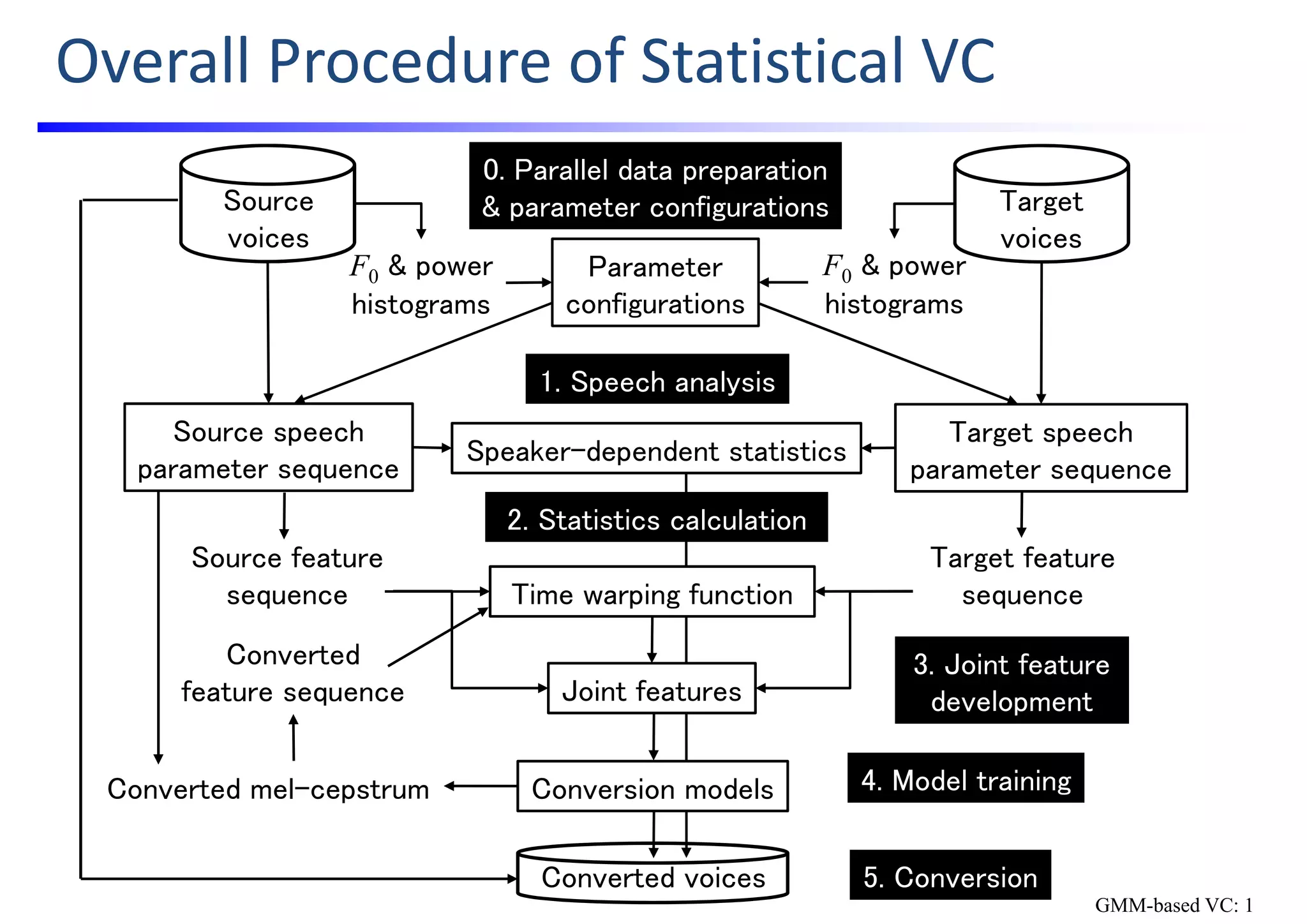
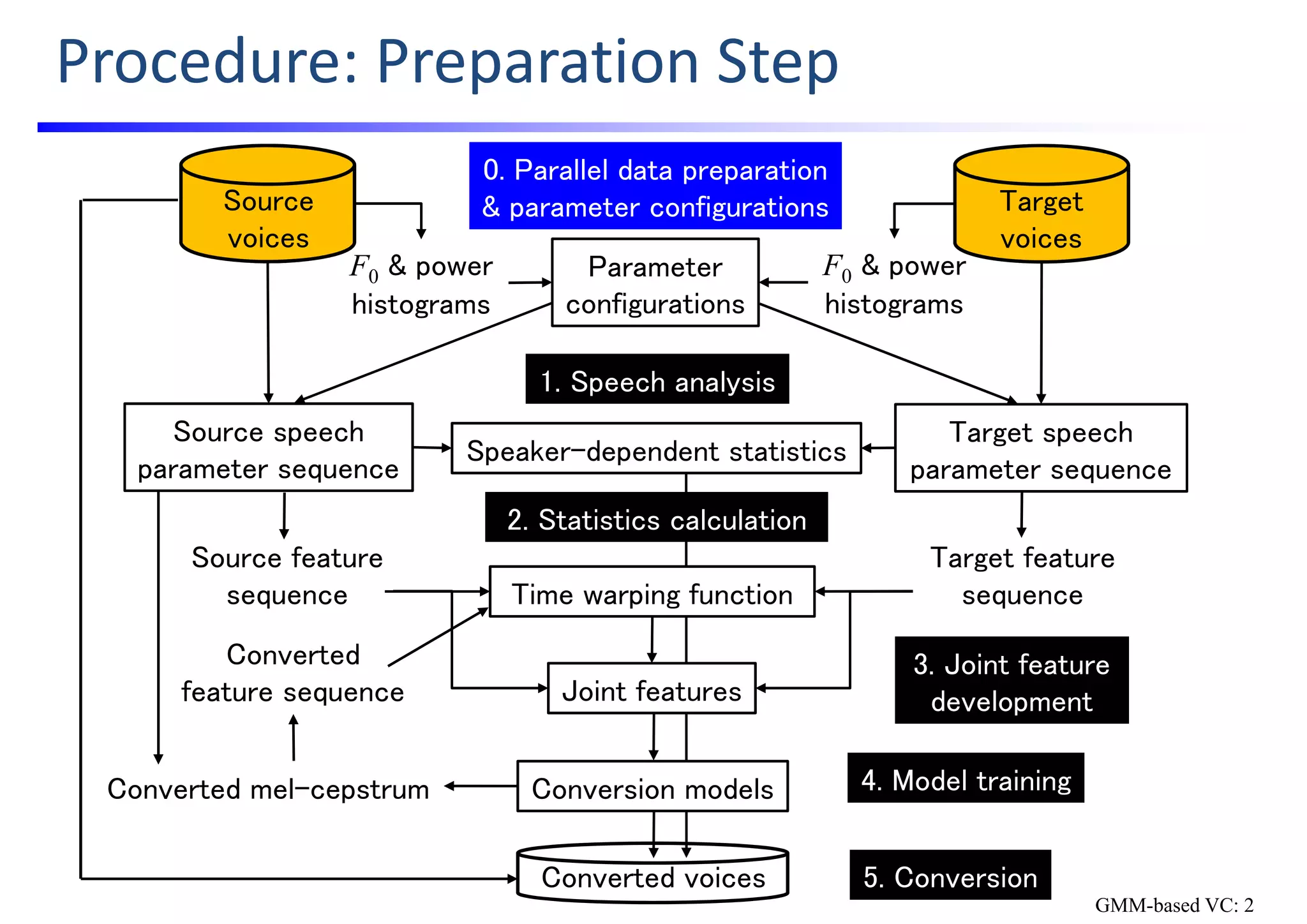
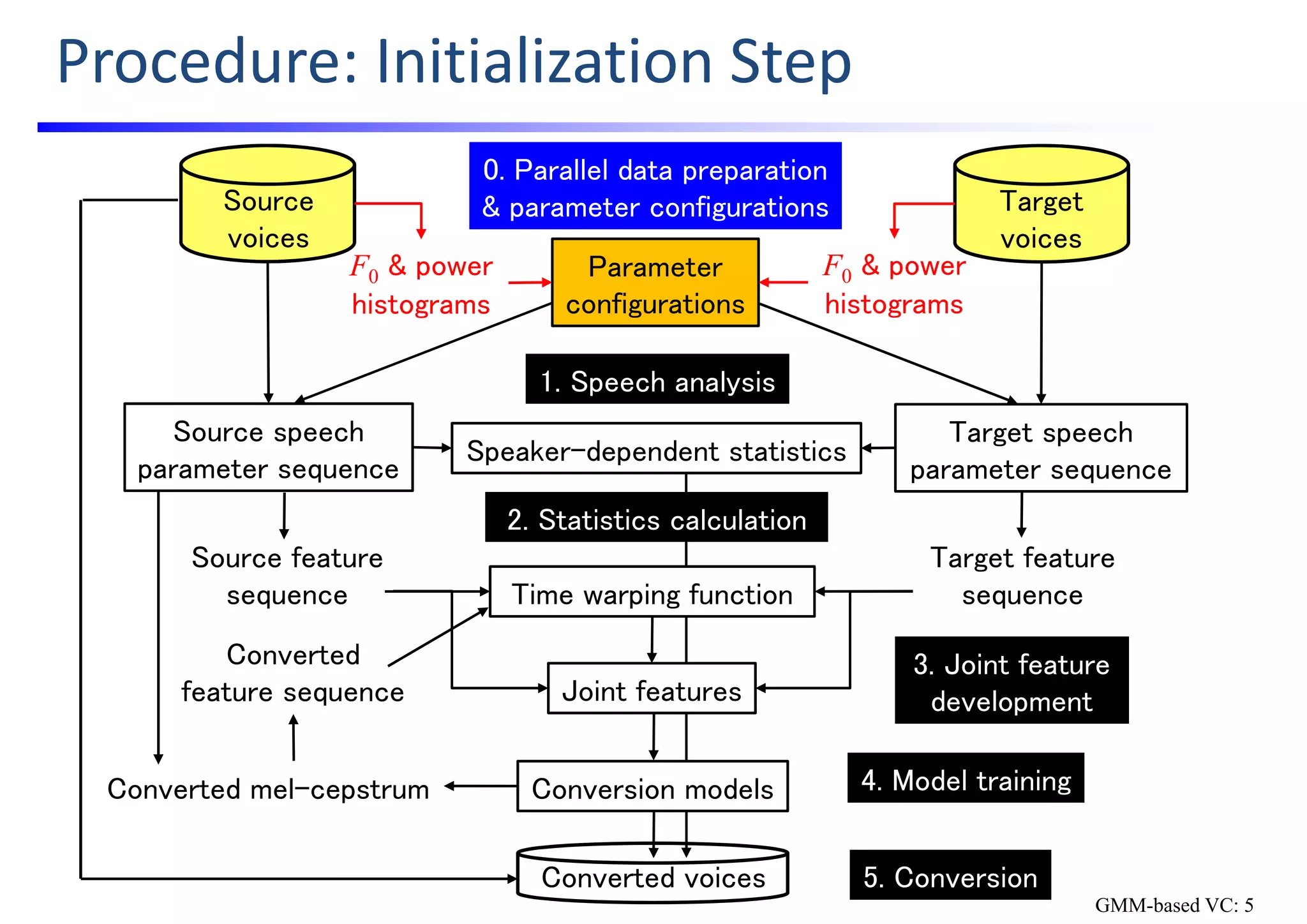
The document outlines a hands-on workshop for developing voice conversion (VC) systems using open-source software called Sprocket, created by Nagoya University. It details the process of building a traditional GMM-based VC and includes instructions for installing the software, preparing datasets, and configuring the system for speaker conversion. The overall goal is to provide participants with the knowledge and tools needed to initiate their own VC research and development.
![Nagoya University, Japan
tomoki@icts.nagoya‐u.ac.jp
Hands on Voice Conversion
July 26th, 2018
Tomoki TODA
100
80
60
40
20
0
1 2 3 4 5
MOS on naturalness
Similarity score [%]
Result of Voice Conversion Challenge 2018
(VCC2018) [Lorenzo‐Trueba; ’18a]
Let’s develop this
baseline system!
Baseline system
Naturalness score = 3.5
Speaker similarity score = 70%](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-1-2048.jpg)

