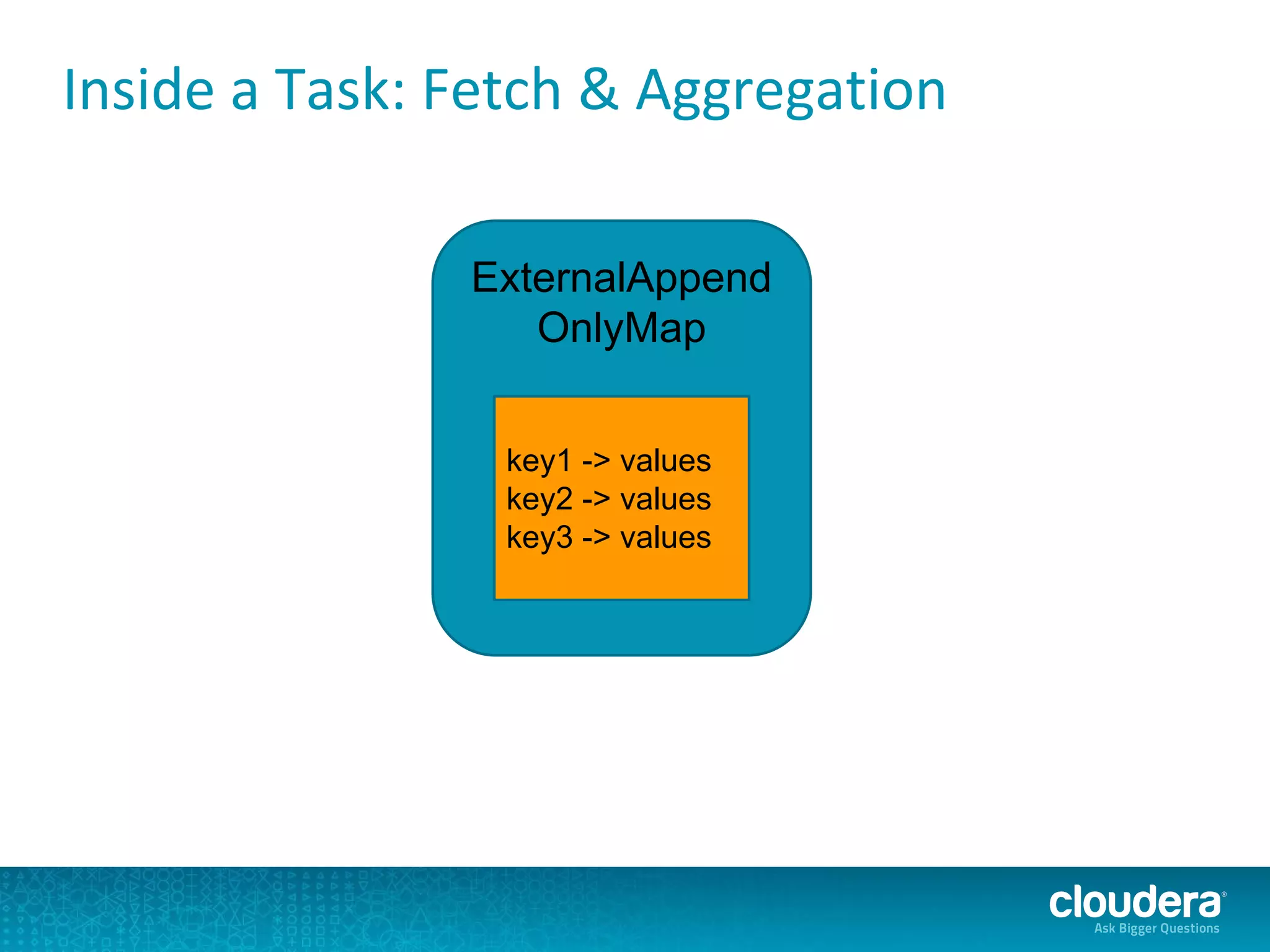

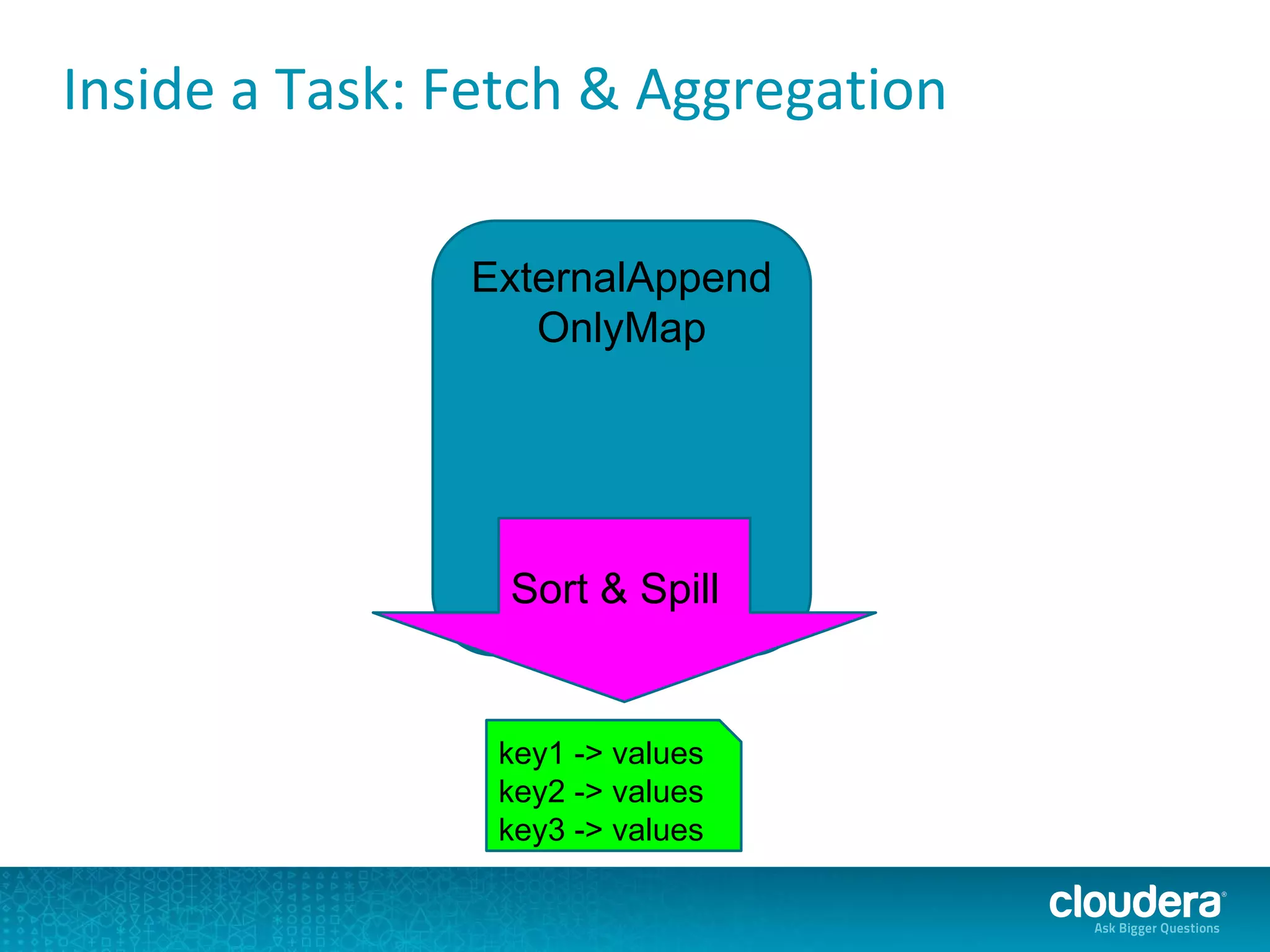






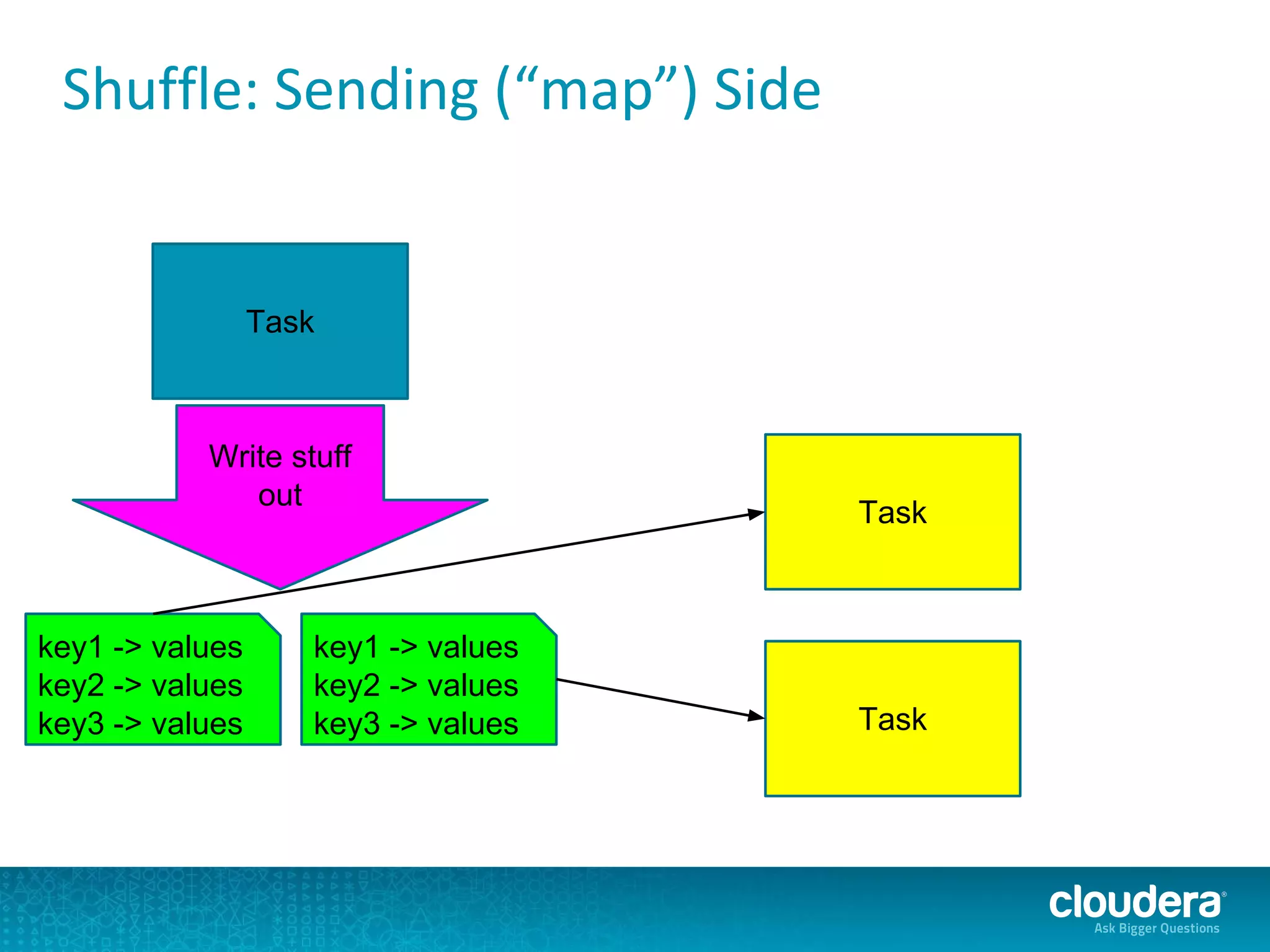
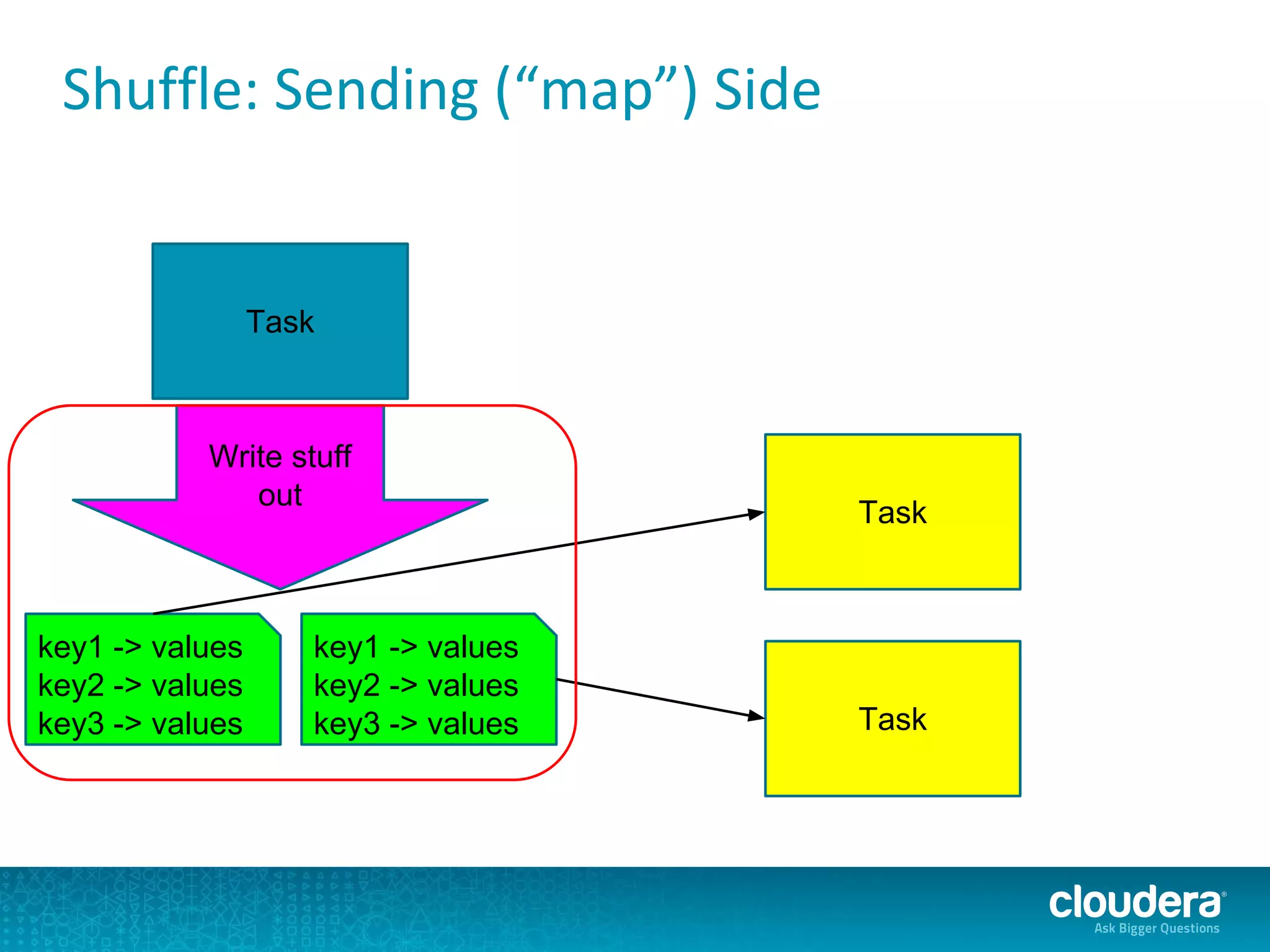
