Download to read offline





![Different perspectives on web archives
• User-centric View
• (Temporal) Search / Information Retrieval
• Direct access / replaying archived pages
• Data-centric View
• (W)ARC and CDX (metadata) datasets
• Big data processing: Hadoop, Spark, …
• Content analysis, historical / evolution studies
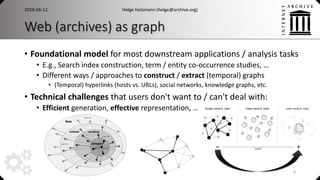
• Graph-centric View
• Structural view on the dataset
• Graph algorithms / analysis, structured information
• Hyperlink and host graphs, entity / social networks, facts and more
2019-06-12 Helge Holzmann (helge@archive.org)
7
[Helge Holzmann. Concepts and Tools for the Effective and Efficient Use of Web Archives. PhD thesis 2019]](https://image.slidesharecdn.com/openrepositories-201906web-data-engineering-190613111519/85/Web-Data-Engineering-A-Technical-Perspective-on-Web-Archives-7-320.jpg)






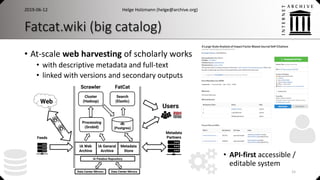


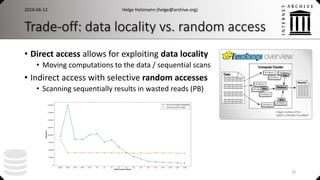

![ArchiveSpark
• Expressive and efficient data access and processing
• Declarative workflows, seamless two step loading approach
• Open source
• Available on GitHub: https://github.com/helgeho/ArchiveSpark
• with documentation, docker image, and recipes for common tasks
• Modular / extensible
• Various DataSpecifications and EnrichFunctions
• ArchiveSpark-server: Web service API for ArchiveSpark
• https://github.com/helgeho/ArchiveSpark-server
• Generalizable for archival collections beyond Web archives
• …
Helge Holzmann (helge@archive.org)2019-06-12
21
[Helge Holzmann, Vinay Goel and Avishek Anand. ArchiveSpark: Efficient Web Archive Access, Extraction and Derivation. JCDL 2016]
[Helge Holzmann, Emily Novak Gustainis and Vinay Goel. Universal Distant Reading through Metadata Proxies with ArchiveSpark. IEEE BigData 2017]](https://image.slidesharecdn.com/openrepositories-201906web-data-engineering-190613111519/85/Web-Data-Engineering-A-Technical-Perspective-on-Web-Archives-21-320.jpg)

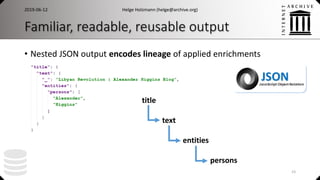





This document discusses web data engineering and processing large web archive datasets. It describes how web archives contain petabytes of archived web pages and metadata that must be efficiently accessed and analyzed at scale. Web data engineering techniques transform this raw data into useful information through methods like extracting graphs and indexes to enable search, while hiding complexity from end users.

































































