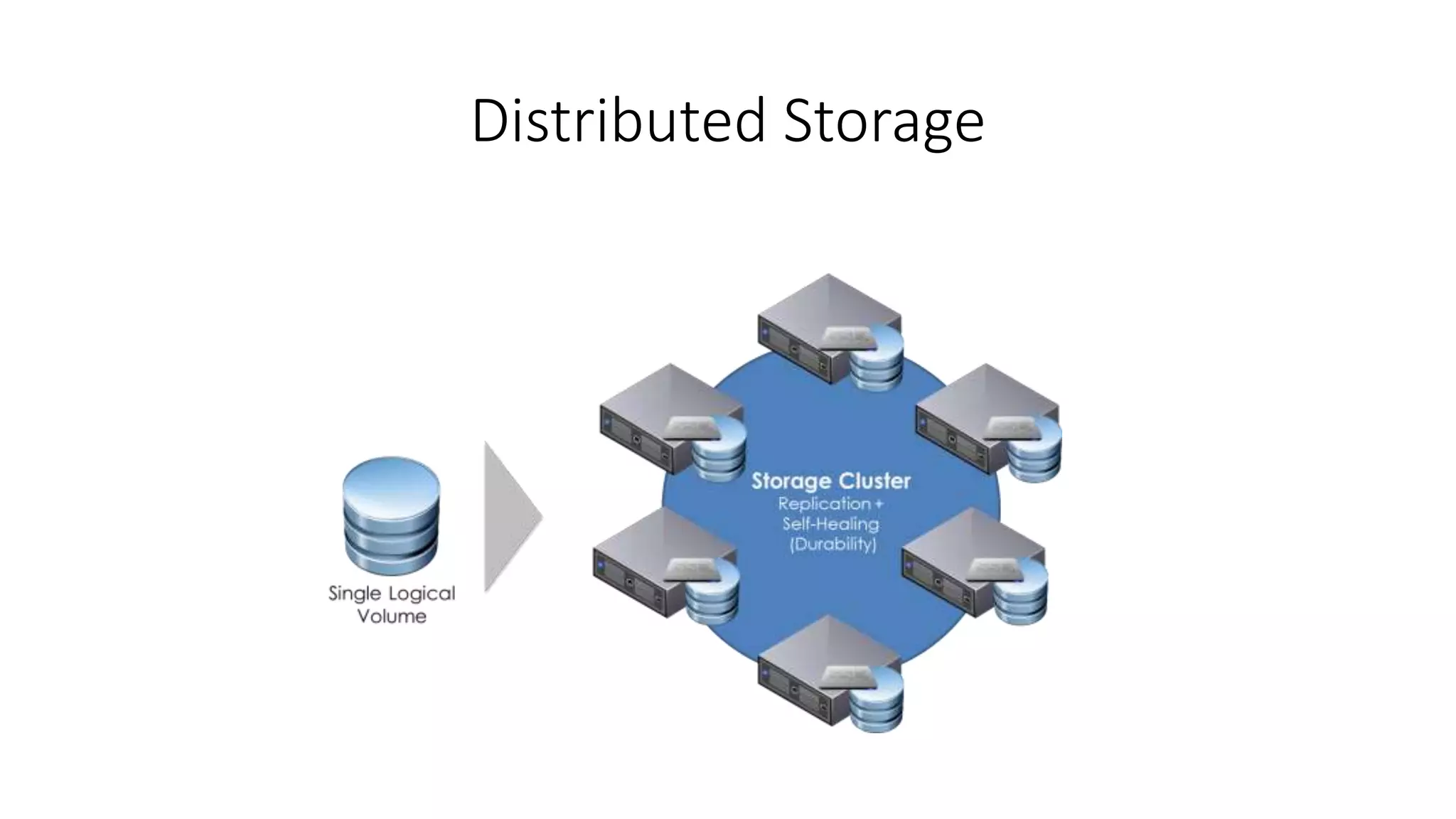
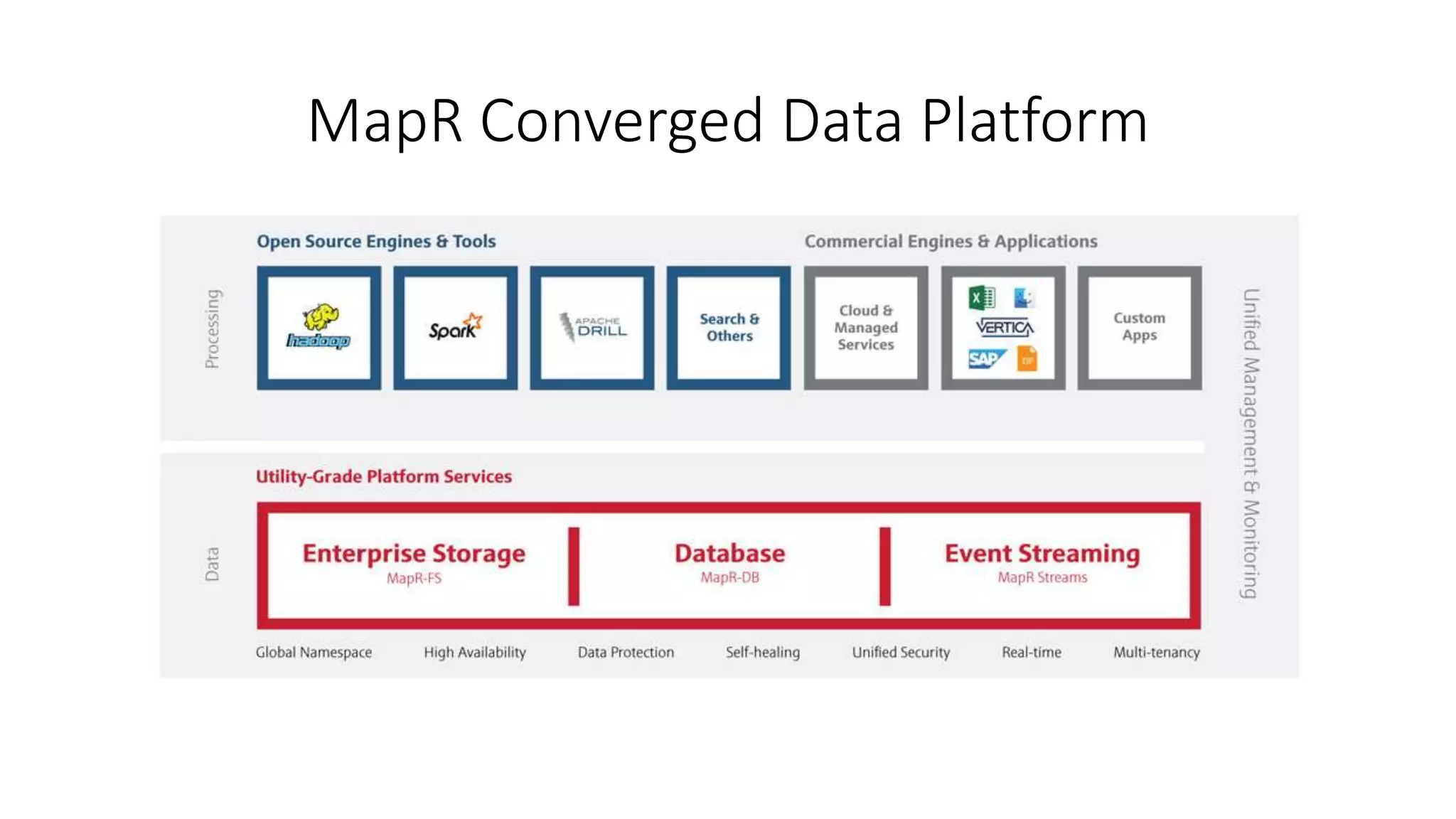
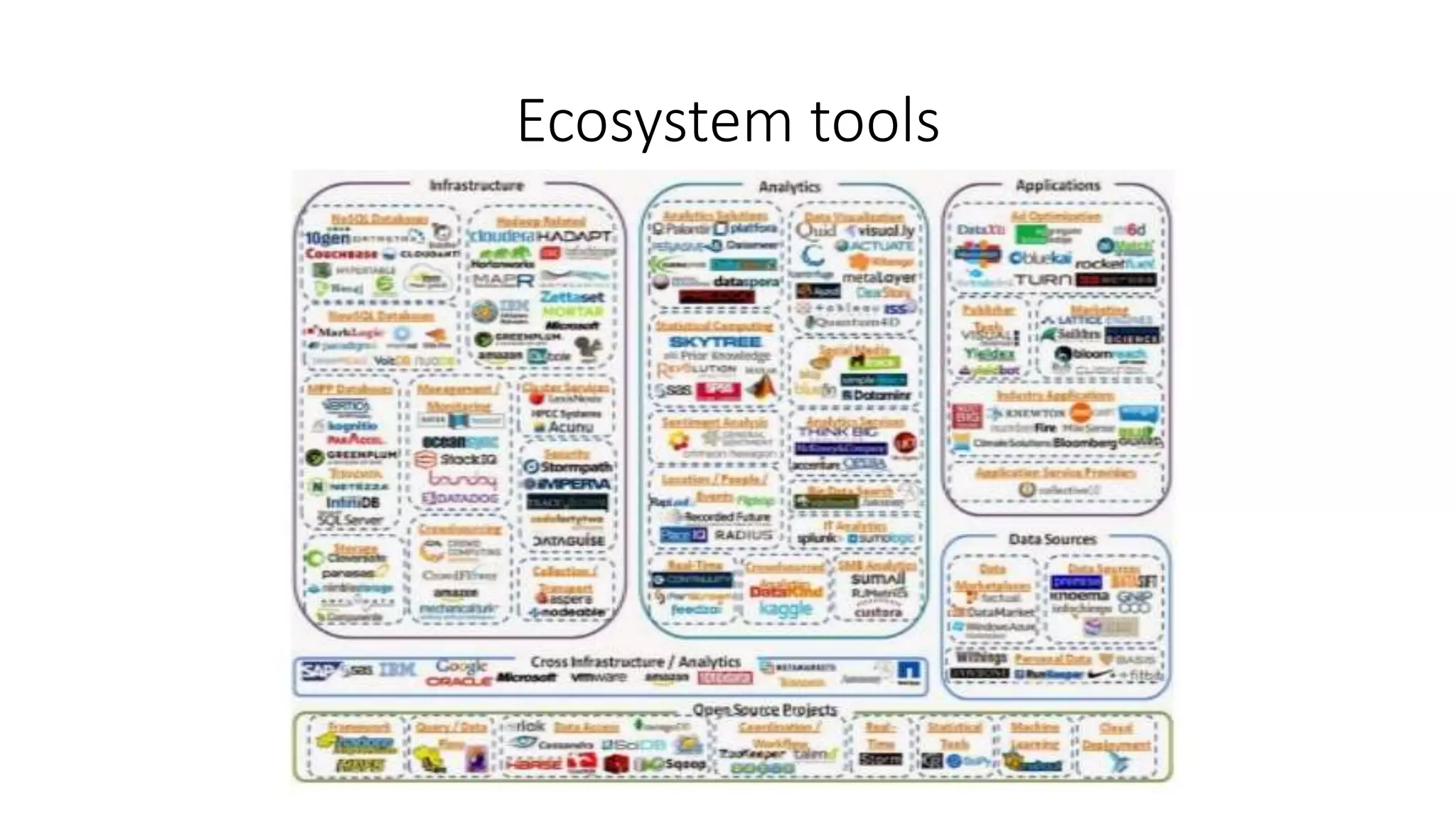
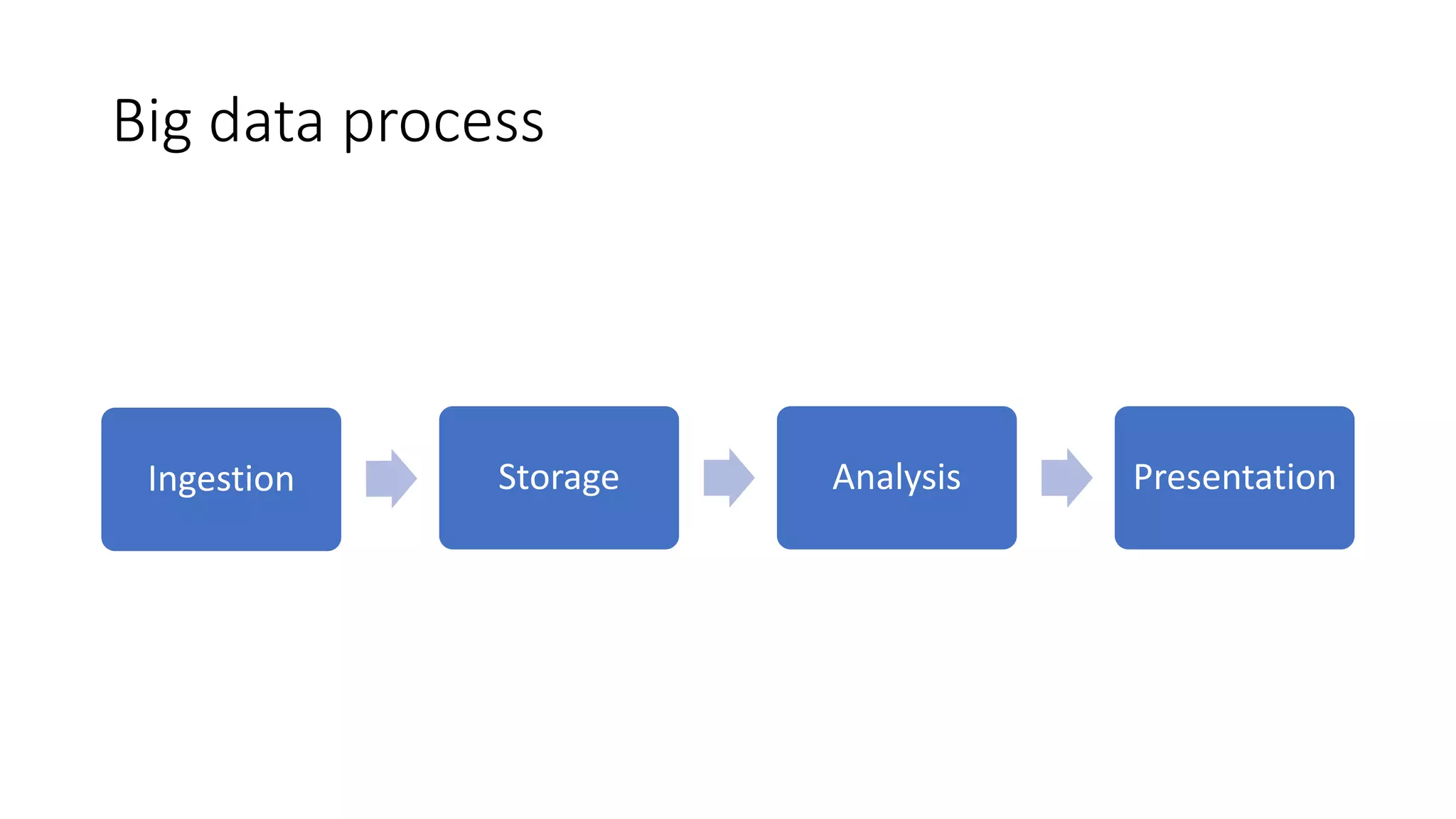
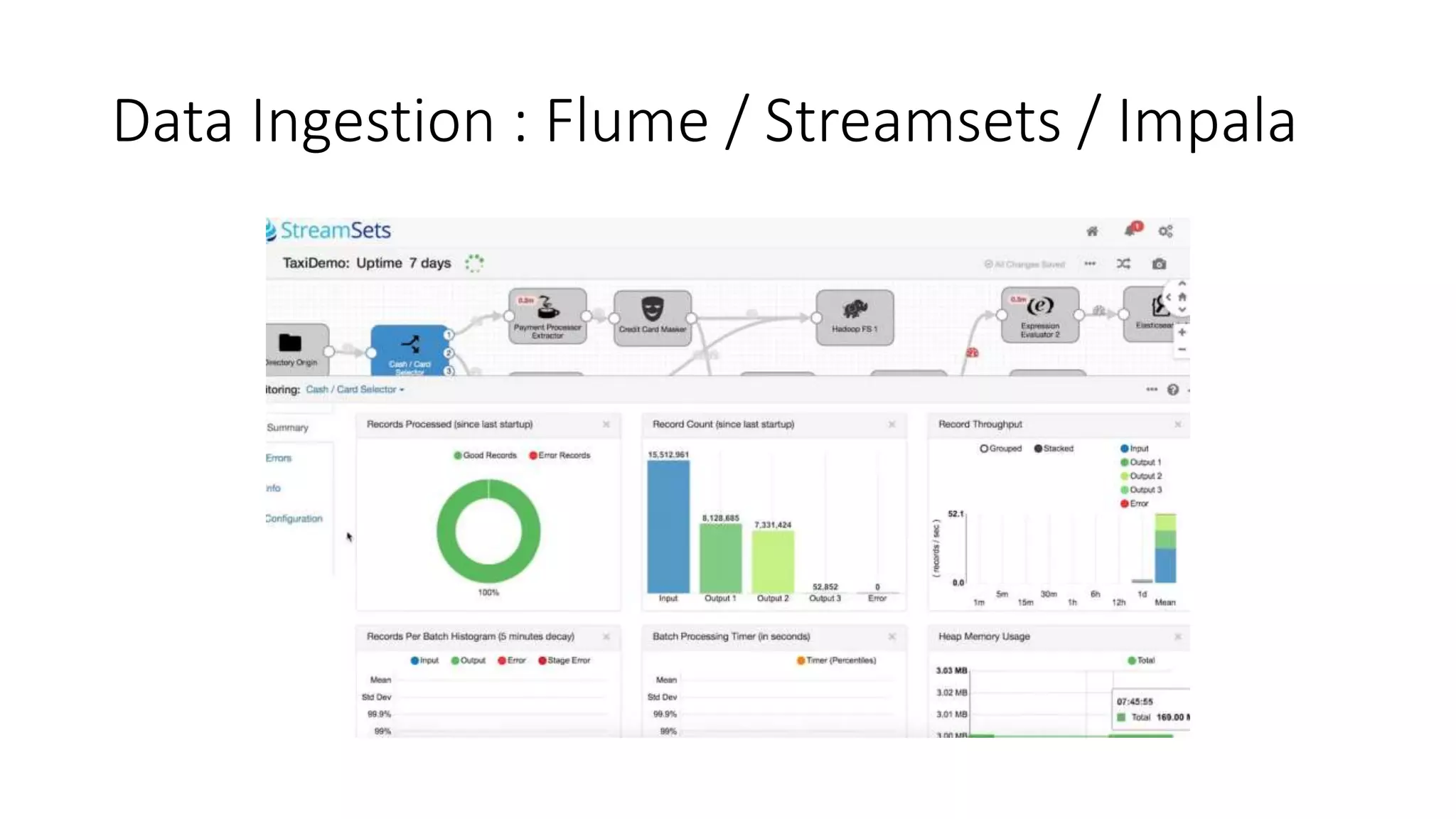
