Download to read offline




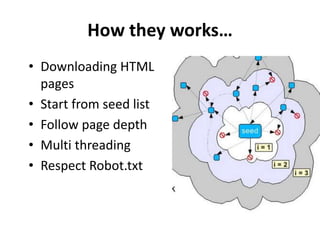













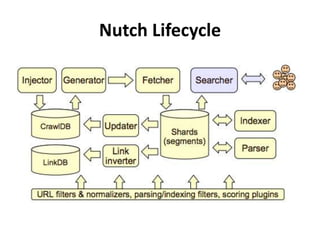
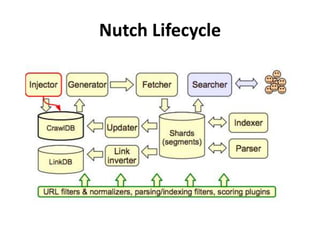
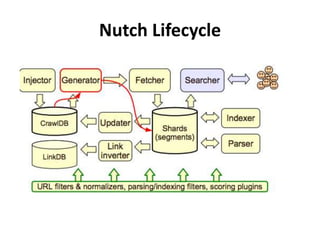
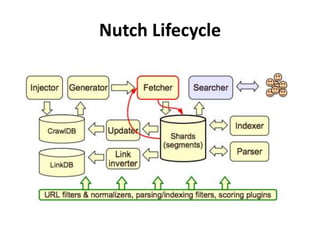
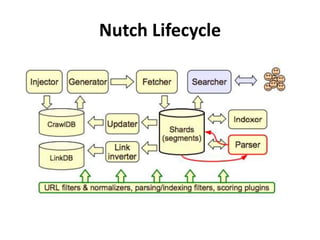
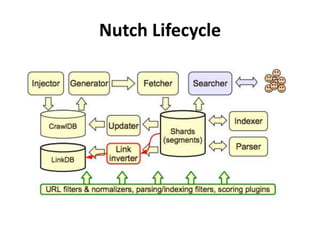
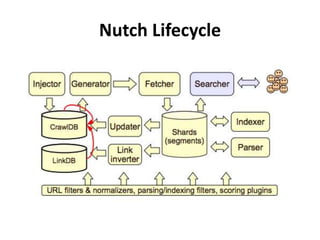








The document discusses Apache Nutch, an open source web crawler software project. It provides an overview of Nutch including its history and community, the Nutch crawling lifecycle of injecting, generating, fetching, parsing and updating URLs, how to extend Nutch through plugins, opportunities to use Nutch for analyzing Myanmar web content, and resources for learning more about Nutch. The presenter is the cofounder and architect of Bindez.com who has experience in web archiving, information retrieval and the Myanmar IT industry.




























































