



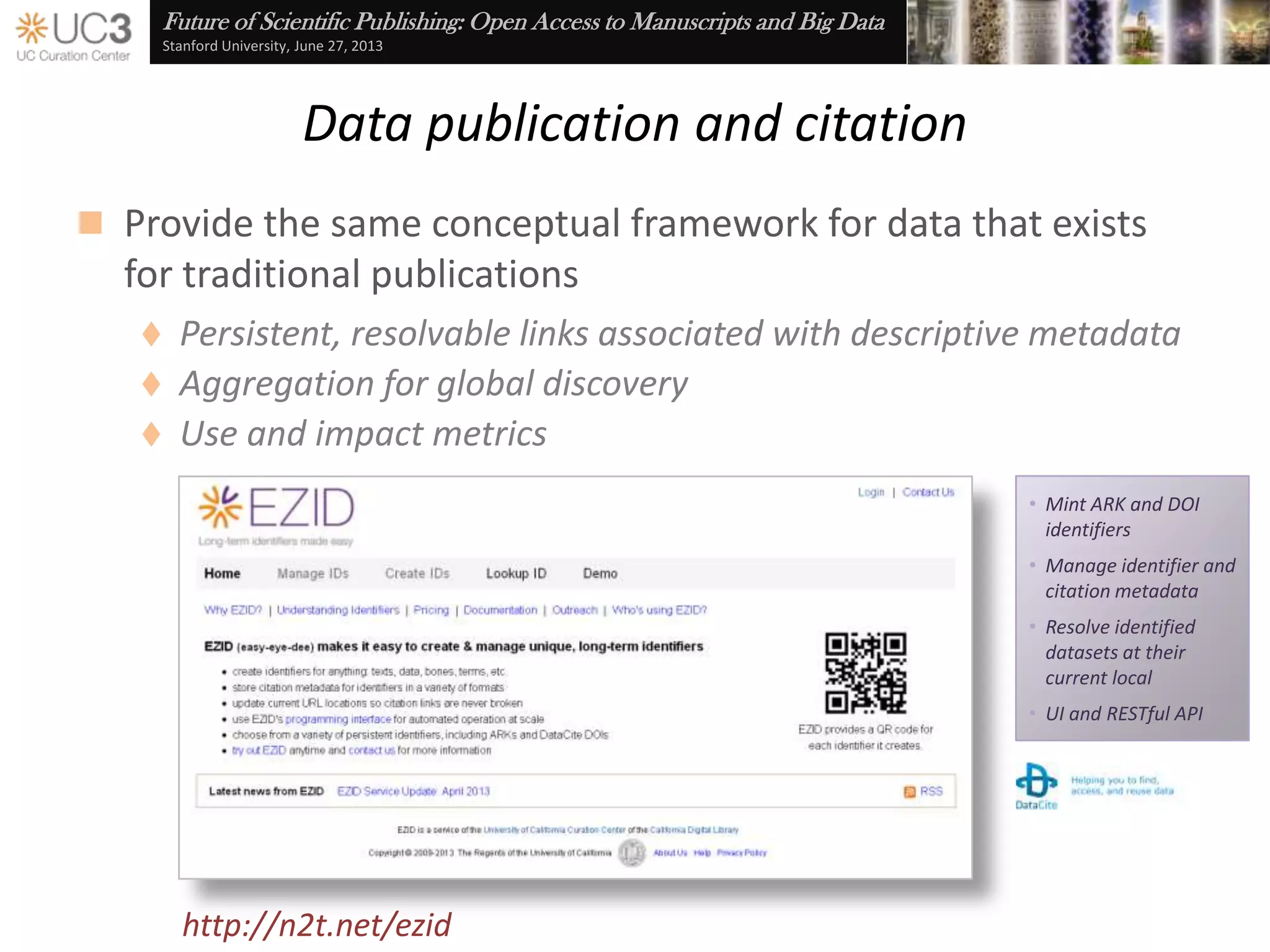
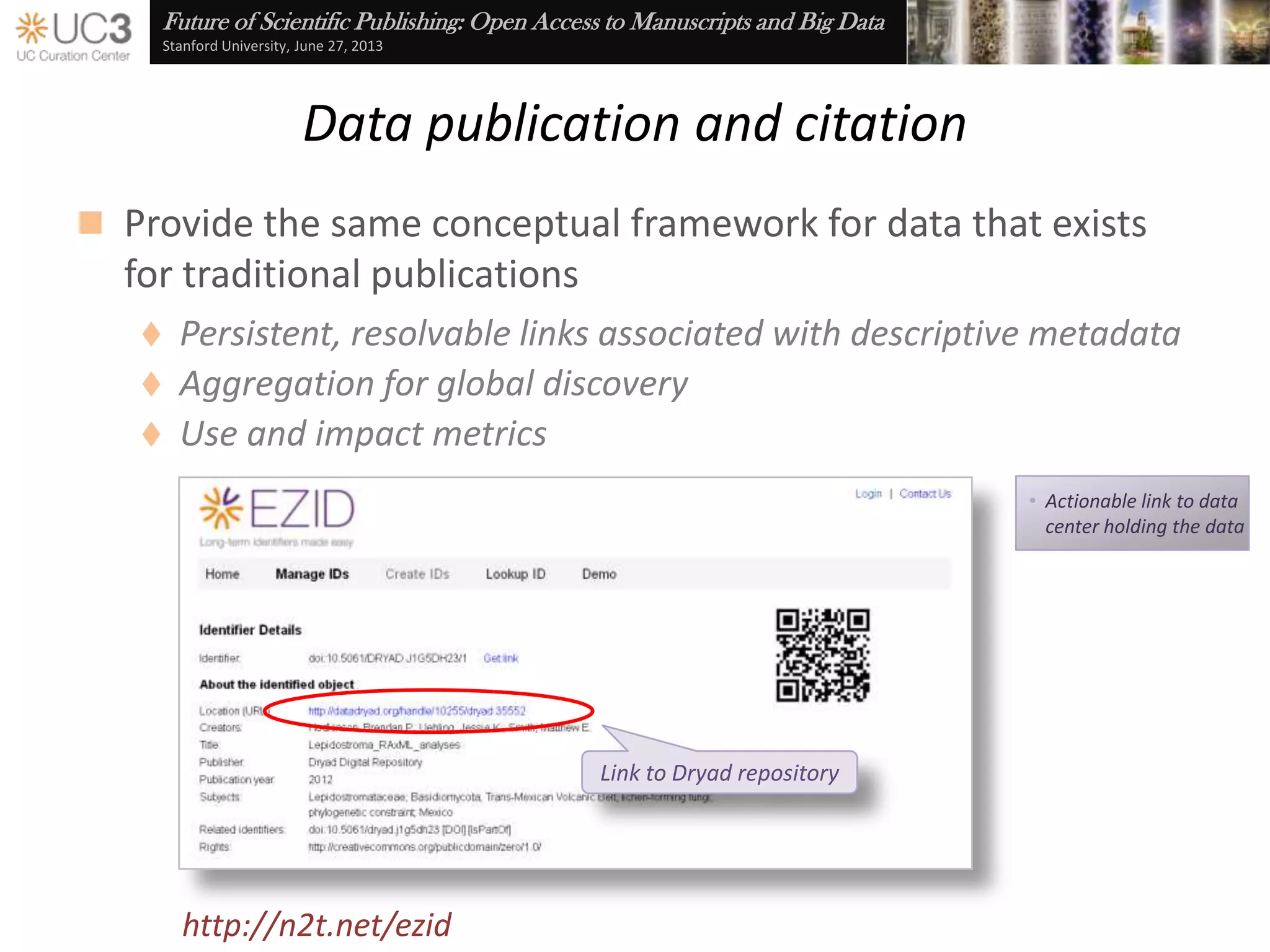
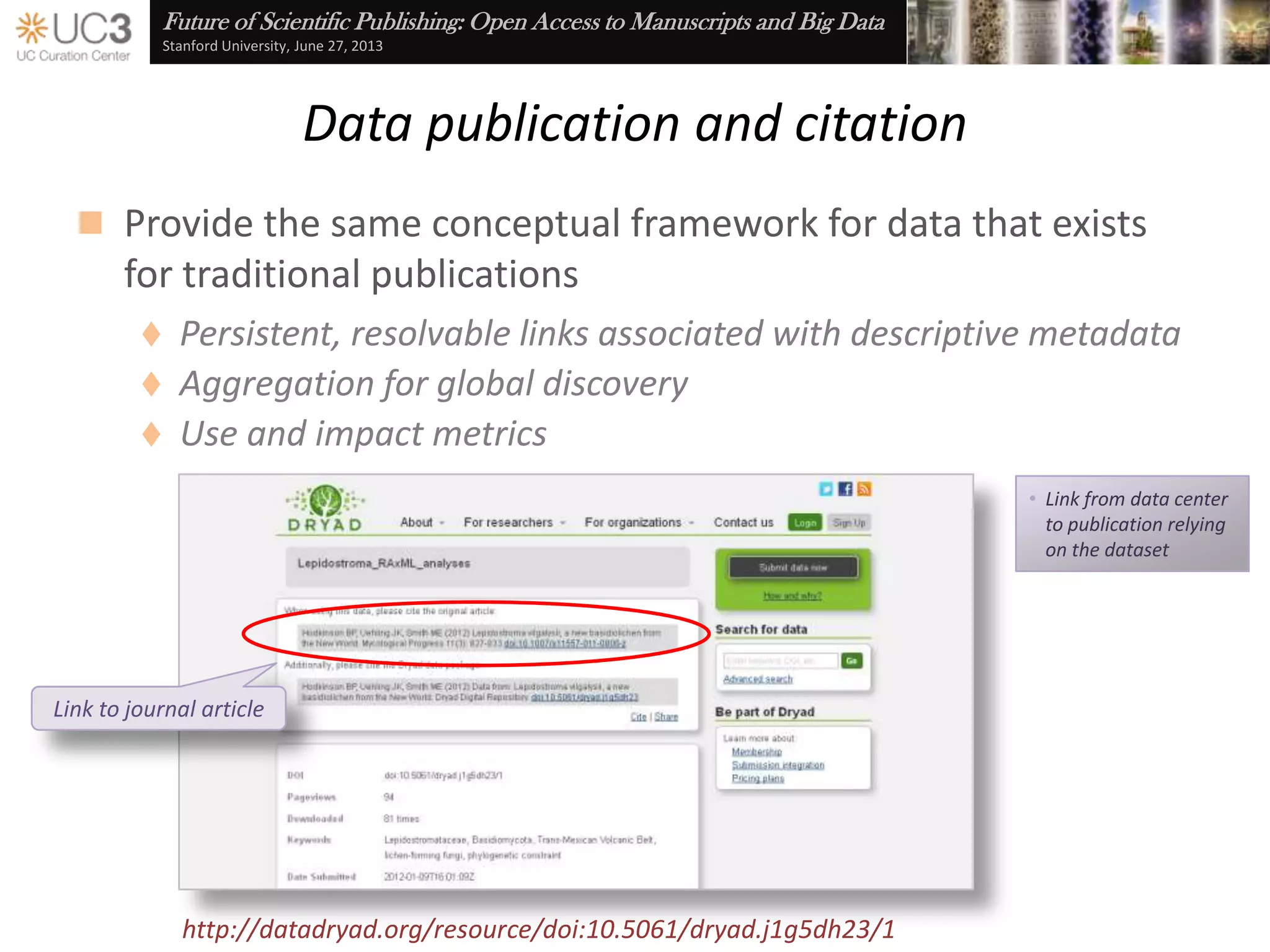
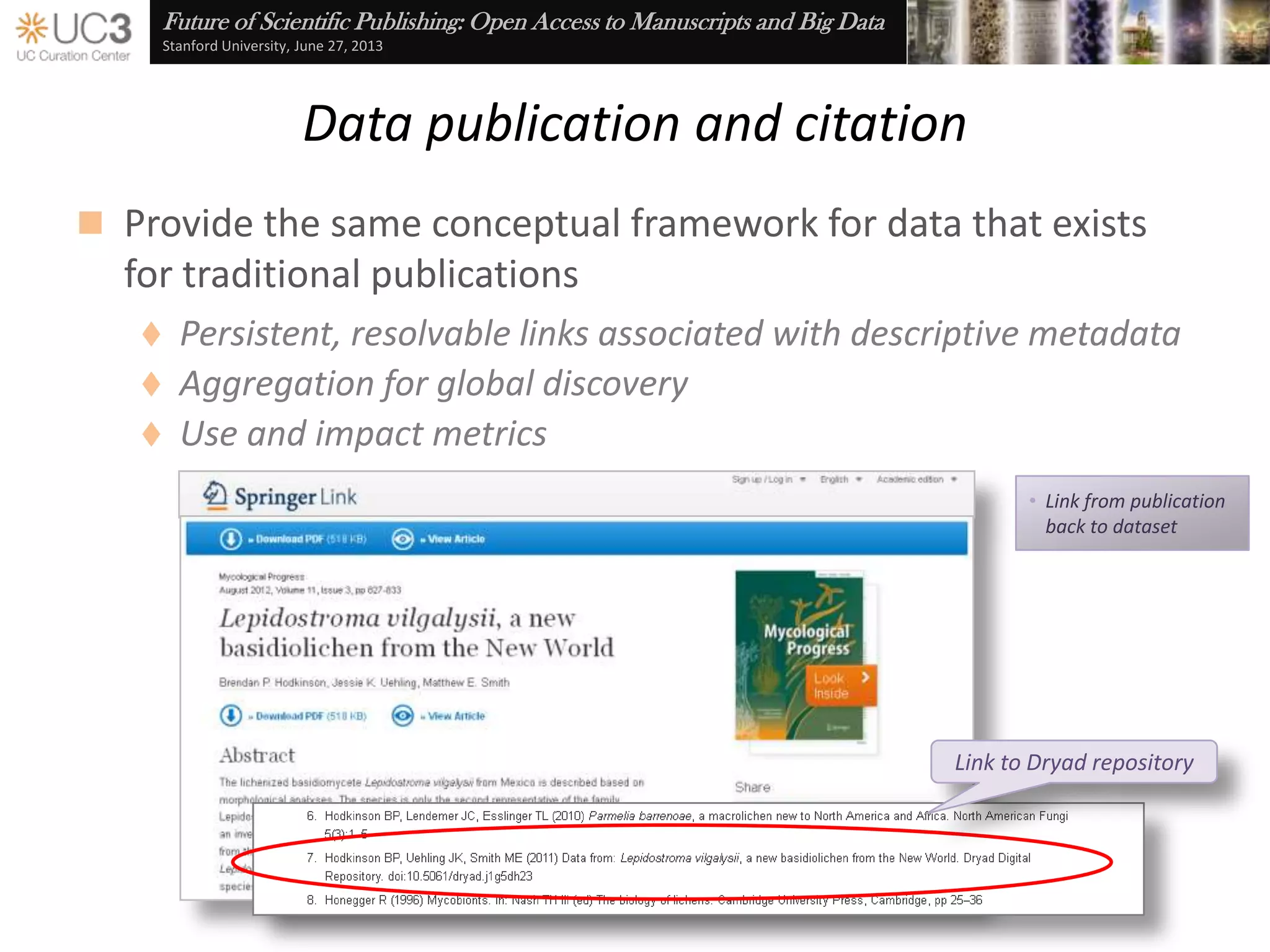