![Let’s use sprocket!
[Kobayashi; ’18a]
K. Kobayashi, T. Toda,
“sprocket: open‐source voice conversion software,”
Proc. Odyssey 2018, pp. 203—210, June 2018.
https://www.isca‐speech.org/archive/Odyssey_2018/pdfs/47.pdf
sprocket](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-3-2048.jpg)
![Open‐Source VC Software: sprocket
• Developed by Dr. Kazuhiro Kobayashi of Nagoya University, JAPAN
• Motivation: provide an environment for both expert and
non‐expert users to easily use statistical VC framework
• Simply developed using existing libraries
• Implemented know‐how accumulated through our VC research (> 15 years)
• Freely available for both research and industrial purposes (MIT license)
• Used as a baseline system for Voice Conversion Challenge 2018 (VCC2018)
• Features:
• Traditional VC method based on GMM
• Vocoder‐free VC method based on DIFFGMM
• Supply Python3 VC library
• What we can do using sprocket?
• Can easily reproduce converted voices using VCC2016 & VCC2018 datasets
[Toda; ’16][Lorenzo‐Trueba; ’18b]
• Can develop VC system using other parallel speech datasets
[Lorenzo‐Trueba; ’18a]
sprocket: 1](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-4-2048.jpg)



![Let’s develop traditional
GMM‐based VC system!
[Toda; ’07]
T. Toda, A.W. Black, K. Tokuda,
“Voice conversion based on maximum likelihood estimation of spectral parameter trajectory,”
IEEE Transactions on Audio, Speech, and Language Processing,
Vol. 15, No. 8, pp. 2222—2235, 2007.
GMM-based VC](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-8-2048.jpg)

![Example of Speech Dataset
• In this session, let’s use a part of VCC2018 database [Lorenzo‐Trueba; ’18b].
• Sampling frequency: 22.05 kHz
• Only speakers for parallel training
• Only 60 out of 81 training utterances and 20 out of 35 evaluation utterances
• Note: The following wav files have already been set in your computer.
data/wav/{SF1, SF2, SM1, SM2}/ # 4 source speakers
data/wav/{TF1, TF2, TM1, TM2}/ # 4 target speakers
10001.wav – 10060.wav # 60 utterances for training
30001.wav – 30020.wav # 20 utterances for evaluation
• Let’s check each speaker’s voice by listening to some wav files, e.g.,
data/wav/SF1/10001.wav & data/wav/TF1/10001.wav
data/wav/SM1/30001.wav & data/wav/TM1/30001.wav
: :
GMM-based VC: 4
You can download VCC2018 database by executing
$ python3 download_speech_corpus.py downloader_conf/vcc2018.yml
and use it. Note that speaker names are slightly different from those shown in these slides.](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-12-2048.jpg)



