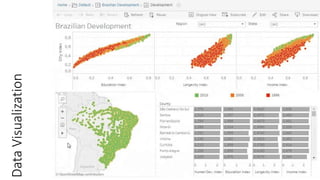
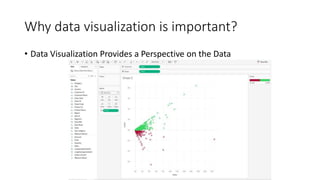
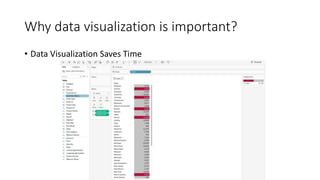
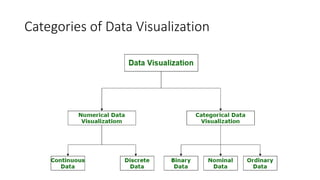
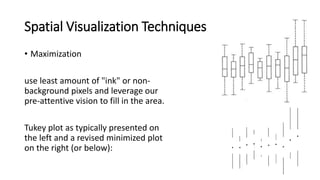
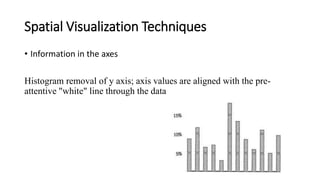
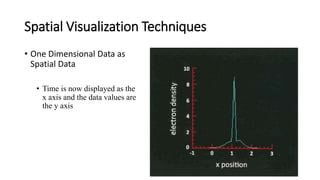
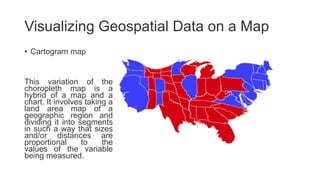
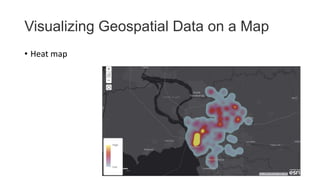
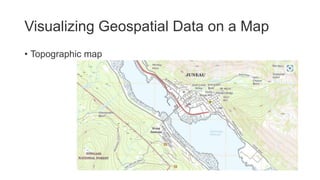
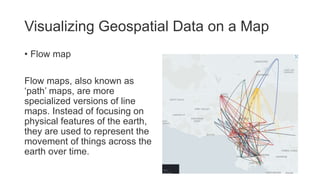
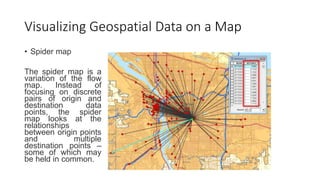
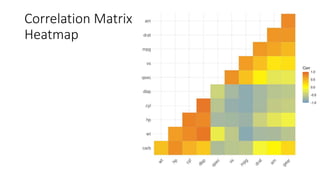
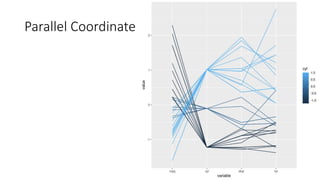
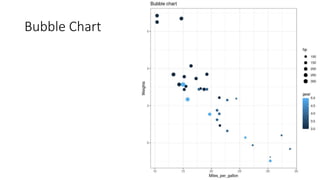
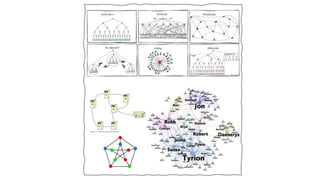
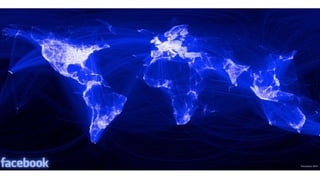
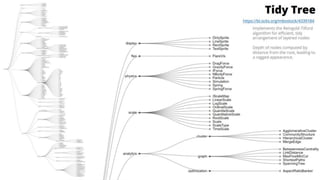
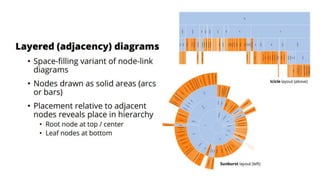
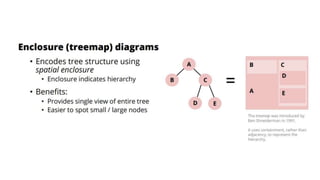
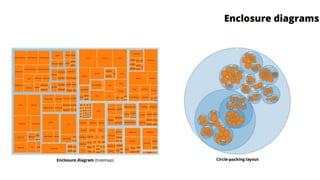
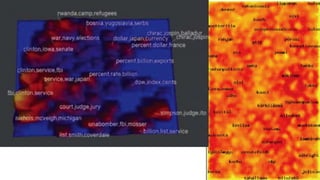
Unit III covers data visualization. It discusses how data visualization tools are needed to analyze and understand large amounts of data. Effective data visualization presents conclusions, chooses appropriate graph types, and ensures visuals accurately reflect numbers to prevent misinterpretations. History of data visualization is discussed using Napoleon's 1812 march as an example. Advantages of data visualization include easily sharing information and exploring opportunities, while disadvantages can include biased information and losing core messages.



































































































































![[DSC Europe 25] Predrag Maletic - Scaling AI in Banking – Our Strategic Journ...](https://cdn.slidesharecdn.com/ss_thumbnails/qu2onv0aruwlvqtygmxx-predrag-maletic-scaling-ai-in-banking-260123083019-6cf1da1d-thumbnail.jpg?width=640&height=640&fit=bounds)