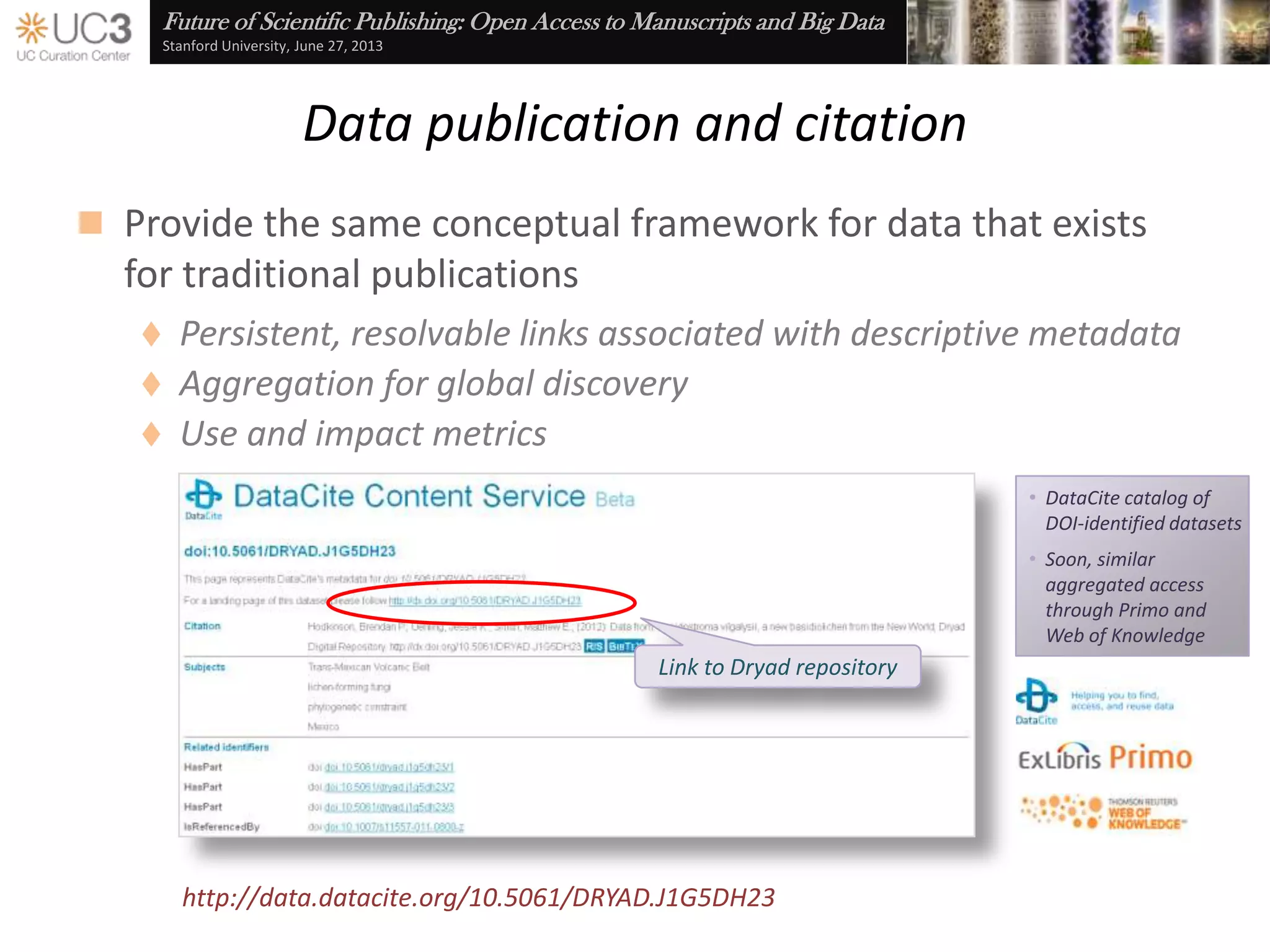
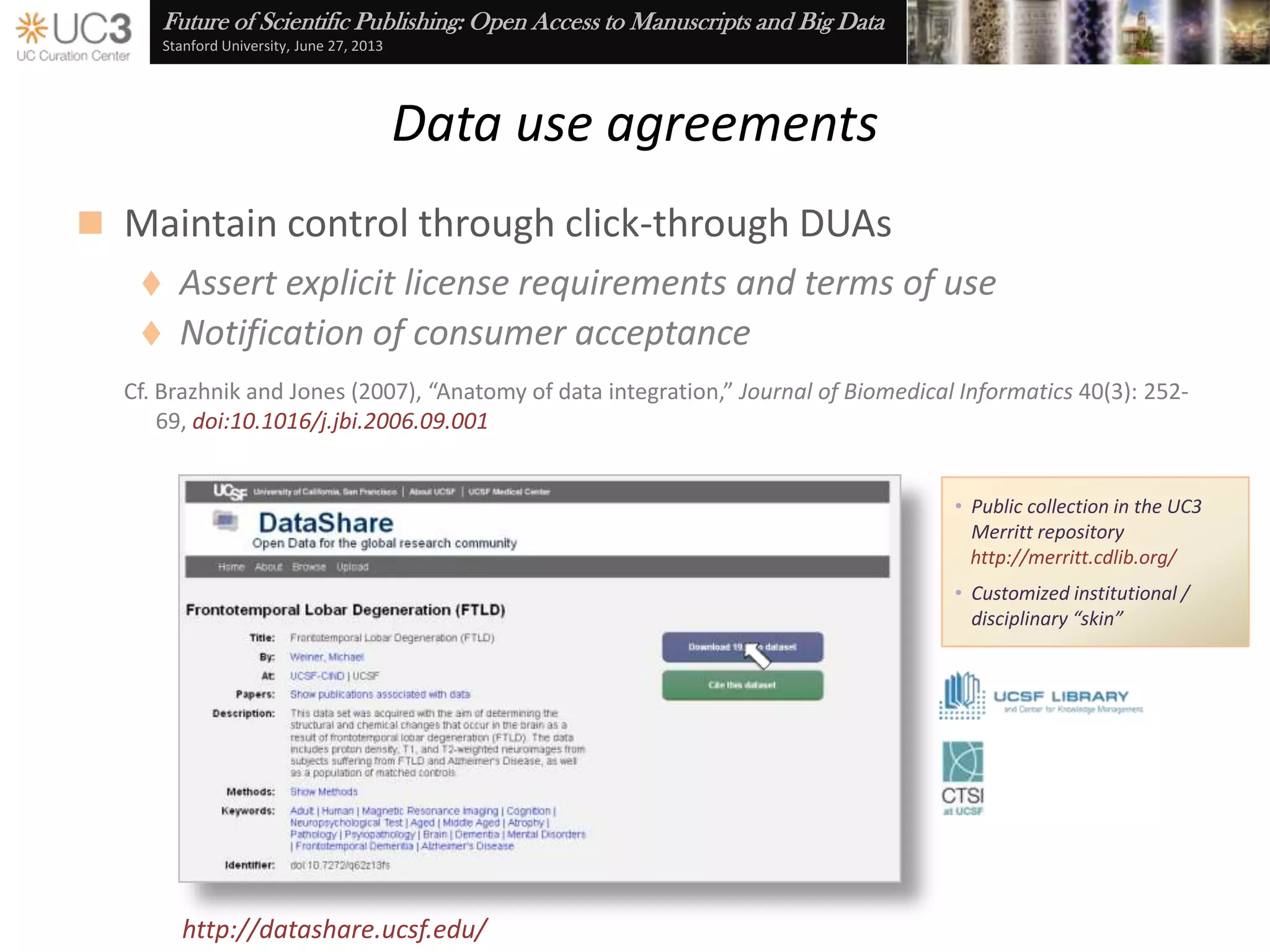
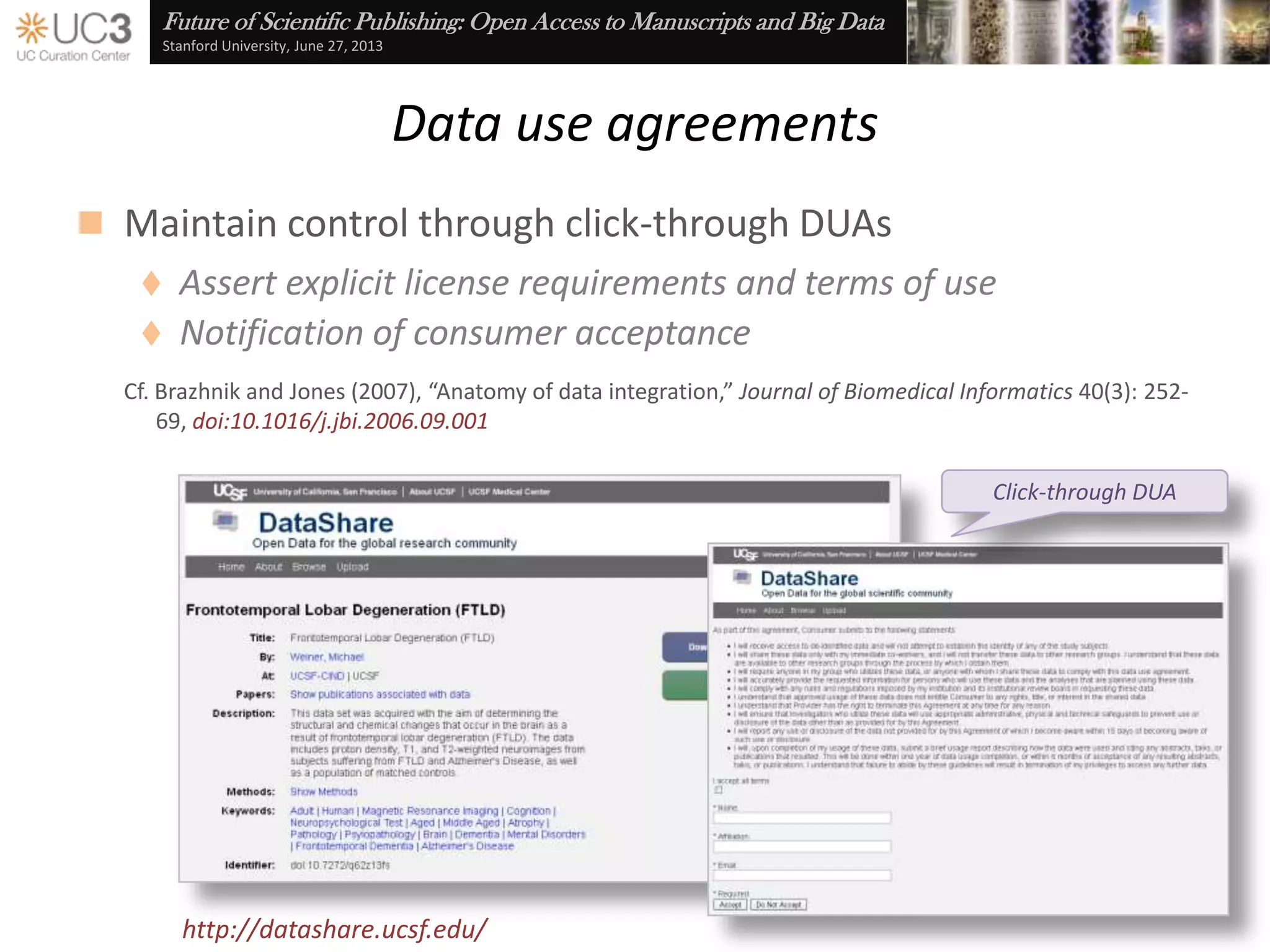
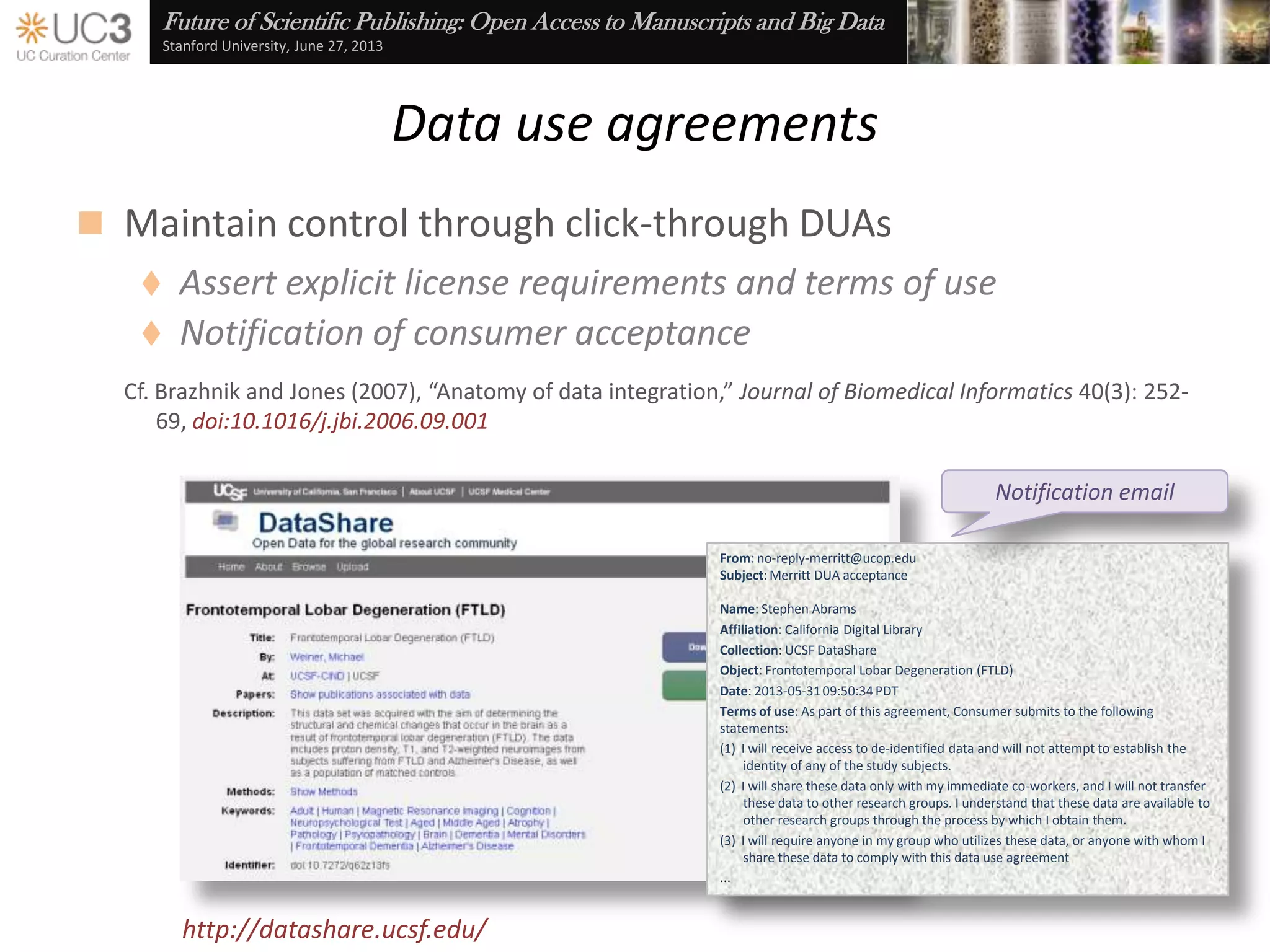