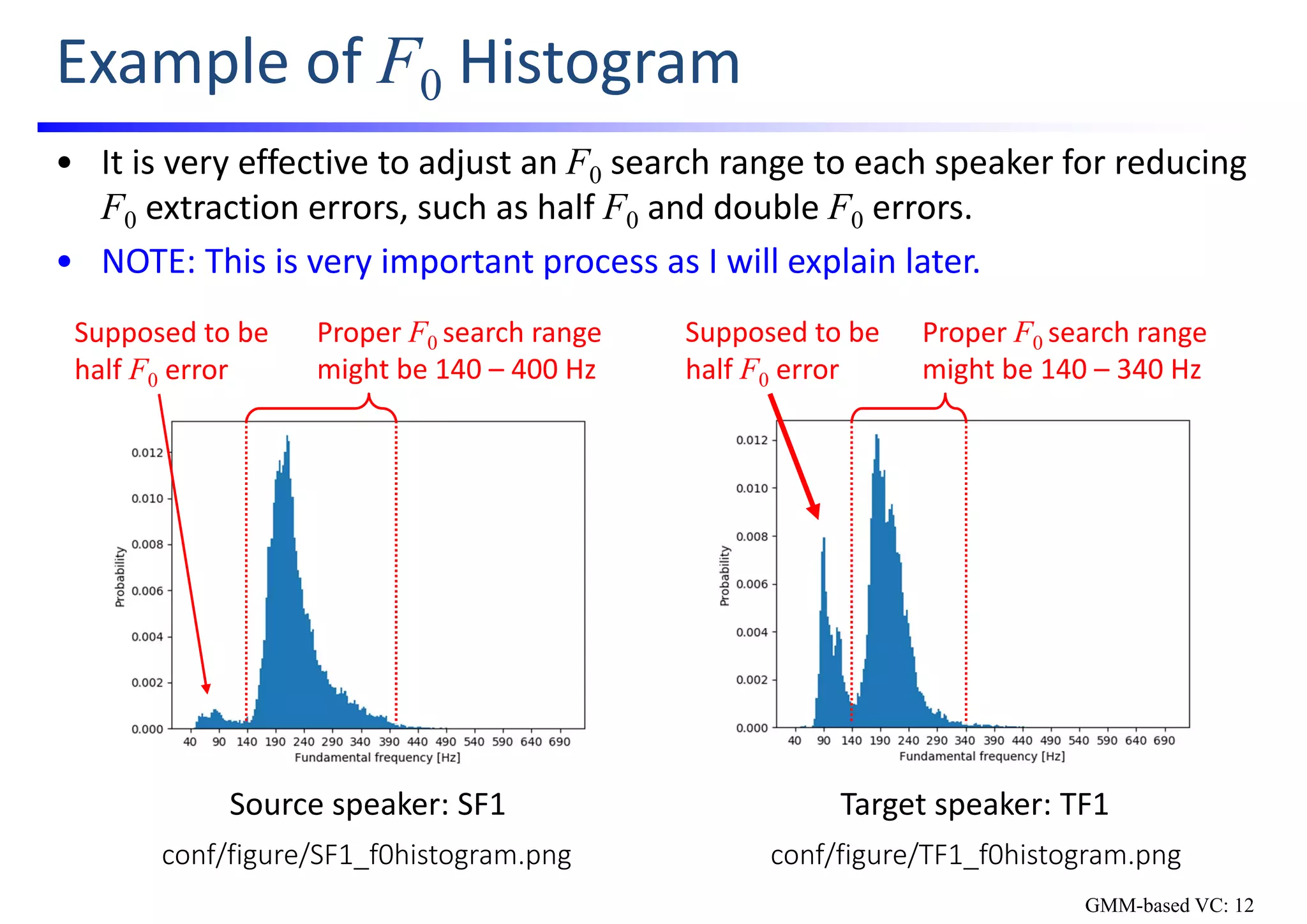
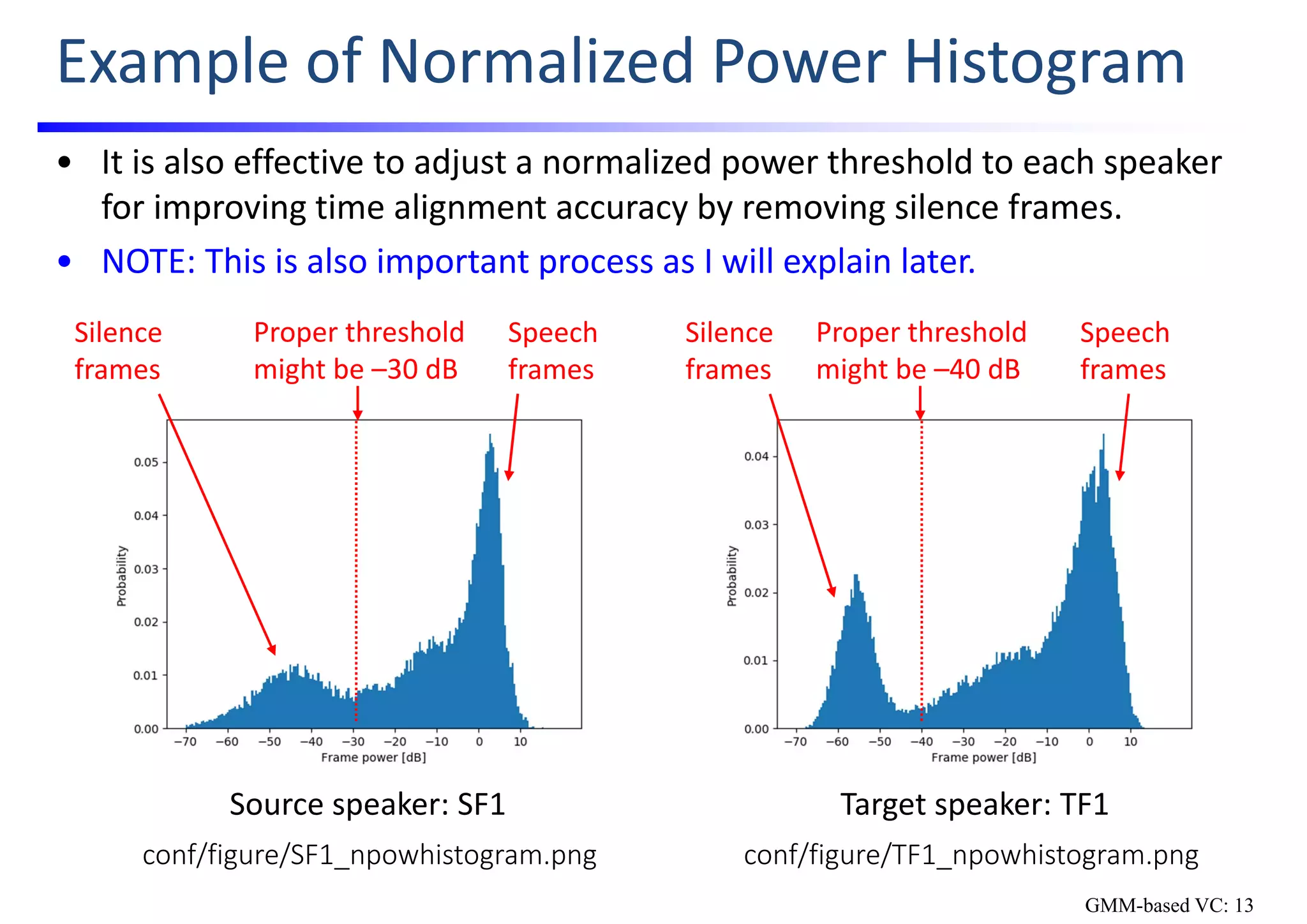
![Example of Speaker‐Dependent YML File
• Contents of the speaker‐dependent YML file: conf/speaker/SF1.yml
wav:
fs: 22050 # sampling frequency [Hz]
bit: 16 # quantization bit [bit]
fftl: 1024 # FFT length [points]
shiftms: 5 # shift length [msec]
f0:
minf0: 40 # minimum F0 [Hz]
maxf0: 700 # maximum F0 [Hz]
mcep:
dim: 34 # order of mel‐cepstrum
alpha: 0.455 # all‐path filter parameter for mel‐frequency warping
power:
threshold: ‐15 # power threshold to remove silence frames
analyzer: world # speech analysis method
GMM-based VC: 9](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-17-2048.jpg)






![Speech Analysis Processing
• Source code: src/extract_features.py
• WORLD [Morise; ’16] is used as an speech analysis‐synthesis method.
• Spectral envelope is parameterized into mel‐cepstrum [Tokuda; ’94].
Speech
waveform
F0 sequence
(f0 seq)
Spectral envelope
Sequence (spc seq)
Coded aperiodicity sequence
(codeap seq)
Mel‐cepstrum sequence
(mcep seq)
Normalized power sequence
(npow seq)
Parameter HDF5 file
(f0, mcep, npow, codeap)wav file
aperiodicity
sequence (ap seq)
*NOTE: F0 is used to accurately estimate
spectral envelope by removing the effects
of periodicity of excitation. Therefore, F0
estimation errors cause adverse effects in
other parameter estimation.
GMM-based VC: 18](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-26-2048.jpg)


![Statistics Calculation Processing
• Source code: src/estimate_feature_statistics.py
• Speaker‐dependent statistics to be used for F0 conversion & GV postfilter
[Toda; ’12] are extracted.
f0 seqs
mcep seqs
Statistics HDF5 file
(f0stats, gv)
Parameter
HDF5 files
Mean & variance
vectors
Log F0
sequence
Mean & variance
values
GMM-based VC: 22](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-30-2048.jpg)

