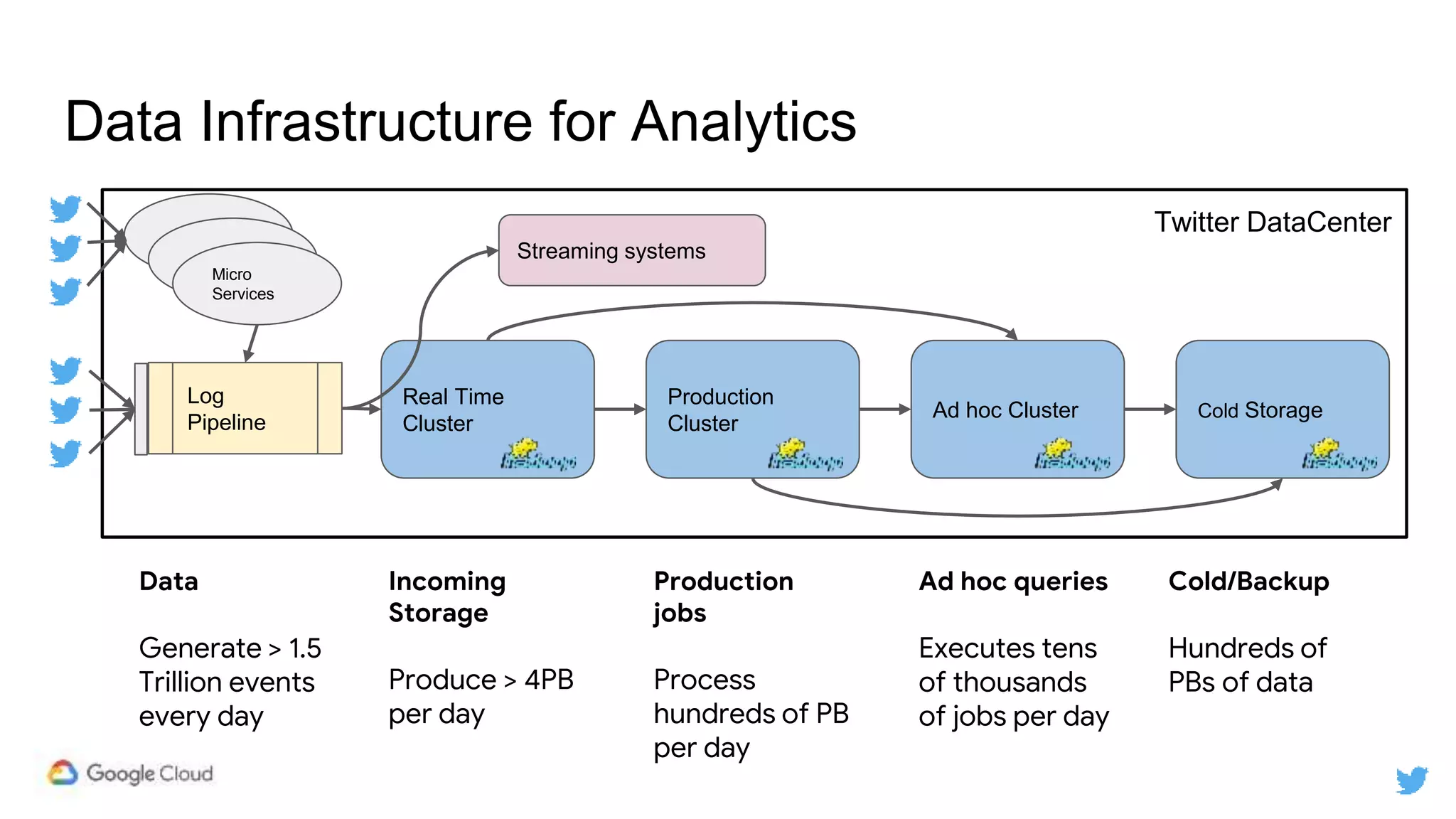
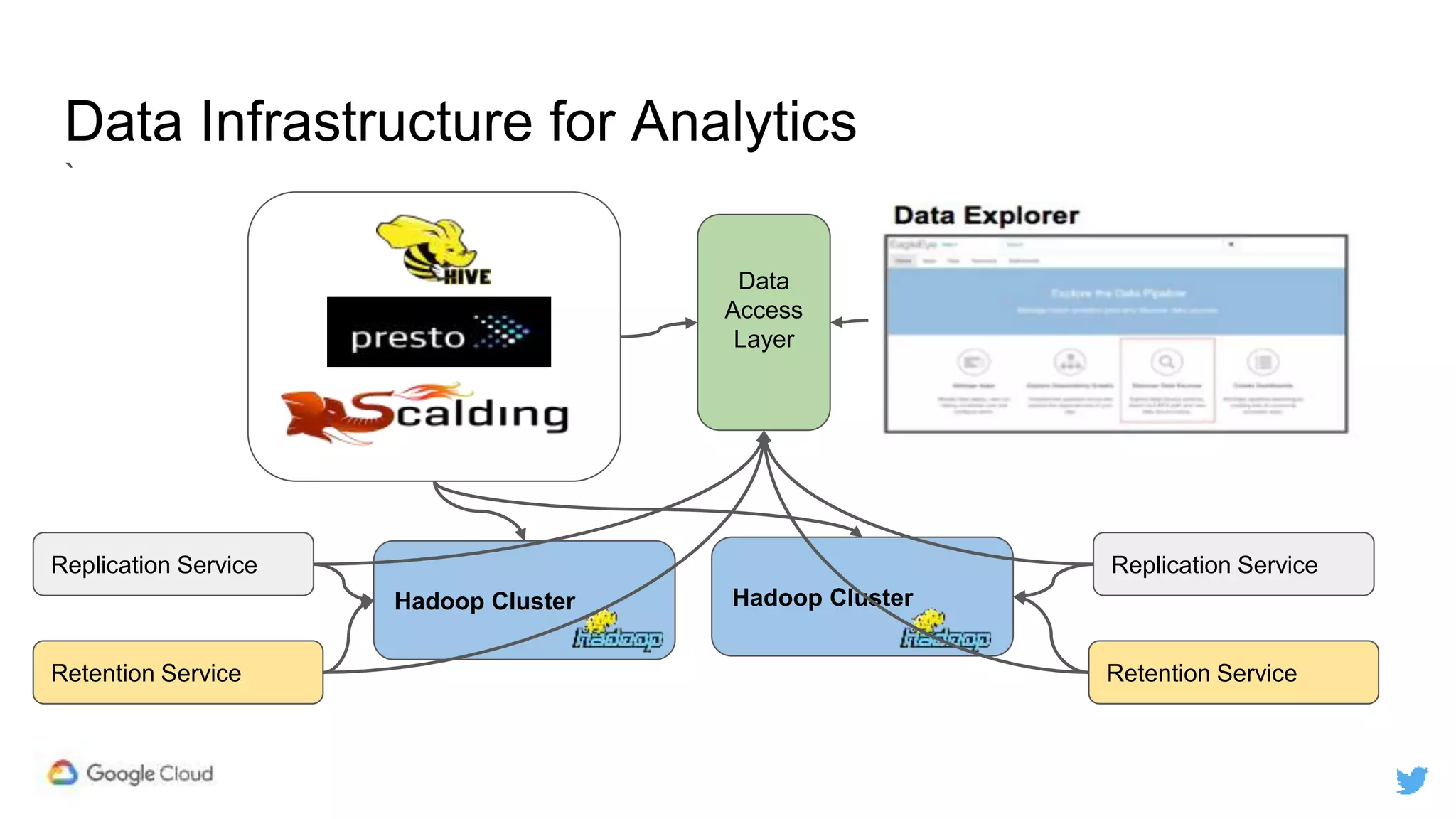
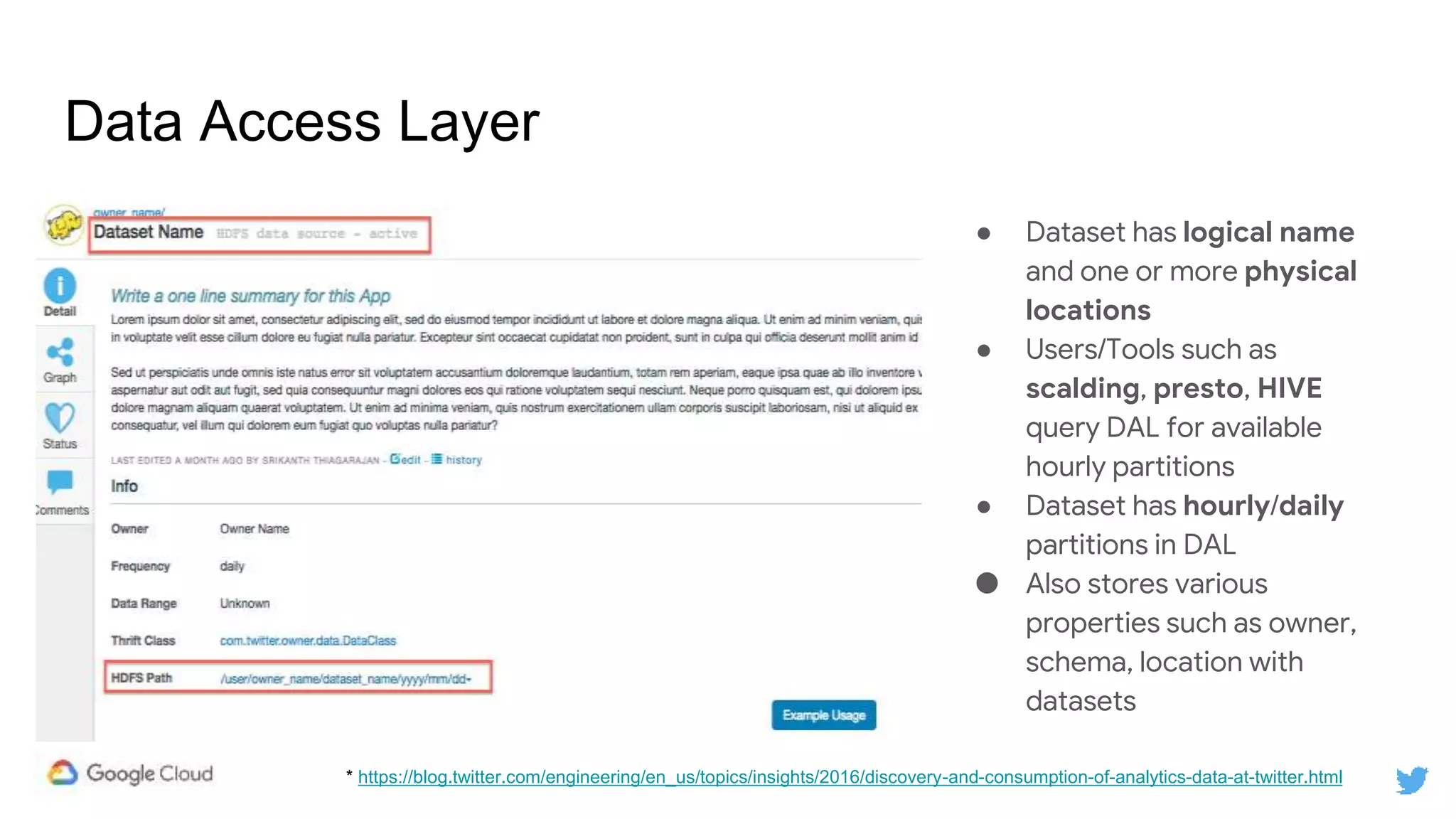
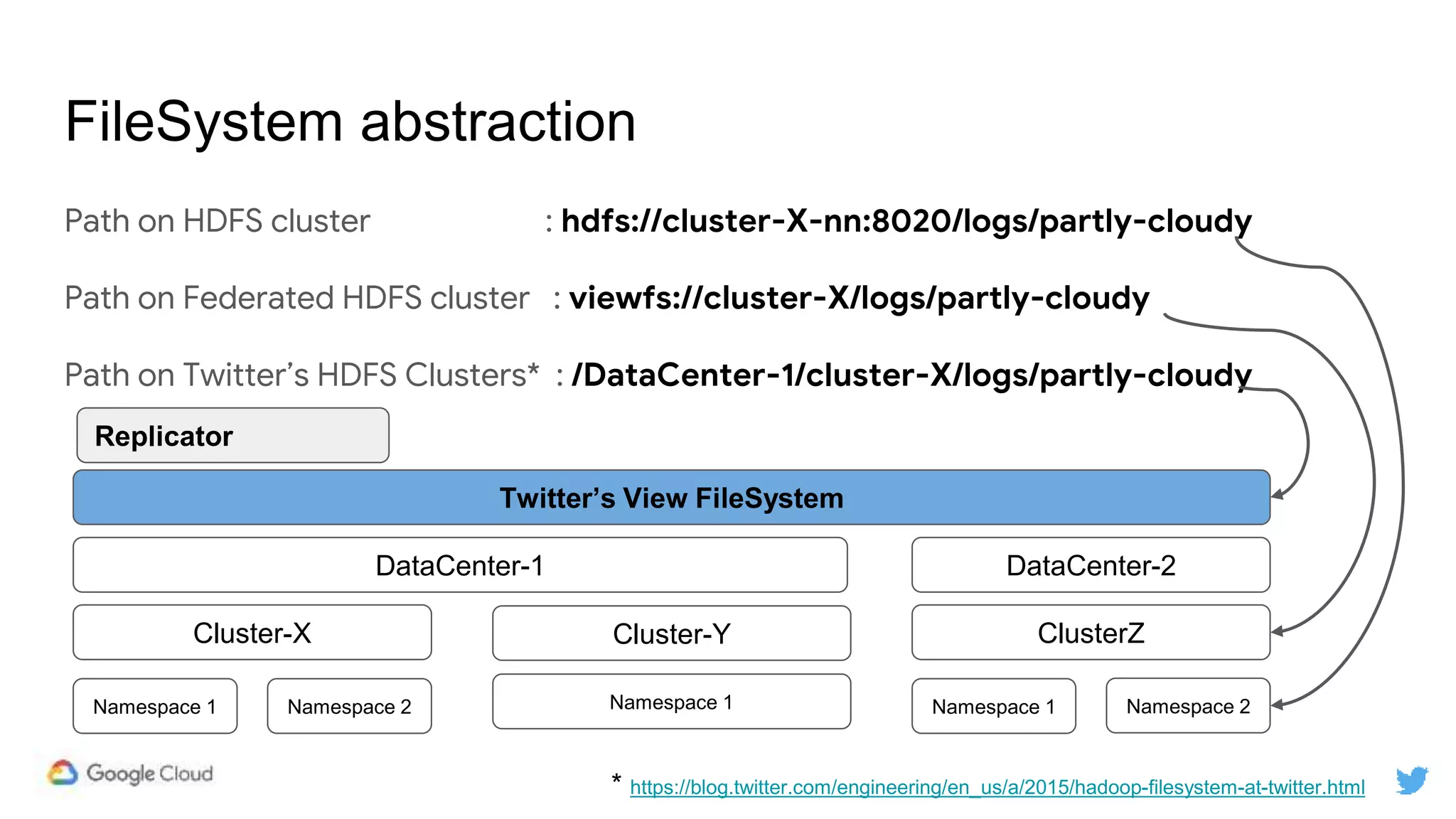
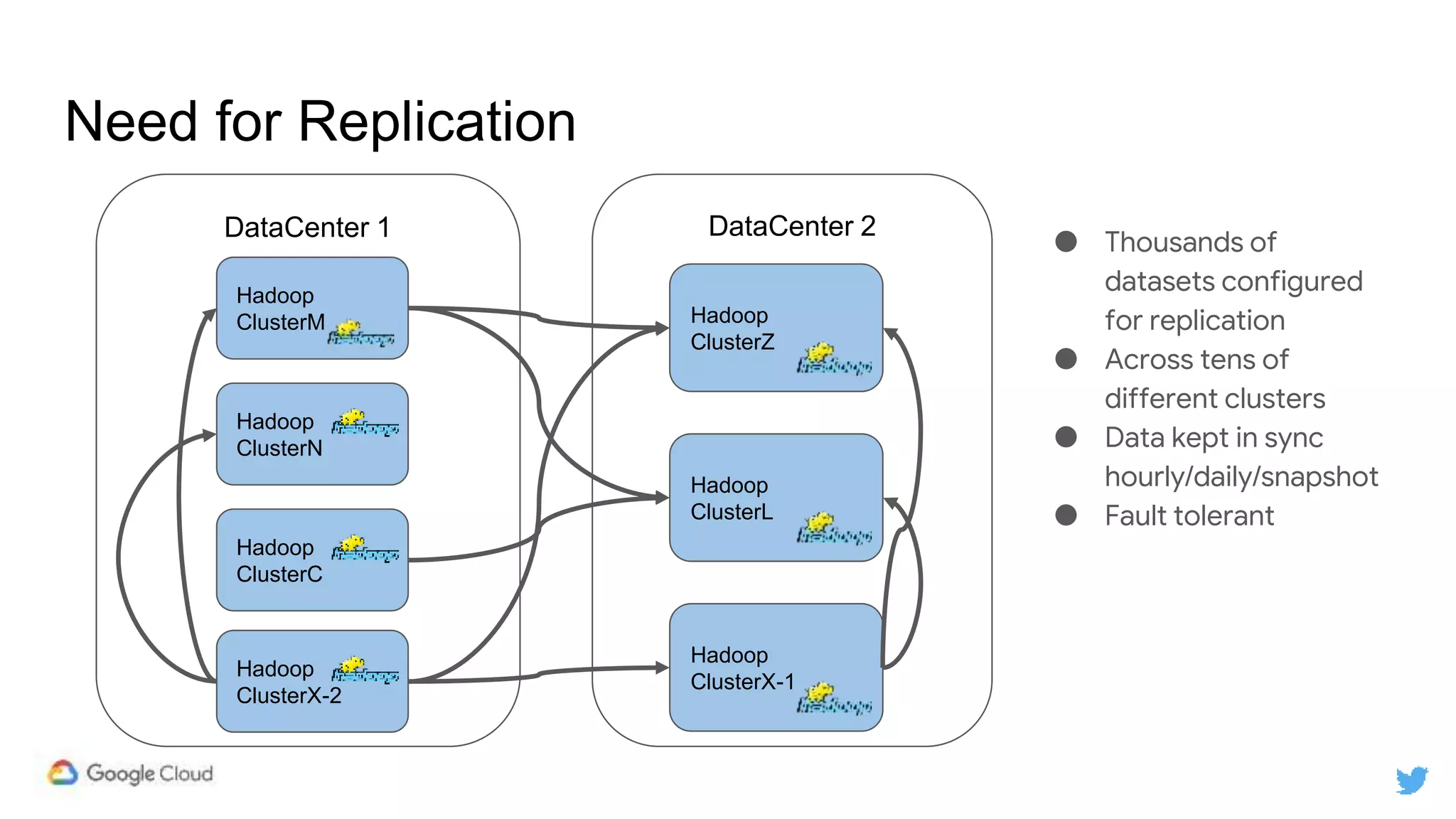
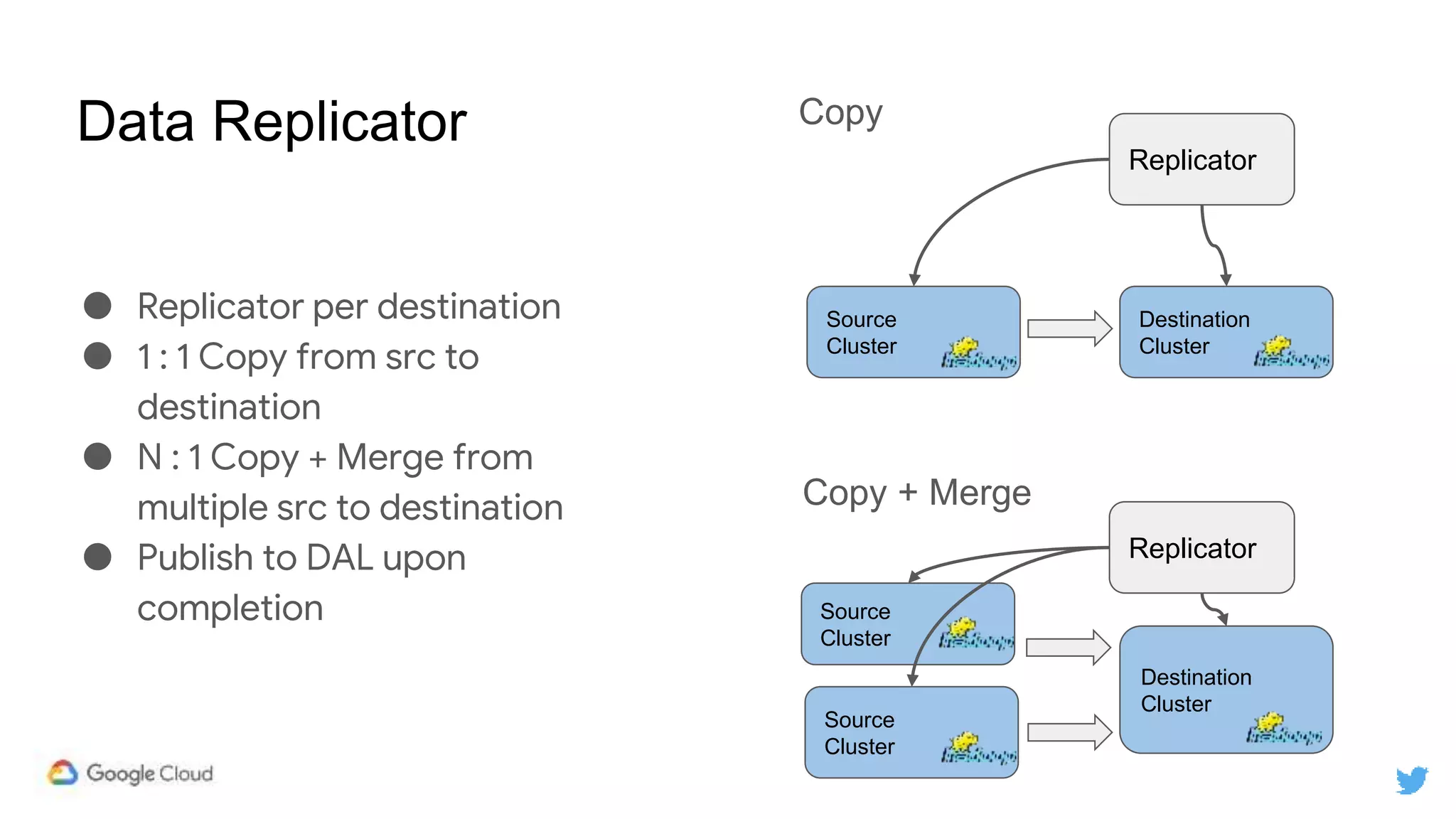
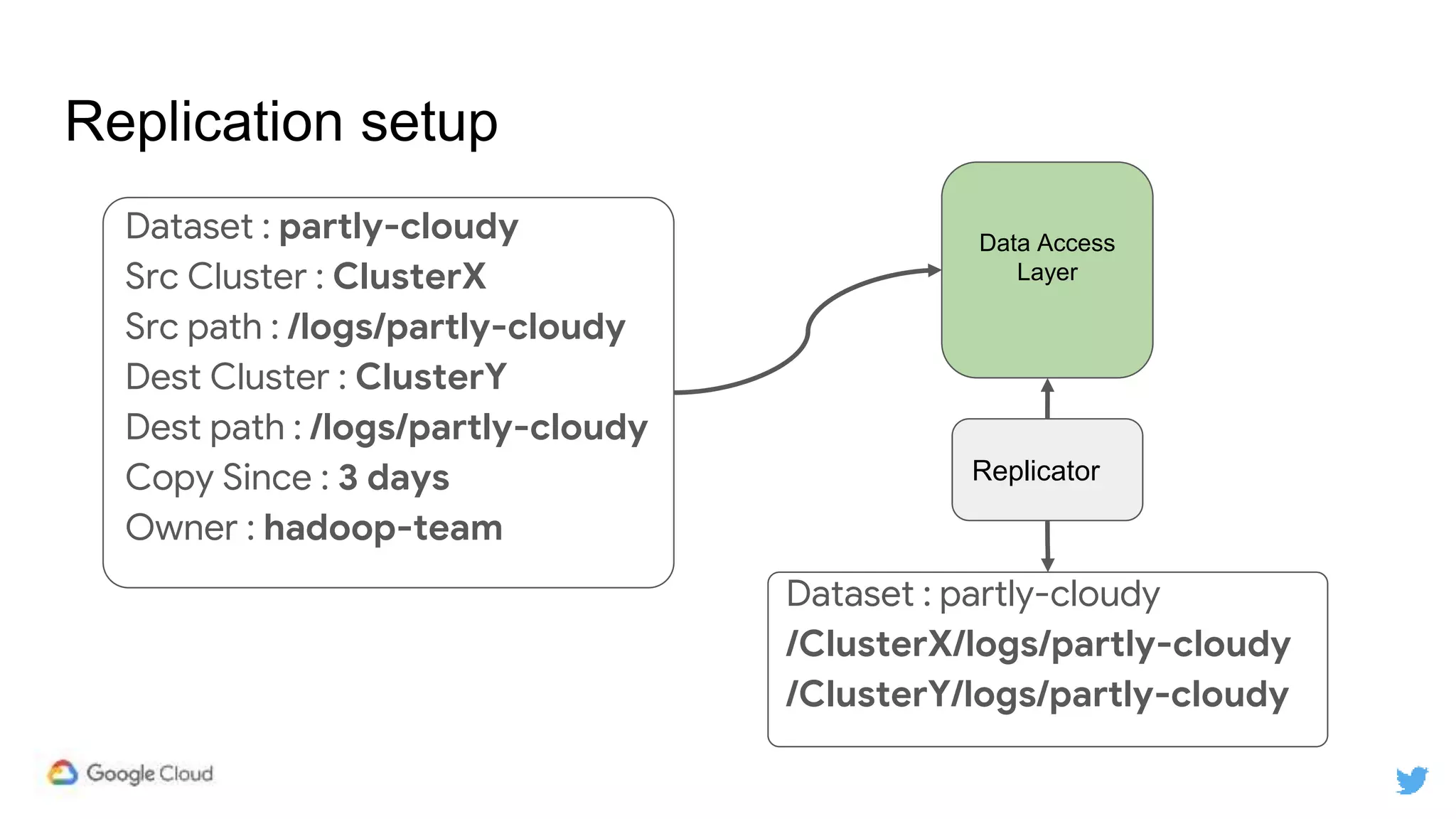