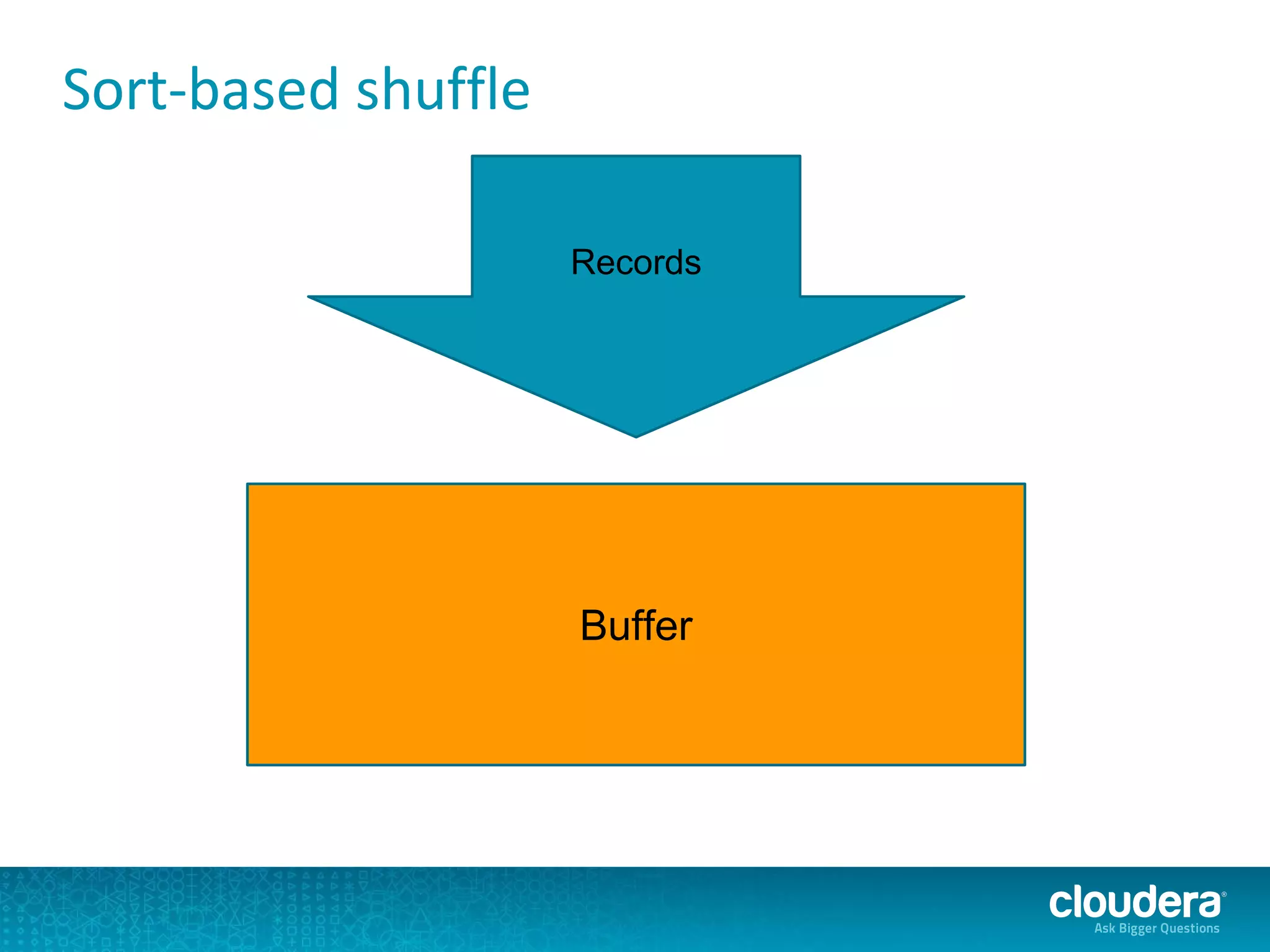
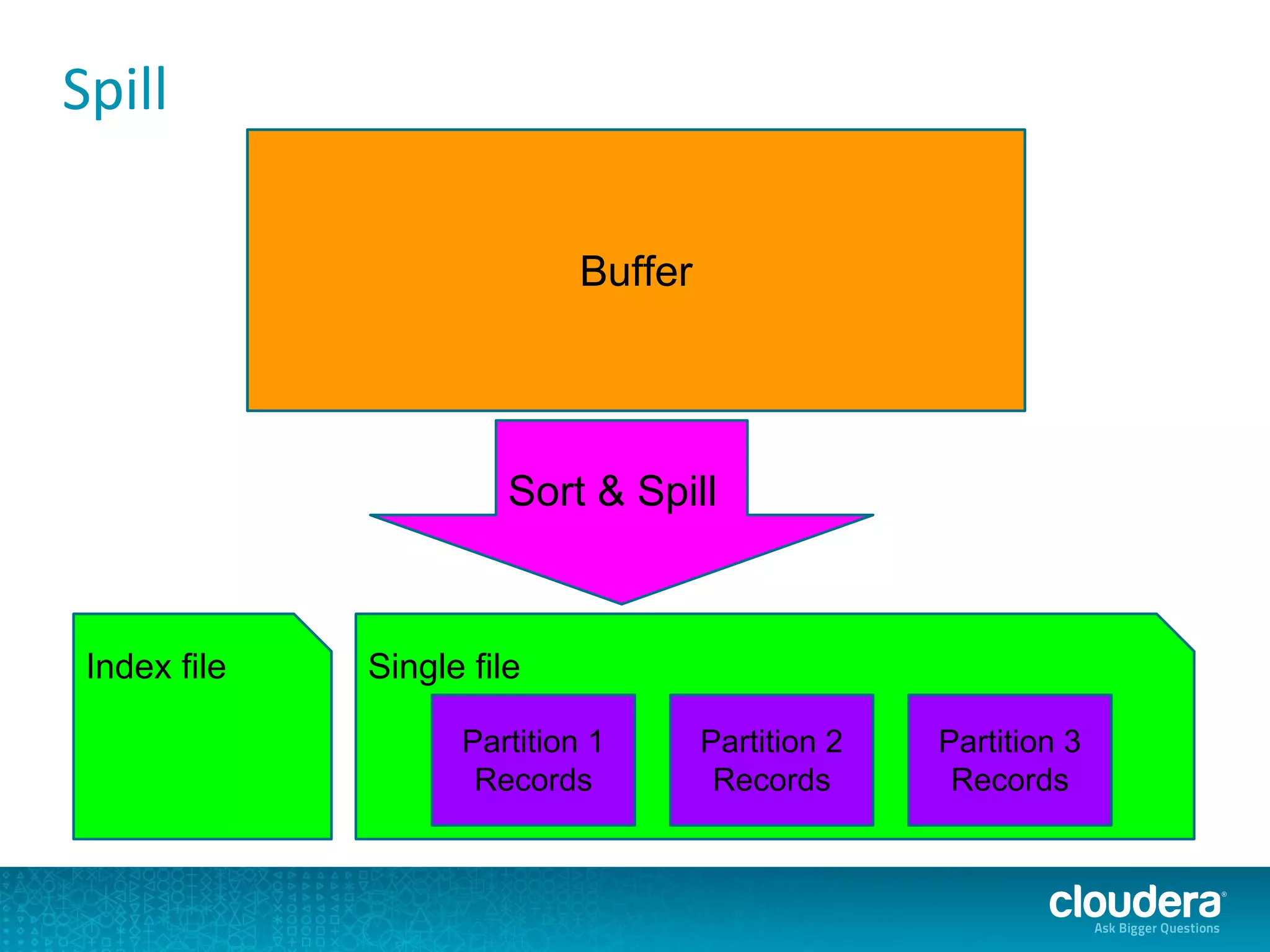


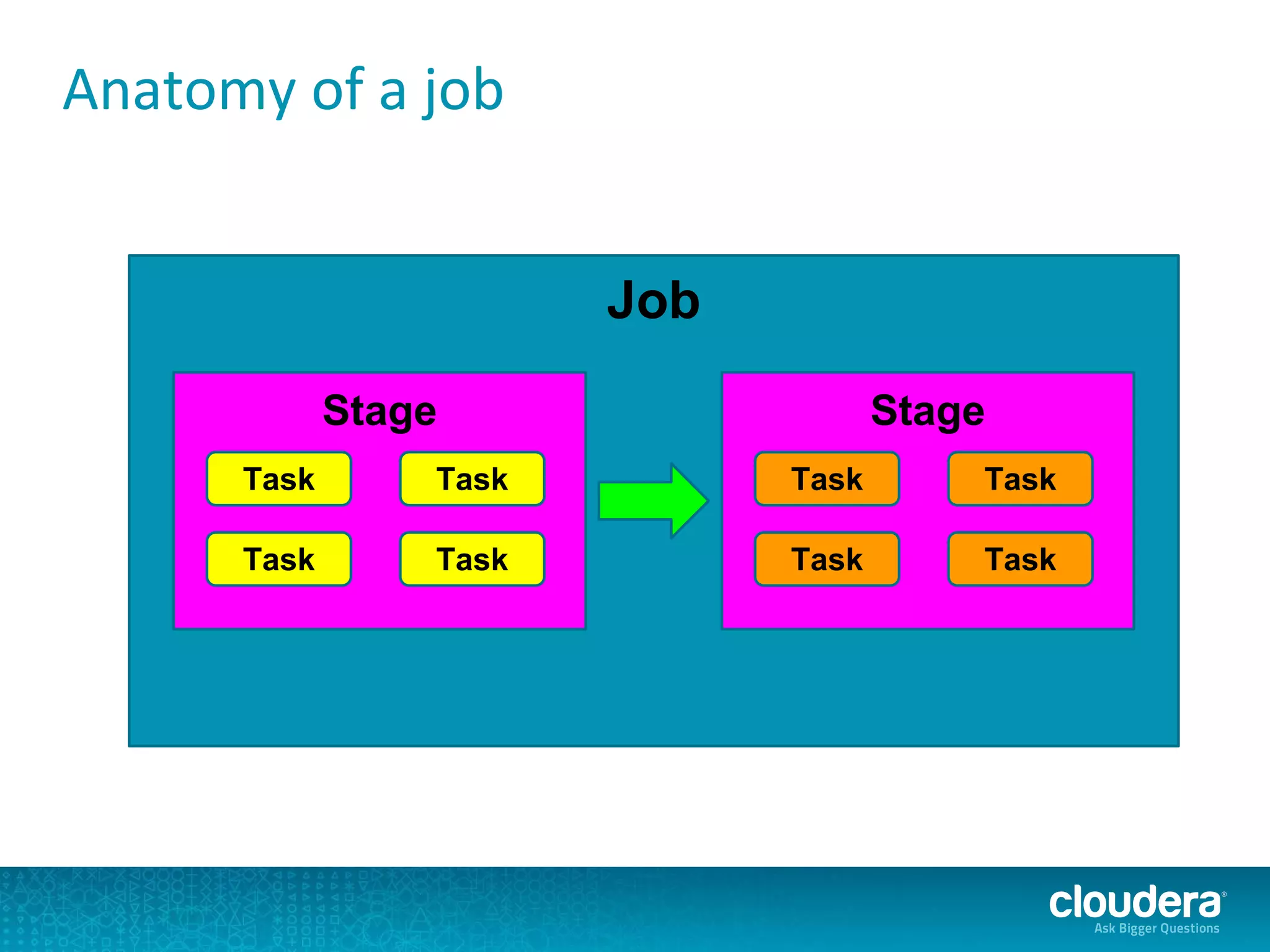
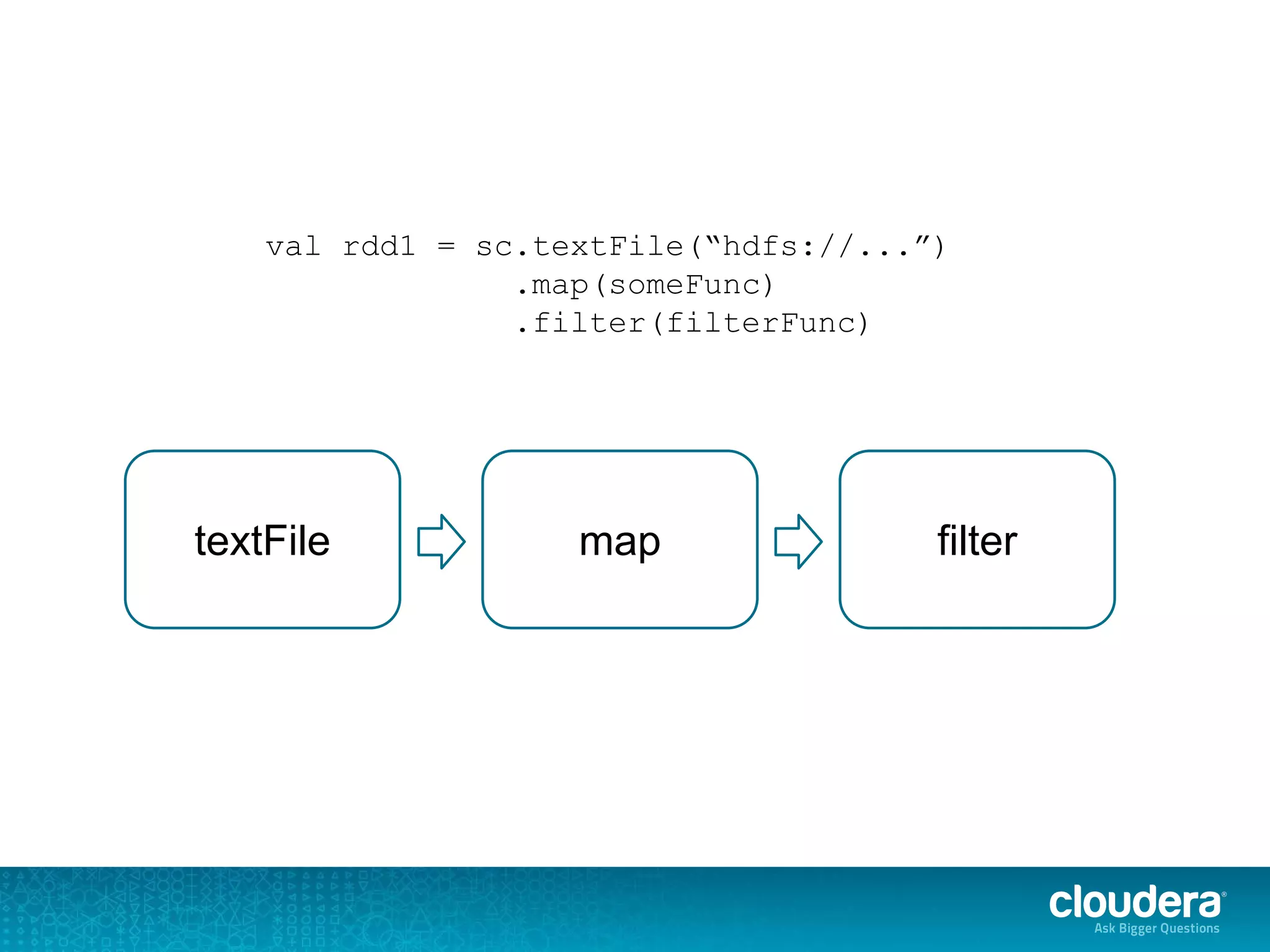
