USENIX NDSI 2017報告
&
EfficientMemory Disaggregation with
Infiniswap (University of Michigan)
須崎有康
独立行政法人 産業技術総合研究所
第2回 システム系輪講会
2.
NSDI2017概要
• 14th USENIXSymposium on Networked Systems Design and
Implementation
• https://www.usenix.org/conference/nsdi17
• MARCH 27–29, 2017, BOSTON, MA
• 投稿数254本、採択46本、シングルセッション、キーノートなし。
• 主催者から発表された今年のNSDI論文で使われたキーワード
• Security、Data Center、Distributed Systems、Big Data
• Best Paper Award
• mOS: A Reusable Network stack for Flow Monitoring Middleboxes
(KAIST)
• Community Award
• Transparently Compress Hundreds of Petabytes of Image Files for a File-
Storage Service (Stanford)
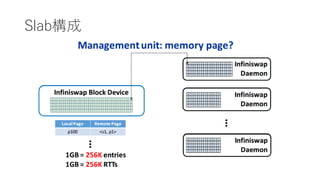
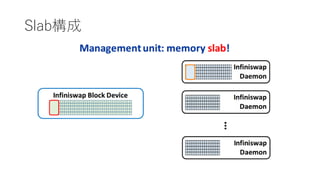
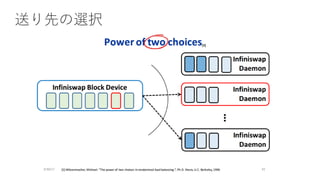
power of tworandom choices
• decentralized slab placements and evictionsの肝
• Michael Mitzenmacher, The Power of Two Choices in Randomized
Load Balancing, Ph.D Thesis, 2001.
• https://pdfs.semanticscholar.org/3885/812a092ff0aad3d45c0464660075e98d0231.pdf
• Michael Mitzenmacher, Andrea Richa, Ramesh Sitaraman,The Power
of Two Random Choices: A Survey of Techniques and Results, 1996.
• http://www.ic.unicamp.br/~celio/peer2peer/math/mitzenmacher-power-of-two.pdf
• Michael Mitzenmacher, The Power of Two Choices in Randomized
Load Balancing, IEEE Trans. Parallel and Distributed Systems, 2001.
• https://www.eecs.harvard.edu/~michaelm/postscripts/tpds2001.pdf
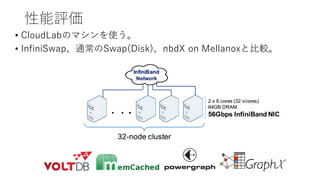
実装
• Linux 3.13.0のSwapを改良。3,500 LOC。
• Loadable Moduleとして実装。
• ndbX for Mellanox https://github.com/accelio/NBDXを活用。
• Stackdb (Stacking a block device over another block device
https://github.com/OrenKishon/stackbd) を活用
The Design, Implementation,and Deployment of a System to Transparently
Compress Hundreds of Petabytes of Image Files for a File-Storage Service (Dropbox,
Stanford University)
• Community Award Paper。JPEGファイルを保存するのにHuffman Codeから
parallelized arithmetic codeでスキャンし直して保存するファイルシステムの
Leptonの発表。圧縮率もCPU性能もよい。Lepton は2017年2月にDropBoxで
使われるようになっており、ソースコードも公開されている。
• PackJPG, MozJPG, JPEGreenなど類似に研究はあるが、JPEGの特徴を取り直
すためにHuffman Codeから別の圧縮方法でファイルシステムが対応するのは、
既存のフォーマットを残しつつシステム側で対応する新たな研究方向と思われ
る。
• また、Leptonの実装ではセキュリティを確保するのにLinuxのSECCOMを使っ
ている。また、C++のthreadで書かれているが、Deterministicを確保している
など、セキュリチィや再現性にまで言及しており、研究の質の高さを示してい
る。
One Key toSign Them All Considered
Vulnerable: Evaluation of DNSSEC in the
Internet (Fraunhofer)
• 現在使われている210万個のDNSSECの鍵の脆弱性調査の発表。
190万個がRSA keyであり、このうち66%が1024bit以下。また、
共通のモジュラスや素数も見つかっている。
• モジュラスが共通だとCommon Modulus Attackが可能となる。
• この発表がインターネット全体を調査した唯一のものであった。
他の一流会議では2,3本あるのに対して、ネットワークが主眼な
会議にしては少ない。





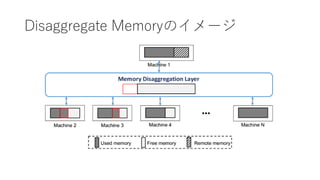

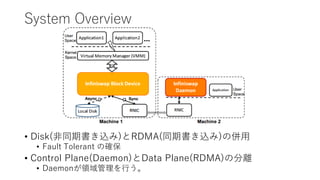
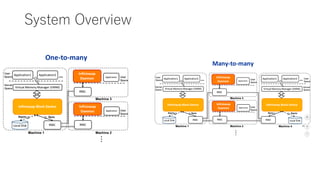
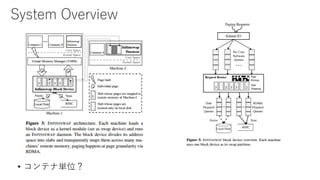







![APUNet: Revitalizing GPU as Packet
Processing Accelerator (KAIST)
• パケット処理にGPUを使う研究(G-Opt[NSDI15])ではメモリコ
ピーの負荷がある。CPUと同じダイにあるIntegrated
GPU(AMD Accelerated Processing Unit)を使うことでアドレ
ス空間を共有し、効率的に処理するAPUNetの提案である。
APUNetはNetwork IDSにもAho-Corasickパターンマッチの高
速化に使えるとのことであった。
• GPUは普及するハードウェアであるが、メモリのコピーの課題
をAMDのAPUを使ってパケット処理と言うターゲットを絞って
活用するのは目の付け所がよい。](https://image.slidesharecdn.com/usenix-nsdi17-memorydisaggregation-170606224304/85/USENIX-NSDI17-Memory-Disaggregation-29-320.jpg)









































