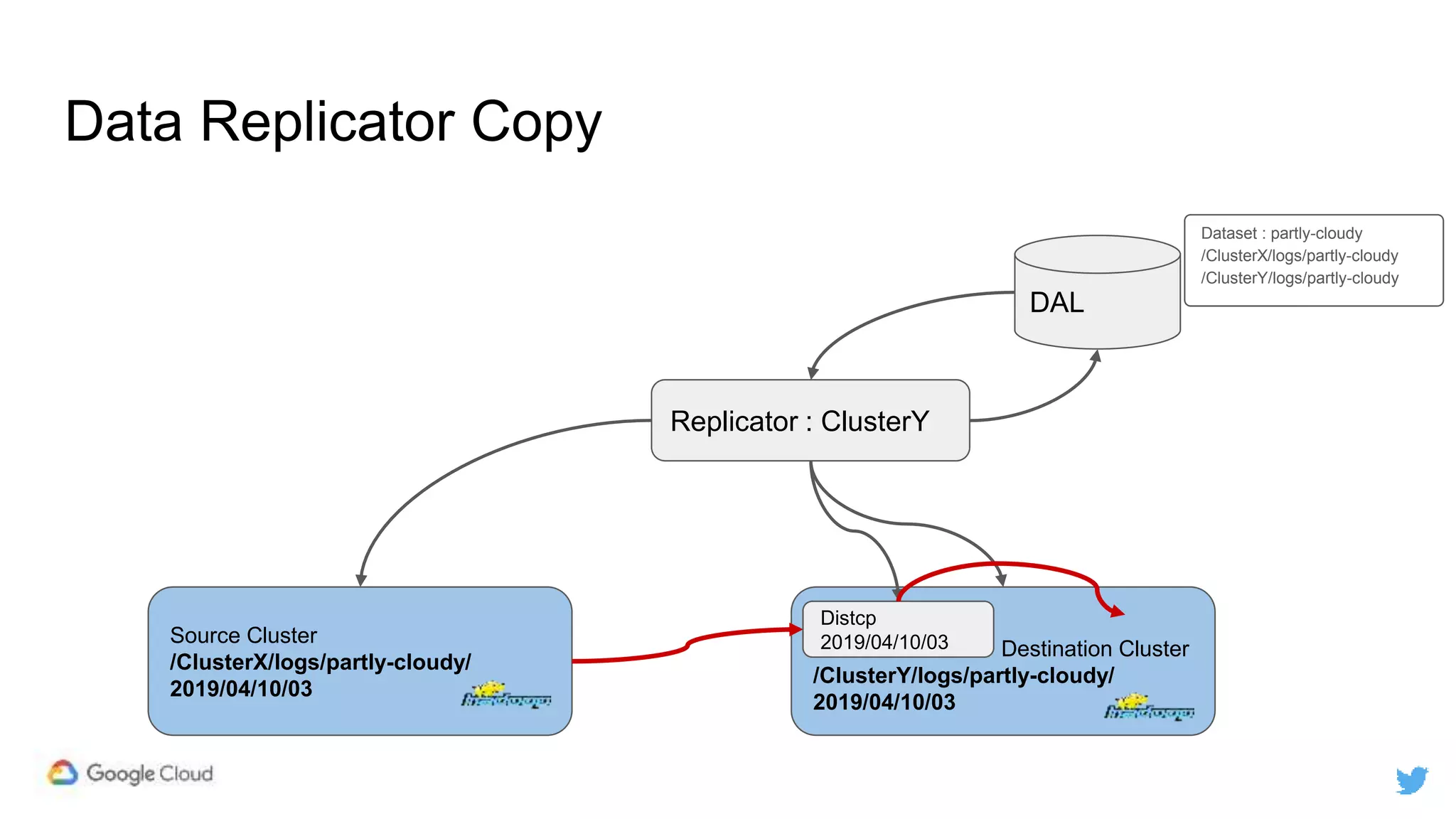
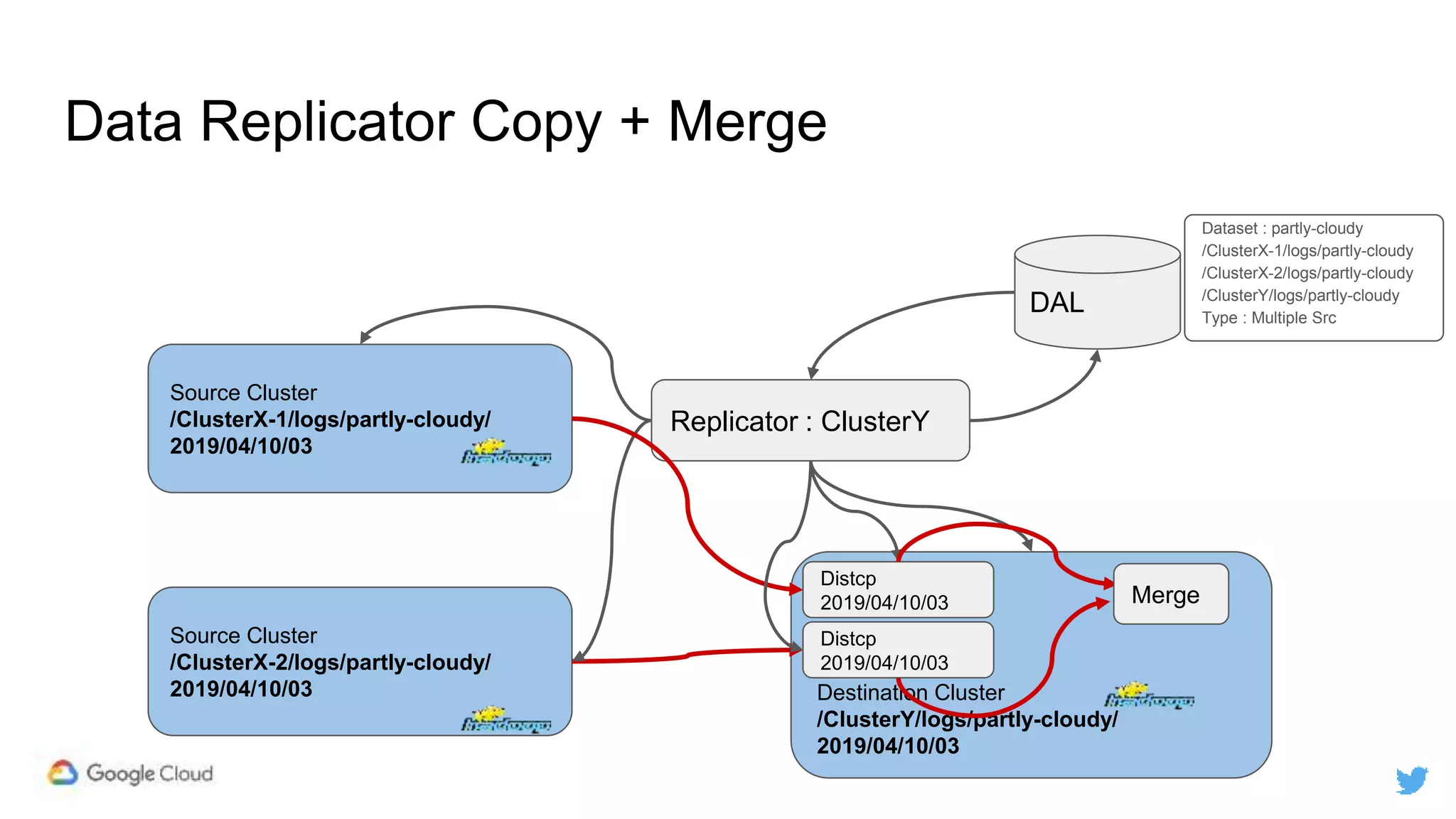
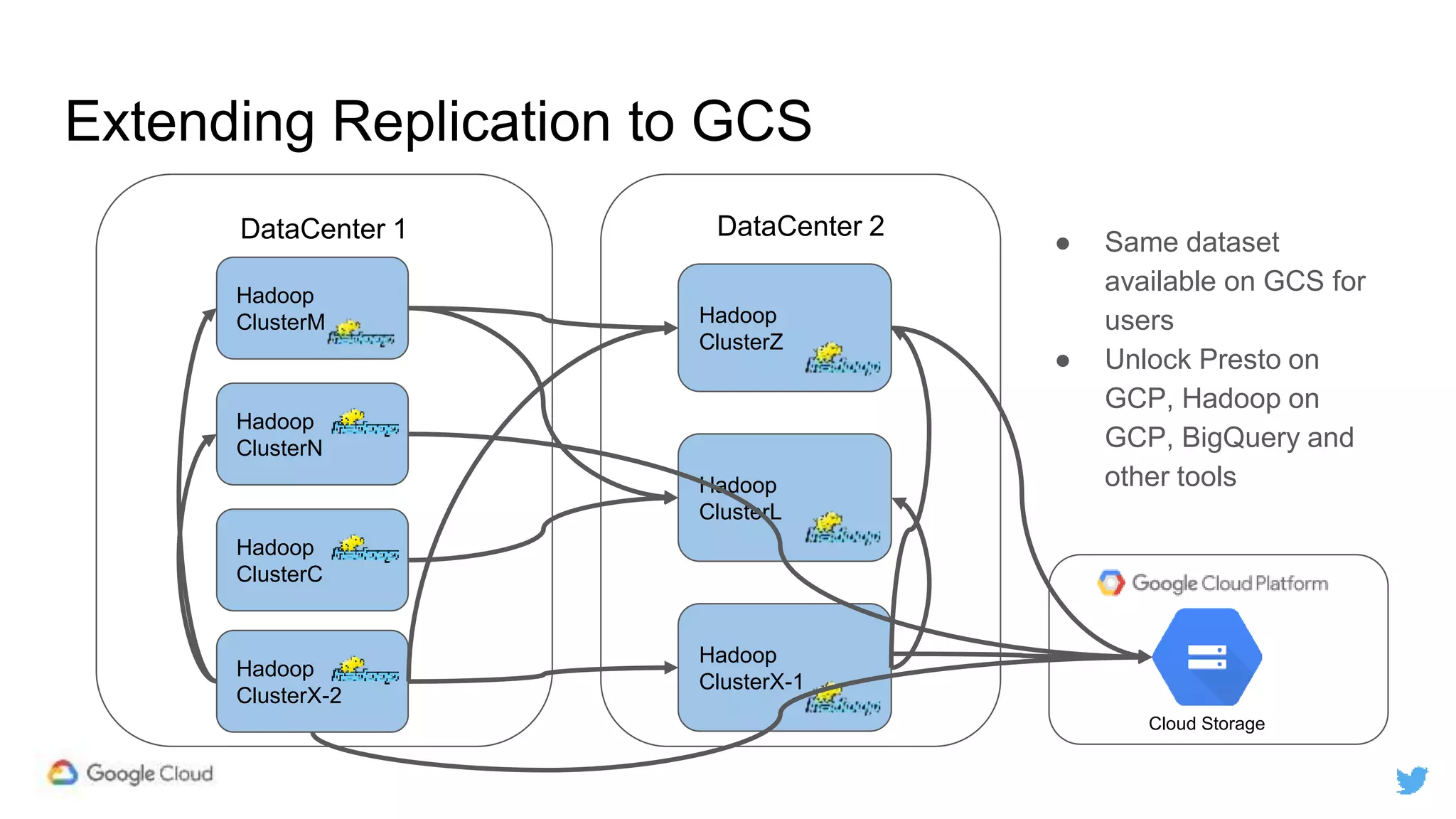
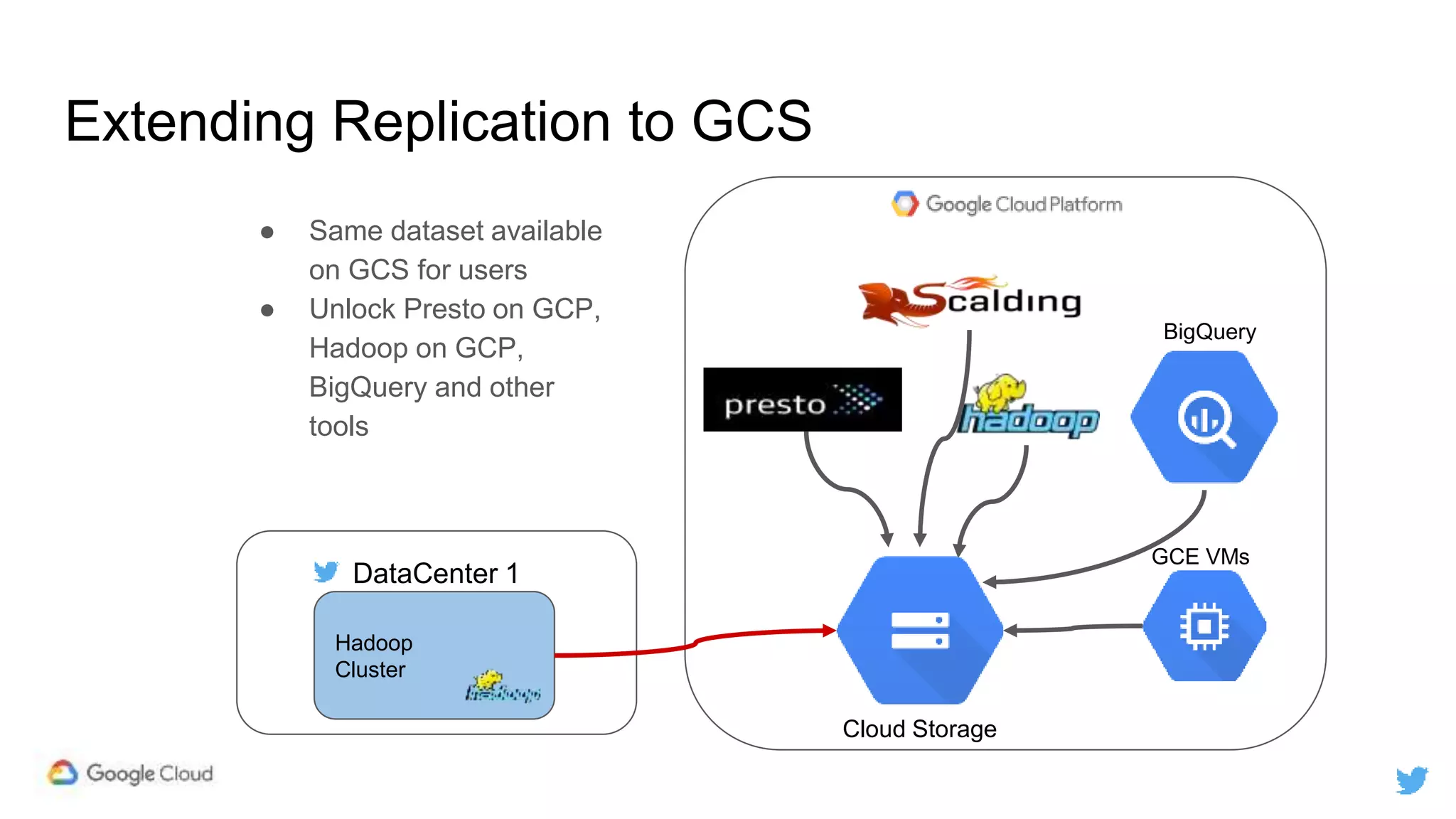
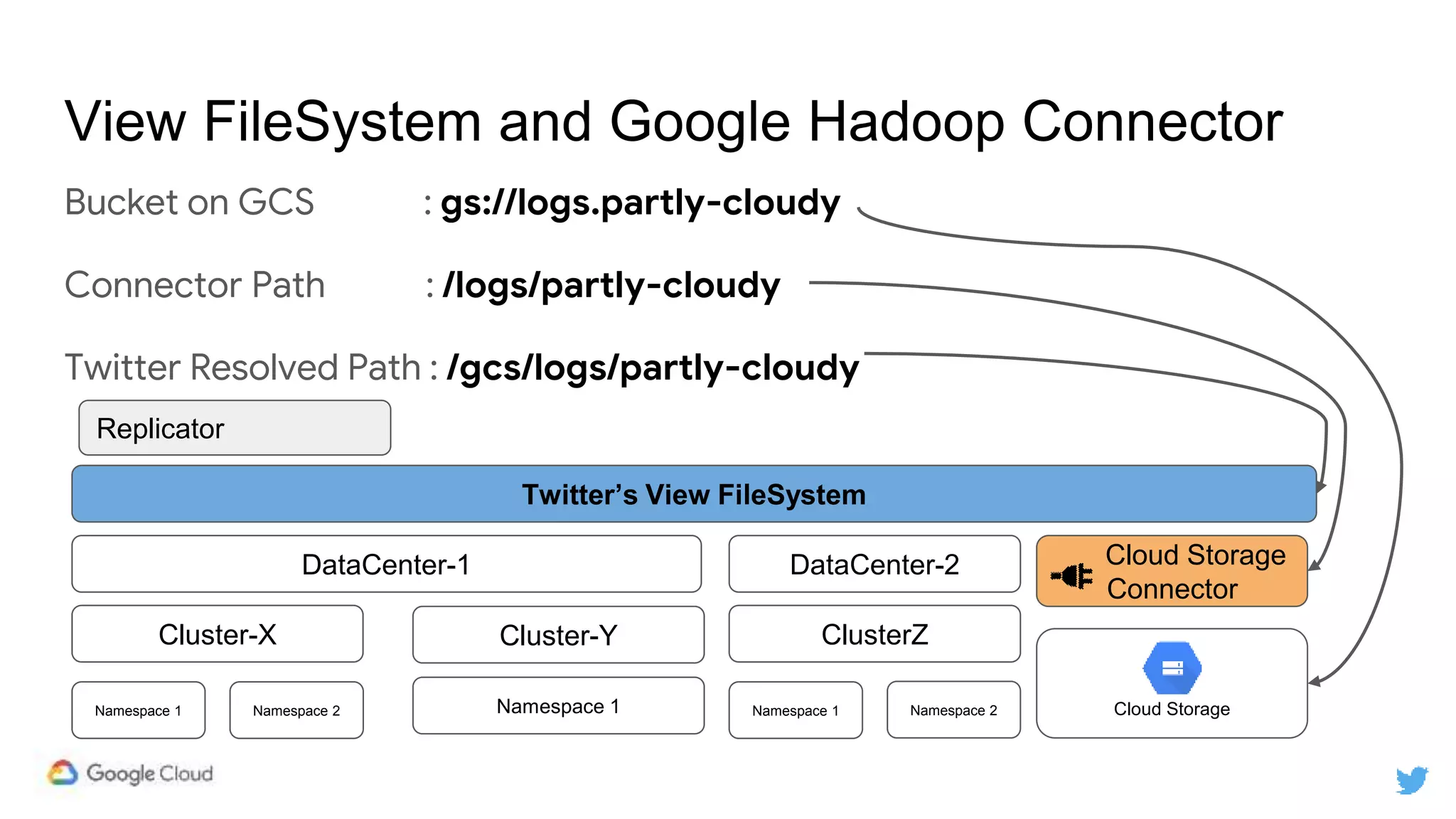
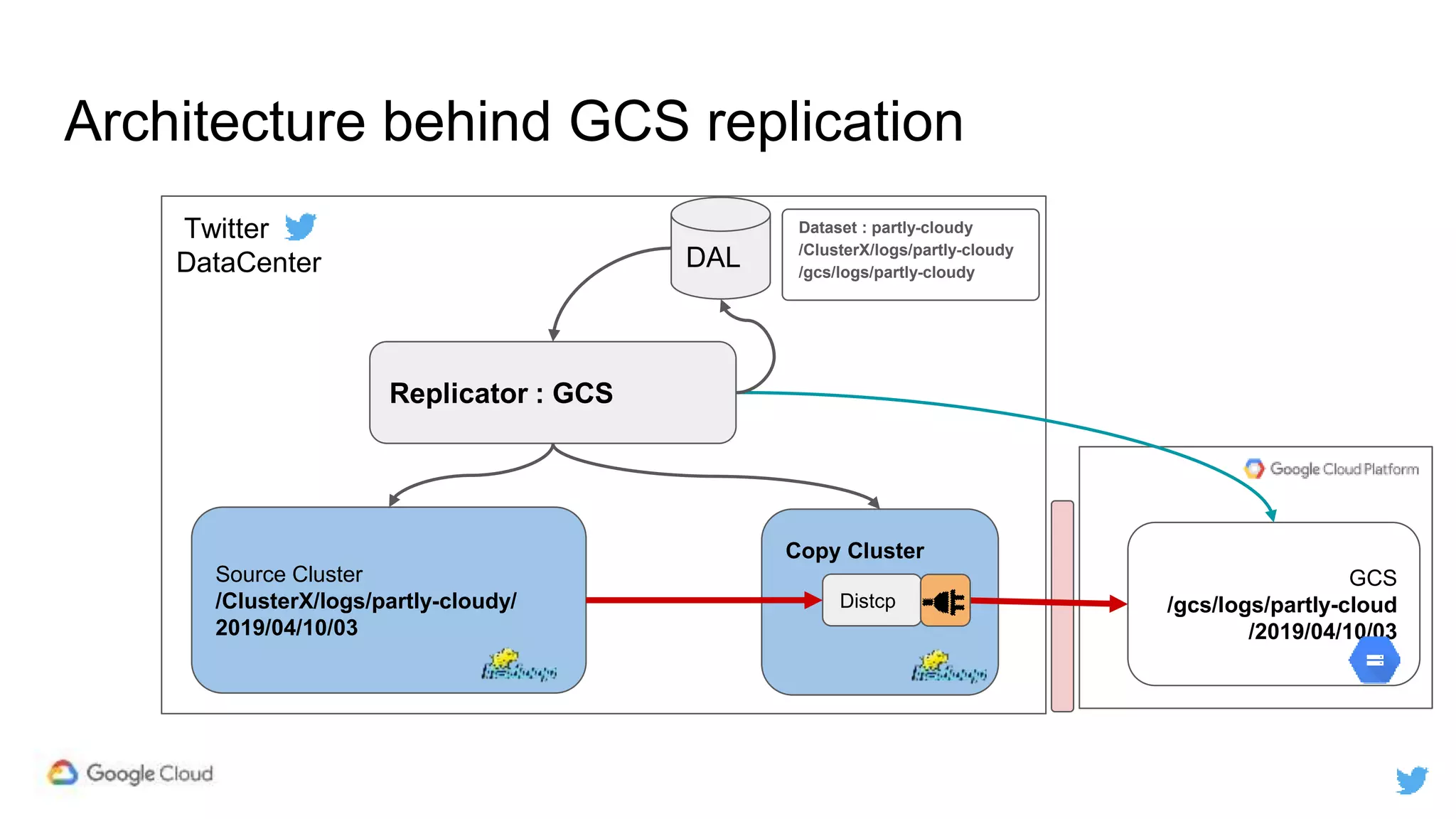
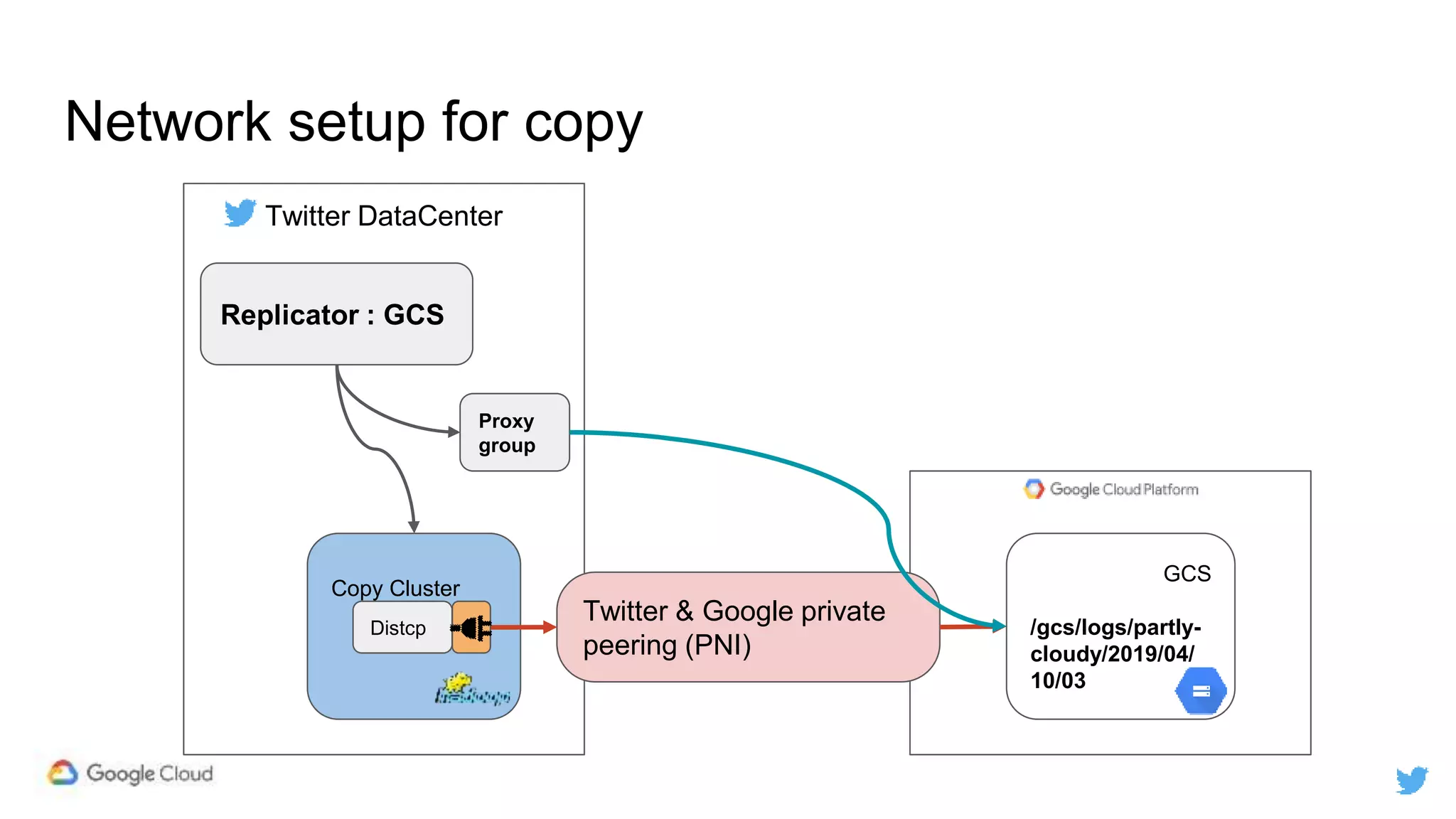
