

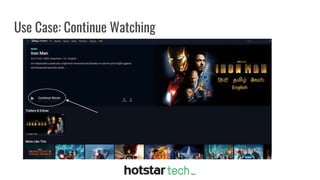

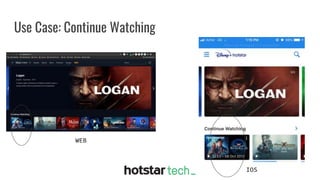


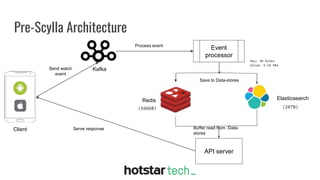
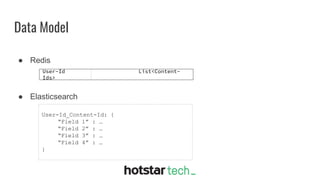




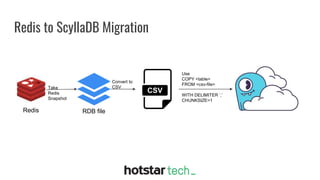


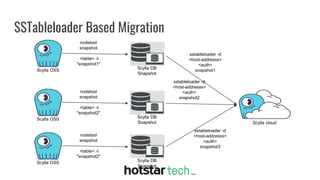

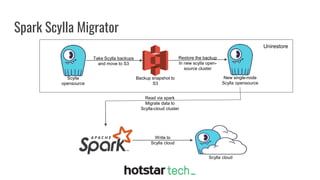




Disney+ Hotstar is an Indian streaming service with over 300 million active monthly users and a world record of 25.3 million concurrent viewers. The document discusses the transition from a pre-Scylla architecture involving multiple data stores to using ScyllaDB for reduced costs and low latency in data processing. The migration process, challenges faced, and recommendations for a successful transition are also outlined.












































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)