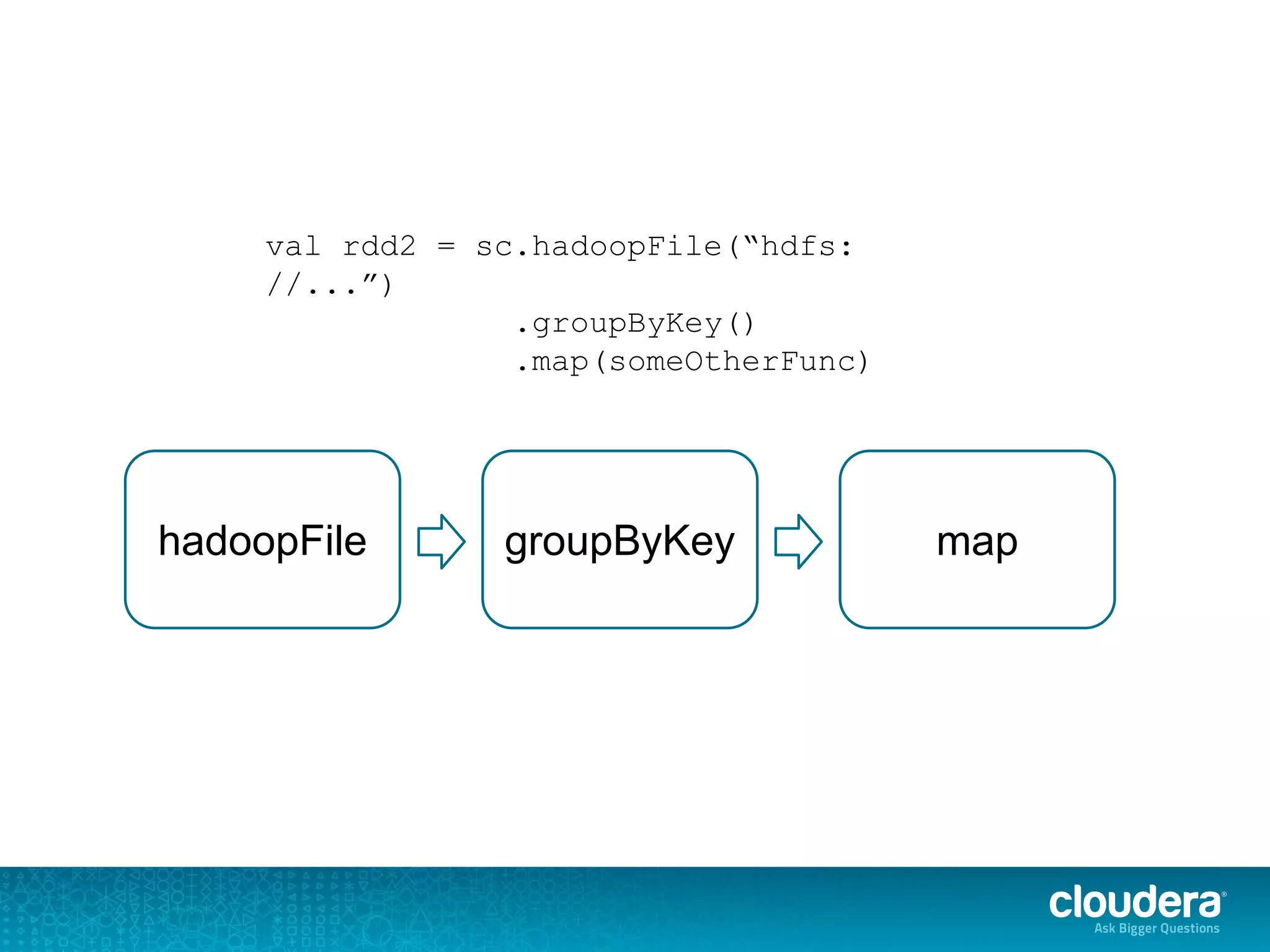
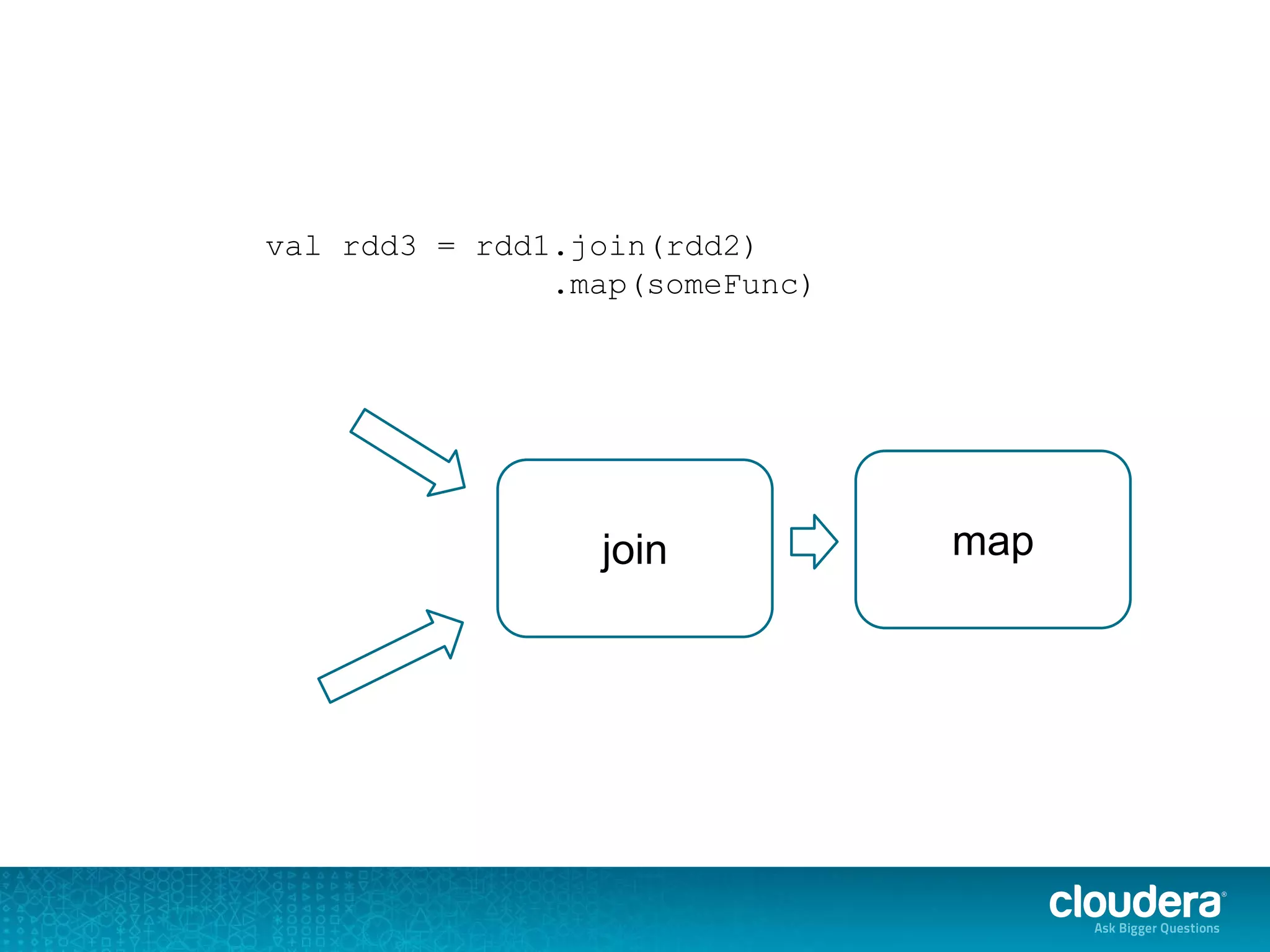
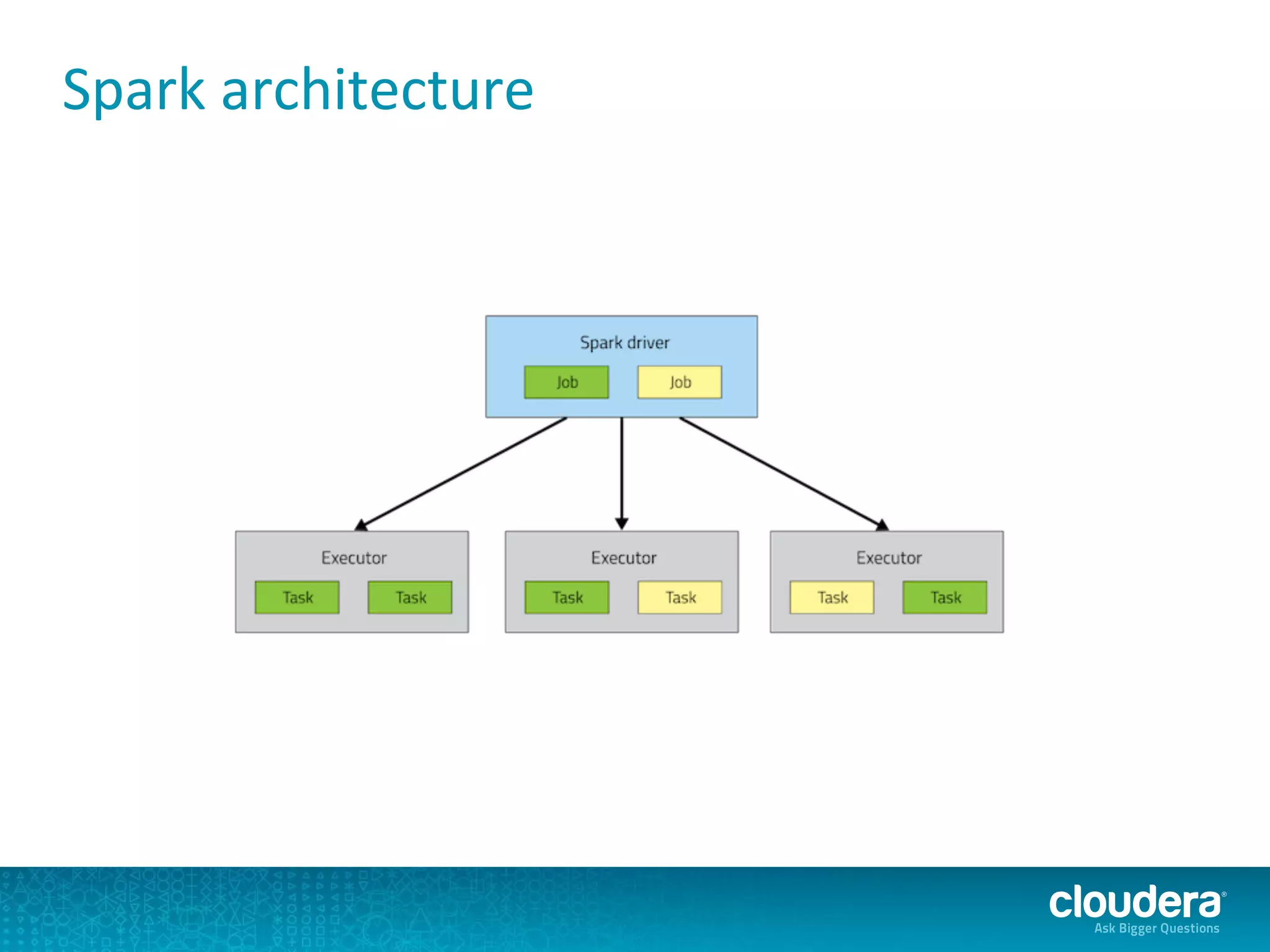
