Download as PDF, PPTX





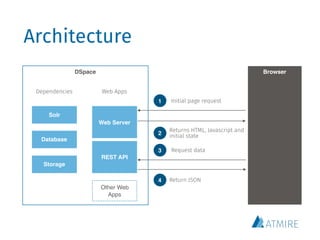








DSpace 7, the next major version of the DSpace platform, is currently in development and aims to introduce a unified user interface built with Angular 2, along with an extended REST API for better interoperability. The new user interface will enhance user experience, optimize search engine results, and maintain existing functionalities found in previous versions. Development focuses on various components including browse/search, authentication, submission workflows, and is guided by dedicated outreach and working groups meeting regularly to track progress.






















































































