Download as PDF, PPTX








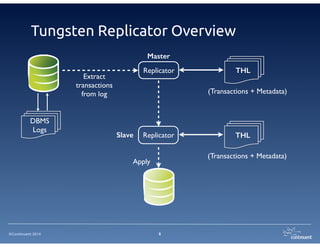
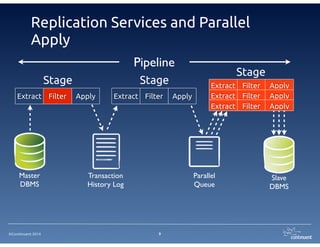
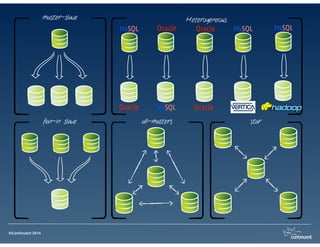

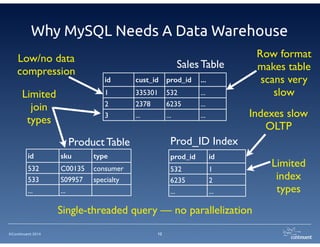
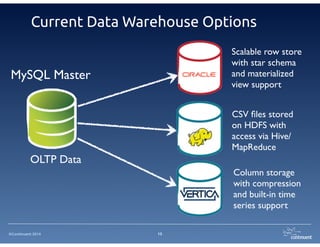
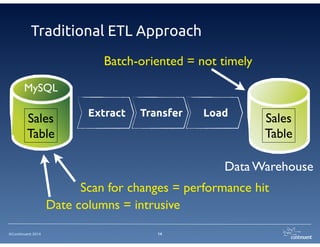
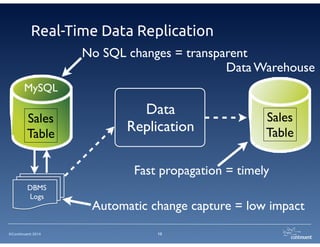
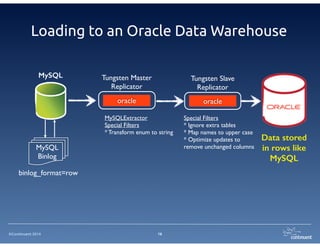
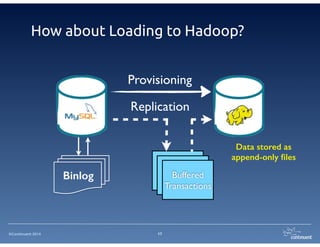

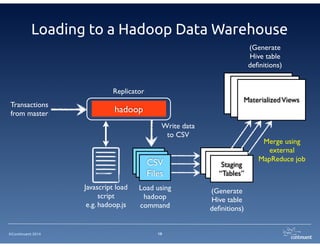
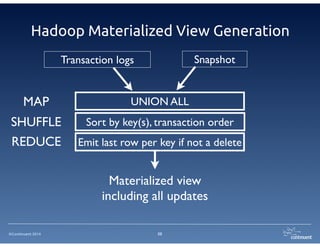
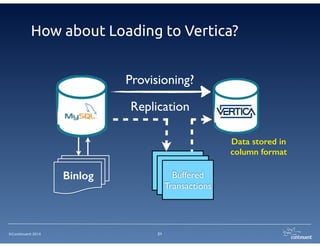
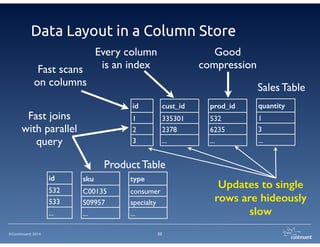
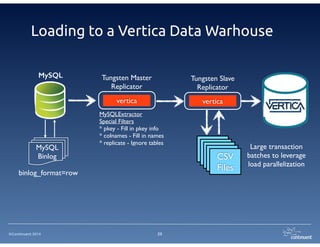
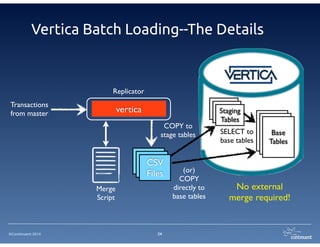
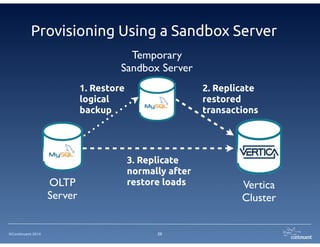

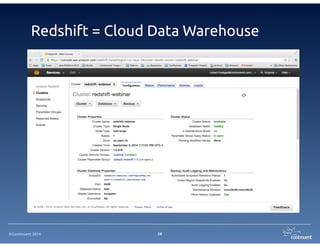


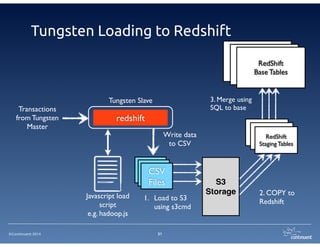
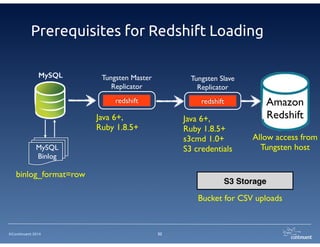

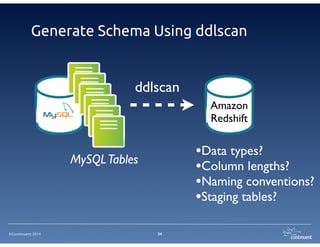


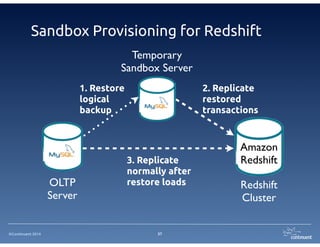


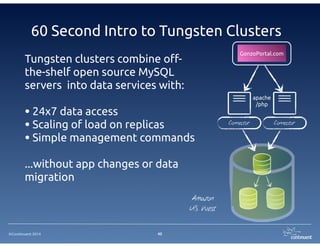
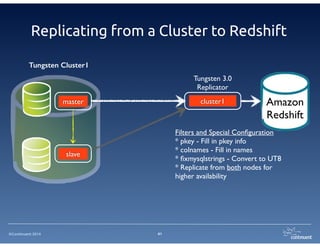
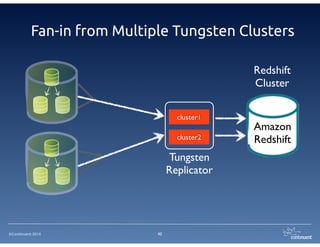





The document provides an overview of Continuent Tungsten, a high-performance open-source database replication engine, which enables real-time data replication from MySQL to Amazon Redshift. It outlines the features and functionalities of Tungsten Replicator, including its ability to handle large transaction volumes and support for various databases and data warehouses. Additionally, it discusses the setup and requirements for using Tungsten with Redshift, emphasizing its production readiness set for September 2014.























































