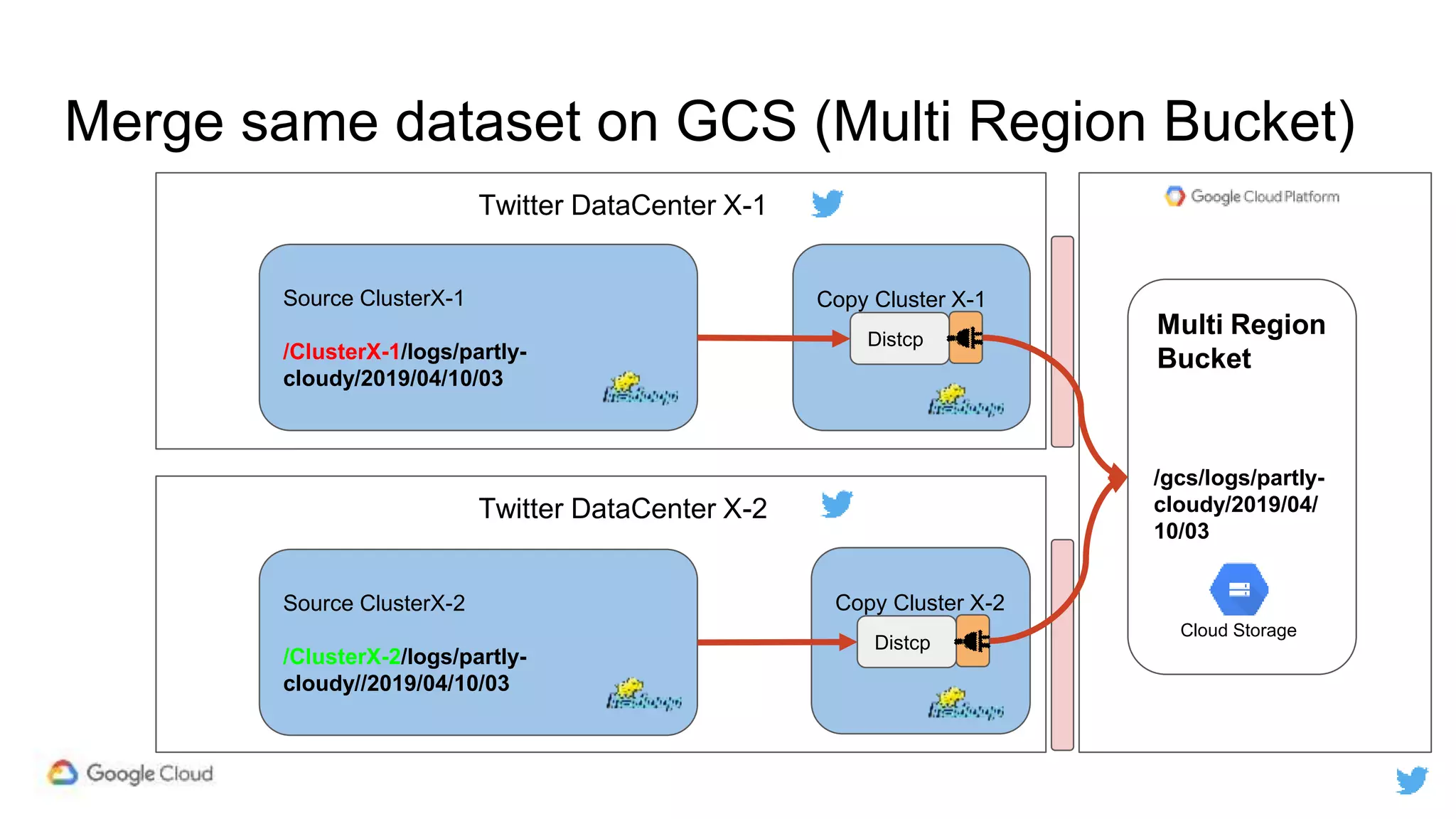
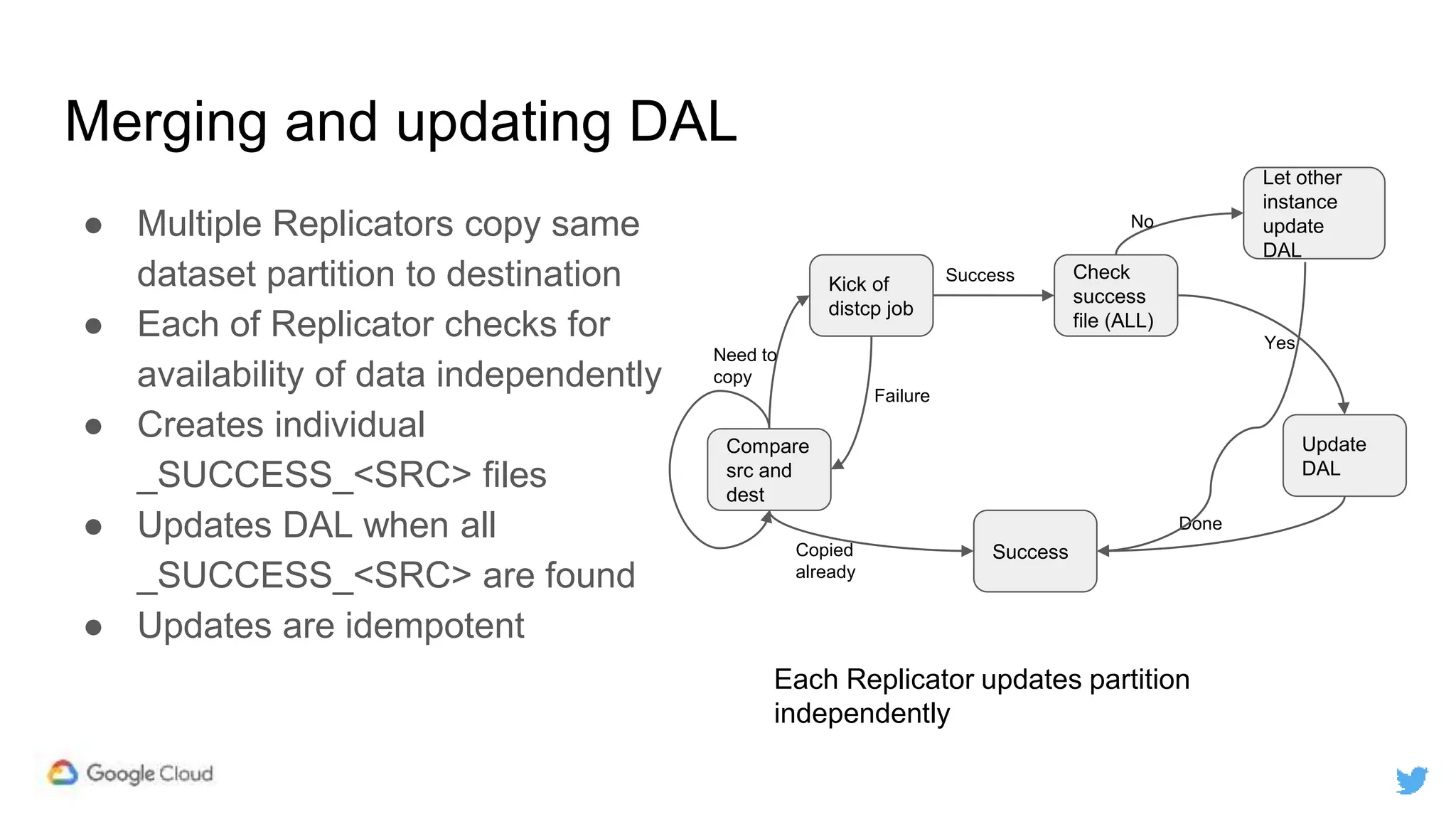
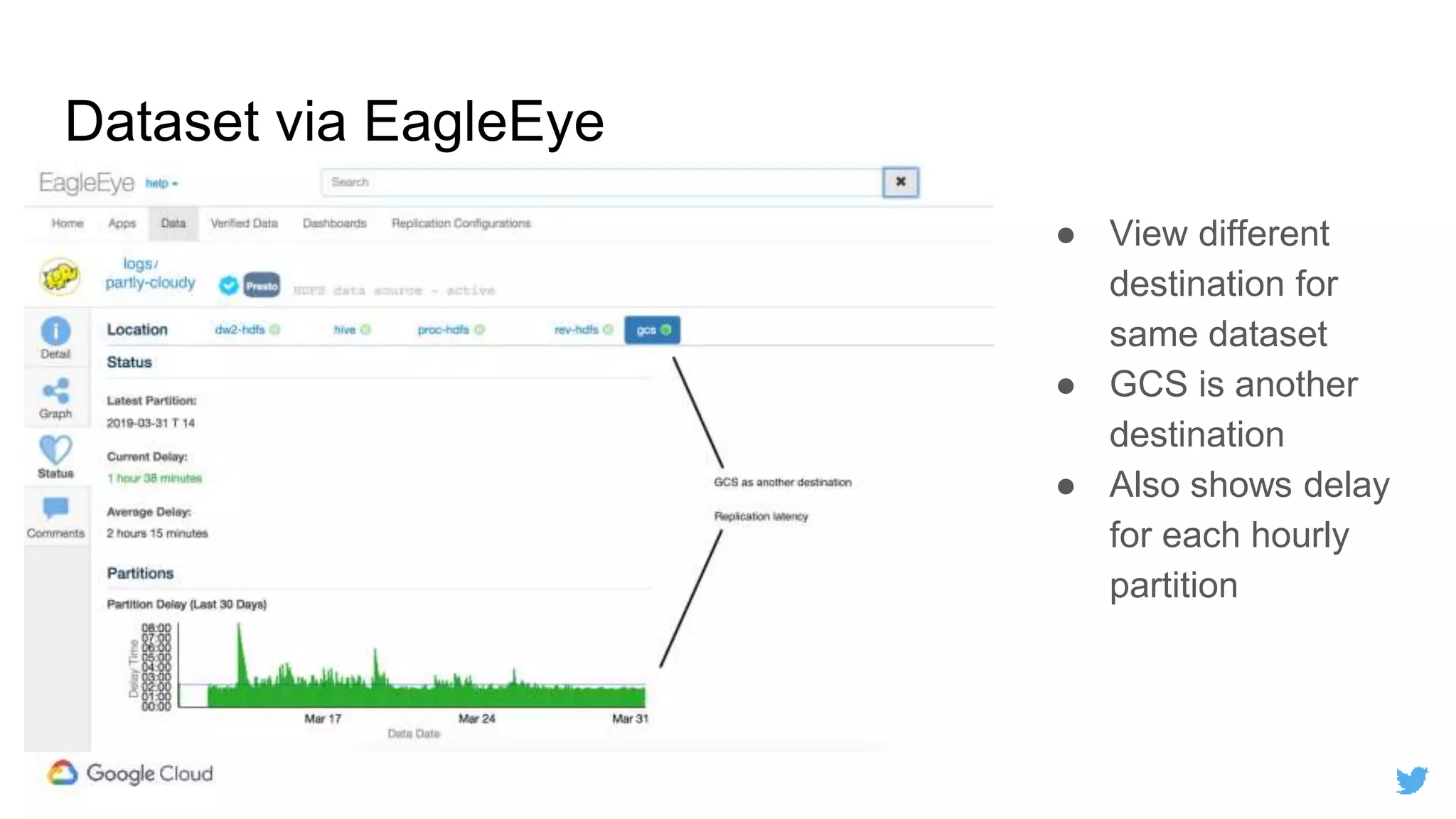
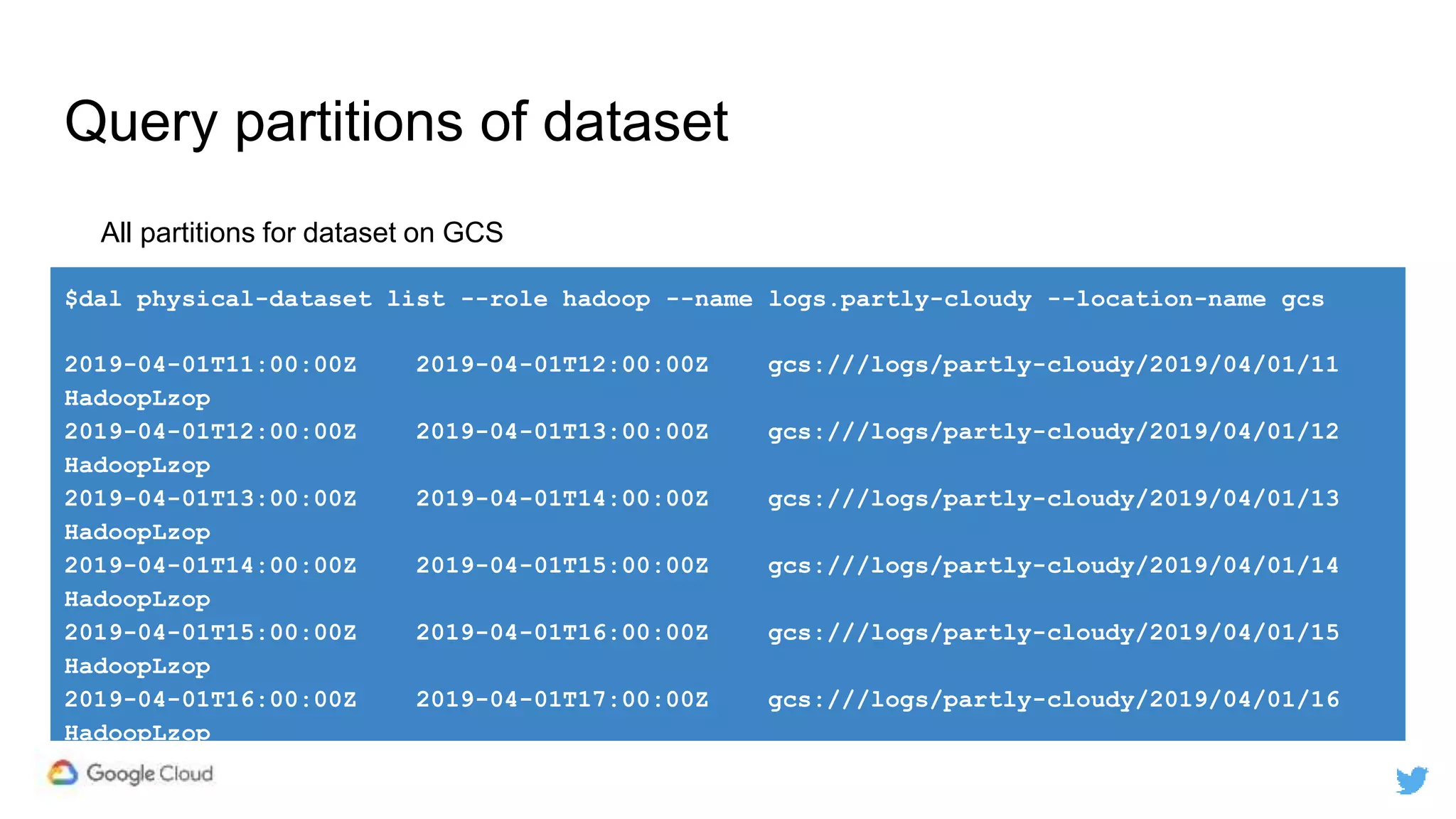
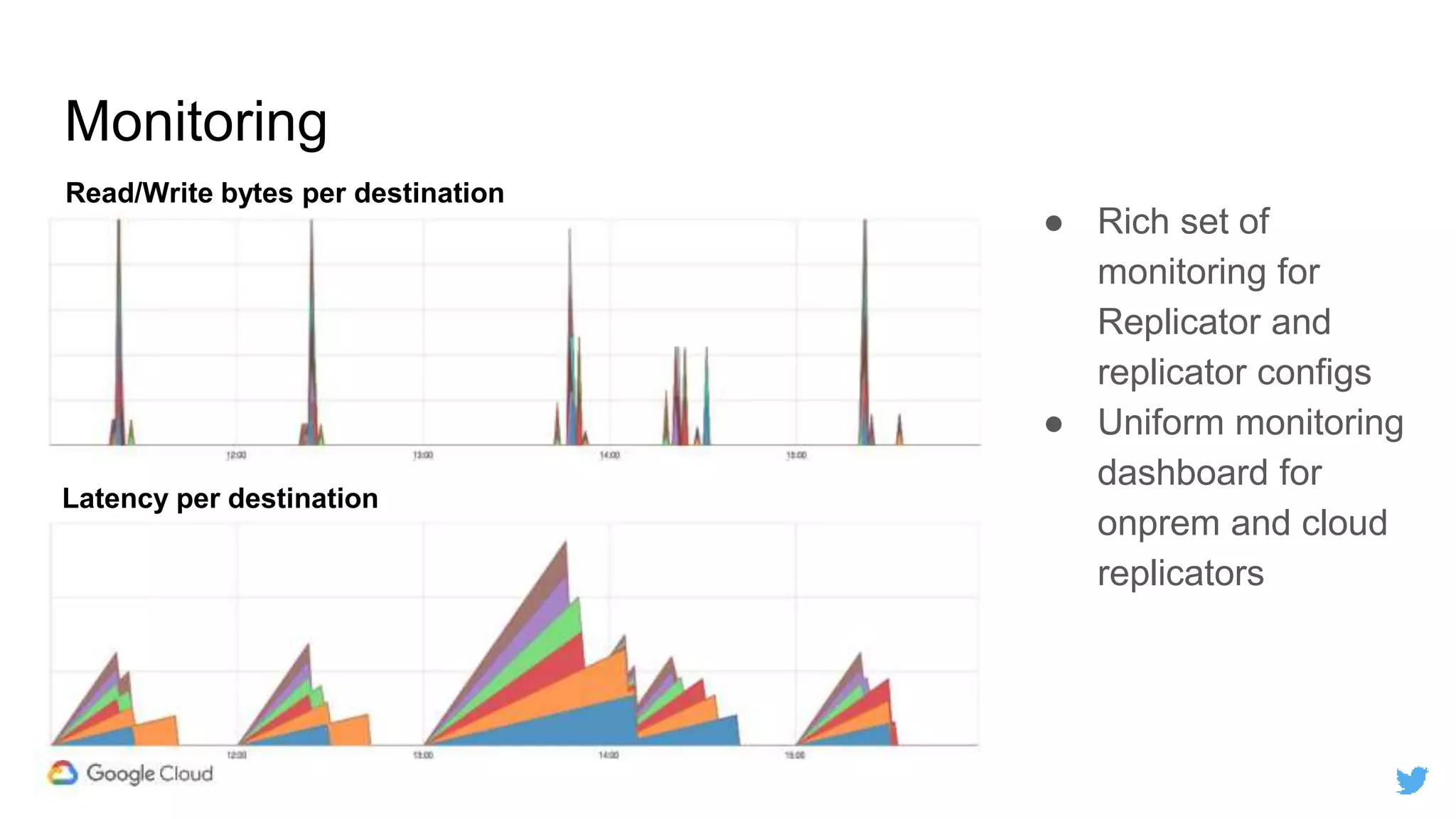
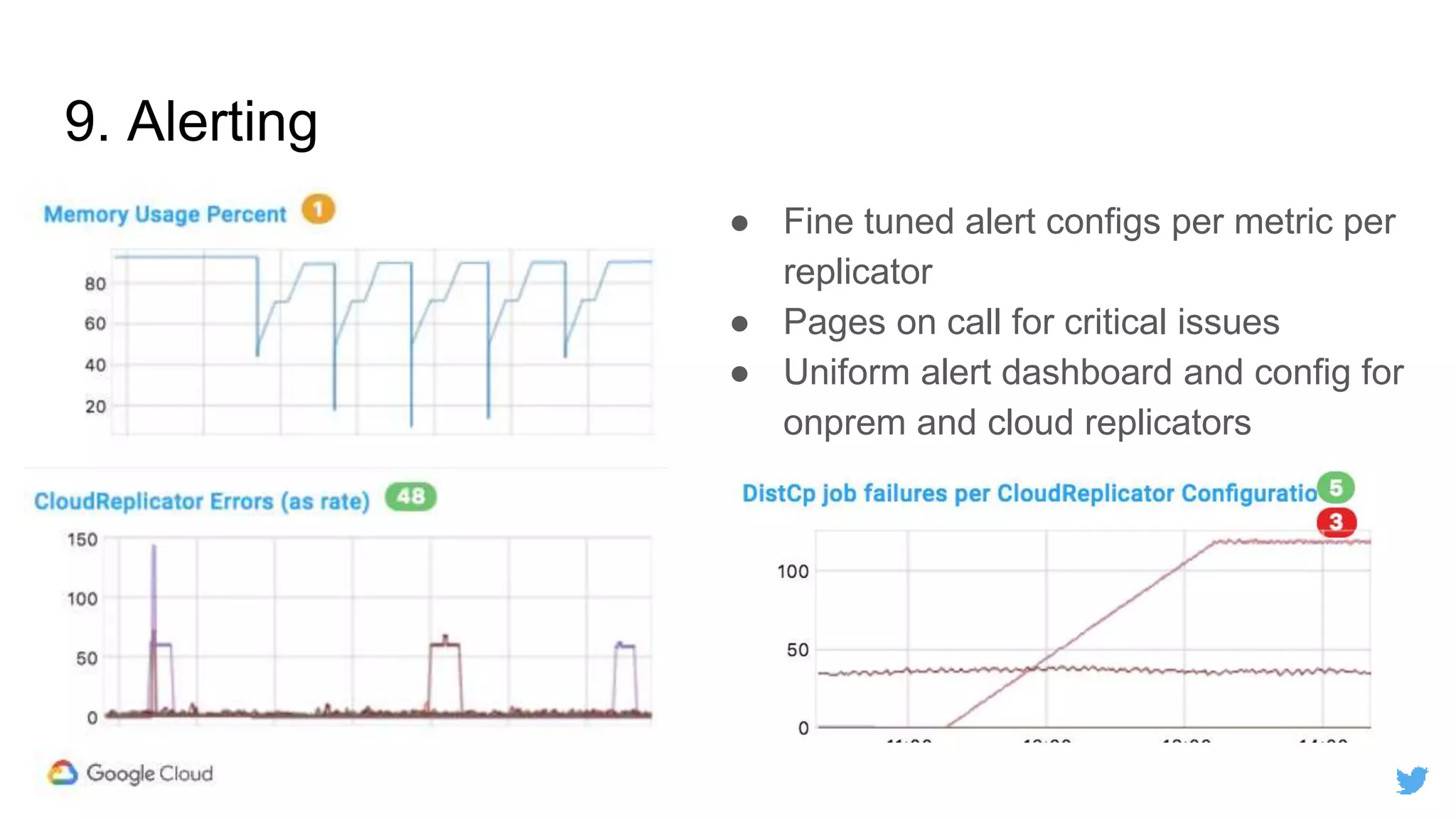