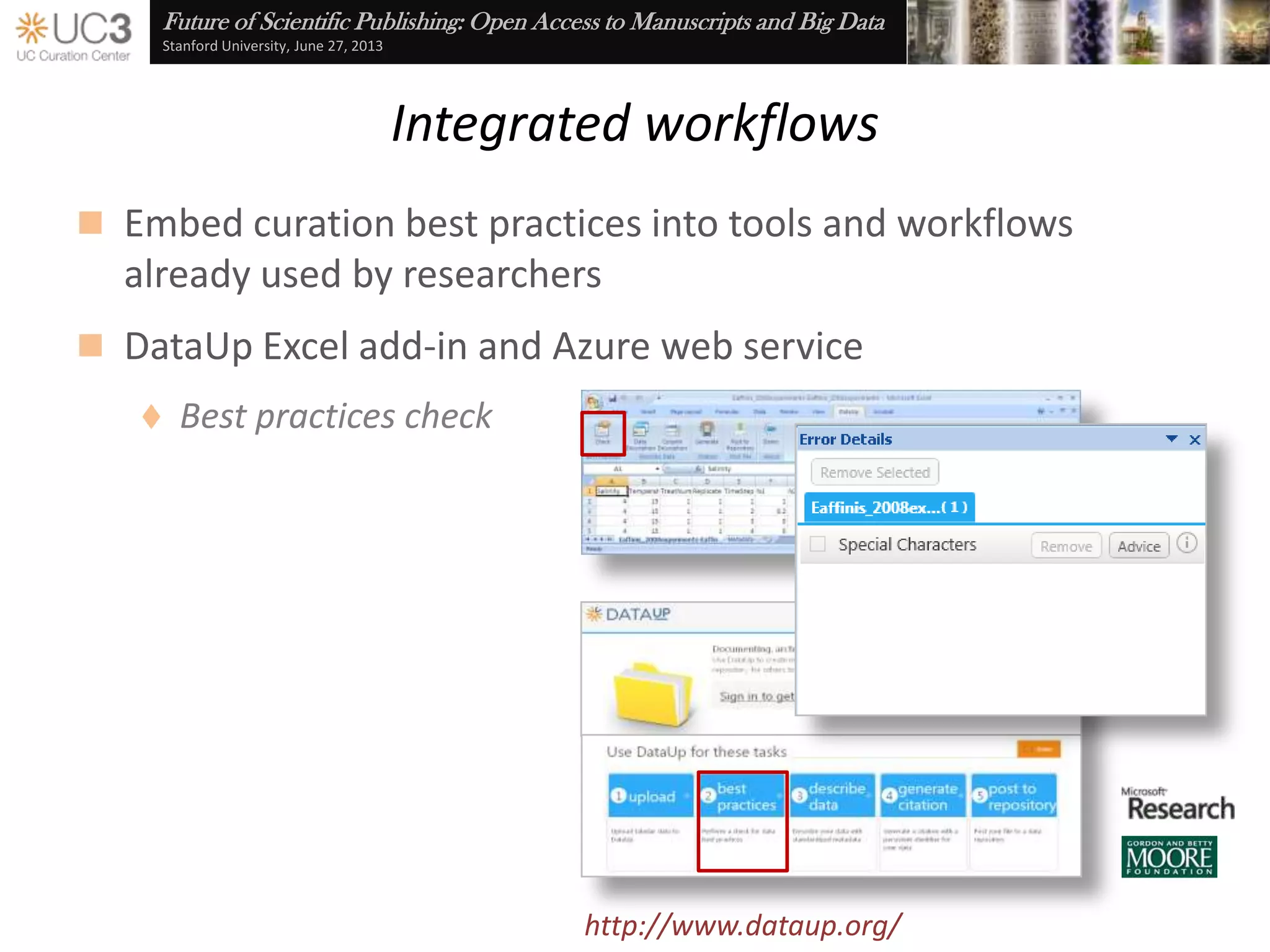
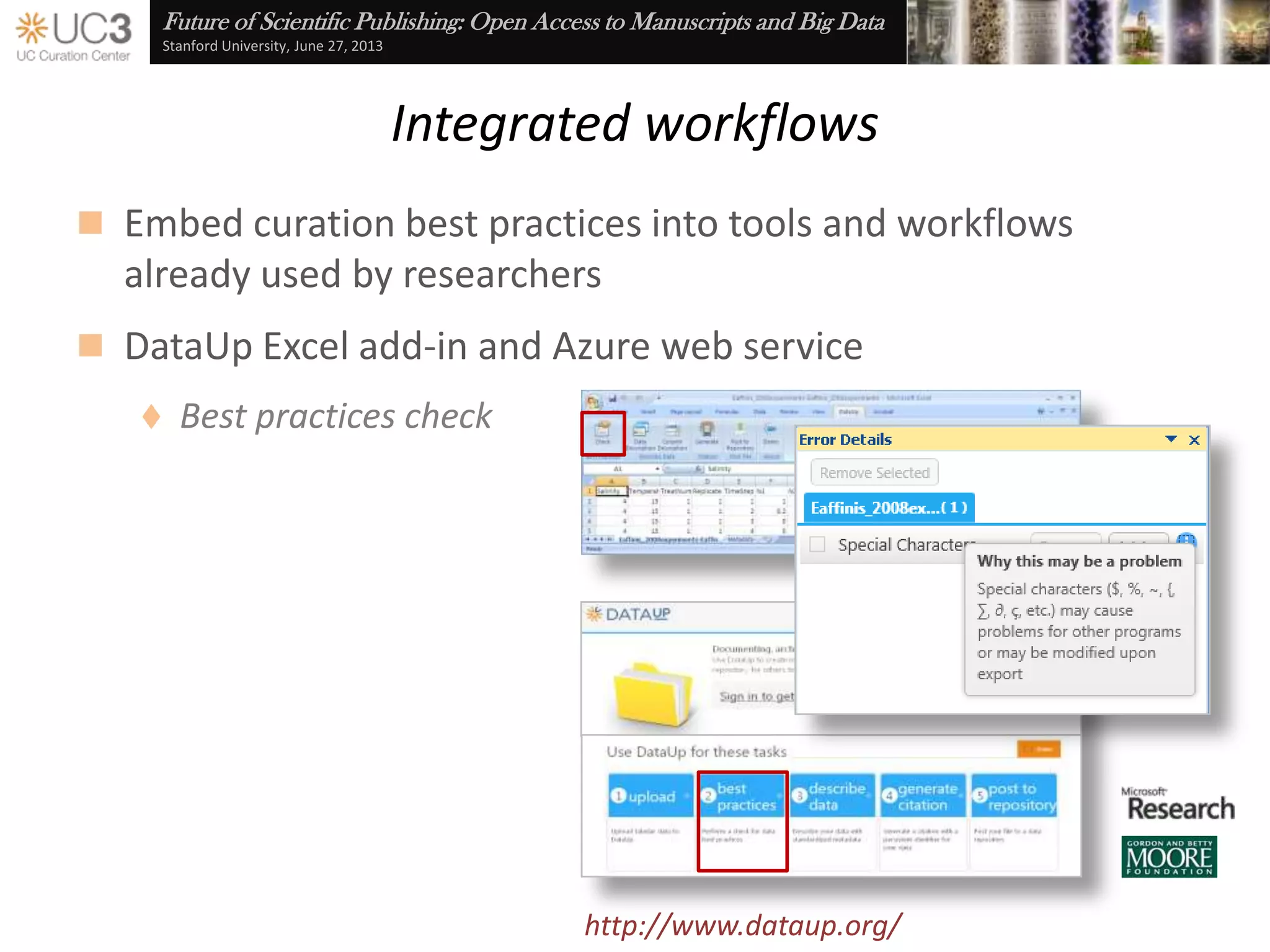
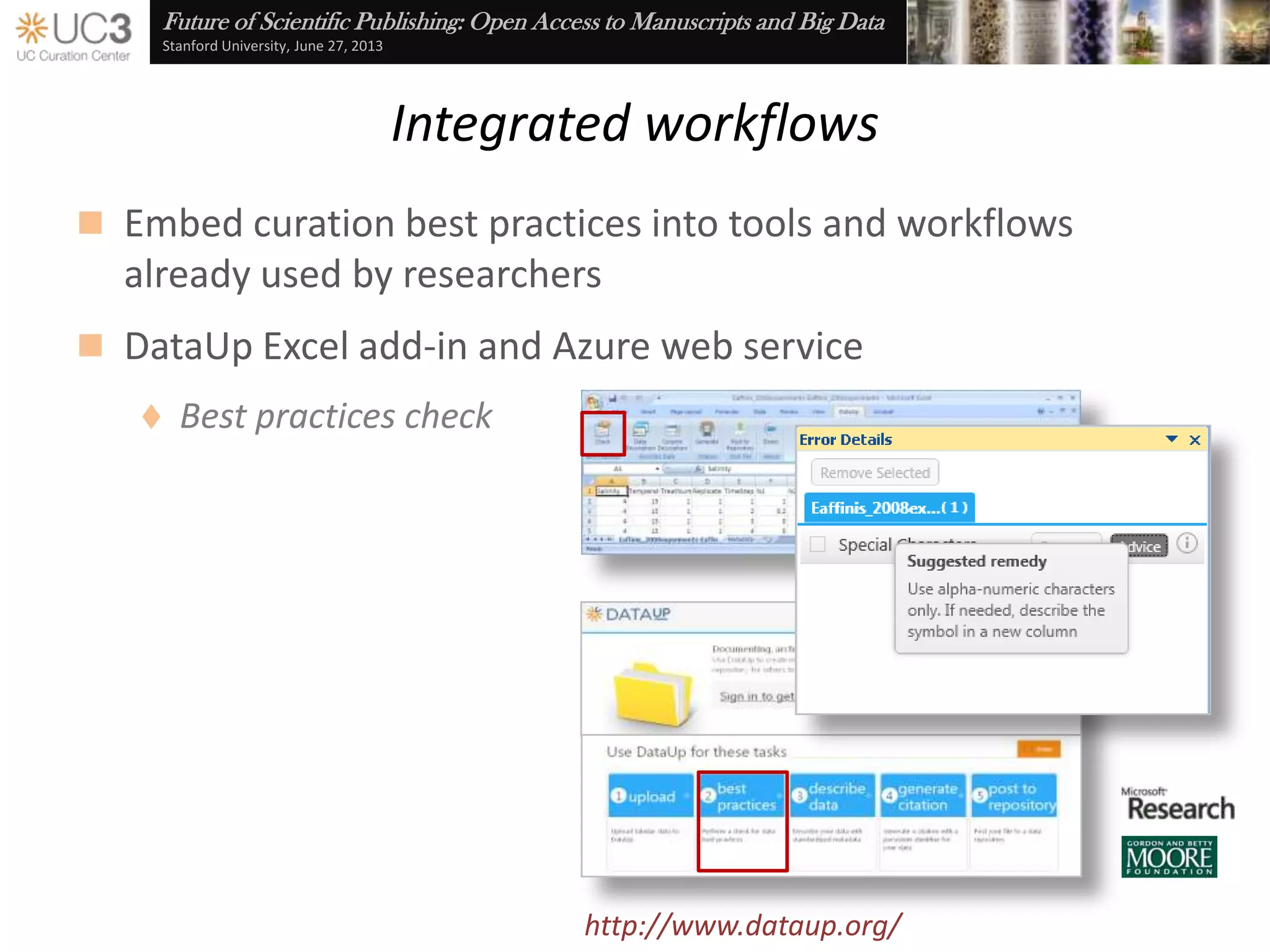
