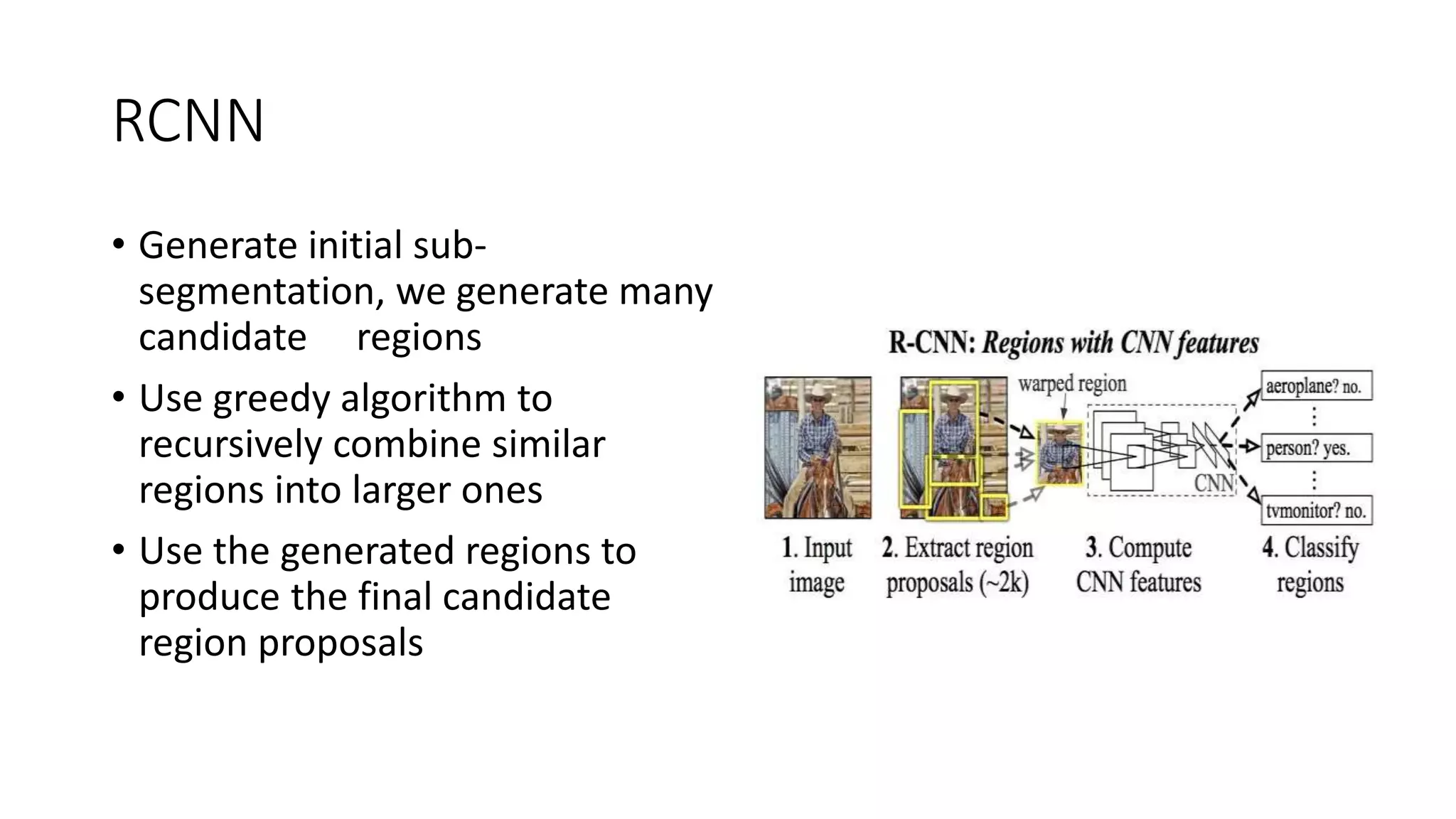
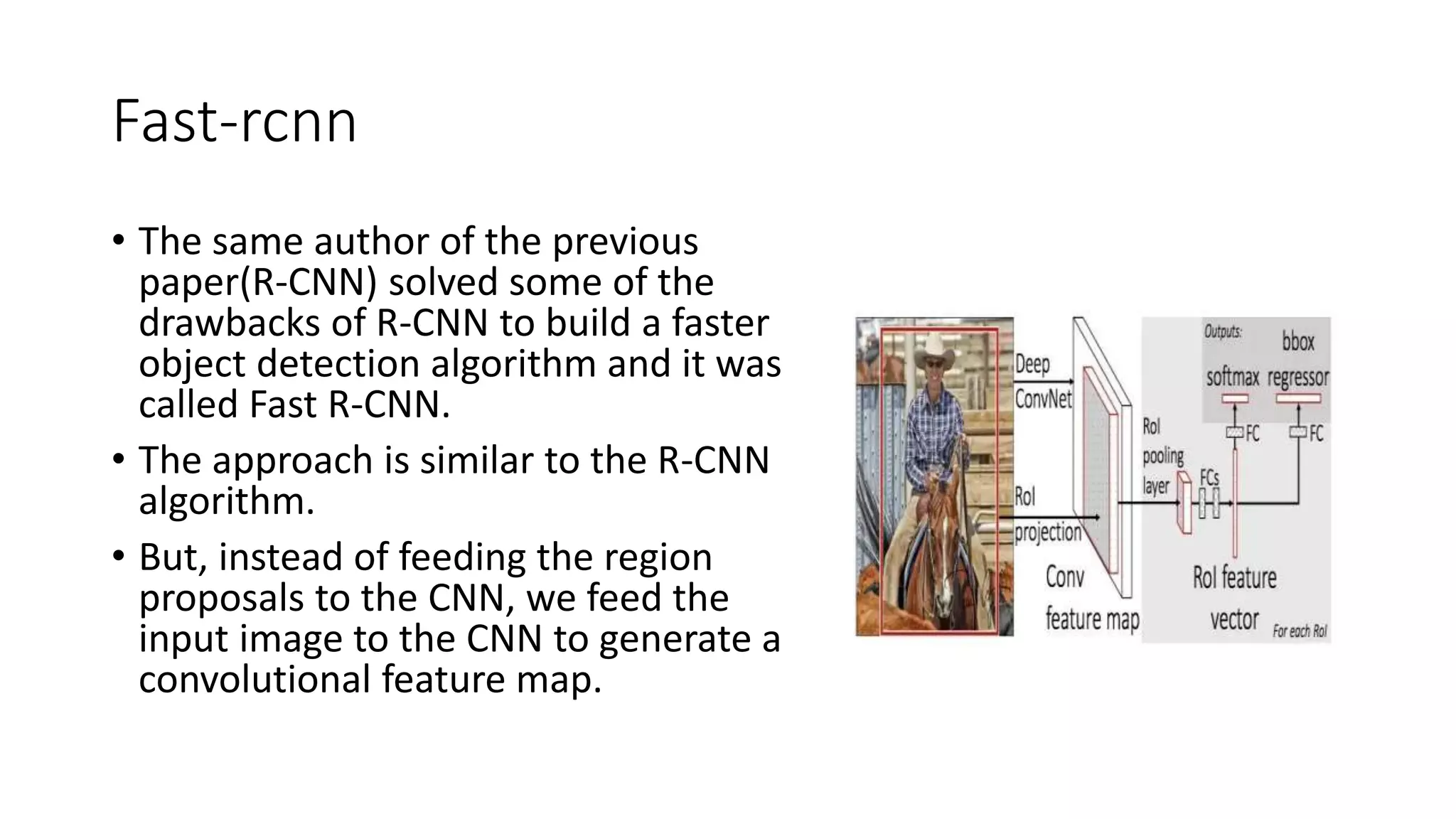
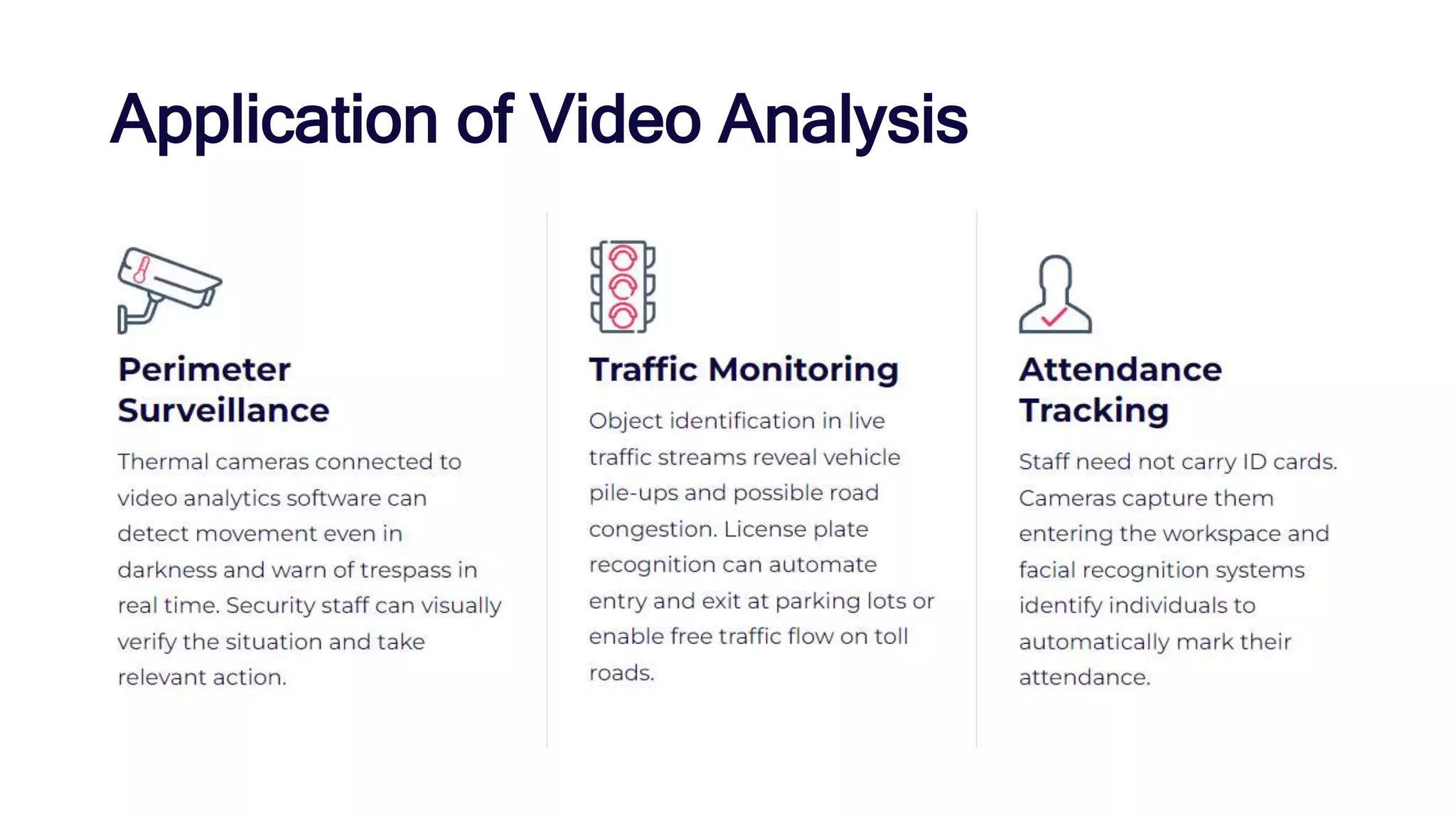
Video processing involves manipulating and analyzing digital video sequences. Common techniques include trimming, resizing, adjusting brightness/contrast, and analyzing using machine learning. Key concepts in video include compression, frames, frame rate, resolution, and aspect ratio. Compression reduces file sizes while maintaining quality. Frames are still images that make up video sequences. Frame rate determines smoothness. Resolution is pixels and quality. Aspect ratio is width to height ratio. Video can be compressed using intra-frame or inter-frame techniques. Enhancement improves quality using techniques like noise reduction and color correction. Analysis extracts information from video.