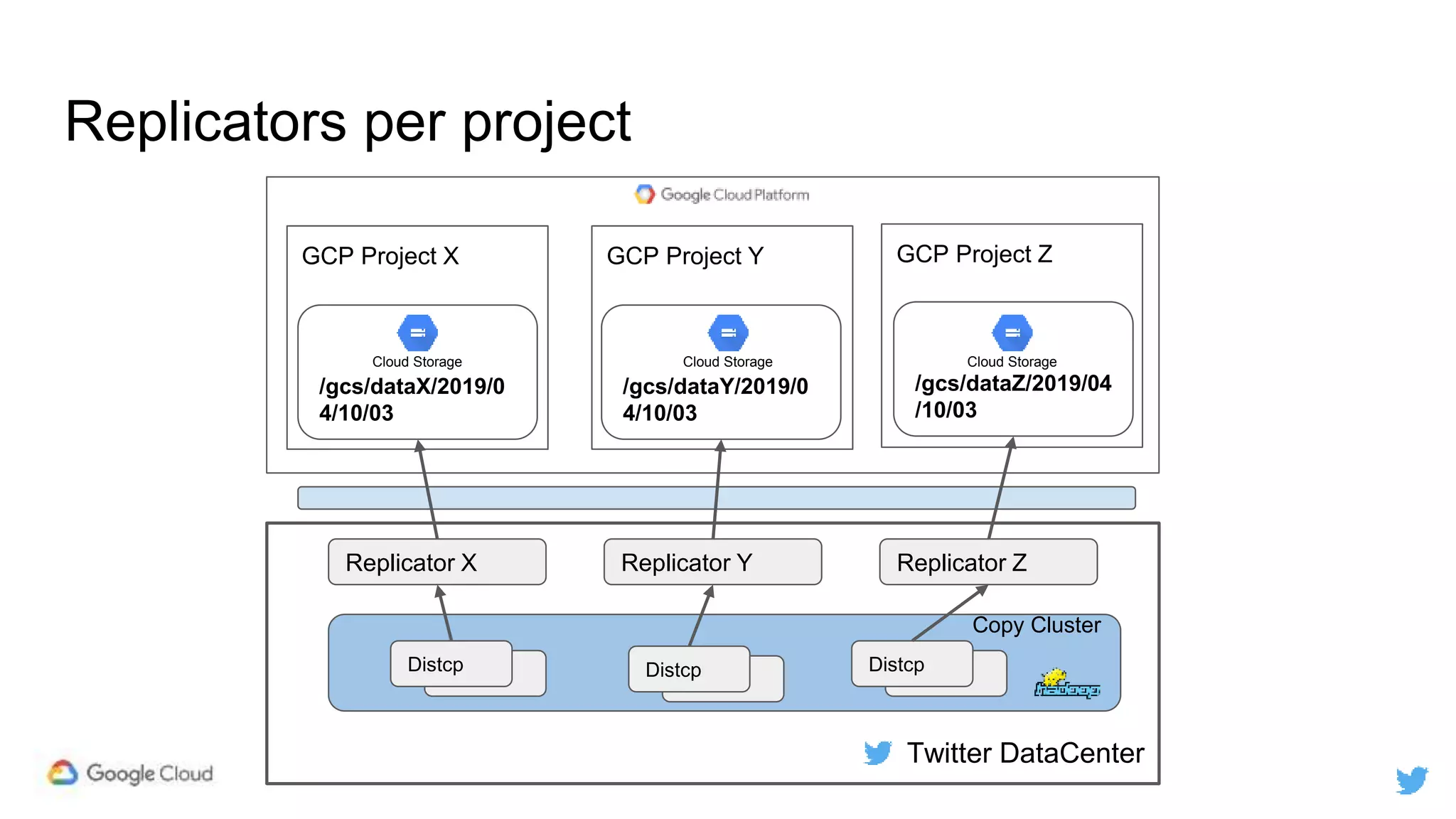
Twitter replicates petabytes of data from its Hadoop clusters to Google Cloud Storage daily using a data replicator architecture. The replicator copies data in hourly/daily partitions from source clusters to destination clusters and Google Cloud Storage, maintaining