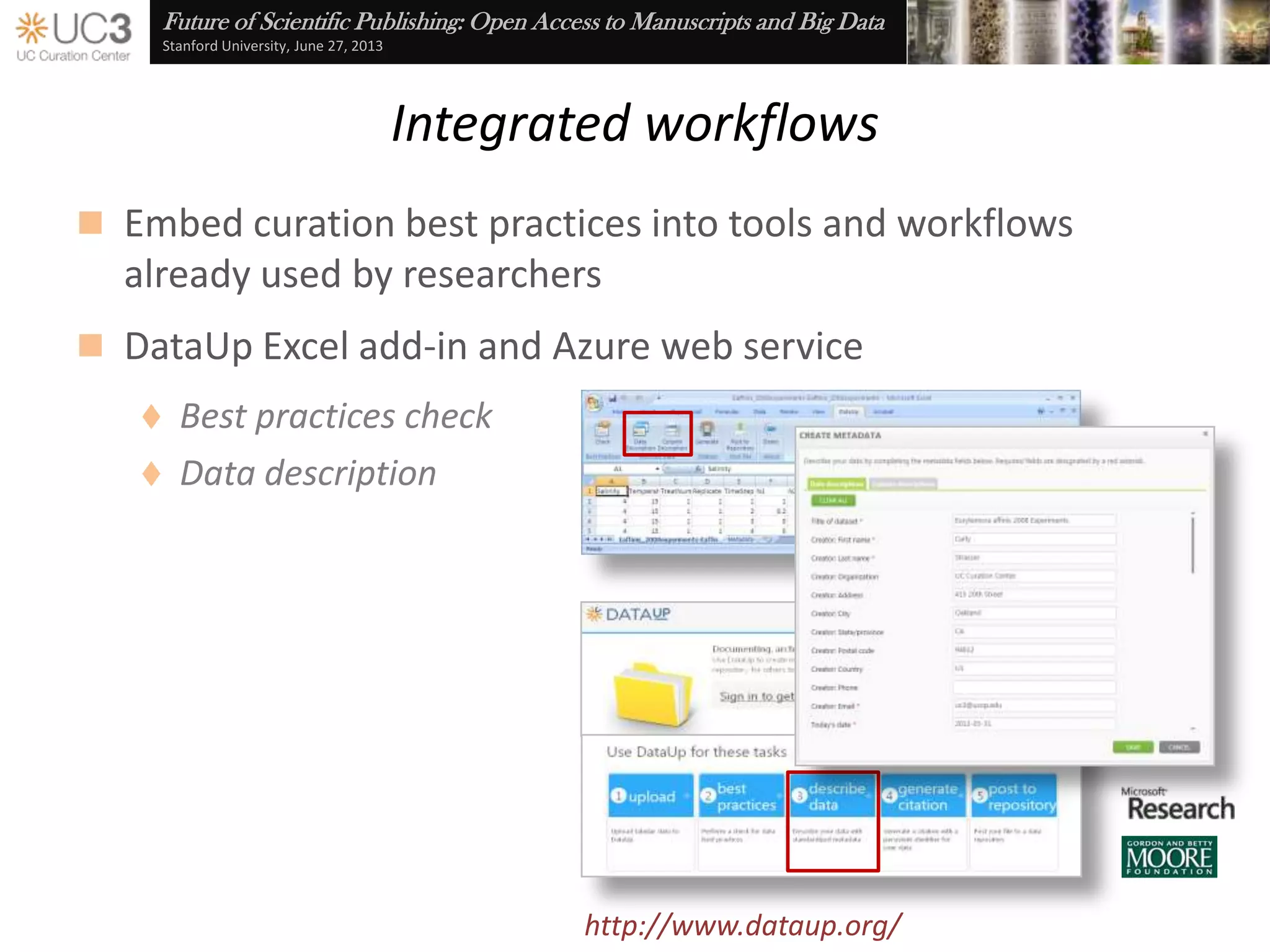
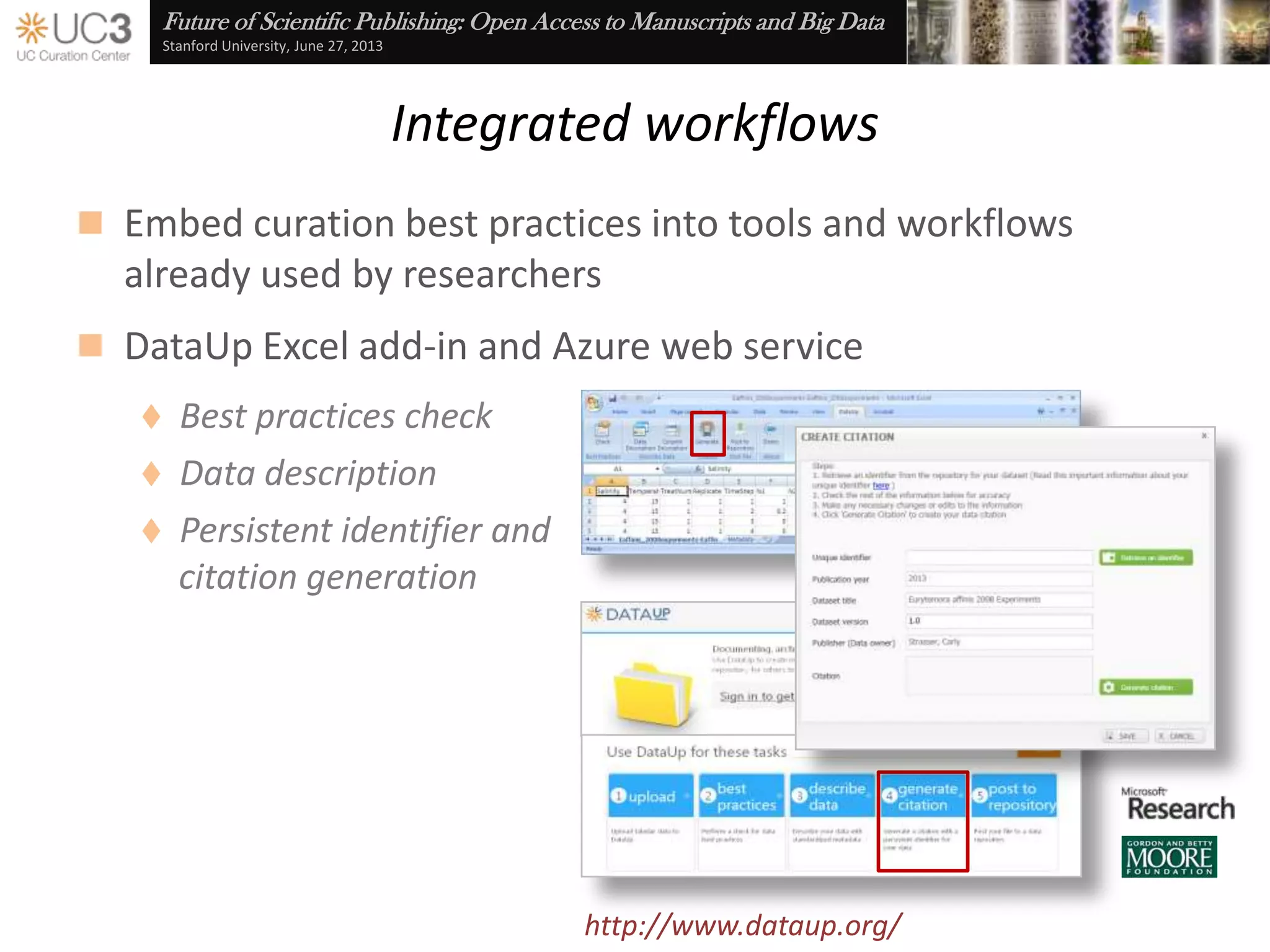
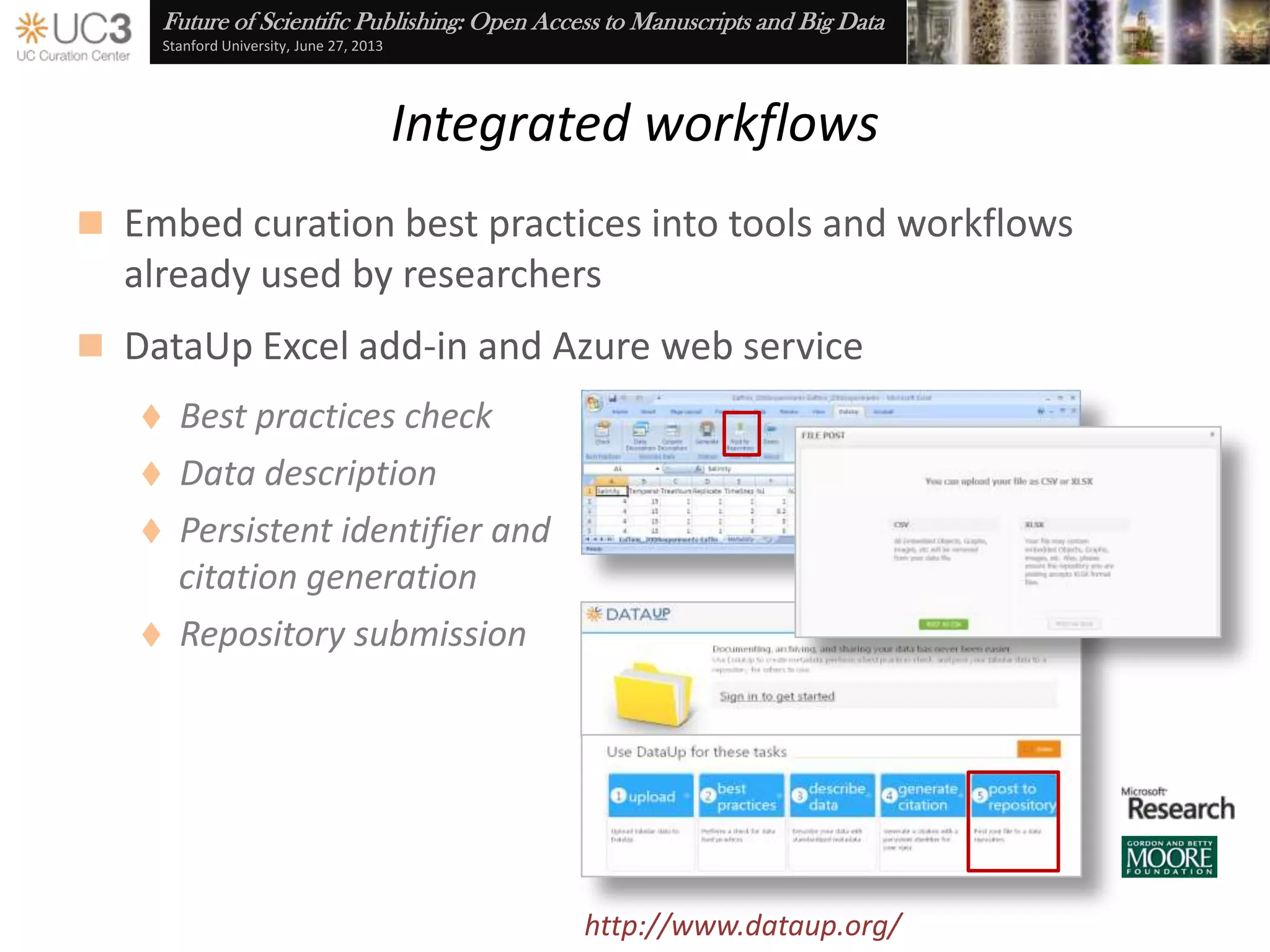
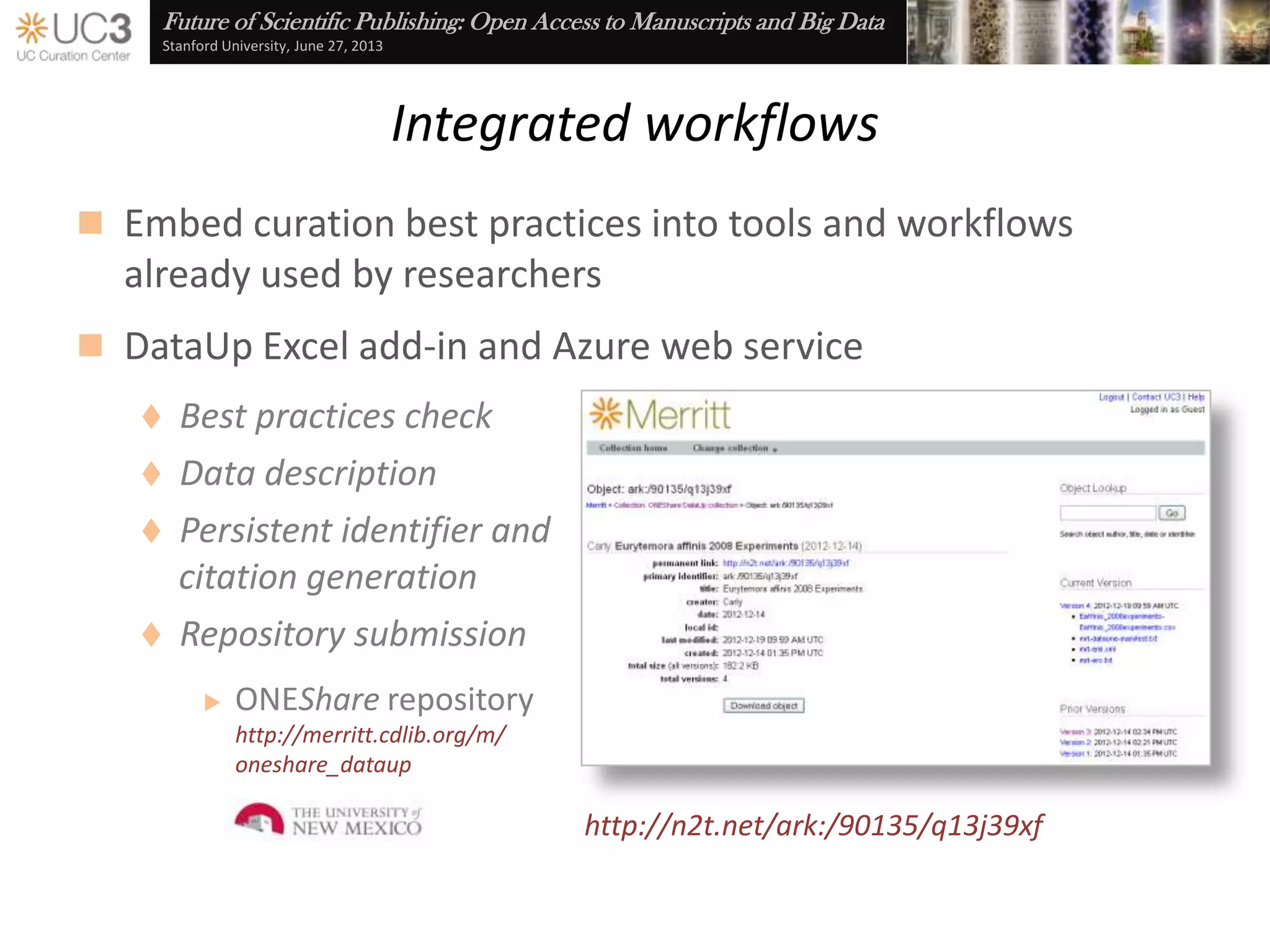

The document discusses the importance of data curation for scientific progress and integrity. It outlines the library's role in connecting researchers to content and supporting the research lifecycle. Barriers to data sharing like poor discovery, unfamiliar processes, and loss of control can be addressed through tools and services that provide identifiers, metadata, data use agreements, and data management planning guidance. Embedding best practices into existing researcher tools and workflows can help promote data curation.








































































