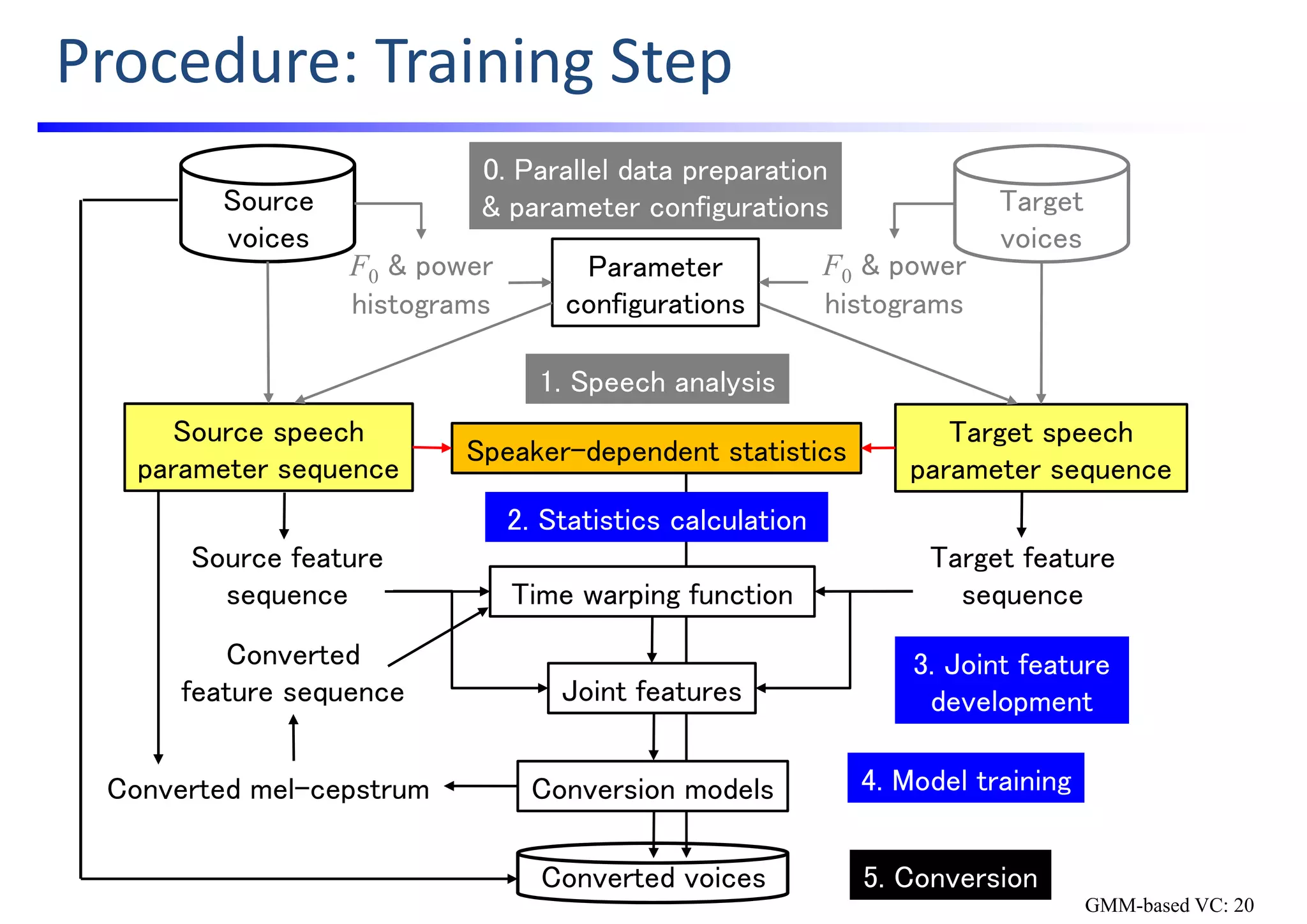
![Training 3: Joint Feature Development
• Develop joint features by executing
$ python3 run_sprocket.py ‐3 SourceSpeaker TargetSpeaker
e.g.,
$ python3 run_sprocket.py ‐3 SF1 TF1
• The following message will be printed out.
### 3. Estimate time warping function and jnt ###
## Alignment mcep w/o 0‐th and silence ##
1‐th joint feature extraction starts.
distortion [dB] for 1‐th file: …..
:
• Finally, a joint feature file and time warping function files will be generated
under data/pair/ directory.
data/pair/SF1‐TF1/jnt/it3_jnt.h5 # joint feature HDF5 file
data/pair/SF1‐TF1/twf/it3_100*.h5 # time warping function HDF5 files
GMM-based VC: 24](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-32-2048.jpg)