consistent access for users through a unified file system abstraction and data access layer. This replication enables unlocking analytics tools on Google Cloud Platform and provides a backup of Twitter data on cloud object storage.









![RegEx based path resolution
<property>
<name>fs.viewfs.mounttable.copycluster.linkRegex.replaceresolveddstpath:-:--
;replaceresolveddstpath:_:-#.^/gcs/logs/(?!((tst|test)(_|-)))(?<dataset>[^/]+)</name>
<value>gs://logs.${dataset}</value>
</property>
<property> <name>fs.viewfs.mounttable.copycluster.linkRegex.replaceresolveddstpath:-:--
;replaceresolveddstpath:_:-#.^/gcs/user/(?!((tst|test)(_|-)))(?<userName>[^/]+)</name>
<value>gs://user.${userName}</value>
</property>
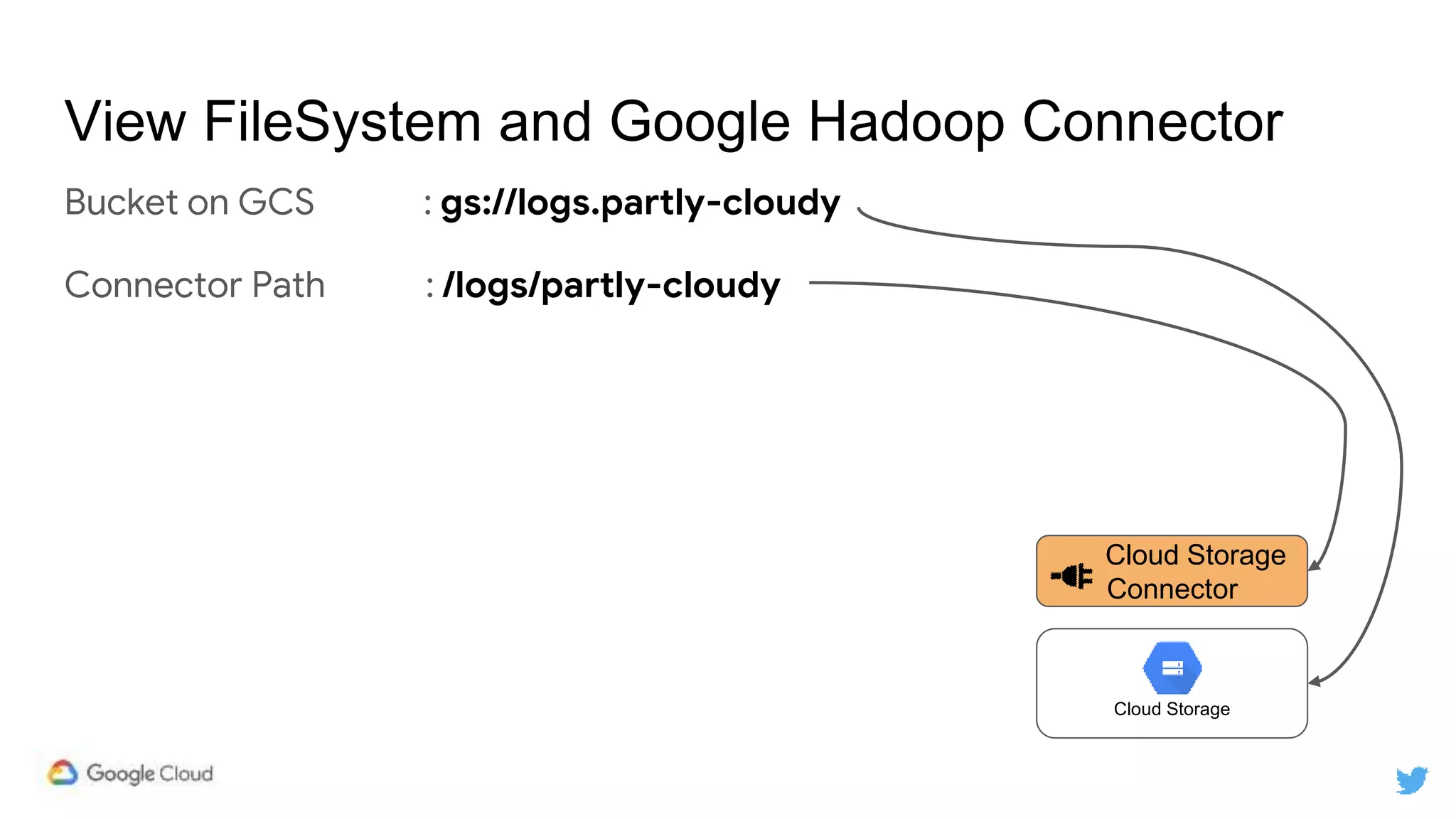
/gcs/logs/partly-cloudy/2019/04/10
/gcs/user/lohit/hadoop-stats
gs://logs.partly-cloudy/2019/04/10
gs://user.lohit/hadoop-stats
Twitter ViewFS Path GCS bucket
Twitter ViewFS mounttable.xml](https://image.slidesharecdn.com/da300twittersdatareplicatorforgooglecloudstorage-190411171318/75/Twitter-s-Data-Replicator-for-Google-Cloud-Storage-32-2048.jpg)