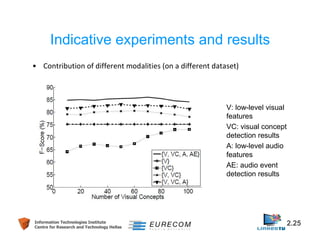
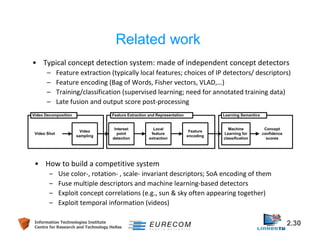
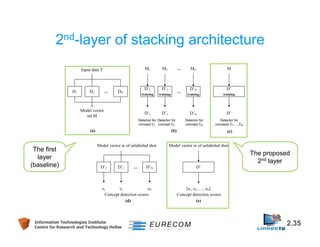
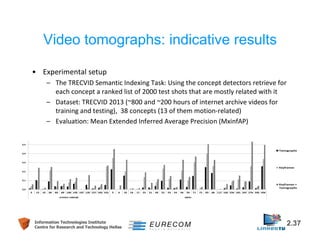
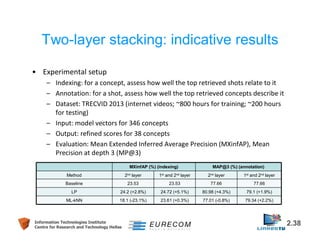
Download as PDF, PPTX
































![Problem statement
• Objective:
– Automatically detect high-level events in large video collections
– Events are defined as “purposeful activities, involving people, acting on
objects and interacting with each other to achieve some result”
“Changing a vehicle tire” “Skiing” “Working on a sewing project”
– Exploit an annotated video dataset
– Represent videos with suitable feature vectors {(x ,y) є X x {-1,1}}
– Learn an appropriate event detector f: X → [0,1]
Information Technologies Institute 2.42
Centre for Research and Technology Hellas](https://image.slidesharecdn.com/videohyperlinkingtutorialpartb-141104100840-conversion-gate02/85/Video-Hyperlinking-Tutorial-Part-B-42-320.jpg)








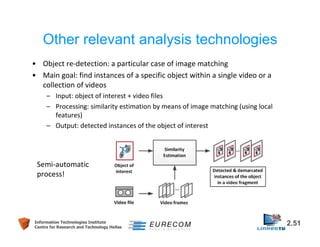
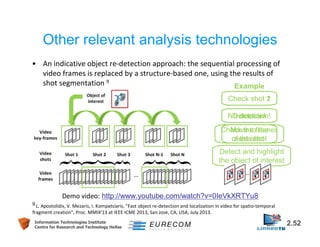





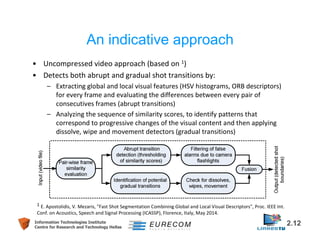
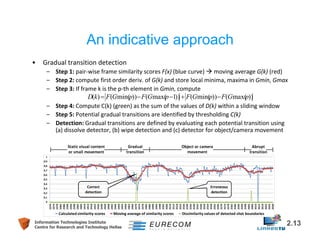
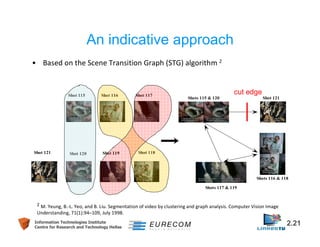
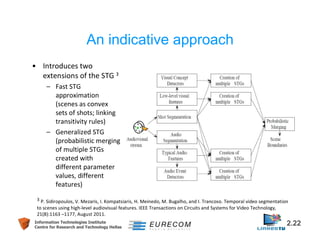
This document discusses technologies for video fragment creation and annotation for the purpose of video hyperlinking. It describes video temporal segmentation to shots and scenes to break videos into fragments. It also discusses visual concept detection and event detection for annotating fragments so meaningful hyperlinks between fragments can be identified. An example approach is described that uses visual features to detect both abrupt and gradual shot transitions with high accuracy at 7-8 times faster than real-time.

























































