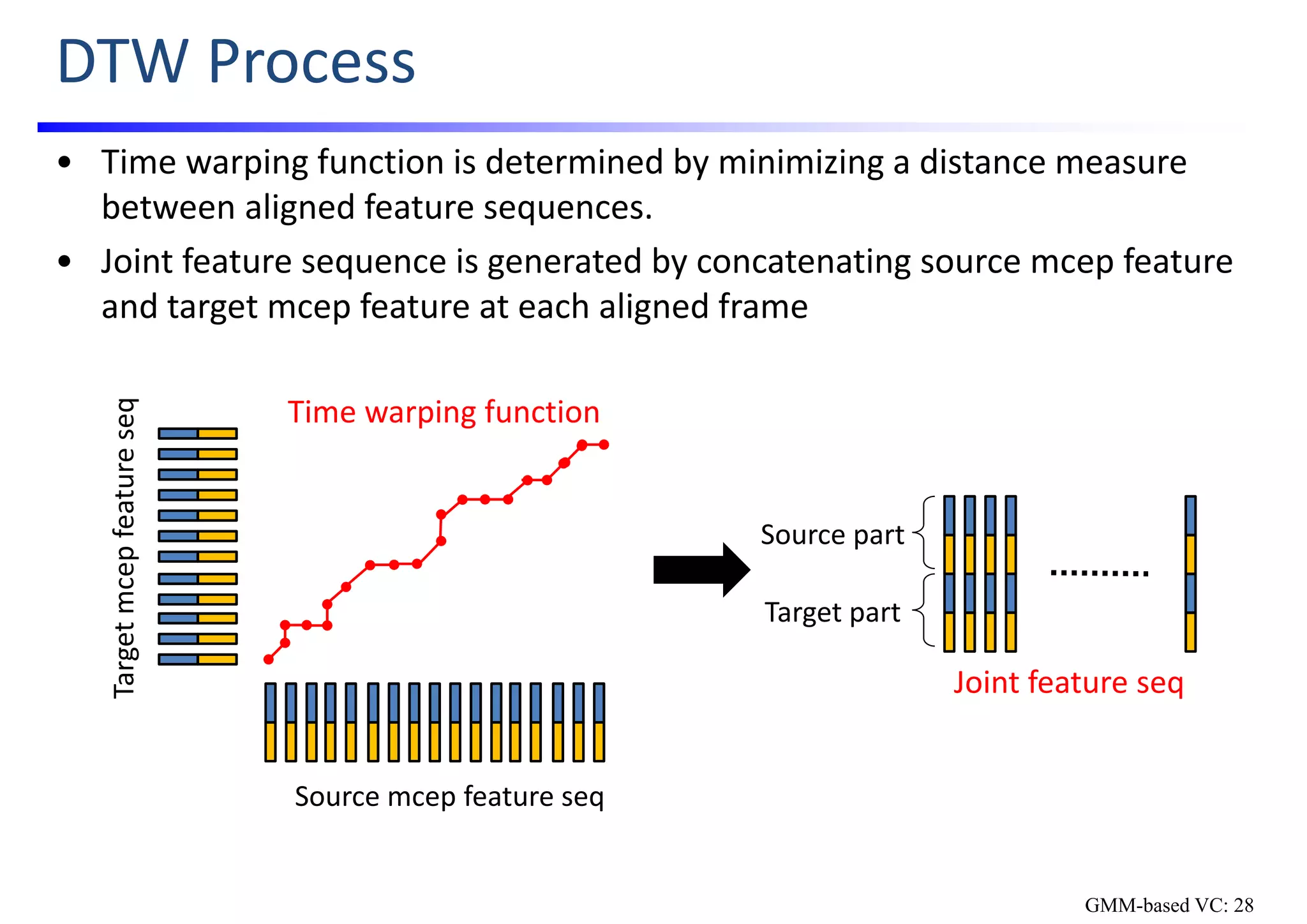

![Iterative DTW Process
• Time alignment determined by using source & target feature seqs suffers
from acoustic differences between source & target voices.
• To improve accuracy of time alignment, iterative DTW process is usually
used for refining the time warping functions [Abe; ’90].
mcep feature
seqs
GMM for mcep
conversion
mcep seqs
Time warping
functions
Joint mcep
feature seqs
Converted mcep
feature seqs
Converted
mcep seqs
mcep feature
seqs
mcep seqs
Same time structure
Used for developing
joint features
Used for determining
time warping function
Acoustically more
similar to target
GMM-based VC: 30](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-38-2048.jpg)
![GMM Training & Conversion Process
• Joint GMM training [Kain; ’98]
• Joint probability density function (p.d.f.) of the source & target mcep features
is modeled by a joint GMM.
• Trajectory‐based conversion [Toda; ’07]
• The source mcep seq is converted into the target one by maximum likelihood
parameter generation using a conditional p.d.f. derived from the joint GMM
Joint mcep
feature seqs
Joint
GMM
Maximum likelihood estimation
using EM algorithm
Source mcep seq
Remove the 0th
coefficients
Append
dynamic features
Converted mcep seq w/o
the 0th coefficients
Conditional p.d.f.
Joint
GMM
GMM-based VC: 31](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-39-2048.jpg)
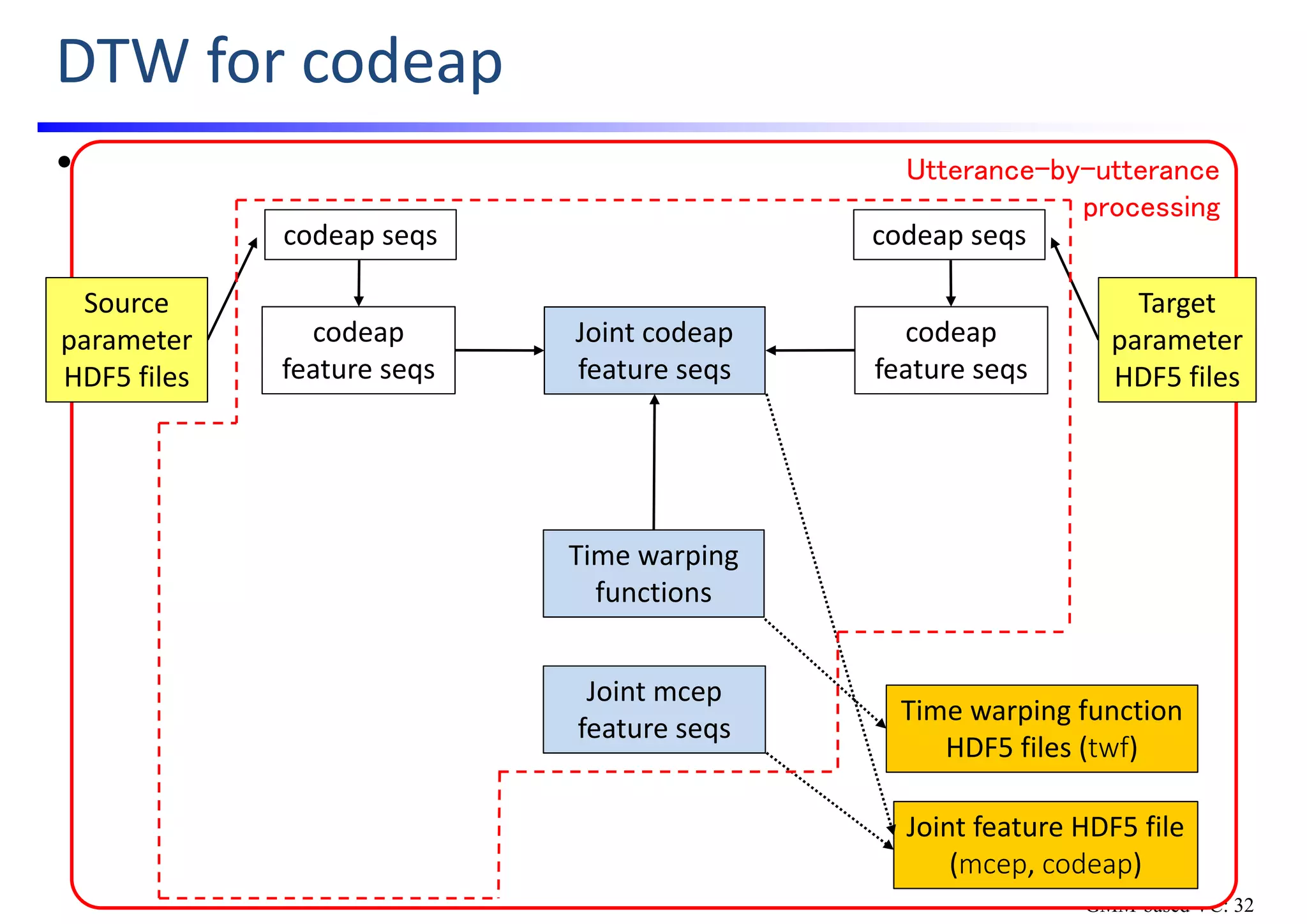
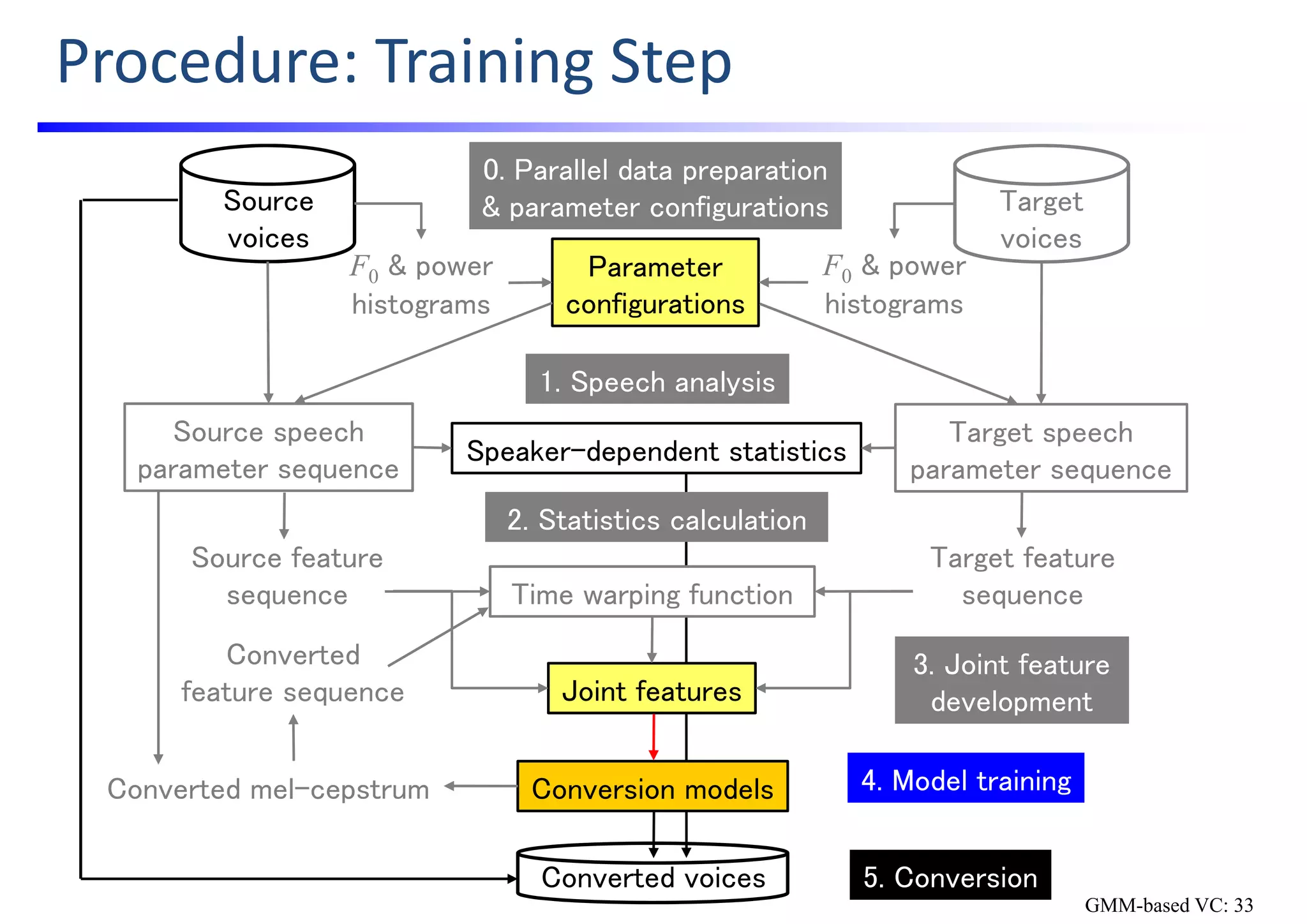