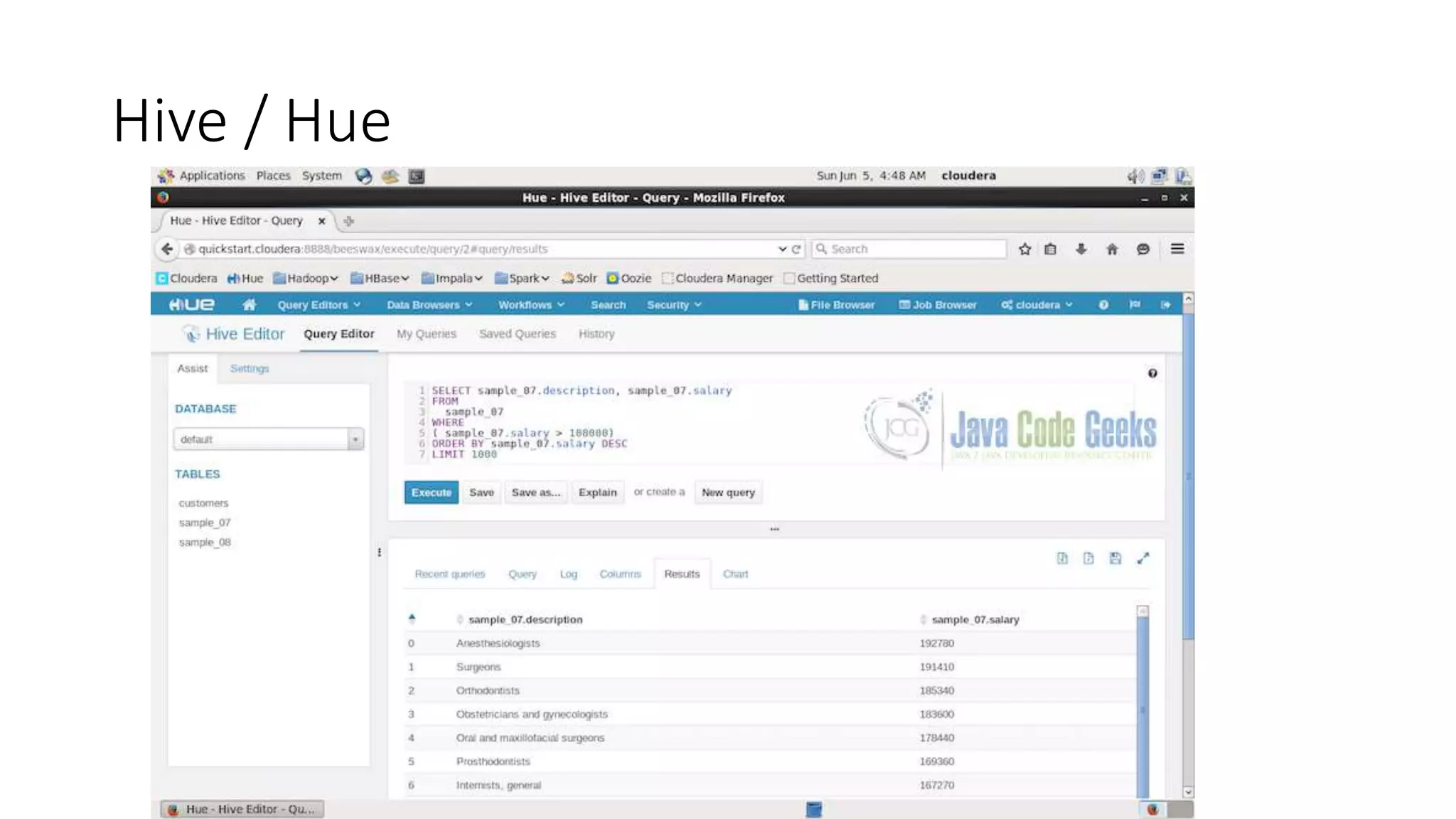
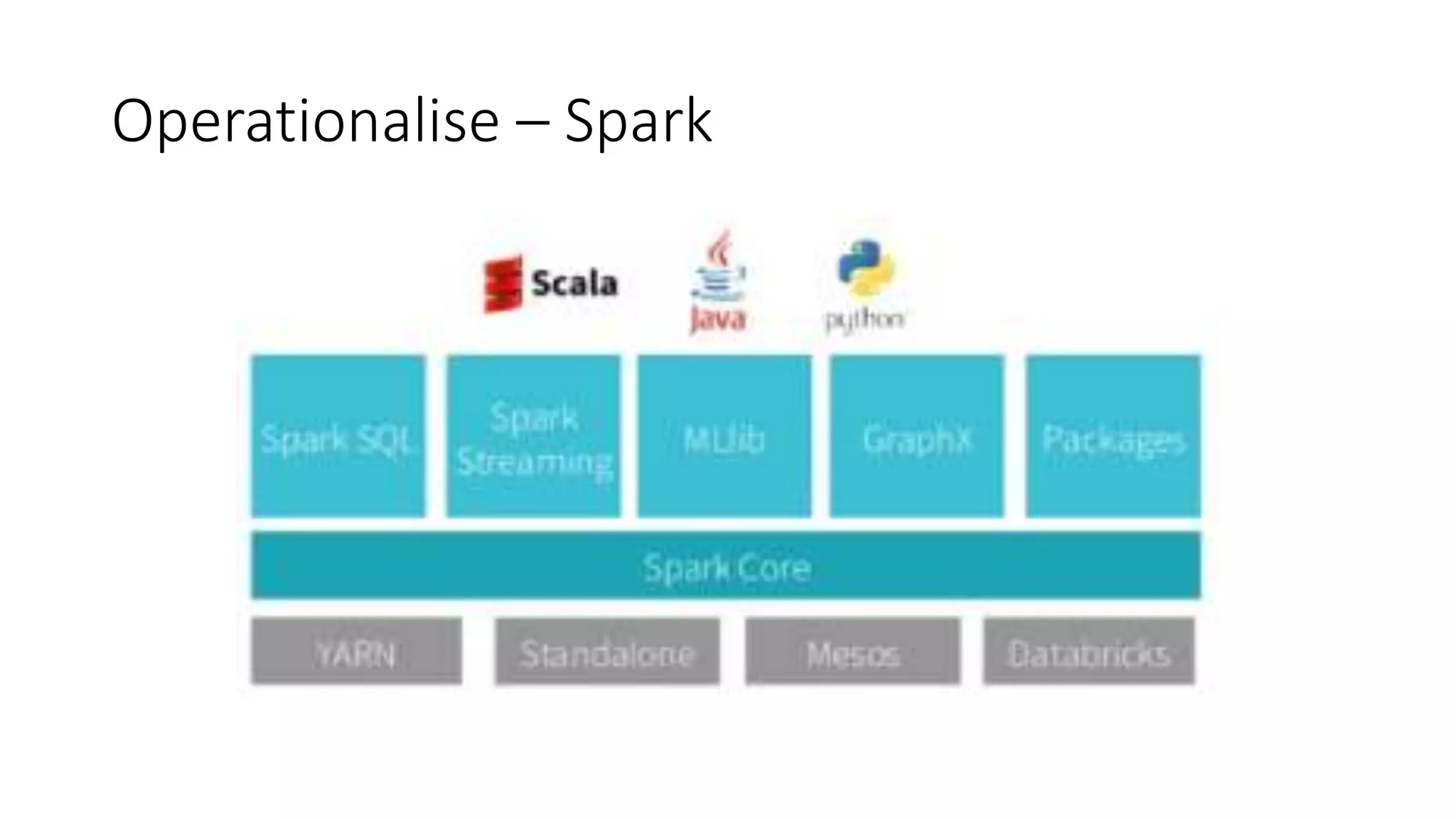
This document discusses trends in big data over the next 5 years. It begins with an overview of how big data has evolved from mainly transactional databases and small social media to today's landscape. It then contrasts old and new data paradigms, discussing distributed storage and main players like MapR. The document outlines the big data ecosystem and tools for ingestion, storage, analysis and presentation. It predicts that by 2025, deep learning will be empowered by big data, decision making will use AI libraries, and bots will provide more human services. The document recommends analyzing only relevant data bytes for decisions, and cautions that creativity is still more important than just big data.































































![Big_Data_ppt[1] (1).pptx](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatappt11-230720100552-10b674be-thumbnail.jpg?width=640&height=640&fit=bounds)


















![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












