Download to read offline






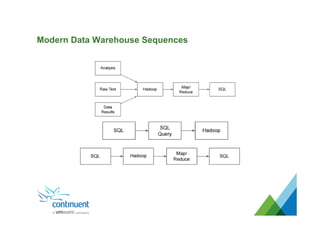



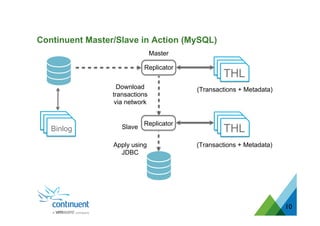
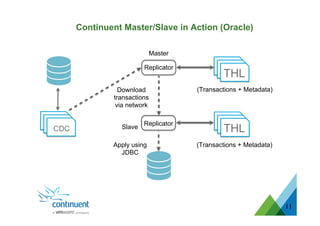
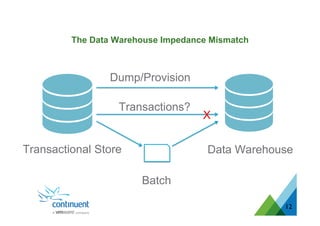

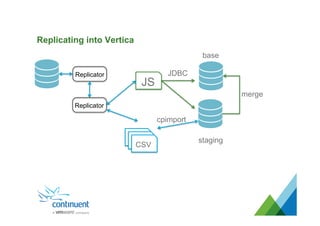

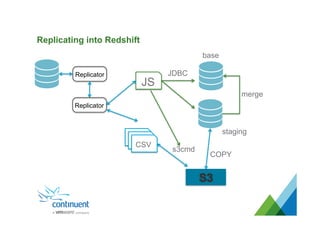
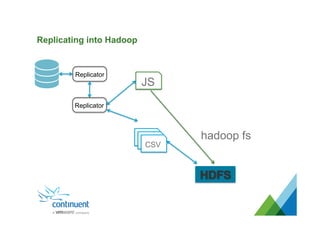
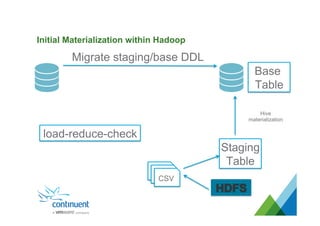

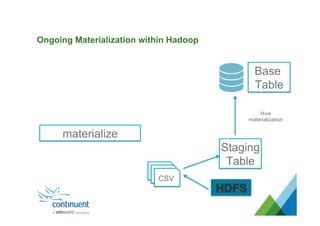





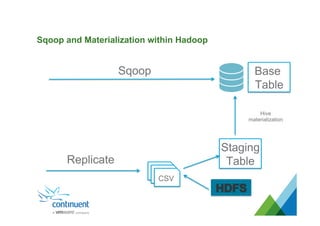


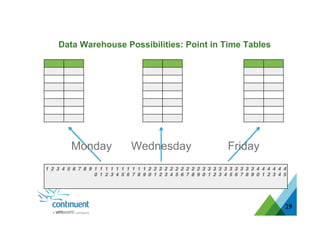



The document presents an overview of Continuent's data replication and integration solutions for databases such as MySQL and Oracle, emphasizing the shift towards real-time analytics and modern data warehousing. It highlights Continuent's products and their capabilities in high availability, business continuity, and efficient data integration across various platforms. Additionally, it discusses the evolution of data warehouses and the need for continuous data replication to support modern analytics requirements.




































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)
