![GMMs Training & GV Postfilter Calculation
• Source code: src/train_GMM.py
• Joint GMMs training
• Joint GMMs for mcep features and for codeap features are separately trained.
• GV calculation [Toda; ’07][Toda; ’12]
• Statistics of converted mcep seqs are calculated for GV postfilter
Joint feature
HDF5 file
(mcep, codeap)
Joint GMM
for mcep
GMM PKL
file (mcep)
Joint mcep
feature seqs
Joint GMM
for codeap
GMM PKL
file (codeap)
Joint codeap
feature seqs
mcep seqs
GV statistics
HDF5 file (cvgv)
Parameter
HDF5 files
Mean & variance
vectors
Converted
mcep seqs
Joint GMM
for mcep
GMM-based VC: 35](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-43-2048.jpg)
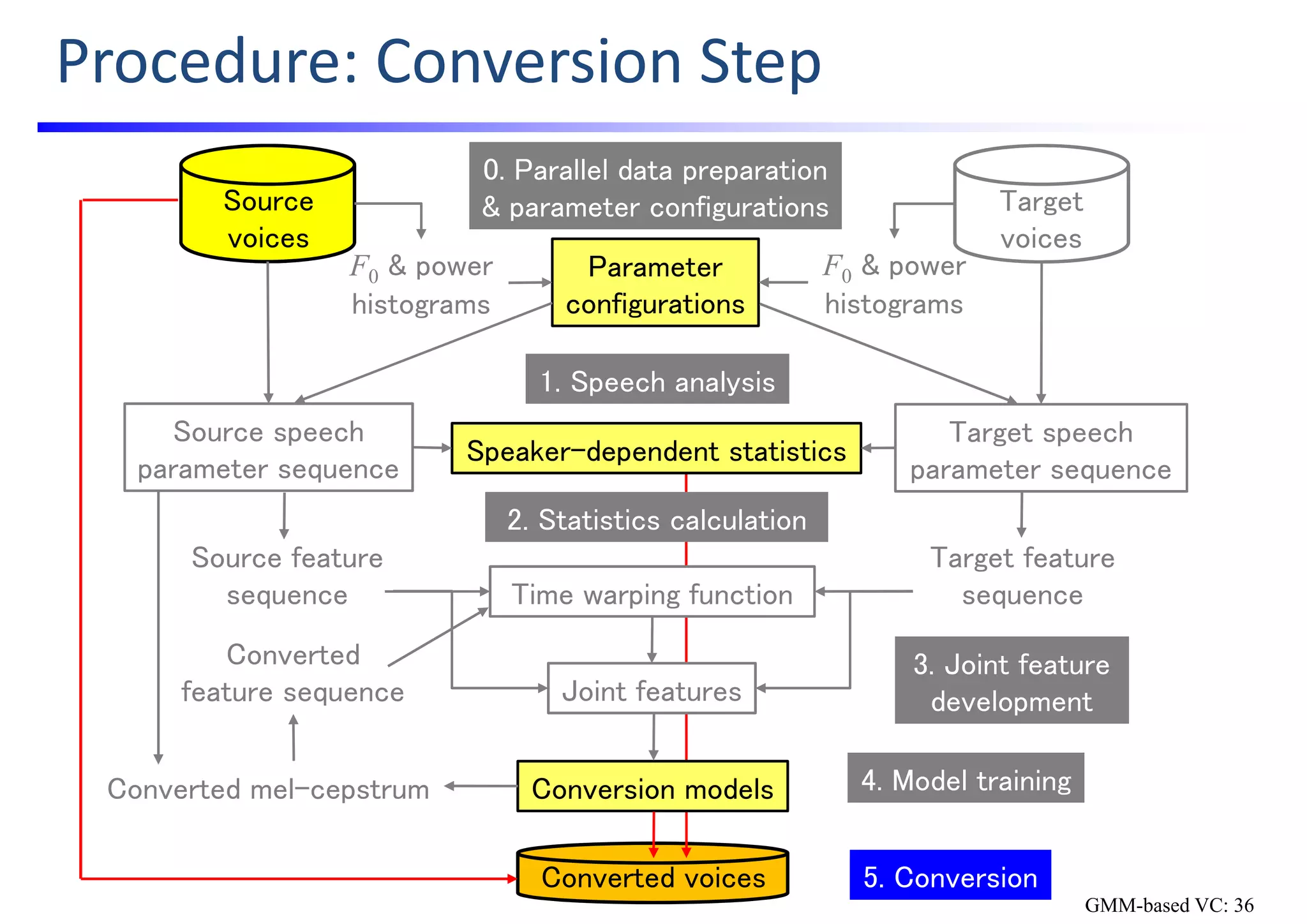

![Converted Speech Generation by VC
• Source code: src/convert.py
• WORLD [Morise; ’16] is used as an speech analysis‐synthesis method.
Speech
waveform
f0 seq
mcep seq
ap seq
Statistics HDF5 file
(f0stats, gv)
Converted
F0 seq
GMM PKL
file (mcep)
Converted mcep
(cvmcep) seq
GV postfiltered
cvmcep seq
Converted
waveform
GV statistics
HDF5 file (cvgv)
Power adjusted
cvmcep seq
Source
wav file Linear transformation
of log‐scaled F0 seq
GV postfiltering
w/o power
conversionTrajectory‐based
conversion
w/o ap conversion
Converted wav
file (VC)
GMM-based VC: 38](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-46-2048.jpg)
![Already Developed
Vocoder‐Free VC based on
DIFFGMM as well!
[Kobayashi; 18b]
K. Kobayashi, T. Toda, S. Nakamura,
“Intra‐gender statistical singing voice conversion with direct waveform modification
using log‐spectral differential,”
Speech Communication, Vol. 99, pp. 211—220, 2018.
https://doi.org/10.1016/j.specom.2018.03.011
DIFFGMM-based VC](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-47-2048.jpg)
![Converted Speech Generation by DIFFVC
• Source code: src/convert.py
• MLSA filter [Tokuda; ’94] is used as to directly convert source waveform
Speech
waveform
f0 seq
mcep seq
Statistics
HDF5 file (gv)
GMM PKL
file (mcep)
Differential mcep
(diffmcep) seq
GV postfiltered
diffmcep seq
Converted wav
file (DIFFVC)
Converted
waveform
GV statistics
HDF5 file (cvgv)
Power adjusted
diffmcep seq
Source
wav file
GV postfiltering
w/o power
conversion
Trajectory‐based conversion
DIFFGMM
for mcep
*NOTE: DIFFVC can generate much higher quality of
converted speech than VC, but F0 is NOT converted.
Thus, DIFFVC is very effective for a speaker‐pair with
a similar F0 range, e.g., in the same gender conversion.
DIFFGMM-based VC: 1](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-48-2048.jpg)