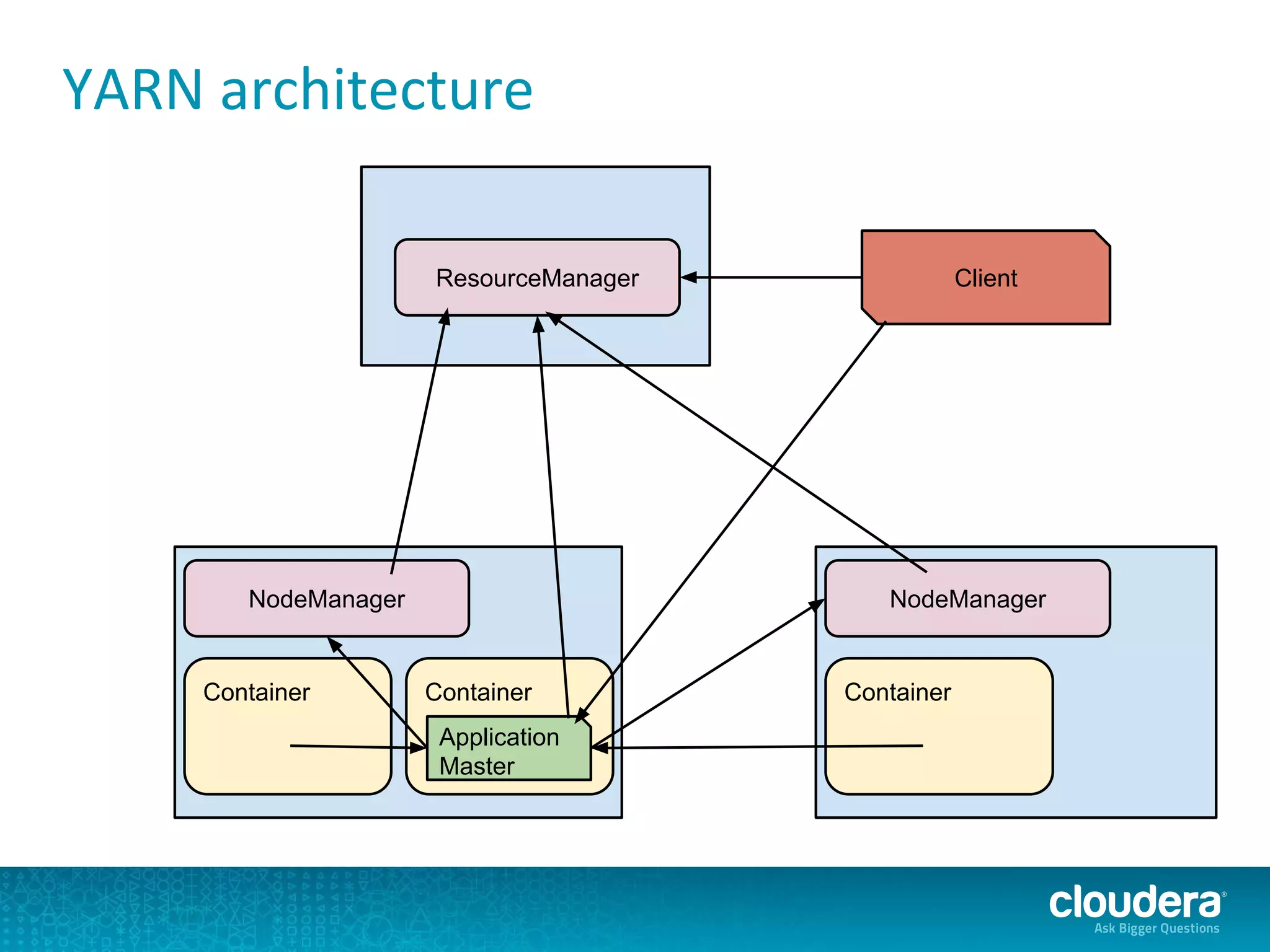
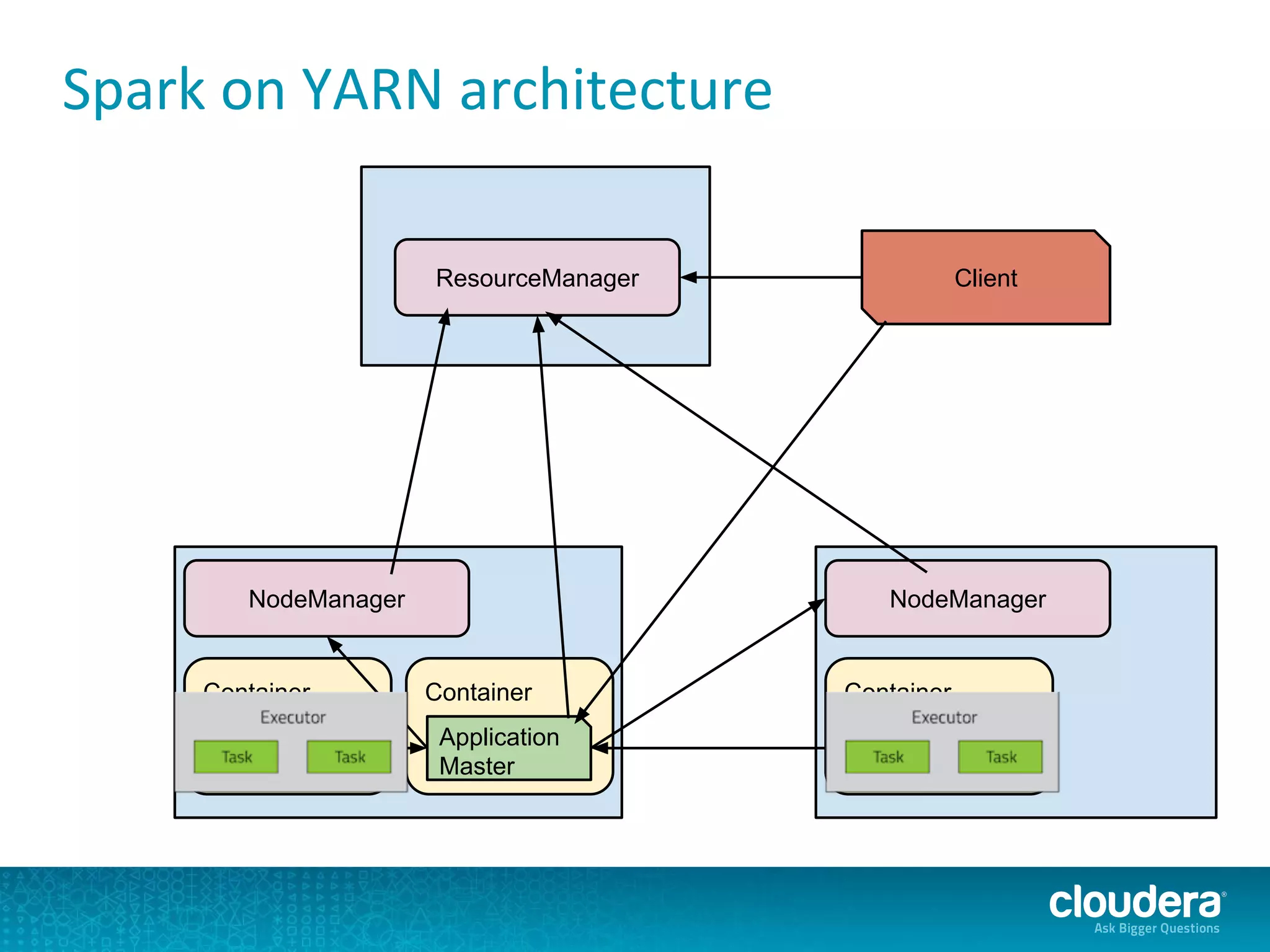
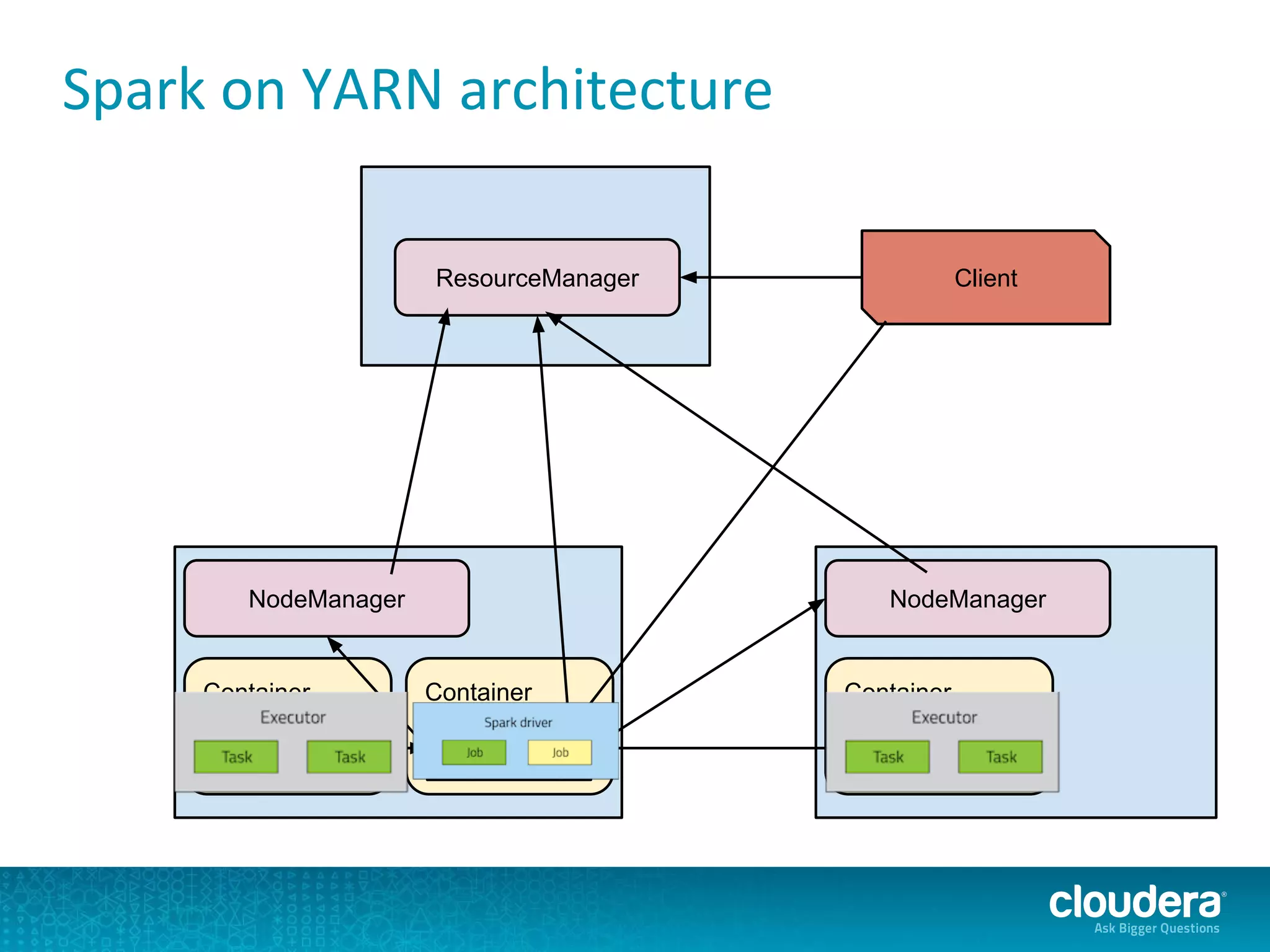
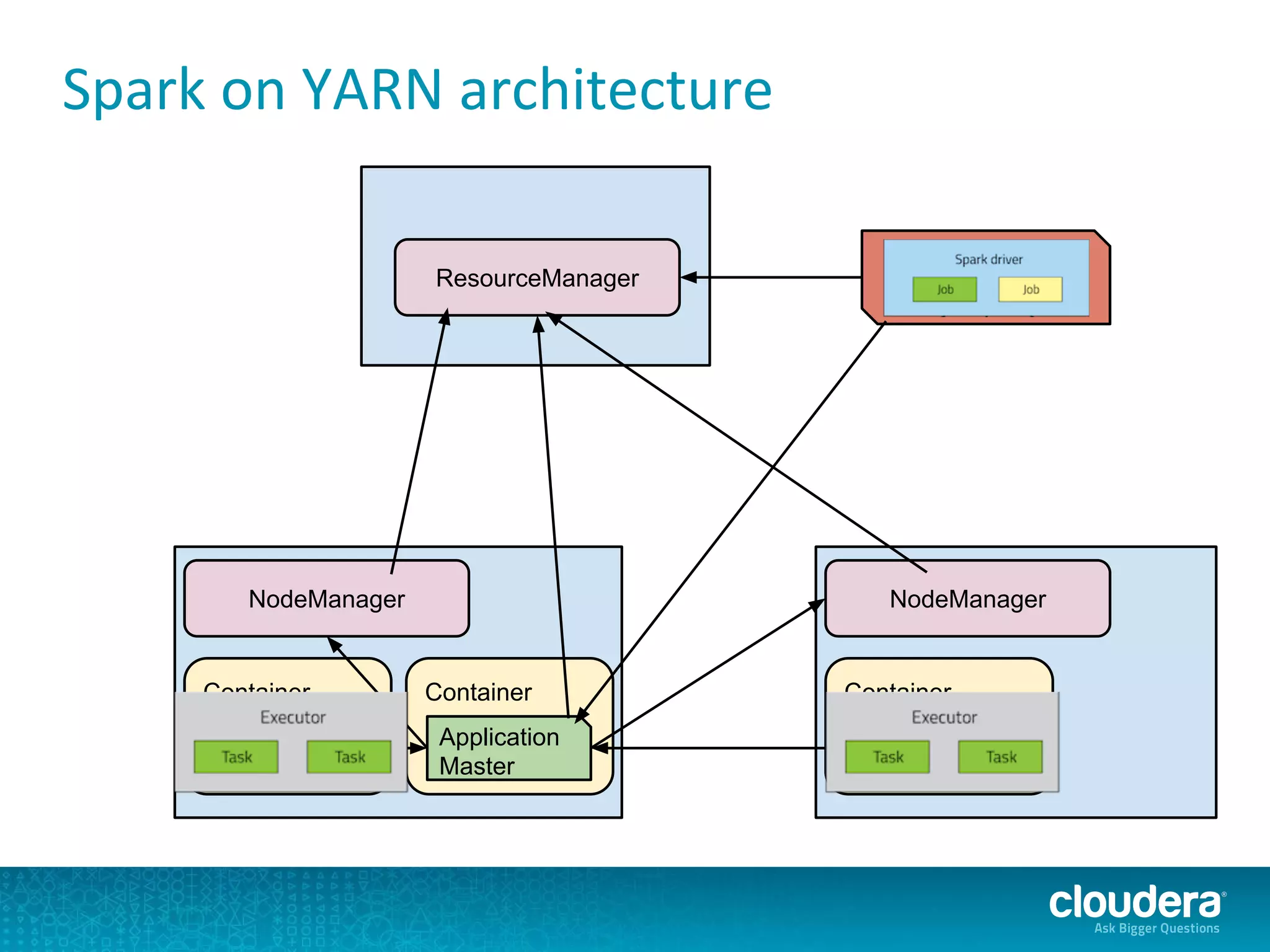
The document discusses issues related to Apache Spark performance, specifically focusing on stage failures and task exceptions that occur during execution, such as Java exceptions related to division by zero and task memory limits. It also touches on Spark's architecture, including components like YARN, and highlights performance challenges, especially during shuffles. Overall, it reflects on common errors and performance bottlenecks that arise in distributed systems using Spark.







































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)





![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