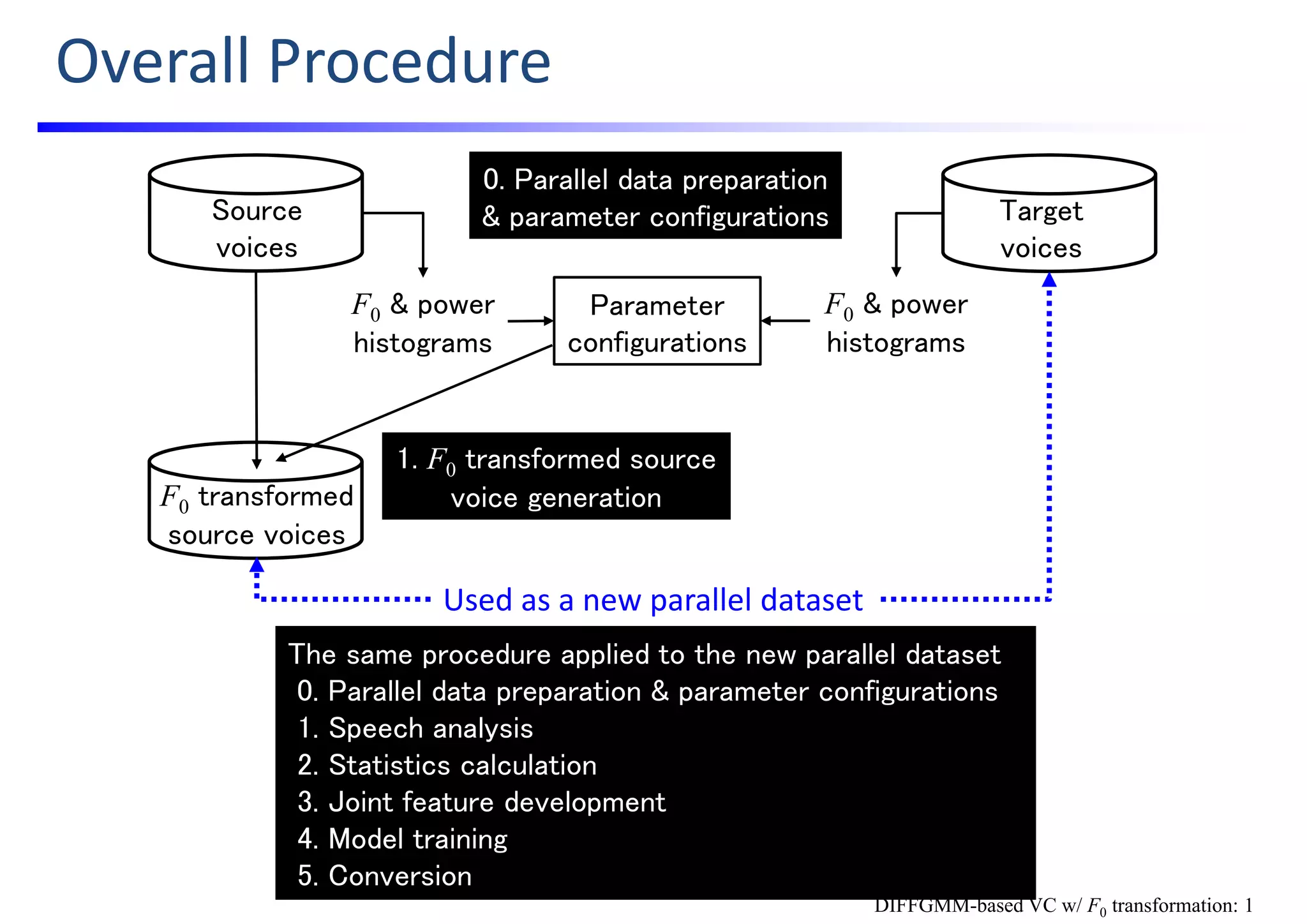
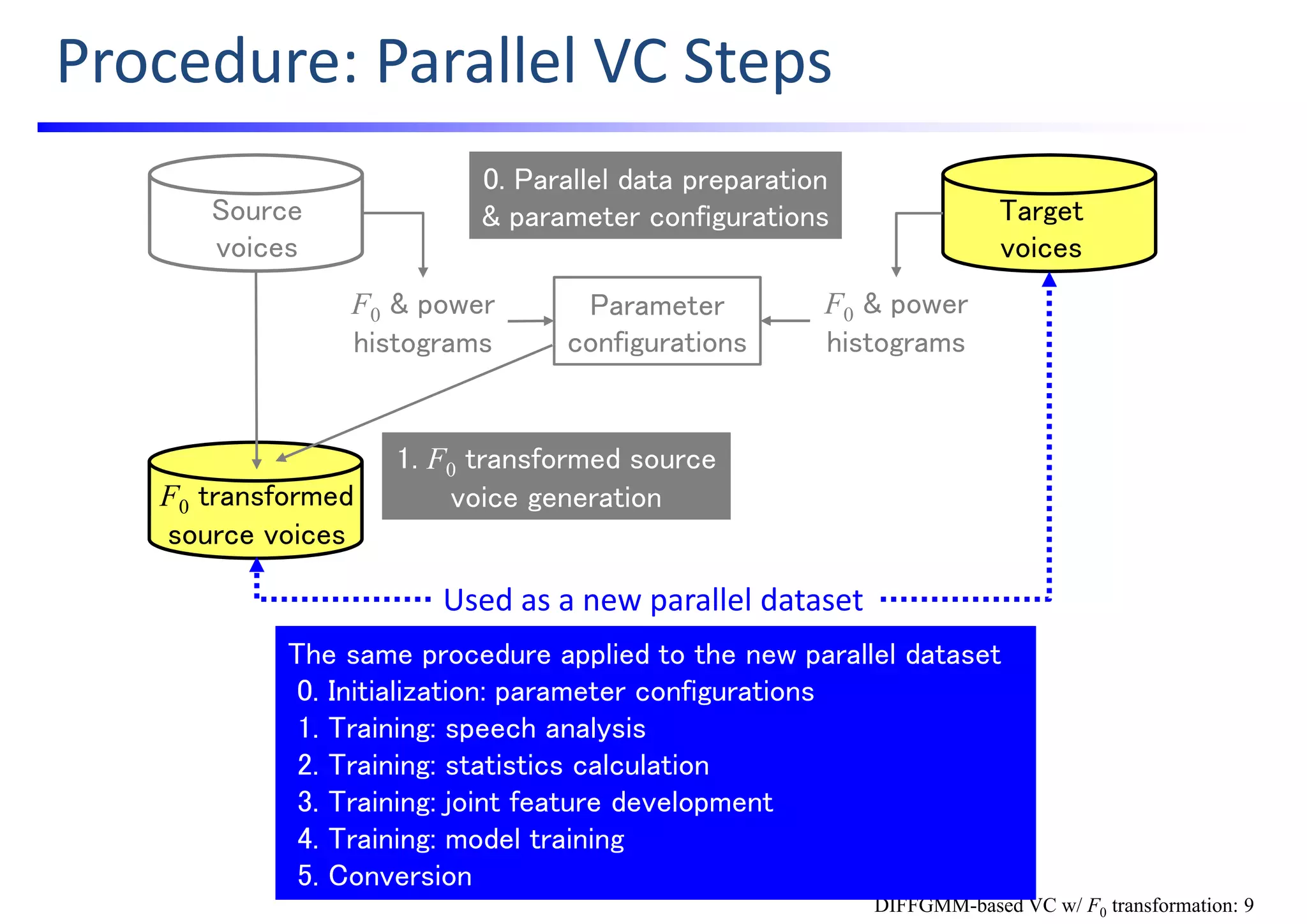
![Let’s Develop Vocoder‐Free
VC based on DIFFGMM
with F0 Modification!
[Kobayashi; ’16]
K. Kobayashi, T. Toda, S. Nakamura,
“F0 transformation techniques for statistical voice conversion with direct waveform
modification with spectral differential,”
Proc. IEEE SLT, pp. 693—700, Dec. 2016.
DIFFGMM-based VC w/ F0 transformation](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-50-2048.jpg)





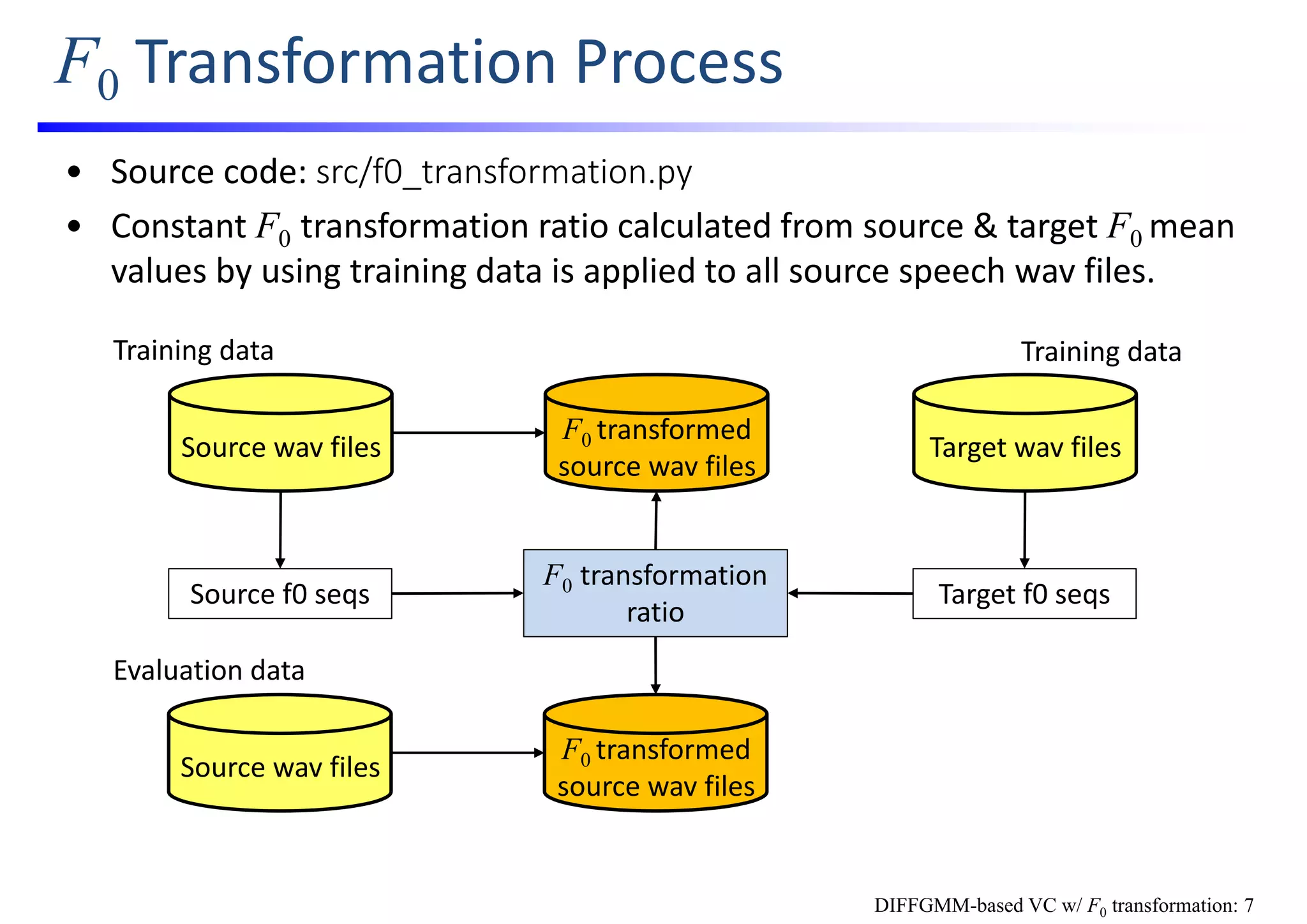
![F0 Transformed Waveform Generation
• Duration conversion w/ WSOLA [Verhelst; ’93] and waveform resampling
is used to generate F0 transformed waveform.
e.g., if setting F0 transformation ratio to 2 (i.e., 100 Hz to 200 Hz),
1. Make duration of input waveform double w/ WSOLA while keeping F0 values
2. Resample the modified waveform to make its duration half
Input waveform
Duration modified
waveform
1.1. Extract frames by windowing
1.2 Find the best concatenation point
1.3 Overlap and add
fO modified
waveform
Deletion or down sampling
Duration modified
waveform
DIFFGMM-based VC w/ F0 transformation: 8](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-58-2048.jpg)



![Reproduce Baseline Results of VCC2018!
• You can develop a baseline system of VCC2018 Hub task [Kobayashi; ’18a] by
using sprocket!
100
80
60
40
20
0
1 2 3 4 5
MOS on naturalness
Similarity score [%]
sprocket
• Hub task: parallel training task
• Source: 2 female & 2 male speakers
• Target: 2 female & 2 male speakers
• 81 utterances for training
• 35 utterances for evaluation
• Baseline system development
• DIFFVC w/o F0 transformation
for the same‐gender pairs
MOS ≅ 4.0, similarity ≅ 70%
• VC for the cross‐gender pairs
MOS ≅ 3.0, similarity ≅ 70%
• In total, MOS ≅ 3.5, similarity ≅ 70%
Results of VCC2018 [Lorenzo‐Trueba; ’18a]
VCC2018 Baseline: 1](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-63-2048.jpg)
![Download VCC2018 Dataset
• Automatically set wav files of VCC2018 datasets [Lerenzo‐Trueba: ’18b] by
executing a download script (download_speech_corpus.py) as follows:
$ python3 download_speech_corpus.py downloader_conf/vcc2018.yml
• The following files will be generated.
data/wav/VCC2{SF1, SF2, SM1, SM2}/ # 4 source speakers for parallel data
data/wav/VCC2{TF1, TF2, TM1, TM2}/ # 4 target speakers for parallel data
10001.wav – 10081.wav # 81 utterances for training
30001.wav – 30035.wav # 35 utterances for evaluation
These files will be used in the baseline system development.
On the other hand, the following files will NOT be used.
data/wav/VCC2{SF3, SF4, SM3, SM4}/ # 4 source speakers for SPOKE task
VCC2018 Baseline: 2](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-64-2048.jpg)
![Develop Baseline System
• Just execute initialize.py & run_sprocket.py for each speaker‐pair.
• Use 81 training utterances and 35 evaluation utterances
• Use default settings of the pair‐dependent YML file (32 mixture components)
• May use the following configurations in speaker‐dependent YML files:
• Use DIFFVC.wav for same‐gender pairs, and VC.wav for cross‐gender pairs
Speaker Minimum F0 (minf0) Maximum F0 (maxf0) Power threshold
VCC2SF1 100 450 –31
VCC2SF2 110 350 –31
VCC2SM1 50 200 –31
VCC2SM2 70 300 –40
VCC2TF1 140 350 –45
VCC2TF2 100 400 –30
VCC2TM1 60 200 –23
VCC2TM2 50 280 –31
Source
speakers
Target
speakers
[Kobayashi; ’18a]
VCC2018 Baseline: 3](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-65-2048.jpg)





![[Abe; ’90] M. Abe, S. Nakamura, K. Shikano, H. Kuwabara. Voice conversion through vector quantization. J.
Acoust. Soc. Jpn (E), Vol. 11, No. 2, pp. 71–76, 1990.
[Kain; ’98] A. Kain, M.W. Macon. Spectral voice conversion for text‐to‐speech synthesis. Proc. IEEE ICASSP,
pp. 285–288, 1998.
[Kobayashi; ’16] K. Kobayashi, T. Toda, S. Nakamura. F0 transformation techniques for statistical voice
conversion with direct waveform modification with spectral differential. Proc. IEEE SLT, pp. 693–700, 2016.
[Kobayashi; ’18a] K. Kobayashi, T. Toda. sprocket: open‐source voice conversion software. Proc. Odyssey,
pp. 203–210, 2018.
[Kobayashi; ’18b] K. Kobayashi, T. Toda, S. Nakamura. Intra‐gender statistical singing voice conversion with
direct waveform modification using log‐spectral differential. Speech Commun., Vol. 99, pp. 211–220, 2018.
[Lorenzo‐Trueba; ’18a] J. Lorenzo‐Trueba, J. Yamagishi, T. Toda, D. Saito, F. Villavicencio, T. Kinnunen, Z. Ling.
The voice conversion challenge 2018: promoting development of parallel and nonparallel methods. Proc.
Odyssey, pp. 195–202, 2018.
[Lorenzo‐Trueba; ’18b] J. Lorenzo‐Trueba, J. Yamagishi, T. Toda, D. Saito, F. Villavicencio, T. Kinnunen, Z. Ling.
The Voice Conversion Challenge 2018: database and results. The Centre for Speech Technology Research,
The University of Edinburgh, UK, 2018. < http://dx.doi.org/10.7488/ds/2337 >
[Morise; ’16] M. Morise, F. Yokomori, K. Ozawa. WORLD: a vocoder‐based high‐quality speech synthesis
system for real‐time applications. IEICE Trans. Inf. & Syst., Vol. E99‐D, No. 7, pp. 1877–1884, 2016.
[Toda; ’07] T. Toda, A.W. Black, K. Tokuda. Voice conversion based on maximum likelihood estimation of
spectral parameter trajectory. IEEE Trans. Audio, Speech & Lang. Process., Vol. 15, No. 8, pp. 2222–2235,
2007.
References
References: 1](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-71-2048.jpg)
![[Toda; ’12] T. Toda, T. Muramatsu, H. Banno. Implementation of computationally efficient real‐time voice
conversion. Proc. INTERSPEECH, 4 pages, 2012.
[Toda; ’16] T. Toda, L.‐H. Chen, D. Saito, F. Villavicencio, M. Wester, Z. Wu, J. Yamagishi. The Voice
Conversion Challenge 2016. University of Edinburgh, School of Informatics, Centre for Speech Technology
Research, 2016. < http://dx.doi.org/10.7488/ds/1430 >
[Tokuda; ’94] K. Tokuda, T. Kobayashi, T. Masuko, S. Imai. Mel‐generalized cepstral analysis – a unified
approach to speech spectral estimation. Proc. ICSLP, pp. 1043–1045, 1994.
[Verhelst; ’93] W. Verhelst, M. Roelands. An overlap‐add technique based on waveform similarity (WSOLA)
for high quality time‐scale modification of speech. Proc. IEEE ICASSP, Vol. 2, pp. 554–557, 1993.
References: 2](https://image.slidesharecdn.com/handsonslidesspcc2018tomokitoda-180730012156/75/Hands-on-Voice-Conversion-72-2048.jpg)














![[DL輪読会]Parallel WaveNet: Fast High-Fidelity Speech Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/0105-180105000252-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]Diffusion-based Voice Conversion with Fast Maximum Likelihood Samplin...](https://cdn.slidesharecdn.com/ss_thumbnails/20220318akuzawa-220322065615-thumbnail.jpg?width=640&height=640&fit=bounds)






































